In FAANG company interview, Candidates always come across heap problems. There is one question they do like to ask — Top K. Because these companies have a huge dataset and they can’t always go through all the data. Finding tope data is always a good option. In this article, I would like to share my methodology on handling heap interview problems. Also, I’ll share 2 typical heap algorithm problems — Top K Frequent, Merge K arrays.
在FAANG公司面試中,候選人總是遇到堆砌問題。 他們想問一個問題-TopK。因為這些公司擁有龐大的數據集,而且不能總是遍歷所有數據。 查找tope數據始終是一個不錯的選擇。 在本文中,我想分享我的方法來處理堆訪談問題。 另外,我將分享2個典型的堆算法問題-排在前K個,合并K個數組。
什么是堆? (What is Heap?)
Heap is a complete Tree-like data structure. It has a parent node, left child node and right child node. For the interview, the min-heap and max-heap are very common to see.
堆是一個完整的樹狀數據結構。 它具有父節點,左子節點和右子節點。 對于采訪來說,最小堆和最大堆很常見。
Max-Heap: In a Max-Heap the value present at the parent node must be greatest among the values present at all of its children.
最大堆 :在最大堆中,父節點上存在的值必須在其所有子節點上存在的值中最大。
Min-Heap: In a Min-Heap the value present at the parent node must be minimum among the values present at all of its children.
最小堆 :在最小堆中,父節點上存在的值必須在其所有子節點上存在的值中最小。
堆方法 (Heap methodology)
This is the methodology to help think about the solution:
這是幫助考慮解決方案的方法:
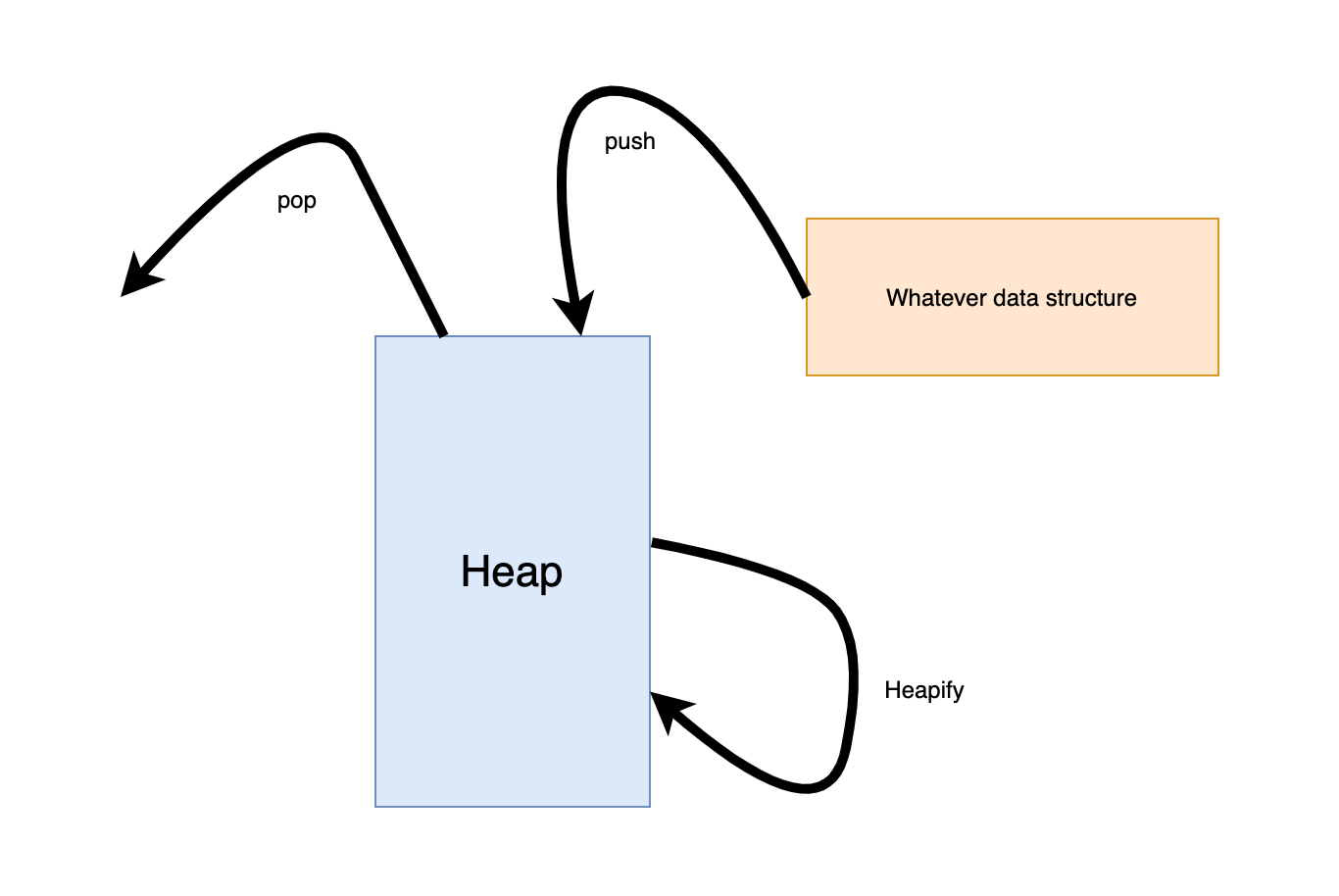
For most of the popular data structure problems. The feature is common: we have to do sort-like steps. We can sort all the elements: heapsort. We can sort just several elements: top-k. The elements should be comparable. Otherwise, we may have to push some comparable value along with the elements.
對于大多數流行的數據結構問題。 該功能很常見:我們必須執行類似排序的步驟。 我們可以對所有元素進行排序:heapsort。 我們可以對幾個元素進行排序:top-k。 元素應該是可比較的。 否則,我們可能不得不將一些可比較的價值與要素一起推向市場。
Push: What we push some comparable elements such as int. Sometimes I have to push a comparable object. No matter what we push, we are doing it for comparison and heapify.
推送 :我們推送一些可比較的元素,例如int。 有時我必須推動一個類似的對象。 無論我們推動什么,我們都在進行比較和堆化。
Heapify: Heapify is the process of converting a binary tree into a Heap data structure by rearranging the nodes in the binary tree to a max-heap or min-heap.
Heapify :Heapify是通過將二叉樹中的節點重新排列為max-heap或min-heap來將二叉樹轉換為Heap數據結構的過程。
In case one of your interview questions is implementing heapify, Here I attached the code:
如果您的面試問題之一是實現heapify,請在此處附加代碼:
In this case, we have to push the node to the heap. As heap’s representation is an array. It appends the new node to the end and heapify it. Here is the code for a max-heap:
在這種情況下,我們必須將節點推送到堆。 由于堆的表示是一個數組。 它將新節點附加到末尾并對其進行堆放。 這是最大堆的代碼:
For each insert, it takes O (log K) time to heapify the node, K is the heap size.
對于每個插入,需要O(log K)時間來堆滿節點,K是堆大小。
Pop: Now it’s time to get what we want. Here we have two cases:
Pop :現在是時候獲得我們想要的東西了。 這里有兩種情況:
We use the value on the root of the heap. If needed, we can use heap[0] to check the top one if we have some extra conditions in the question. After we get the value, we can put it in an array or do extra work as the question requested.
我們在堆的根上使用該值。 如果需要,可以在問題中使用一些額外的條件,使用heap [0]檢查最上面的一個。 獲得值后,我們可以將其放入數組中,也可以根據要求進行其他工作。
- In other cases, we need the rest of the values in the Heap. We can loop through the heap and return it. 在其他情況下,我們需要堆中的其余值。 我們可以遍歷堆并返回它。
實踐 (Practices)
Here I provide solutions with python. For most of the Algorithm problems, it’s not just one solution. It’s better to give different solutions, analyse the time/space complexity and move to the best one.
在這里,我提供了python解決方案。 對于大多數算法問題,這不僅僅是一種解決方案。 最好提供不同的解決方案,分析時間/空間的復雜性,然后轉向最佳解決方案。
In python, we have heapq library to help us operate the heap properly. It has nlargest and nsmallest which we can use to solve top-k type problem in one line of code. However, to ensure you can understand better about Heap, let’s go step by step.
在python中,我們有heapq庫來幫助我們正確地操作堆。 它具有nlarge和nsmallest ,可用于在一行代碼中解決top-k類型的問題。 但是,為了確保您可以更好地了解Heap,讓我們逐步進行。
前K頻 (Top K Frequent)
Here is the reference question on leetcode. We just find the top K frequent values in an array.
這是有關leetcode的參考問題 。 我們只是在數組中找到前K個頻繁值。
Here are the steps from the code:
這是代碼中的步驟:
- Convert the array to a new array where the element is a tuple with value and frequency. 將數組轉換為新數組,其中元素是具有值和頻率的元組。
- Push the tuple elements to the k-size heap. The heap heapify automatically whenever a new node has been pushed. 將元組元素推入k大小的堆。 每當推送新節點時,堆都會自動堆化。
- After we go through all the elements with the heap, we loop the rest of the heap to find our target values. 在遍歷了堆中的所有元素之后,我們循環其余堆以找到目標值。
If you are pushing an object, you have to ensure the object is comparable. If you push a tuple, the heap compare the first element while doing heapify, if ties happened, it will compare the next value.
如果要推動對象,則必須確保該對象具有可比性。 如果推入一個元組,堆將在執行heapify時比較第一個元素,如果發生聯系,它將比較下一個值。
合并K個數組 (Merge K arrays)
Here is the reference question on leetcode. We have to Merge k sorted linked lists and return it as one sorted list. Here is the solution with Heap:
這是有關leetcode的參考問題 。 我們必須合并k個排序的鏈表,并將其作為一個排序表返回。 這是堆的解決方案:
Here are the steps from the code:
這是代碼中的步驟:
- We build an array with the first node and its value from each ListNode in lists. Then we heapify it to be a min-heap. 我們使用列表中每個ListNode的第一個節點及其值構建一個數組。 然后我們將其堆成最小堆。
- We use the peek node in the heap to build the output ListNode. 我們使用堆中的peek節點構建輸出ListNode。
If the node not ends, we use heapreplace which means we pop and return the smallest item from the heap, and also push the new item.
如果節點未結束,則使用heapreplace,這意味著我們從堆中彈出并返回最小的項,并推送新項 。
Here I would like to explain another solution to this question with the Priority Queue.
在這里,我想用“優先級隊列”解釋這個問題的另一種解決方案。
Priority Queues are abstract data structures where each data/value in the queue has a certain priority. Priority Queue is an extension of the queue with the following properties.1, An element with high priority is dequeued before an element with low priority.2, If two elements have the same priority, they are served according to their order in the queue.
優先級隊列是抽象的數據結構,其中隊列中的每個數據/值都有特定的優先級。 Priority Queue是具有以下屬性的隊列的擴展:1,將高優先級的元素排在優先級低的元素之前。2,如果兩個元素具有相同的優先級,則根據它們在隊列中的順序進行服務。
Here are the steps from the code:
這是代碼中的步驟:
- From each element in the List, we find the first node with its value in the ListNode, put it into the Priority Queue. We need the node value because we need it for comparison in the Priority Queue. 從List中的每個元素中,我們在ListNode中找到具有其值的第一個節點,并將其放入Priority Queue。 我們需要節點值,因為在優先級隊列中需要進行比較。
- Then, we get the element from the Priority Queue (the element with the smallest value), link it to the output ListNode. 然后,我們從Priority Queue中獲得元素(值最小的元素),并將其鏈接到輸出ListNode。
- We move the node to the next, if it exists, we put it into the Priority Queue. After all these steps, we return the output ListNode which is the head.next. 我們將節點移到下一個節點(如果存在),將其放入優先級隊列。 完成所有這些步驟之后,我們返回輸出ListNode,它是head.next。
最后的話 (Final Words)
After you read this article, you may think heap is not as hard as you thought with this methodology. However, we may have other data structure comes up with Heap such as the LinkedList. Therefore, we still need to practise and master the basic data structure API with the language you preferred.
閱讀本文之后,您可能會認為堆并不像您對這種方法所想象的那樣難。 但是,Heap可能還會提供其他數據結構,例如LinkedList。 因此,我們仍然需要使用您喜歡的語言來練習和掌握基本的數據結構API。
Hope you learn something from this article. If you are interested in reading any of my other articles, you are welcome to check them out in my profile. Best wishes for your job hunting!
希望您能從本文中學到一些東西。 如果您有興趣閱讀我的其他文章,歡迎您在我的個人資料中查看。 祝您工作愉快!
翻譯自: https://medium.com/dev-genius/a-methodology-to-ace-the-heap-algorithms-question-c7063b2ba7fd
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388900.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388900.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388900.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

android webView的緩存機制和資源預加載

mysql springboot 緩存_Spring Boot 整合 Redis 實現緩存操作

http壓力測試工具及使用說明

itchat 道歉_人類的“道歉”
)
使用Kubespray部署生產可用的Kubernetes集群(1.11.2)

android webView 與 JS交互方式

matlab軟件imag函數_「復變函數與積分變換」基本計算代碼

數據科學 python_為什么需要以數據科學家的身份學習Python的7大理由
![[luoguP4142]洞穴遇險](http://pic.xiahunao.cn/[luoguP4142]洞穴遇險)
[luoguP4142]洞穴遇險


django的contenttype表

視頻播放問題和提高性能方案

rabbitmq 不同的消費者消費同一個隊列_RabbitMQ 消費端限流、TTL、死信隊列

動量策略 python_在Python中使用動量通道進行交易

css3 變換、過渡效果、動畫

webservice 啟用代理服務器

mysql常用的存儲引擎_Mysql存儲引擎


高斯模糊為什么叫高斯濾波_為什么高斯是所有發行之王?
