Anomaly detection
異常檢測是機器學習中比較常見的應用,它主要用于非監督學習問題,從某些角度看, 它又類似于一些監督學習問題。
什么是異常檢測?來看幾個例子:
例1. 假設是飛機引擎制造商, 要對引擎進行質量控制測試,現在測量了飛機引擎的一些特征變量,比如引擎運轉時產生的熱量,引擎的震動,然后得到了兩個特征的無標簽數據集, 現在有了新的特征變量xtest ,我們希望這個新飛機引擎是否有某種異常。就是異常檢測。
在這次練習中,實現一個異常檢測算法來檢測服務器計算機中的異常行為。這些特性測量每個服務器的響應速度 (mb/s)和響應延遲(ms)。
收集到了m=307的樣本,無標簽。相信其中絕大多數樣本是正常的,但還是有一小部分的樣本是異常的。
mat = loadmat('ex8data1.mat')
print(mat.keys())
X = mat['X']
Xval, yval = mat['Xval'], mat['yval']
X.shape, Xval.shape, yval.shape
def gaussian(X, mu, sigma2):m, n = X.shapeif np.ndim(sigma2) == 1:sigma2 = np.diag(sigma2)norm = 1. / (np.power((2 * np.pi), n / 2) * np.sqrt(np.linalg.det(sigma2)))exp = np.zeros((m, 1))for row in range(m):xrow = X[row]exp[row] = np.exp(-0.5 * ((xrow - mu).T).dot(np.linalg.inv(sigma2)).dot(xrow - mu))return norm * exp
Gaussian distribution
高斯分布,也稱為正態分布,變量x 符合高斯分布 xN(μ,σ2)x~N(μ, σ^{2})x?N(μ,σ2) 則其概率密度函數為:
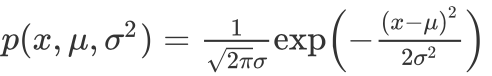
利用已有的數據來預測總體中的μ和σ2的計算方法如下:利用已有的數據來預測總體中的μ和σ^{2}的計算方法如下:利用已有的數據來預測總體中的μ和σ2的計算方法如下:
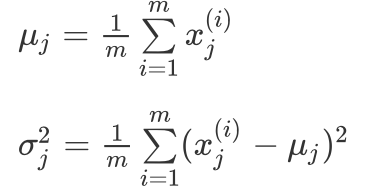
一旦我們獲得了平均值和方差的估計值,給定新的一個訓練實例,根據模型計算 p(x):
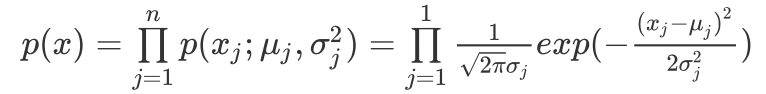
當p(x) < ε, 為異常。
Estimating parameters for a Gaussian
def get_gaussian_params(X, useMultivariate):mu = X.mean(axis=0)if useMultivariate:sigma2 = ((X - mu).T @ (X - mu)) / len(X)else:sigma2 = X.var(axis=0, ddof=0) # 樣本方差return mu, sigma2
def plot_contours(mu, sigma2):"""畫出高斯概率分布的圖,在三維中是一個上凸的曲面。投影到平面上則是一圈圈的等高線。"""delta = .3 # 注意delta不能太小!!!否則會生成太多的數據,導致矩陣相乘會出現內存錯誤。x = np.arange(0, 30, delta)y = np.arange(0, 30, delta)# 這部分要轉化為X形式的坐標矩陣,也就是一列是橫坐標,一列是縱坐標,# 然后才能傳入gaussian中求解得到每個點的概率值xx, yy = np.meshgrid(x, y)points = np.c_[xx.ravel(), yy.ravel()] # 按列合并,一列橫坐標,一列縱坐標z = gaussian(points, mu, sigma2)z = z.reshape(xx.shape) # 這步驟不能忘cont_levels = [10 ** h for h in range(-20, 0, 3)]plt.contour(xx, yy, z, cont_levels) # 這個levels是作業里面給的參考,或者通過求解的概率推出來。plt.title('Gaussian Contours', fontsize=16)
First contours without using multivariate gaussian
plot_data()
useMV = False
plot_contours(*get_gaussian_params(X, useMV))# Then contours with multivariate gaussian:
plot_data()
useMV = True
# *表示解元組
plot_contours(*get_gaussian_params(X, useMV))
Selecting the threshold, ε
確定哪些例子是異常的一種方法是通過一組交叉驗證集,選擇一個好的閾值 ε 。
在這部分的練習中,您將實現一個算法使用交叉驗證集的F1分數來選擇合理的閾值 ε
tp means true positives:是異常值,并且我們的模型預測成異常值了,即真的異常值。
fp means false positives:是正常值,但模型把它預測成異常值,即假的異常值。
fn means false negatives:是異常值,但是模型把它預測成正常值,即假的正常值。
precision 表示你預測為positive的樣本中有多少是真的positive的樣本。
recall 表示實際有多少positive的樣本,而你成功預測出多少positive的樣本。
def select_threshold(yval, pval):def computeF1(yval, pval):m = len(yval)tp = float(len([i for i in range(m) if pval[i] and yval[i]]))fp = float(len([i for i in range(m) if pval[i] and not yval[i]]))fn = float(len([i for i in range(m) if not pval[i] and yval[i]]))prec = tp / (tp + fp) if (tp + fp) else 0rec = tp / (tp + fn) if (tp + fn) else 0F1 = 2 * prec * rec / (prec + rec) if (prec + rec) else 0return F1epsilons = np.linspace(min(pval), max(pval), 1000)bestF1, bestEpsilon = 0, 0for e in epsilons:pval_ = pval < ethisF1 = computeF1(yval, pval_)if thisF1 > bestF1:bestF1 = thisF1bestEpsilon = ereturn bestF1, bestEpsilon
mu, sigma2 = get_gaussian_params(X, useMultivariate=False)
pval = gaussian(Xval, mu, sigma2)
bestF1, bestEpsilon = select_threshold(yval, pval)
# (0.8750000000000001, 8.999852631901397e-05)y = gaussian(X, mu, sigma2) # X的概率
xx = np.array([X[i] for i in range(len(y)) if y[i] < bestEpsilon])
xx # 離群點plot_data()
plot_contours(mu, sigma2)
plt.scatter(xx[:, 0], xx[:, 1], s=80, facecolors='none', edgecolors='r')
# High dimensional dataset
mat = loadmat('ex8data2.mat')
X2 = mat['X']
Xval2, yval2 = mat['Xval'], mat['yval']
X2.shape # (1000, 11)mu, sigma2 = get_gaussian_params(X2, useMultivariate=False)
ypred = gaussian(X2, mu, sigma2)yval2pred = gaussian(Xval2, mu, sigma2)# You should see a value epsilon of about 1.38e-18, and 117 anomalies found.
bestF1, bestEps = select_threshold(yval2, yval2pred)
anoms = [X2[i] for i in range(X2.shape[0]) if ypred[i] < bestEps]
bestEps, len(anoms)
Recommender Systems
Movie ratings dataset
mat = loadmat('ex8_movies.mat')
print(mat.keys())
Y, R = mat['Y'], mat['R']
nm, nu = Y.shape # Y中0代表用戶沒有評分
nf = 100
Y.shape, R.shape
# ((1682, 943), (1682, 943))Y[0].sum() / R[0].sum() # 分子代表第一個電影的總分數,分母代表這部電影有多少評分數據# "Visualize the ratings matrix"
fig = plt.figure(figsize=(8,8*(1682./943.)))
plt.imshow(Y, cmap='rainbow')
plt.colorbar()
plt.ylabel('Movies (%d) ' % nm, fontsize=20)
mat = loadmat('ex8_movieParams.mat')
X = mat['X']
Theta = mat['Theta']
nu = int(mat['num_users'])
nm = int(mat['num_movies'])
nf = int(mat['num_features'])
# For now, reduce the data set size so that this runs faster
nu = 4
nm = 5
nf = 3
X = X[:nm, :nf]
Theta = Theta[:nu, :nf]
Y = Y[:nm, :nu]
R = R[:nm, :nu]
Collaborative filtering learning algorithm
# 展開參數
def serialize(X, Theta):return np.r_[X.flatten(),Theta.flatten()]# 提取參數
def deserialize(seq, nm, nu, nf):return seq[:nm*nf].reshape(nm, nf), seq[nm*nf:].reshape(nu, nf)
Collaborative filtering cost function
def co_fi_cost_func(params, Y, R, nm, nu, nf, l=0):"""params : 拉成一維之后的參數向量(X, Theta)Y : 評分矩陣 (nm, nu)R :0-1矩陣,表示用戶對某一電影有無評分nu : 用戶數量nm : 電影數量nf : 自定義的特征的維度l : lambda for regularization"""X, Theta = deserialize(params, nm, nu, nf)# (X@Theta)*R含義如下: 因為X@Theta是我們用自定義參數算的評分,但是有些電影本來是沒有人# 評分的,存儲在R中,0-1表示。將這兩個相乘,得到的值就是我們要的已經被評分過的電影的預測分數。error = 0.5 * np.square((X @ Theta.T - Y) * R).sum()reg1 = .5 * l * np.square(Theta).sum()reg2 = .5 * l * np.square(X).sum()return error + reg1 + reg2co_fi_cost_func(serialize(X,Theta),Y,R,nm,nu,nf),co_fi_cost_func(serialize(X,Theta),Y,R,nm,nu,nf,1.5)Collaborative filtering gradient
def check_gradient(params, Y, myR, nm, nu, nf, l=0.):"""Let's check my gradient computation real quick"""print('Numerical Gradient \t cofiGrad \t\t Difference')# 分析出來的梯度grad = co_fi_gradient(params, Y, myR, nm, nu, nf, l)# 用 微小的e 來計算數值梯度。e = 0.0001nparams = len(params)e_vec = np.zeros(nparams)# Choose 10 random elements of param vector and compute the numerical gradient# 每次只能改變e_vec中的一個值,并在計算完數值梯度后要還原。for i in range(10):idx = np.random.randint(0, nparams)e_vec[idx] = eloss1 = co_fi_cost_func(params - e_vec, Y, myR, nm, nu, nf, l)loss2 = co_fi_cost_func(params + e_vec, Y, myR, nm, nu, nf, l)numgrad = (loss2 - loss1) / (2 * e)e_vec[idx] = 0diff = np.linalg.norm(numgrad - grad[idx]) / np.linalg.norm(numgrad + grad[idx])print('%0.15f \t %0.15f \t %0.15f' % (numgrad, grad[idx], diff))print("Checking gradient with lambda = 0...")
check_gradient(serialize(X, Theta), Y, R, nm, nu, nf)
print("\nChecking gradient with lambda = 1.5...")
check_gradient(serialize(X, Theta), Y, R, nm, nu, nf, l=1.5)
Learning movie recommendations
movies = [] # 包含所有電影的列表
with open('data/movie_ids.txt', 'r', encoding='utf-8') as f:for line in f:
# movies.append(' '.join(line.strip().split(' ')[1:]))movies.append(' '.join(line.strip().split(' ')[1:]))my_ratings = np.zeros((1682, 1))my_ratings[0] = 4
my_ratings[97] = 2
my_ratings[6] = 3
my_ratings[11] = 5
my_ratings[53] = 4
my_ratings[63] = 5
my_ratings[65] = 3
my_ratings[68] = 5
my_ratings[182] = 4
my_ratings[225] = 5
my_ratings[354] = 5for i in range(len(my_ratings)):if my_ratings[i] > 0:print(my_ratings[i], movies[i])mat = loadmat('data/ex8_movies.mat')
Y, R = mat['Y'], mat['R']
Y.shape, R.shapeY = np.c_[Y, my_ratings] # (1682, 944)
R = np.c_[R, my_ratings!=0] # (1682, 944)
nm, nu = Y.shape
nf = 10 # 我們使用10維的特征向量def normalizeRatings(Y, R):"""The mean is only counting movies that were rated"""Ymean = (Y.sum(axis=1) / R.sum(axis=1)).reshape(-1,1)
# Ynorm = (Y - Ymean)*R # 這里也要注意不要歸一化未評分的數據Ynorm = (Y - Ymean)*R # 這里也要注意不要歸一化未評分的數據return Ynorm, YmeanYnorm, Ymean = normalizeRatings(Y, R)
Ynorm.shape, Ymean.shape
# ((1682, 944), (1682, 1))X = np.random.random((nm, nf))
Theta = np.random.random((nu, nf))
params = serialize(X, Theta)
l = 10
Recommendations
import scipy.optimize as opt
res = opt.minimize(fun=co_fi_cost_func(),x0=params,args=(Y, R, nm, nu, nf, l),method='TNC',jac=co_fi_gradient(),options={'maxiter': 100})ret = res.xfit_X, fit_Theta = deserialize(ret, nm, nu, nf)# Recommendations
# 所有用戶的劇場分數矩陣
pred_mat = fit_X @ fit_Theta.T# 最后一個用戶的預測分數, 也就是我們剛才添加的用戶
pred = pred_mat[:,-1] + Ymean.flatten()pred_sorted_idx = np.argsort(pred)[::-1] # 排序并翻轉,使之從大到小排列print("Top recommendations for you:")
for i in range(10):print('Predicting rating %0.1f for movie %s.' \% (pred[pred_sorted_idx[i]], movies[pred_sorted_idx[i]]))print("\nOriginal ratings provided:")
for i in range(len(my_ratings)):if my_ratings[i] > 0:print('Rated %d for movie %s.' % (my_ratings[i], movies[i]))
![CODE[VS] 1621 混合牛奶 USACO](http://pic.xiahunao.cn/CODE[VS] 1621 混合牛奶 USACO)





![isql 測試mysql連接_[libco] 協程庫學習,測試連接 mysql](http://pic.xiahunao.cn/isql 測試mysql連接_[libco] 協程庫學習,測試連接 mysql)












