人口密度可視化
GeoVisualization /菲律賓。 (GeoVisualization /Philippines.)
Population density is a crucial concept in urban planning. Theories on how it affects economic growth are divided. Some claim, as Rappaport does, that an economy is a form of “spatial equilibrium”: that net flows of residents and employment gradually move to be balanced with one another.
人口密度是城市規劃中的關鍵概念。 關于它如何影響經濟增長的理論存在分歧。 就像拉帕波特所做的那樣,有人聲稱經濟是“空間均衡”的一種形式: 居民和就業的凈流動逐漸走向相互平衡。
The thought that density has some sort of relationship with economic growth has long been established by multiple studies. But whether the same theory holds for the Philippines and to what predates what (density follows urban development or urban development follows density) is a classic data science problem.
關于密度與經濟增長之間存在某種關系的觀點早已由多項研究確立。 但是,對于菲律賓來說,是否適用相同的理論以及先于什么(密度跟隨城市發展,密度跟隨城市發展)是一個經典的數據科學問題。
Before we can test out any models, however, let’s do a fun exercise and visualize our dataset.
但是,在測試任何模型之前,讓我們做一個有趣的練習并使數據集可視化。
The 2015 Philippines’ Population Dataset
2015年菲律賓的人口數據集
The Philippine Statistic Authority publishes population data every five (5) years. At the time of the writing, only the 2015 Dataset is published so we will be using this.
菲律賓統計局每五(5)年發布一次人口數據。 在撰寫本文時,僅發布了2015年數據集,因此我們將使用它。
Importing Packages
導入包
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as colors #to customize our colormap for legendimport numpy as np
import seaborn as sns; sns.set(style="ticks", color_codes=True)import geopandas as gpd
import descartes #important for integrating Shapely Geometry with the Matplotlib Library
import mapclassify #You will need this to implement a Choropleth
import geoplot #You will need this to implement a Choropleth%matplotlib inlineA lot of the packages we will be using needs to be installed. For those having trouble installing GeoPandas, check out my article about this. Note that geoplot requires cartopy package and can be installed as any dependencies discussed in my article.
我們將要使用的許多軟件包都需要安裝。 對于那些在安裝GeoPandas時遇到麻煩的人,請查看有關此的文章 。 請注意,geoplot需要cartopy軟件包,并且可以作為本文中討論的任何依賴項進行安裝。
Loading Shapefiles
加載Shapefile
Shapefiles are needed to create “shape” to your geographical or political boundaries.
需要Shapefile來為您的地理或政治邊界創建“形狀”。
Download the shapefile and load it using GeoPandas.
下載shapefile并使用GeoPandas加載它。
An important note here when extracting the zip package: all the contents should be in one folder, even though you will simply be using the “.shp” file or else it won’t work. (this means that the “.cpg”, “.dbf”, “.prj” and so forth should be in the same location as your “.shp” file.
解壓縮zip包時的重要注意事項:所有內容都應放在一個文件夾中,即使您只是使用“ .shp”文件,否則它也將不起作用。 (這意味著“ .cpg”,“。dbf”,“。prj”等應與“ .shp”文件位于同一位置。
You can download the shapefile of the Philippines in gadm.org (https://gadm.org/).
您可以在gadm.org( https://gadm.org/ )中下載菲律賓的shapefile。
Note: You can likewise download the shapefiles from: PhilGIS (http://philgis.org/). It will probably be better for Philippine data though some of it is sourced with GADM, but let’s go with GADM as I have more experience in it.
注意:您也可以從以下位置下載shapefile:PhilGIS( http://philgis.org/ )。 盡管其中一些數據來自GADM,但對于菲律賓數據而言可能會更好一些,但是隨著我對GADM的更多了解,讓我們開始吧。
#The level of adminsitrative boundaries are given by 0 to 3; the details and boundaries get more detailed as the level increasecountry = gpd.GeoDataFrame.from_file("Shapefiles/gadm36_PHL_shp/gadm36_PHL_0.shp")
provinces = gpd.GeoDataFrame.from_file("Shapefiles/gadm36_PHL_shp/gadm36_PHL_1.shp")
cities = gpd.GeoDataFrame.from_file("Shapefiles/gadm36_PHL_shp/gadm36_PHL_2.shp")
barangay = gpd.GeoDataFrame.from_file("Shapefiles/gadm36_PHL_shp/gadm36_PHL_3.shp")At this point, you can view the shapefiles and examine the boundaries. You can do this by plotting the shapefiles.
此時,您可以查看shapefile并檢查邊界。 您可以通過繪制shapefile來實現。
#the GeoDataFrame of pandas has built-in plot which we can use to view the shapefilefig, axes = plt.subplots(2,2, figsize=(10,10));#Color here refers to the fill-color of the graph while
#edgecolor refers to the line colors (you can use words, hex values but not rgb and rgba)country.plot(ax=axes[0][0], color='white', edgecolor = '#2e3131');
provinces.plot(ax=axes[0][1], color='white', edgecolor = '#2e3131');
cities.plot(ax=axes[1][0], color='white', edgecolor = '#2e3131');
barangay.plot(ax=axes[1][1], color='white', edgecolor = '#555555');#Adm means administrative boundaries level - others refer to this as "political boundaries"
adm_lvl = ["Country Level", "Provincial Level", "City Level", "Barangay Level"]
i = 0
for ax in axes:
for axx in ax:
axx.set_title(adm_lvl[i])
i = i+1
axx.spines['top'].set_visible(False)
axx.spines['right'].set_visible(False)
axx.spines['bottom'].set_visible(False)
axx.spines['left'].set_visible(False)
Load Population Density Data
負荷人口密度數據
Population data and Density per SQ Kilometers are usually collected by the Philippine Statistics Authority (PSA).
人口數據和每SQ公里的密度通常由菲律賓統計局(PSA)收集。
You can do this with other demographics or macroeconomic data as the Philippines have been advancing on the provision of these. (Good Job Philippines!)
您可以使用其他人口統計數據或宏觀經濟數據來做到這一點,因為菲律賓一直在提供這些數據。 (菲律賓好工作!)
Because we want to amp up the challenge, let’s go with the most detailed one: the city and municipality level.
因為我們要應對挑戰,所以讓我們來探討最詳細的挑戰:城市和市政級別。
We first load the data and examine it:
我們首先加載數據并檢查它:
df = pd.read_excel(r'data\2015 Population Density.xlsx',
header=1,
skipfooter=25,
usecols='A,B,D,E',
names=["City", 'Population', "landArea_sqkms", "Density_sqkms"])Cleaning the Data
清理數據
Before we can proceed, we have to clean our data. We should:
在繼續之前,我們必須清除數據。 我們應該:
- drop rows with empty values 刪除具有空值的行
- remove non-alphabet characters after the names (* denoting footnotes) 刪除名稱后的非字母字符(*表示腳注)
- remove the words “(capital)” and “excluding” after each city name 在每個城市名稱后刪除“(大寫)”和“排除”
- remove leading and trailing spaces 刪除前導和尾隨空格
- and many more…. 還有很多…。
Cleaning really will take the bulk of the work when merging data with shapefiles.
將數據與shapefile合并時,清理確實會占用大量工作。
This is true for the Philippines, which have cities that are named similarly after one another. (e.g. San Isidro, San Juan, San Pedro, etc).
對于菲律賓來說,這是正確的,因為菲律賓的城市彼此之間有著相似的名字。 (例如,圣伊西德羅,圣胡安,圣佩德羅等)。
Let’s skip this part in the article but for those who would like to know how I did it, visit my Github repository. The code will apply to any PSA data on a municipality/city level.
讓我們跳過本文的這一部分,但是對于那些想知道我是如何做到的,請訪問我的Github存儲庫 。 該代碼將適用于市政/城市級別的任何PSA數據。
Exploratory Data Analysis
探索性數據分析
One of my favorite way to implement EDA is through a scatter plot. Let’s do it just to see which cities have high densities in chart form.
我最喜歡的實現EDA的方法之一是通過散點圖。 讓我們來看一下圖表中哪些城市的人口密度高。
Matplotlib is workable but I like the style of seaborn plots so I prefer to use it more often.
Matplotlib是可行的,但是我喜歡海洋情節的風格,因此我更喜歡使用它。
#First sort the dataframe according to Density from highest to lowest
sorted_df = df.sort_values("Density_sqkms", ascending=False,ignore_index=True )[:50]fig, ax = plt.subplots(figsize=(10,15));
scatter = sns.scatterplot(x=df.index, y=df.Density_sqkms)#Labeling the top 20 data (limiting so it won't get too cluttered)
#First sort the dataframe according to Density from highest to lowest
sorted_df = df.sort_values("Density_sqkms", ascending=False)[:20]#Since text annotations,overlap for something like this, let's import a library that adjusts this automatically
from adjustText import adjust_texttexts = [ax.text(p[0], p[1],"{},{}".format(sorted_df.City.loc[p[0]], round(p[1])),
size='large') for p in zip(sorted_df.index, sorted_df.Density_sqkms)];adjust_text(texts, arrowprops=dict(arrowstyle="->", color='r', lw=1), precision=0.01)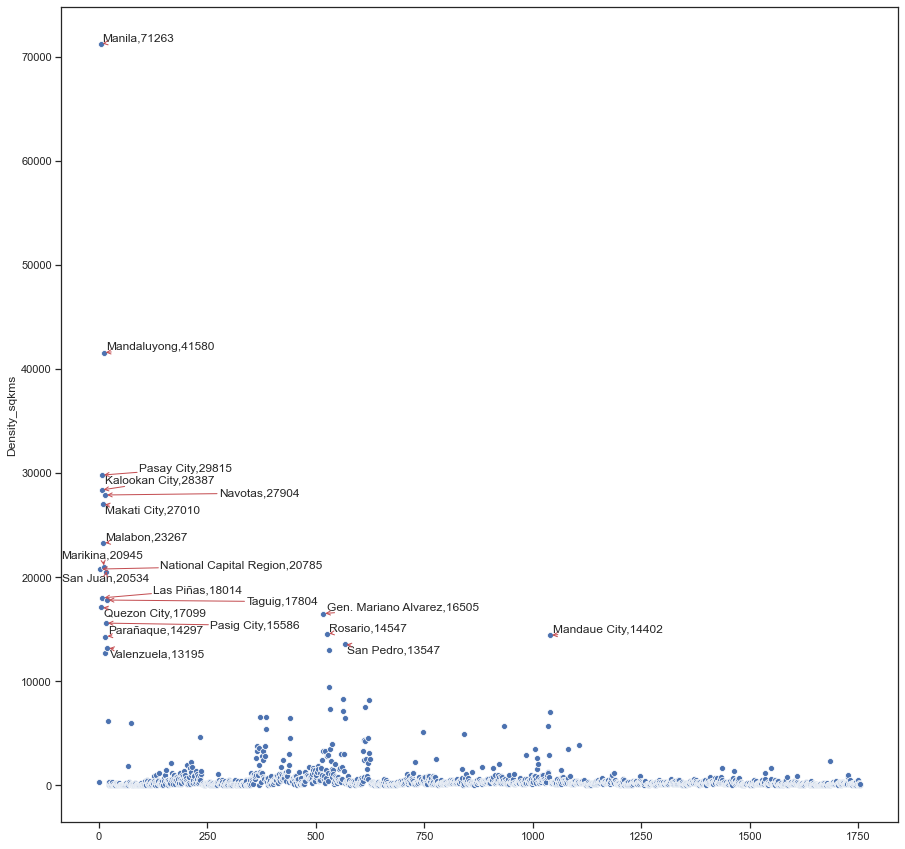
With this chart, we can already see which cities are above the average of “Nationa Capital Region”, namely, Mandaluyong, Pasay, Caloocan, Navotas, Makati, Malabon, and Marikina.
通過此圖表,我們已經可以看到哪些城市位于“國家首都地區”的平均水平之上,即曼達盧永 , 帕賽 , 卡盧奧坎 , 納沃塔斯 , 馬卡蒂 , 馬拉本和馬利基納 。
Within the top 20 as well, we can see that most of these cities are located in the “National Capital Region” and nearby provinces such as Laguna. Notice as well how the city of Manila is an outlier for this dataset.
同樣在前20名中,我們可以看到這些城市中的大多數都位于“國家首都地區”和附近的省份,例如拉古納。 還要注意,馬尼拉市是該數據集的離群值。
GeoPandas Visualization
GeoPandas可視化
The First Law of Geography, according to Waldo Tobler, is “everything is related to everything else, but near things are more related than distant things.”
根據沃爾多· 托伯勒 (Waldo Tobler)的說法, “地理第一定律”是“所有事物都與其他事物相關,但近處的事物比遠處的事物更相關”。
This is why in real estate, it is important to examine and visualize, how proximity affects values. Ultimately, GeoVisualization is one of the ways we can do this.
這就是為什么在房地產中,重要的是檢查和可視化鄰近性如何影響價值。 最終,GeoVisualization是我們執行此操作的方法之一。
We can already visualize our data using the builtin plot method of GeoPandas.
我們已經可以使用GeoPandas的內置繪圖方法來可視化我們的數據。
k = 1600 #I find that the more colors, the smoother the viz becomes as data points are spread across gradients
cmap = 'Blues'
figsize=(12,12)
scheme= 'Quantiles'ax = merged_df.plot(column='Density_sqkms', cmap=cmap, figsize=figsize,
scheme=scheme, k=k, legend=False)ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)#Adding Colorbar for legibility
# normalize color
vmin, vmax, vcenter = merged_df.Density_sqkms.min(), merged_df.Density_sqkms.max(), merged_df.Density_sqkms.mean()
divnorm = colors.TwoSlopeNorm (vmin=vmin, vcenter=vcenter, vmax=vmax)# create a normalized colorbar
cbar = plt.cm.ScalarMappable(norm=divnorm, cmap=cmap)
fig.colorbar(cbar, ax=ax)
# plt.show()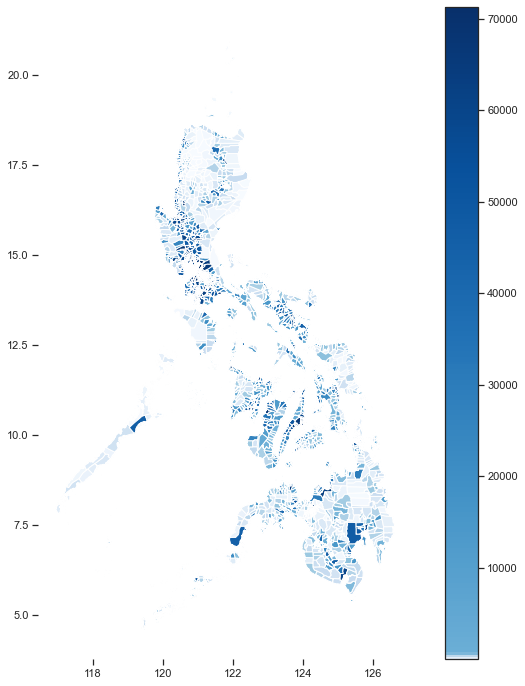
Some analysts prefer monotonic colormaps such as Blues or Greens, but when data is highly-skewed (having many outliers), I find it is better to use diverging colormaps.
一些分析人員更喜歡單調的顏色圖,例如藍色或綠色,但是當數據高度偏斜(具有許多離群值)時,我發現使用分散的顏色圖更好。
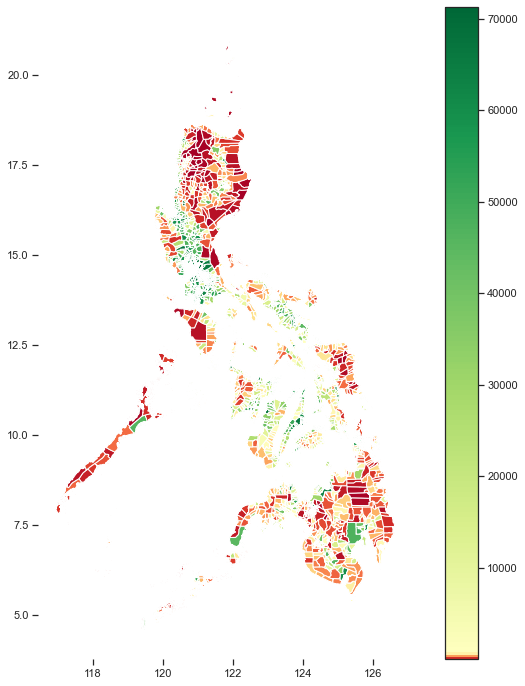
Using diverging colormaps, we can visualize the dispersion of density values. Even looking at the colorbar legend indicates how density values in the Philippines contain outliers on the high side.
使用發散的顏色圖,我們可以可視化密度值的分散。 即使查看色標圖例,也表明菲律賓的密度值如何包含較高的離群值。
Plotting using Geoplot
使用Geoplot進行繪圖
In addition to the built-in plot function of GeoPandas, you can plot this using geoplot.
除了GeoPandas的內置繪圖功能外,您還可以使用geoplot對其進行繪圖。
k = 1600
cmap = 'Greens'
figsize=(12,12)
scheme= 'Quantiles'geoplot.choropleth(
merged_df, hue=merged_df.Density_sqkms, scheme=scheme,
cmap=cmap, figsize=figsize
)In the next series, let’s try to plot this more interactively or use some machine learning algorithms to extract more insights.
在下一個系列中,讓我們嘗試以更具交互性的方式進行繪制,或者使用一些機器學習算法來提取更多的見解。
For the full code, check out my Github repository.
有關完整的代碼,請查看我的Github存儲庫 。
The code to preprocess data on the municipality and city level applies to other PSA reported statistics as well.
預處理市政和城市級別數據的代碼也適用于PSA報告的其他統計數據。
Let me know what dataset you would like for us to try and visualize in the future.
讓我知道您希望我們將來嘗試并可視化的數據集。
翻譯自: https://towardsdatascience.com/psvisualizing-the-philippines-population-density-using-geopandas-ab8190f52ed1
人口密度可視化
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388867.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388867.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388867.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Unity - Humanoid設置Bip骨骼導入報錯
)
python3openpyxl無法打開文件_Python3 處理excel文件(openpyxl庫)

Kubernetes - - k8s - v1.12.3 OpenLDAP統一認證


srpg 勝利條件設定_英雄聯盟獲勝條件
![[Egret][文檔]遮罩](http://pic.xiahunao.cn/[Egret][文檔]遮罩)
[Egret][文檔]遮罩

clob類型字段最大存儲長度_請教oracle的CLOB字段的最大長度?

機器學習 綜合評價_PyCaret:機器學習綜合

silverlight 3D 游戲開發

redis終端簡單命令

python中ix用法_Python中使用ix的數據幀子集

LintCode 16. 帶重復元素的排列

皮爾遜相關系數 相似系數_皮爾遜相關系數
![【洛谷】P1641 [SCOI2010]生成字符串(思維+組合+逆元)](http://pic.xiahunao.cn/【洛谷】P1641 [SCOI2010]生成字符串(思維+組合+逆元))
【洛谷】P1641 [SCOI2010]生成字符串(思維+組合+逆元)

Kubernetes持續交付-Jenkins X的Helm部署
暑期集訓--二進制(BZOJ5294)【線段樹】)
中國石油大學(華東)暑期集訓--二進制(BZOJ5294)【線段樹】

2018年10個最佳項目管理工具及鏈接

Java 8 新特性之Stream API
![[Python設計模式] 第17章 程序中的翻譯官——適配器模式](http://pic.xiahunao.cn/[Python設計模式] 第17章 程序中的翻譯官——適配器模式)