機器學習 綜合評價
Any Machine Learning project journey starts with loading the dataset and ends (continues ?!) with the finalization of the optimum model or ensemble of models for predictions on unseen data and production deployment.
任何機器學習項目的旅程都始于加載數據集,然后結束(繼續?!),最后確定最佳模型或模型集合,以預測看不見的數據和生產部署。
As machine learning practitioners, we are aware that there are several pit stops to be made along the way to arrive at the best possible prediction performance outcome. These intermediate steps include Exploratory Data Analysis (EDA), Data Preprocessing — missing value treatment, outlier treatment, changing data types, encoding categorical features, data transformation, feature engineering /selection, sampling, train-test split etc. to name a few — before we can embark on model building, evaluation and then prediction.
作為機器學習的從業者,我們意識到在達到最佳預測性能結果的過程中,有幾個進站。 這些中間步驟包括探索性數據分析(EDA),數據預處理-缺失值處理,離群值處理,更改數據類型,編碼分類特征,數據轉換,特征工程/選擇,采樣,訓練測試拆分等,僅舉幾例-在我們開始進行模型構建,評估然后進行預測之前。
We end up importing dozens of python packages to help us do this and this means getting familiar with the syntax and parameters of multiple function calls within each of these packages.
我們最終導入了數十個python軟件包來幫助我們完成此操作,這意味著要熟悉每個軟件包中的多個函數調用的語法和參數。
Have you wished that there could be a single package that can handle the entire journey end to end with a consistent syntax interface? I sure have!
您是否希望有一個包可以使用一致的語法接口來處理整個旅程,從頭到尾? 我肯定有!
輸入PyCaret (Enter PyCaret)
These wishes were answered with PyCaretpackage and it is now even more awesome with the release of pycaret2.0.
PyCaret軟件包滿足了這些愿望,現在pycaret2.0的發布pycaret2.0更加令人敬畏。
Starting with this Article, I will post a series on how pycaret helps us zip through the various stages of an ML project.
從本文開始,我將發布一系列有關pycaret如何幫助我們完成ML項目各個階段的文章。
安裝 (Installation)
Installation is a breeze and is over in a few minutes with all dependencies also being installed. It is recommended to install using a virtual environment like python3 virtualenv or conda environments to avoid any clash with other pre-installed packages.
安裝輕而易舉,幾分鐘后就結束了,同時還安裝了所有依賴項。 建議使用虛擬環境(例如python3 virtualenv或conda環境)進行安裝,以免與其他預裝軟件包沖突。
pip install pycaret==2.0
pip install pycaret==2.0
Once installed, we are ready to begin! We import the package into our notebook environment. We will take up a classification problem here. Similarly, the respective PyCaret modules can be imported for a scenario involving regression, clustering, anomaly detection, NLP and Association rules mining.
安裝完成后,我們就可以開始了! 我們將包導入到筆記本環境中。 我們將在這里處理分類問題。 同樣,可以針對涉及回歸,聚類,異常檢測,NLP和關聯規則挖掘的方案導入相應的PyCaret模塊。
We will use the titanic dataset from kaggle.com. You can download the dataset from here.
我們將使用來自kaggle.com的titanic數據集。 您可以從此處下載數據集。

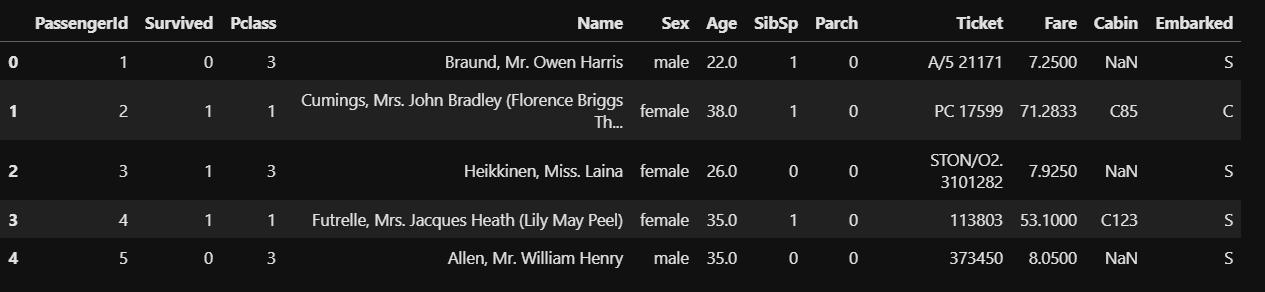
Let's check the first few rows of the dataset using the head() function:
讓我們使用head()函數檢查數據集的前幾行:

建立 (Setup)
The setup() function of pycaret does most — correction, ALL, of the heavy-lifting, that normally is otherwise done in dozens of lines of code — in just a single line!
pycaret的setup()函數pycaret完成大部分工作-校正,全部進行繁重的工作,否則通常只需要一行幾十行代碼即可完成!

We just need to pass the dataframe and specify the name of the target feature as the arguments. The setup command generates the following output.
我們只需要傳遞數據框并指定目標要素的名稱作為參數即可。 setup命令生成以下輸出。
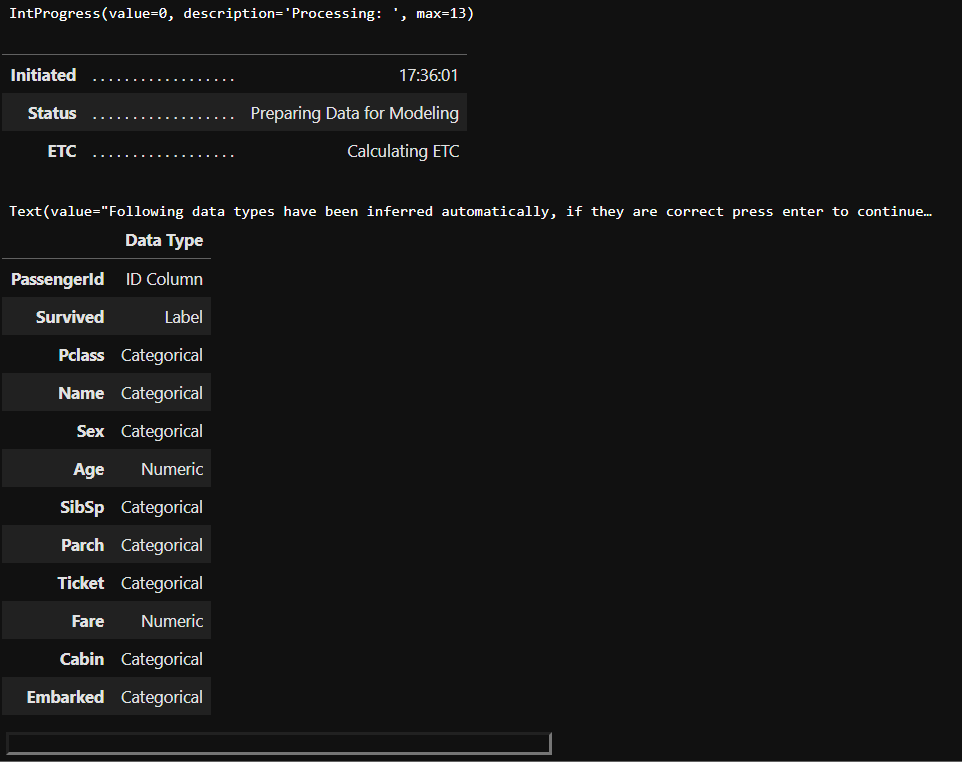
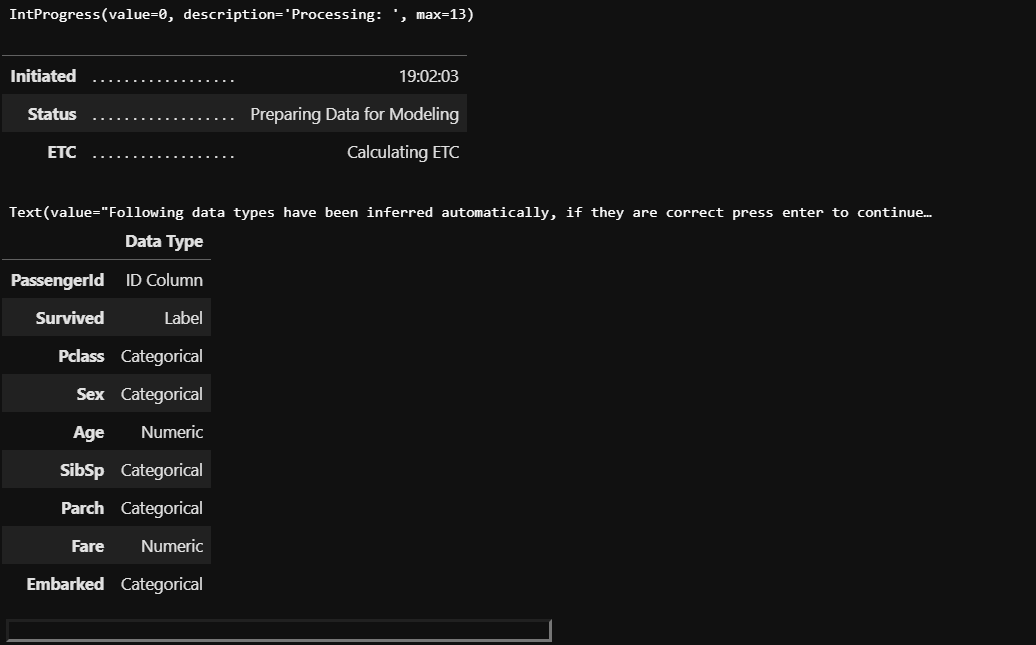
setup has helpfully inferred the data types of the features in the dataset. If we agree to it, all we need to do is hit Enter . Else, if you think the data types as inferred by setup is not correct then you can type quit in the field at the bottom and go back to the setup function to make changes. We will see how to do that shortly. For now, lets hit Enter and see what happens.
setup有助于推斷數據集中要素的數據類型。 如果我們同意,則只需按Enter 。 否則,如果您認為由setup程序推斷出的數據類型不正確,則可以在底部的字段中鍵入quit ,然后返回到setup功能進行更改。 我們將很快看到如何做。 現在,讓我們Enter ,看看會發生什么。
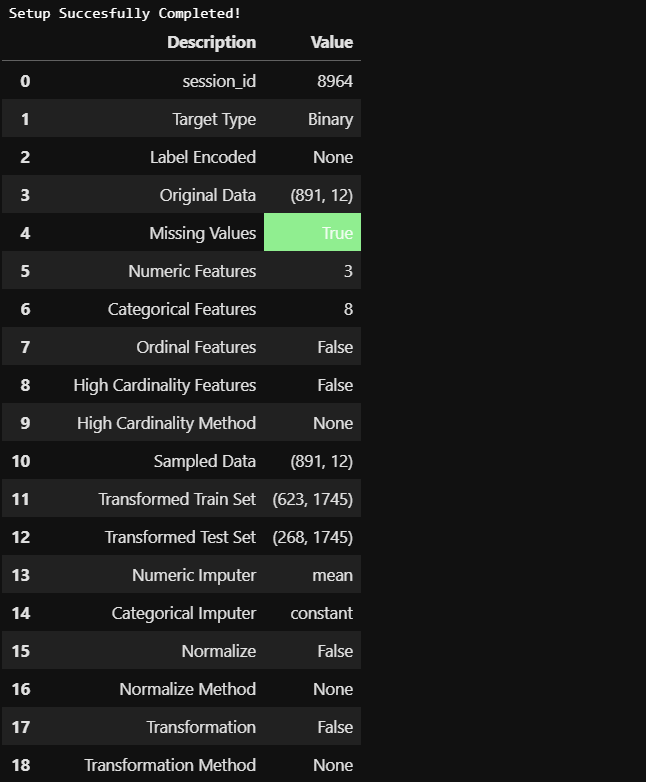
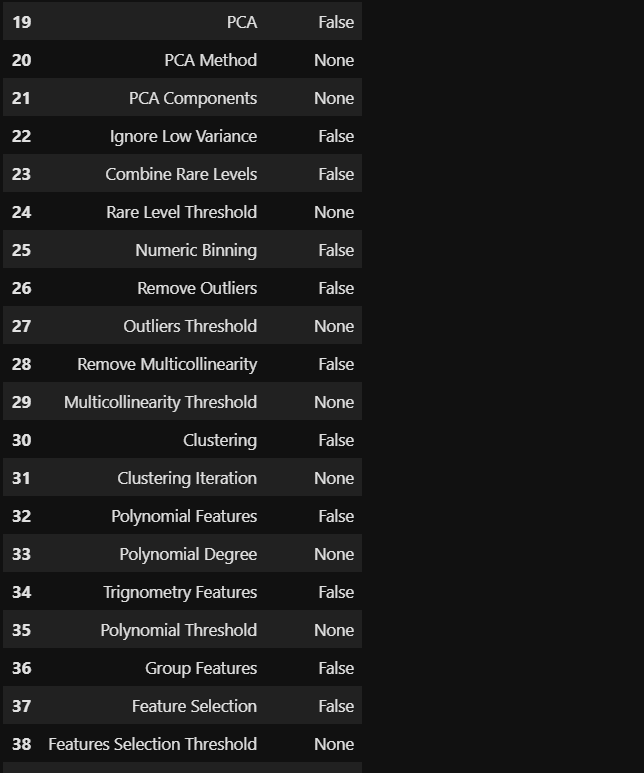
Whew! A whole lot seems to have happened under the hood in just one line of innocuous-looking code! Let's take stock:
ew! 似乎只有一行無害的代碼在幕后發生了很多事情! 讓我們盤點一下:
- checked for missing values 檢查缺失值
- identified numeric and categorical features 確定的數字和分類特征
- created train and test data sets from the original dataset 從原始數據集中創建訓練和測試數據集
- imputed missing values in continuous features with mean 連續特征中的插補缺失值
- imputed missing values in categorical features with a constant value 具有恒定值的分類特征中的推定缺失值
- done label-encoding 完成標簽編碼
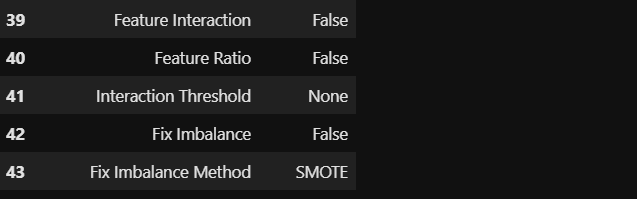
- ..and a whole host of other options seem to be available including outlier treatment, data scaling, feature transformation, dimensionality reduction, multi-collinearity treatment, feature selection and handling imbalanced data etc.! ..以及似乎還有許多其他選擇,包括異常值處理,數據縮放,特征轉換,降維,多重共線性處理,特征選擇和處理不平衡數據等!
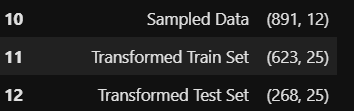
But hey! what is that on lines 11 & 12? The number of features in the train and test datasets are 1745? Seems to be a case of label encoding gone berserk most probably from the categorical features like name, ticket and cabin. Further in this article and in the next, we will look at how we can control the setup as per our requirements to address such cases proactively.
但是,嘿! 第11和12行是什么? 訓練和測試數據集中的要素數量為1745? 似乎是標簽編碼的一種情況,很可能是從name , ticket和cabin等分類特征中消失了。 在本文的下一部分和下一部分中,我們將研究如何根據我們的要求控制設置,以主動解決此類情況。
定制setup (Customizing setup)
To start with how can we exclude features from model building like the three features above? We pass the variables which we want to exclude in the ignore_features argument of the setup function. It is to be noted that the ID and DateTime columns, when inferred, are automatically set to be ignored for modelling.
首先,我們如何像上面的三個功能那樣從模型構建中排除功能? 我們在setup函數的ignore_features參數中傳遞要排除的變量。 要注意的是,ID和DateTime列在推斷時會自動設置為忽略以進行建模。
Note below that pycaret, while asking for our confirmation has dropped the above mentioned 3 features. Let's click Enter and proceed.
請注意,在pycaret下方,要求我們確認時已刪除了上述3個功能。 讓我們單擊Enter并繼續。
In the resultant output (the truncated version is shown below), we can see that post setup, the dataset shape is more manageable now with label encoding done only of the remaining more relevant categorical features:
在結果輸出中(截斷的版本如下所示),我們可以看到設置后,現在僅使用其余更相關的分類特征進行標簽編碼,就更易于管理數據集形狀:
In the next Article in this series we will look in detail at further data preprocessing tasks we can achieve on the dataset using this single setup function of pycaret by passing additional arguments.
在本系列的下一篇文章中,我們將詳細介紹通過使用pycaret的單個setup功能通過傳遞附加參數可以對數據集完成的進一步數據預處理任務。
But before we go, let’s do a flash-forward to the amazing model comparison capabilities of pycaret using the compare_model() function.
但是在開始之前,讓我們使用compare_model()函數pycaret驚人的模型比較功能。
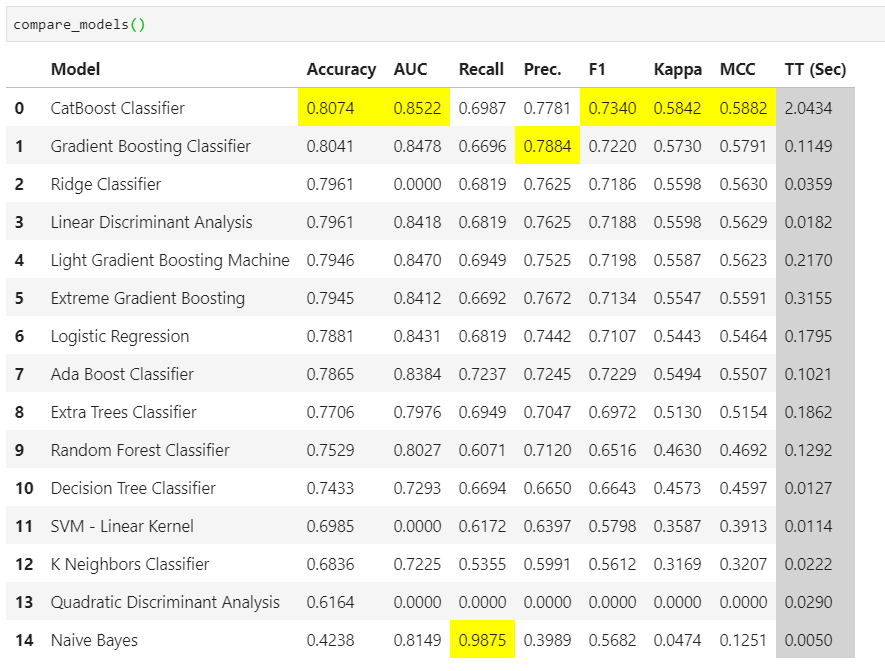
Boom! All it takes is just compare_models() to get the results of 15 classification modelling algorithms compared across various classification metrics on cross-validation. At a glance, we can see that CatBoost classifier performs best across most of the metrics with Naive-Bayes doing well on recall and Gradient Boosting on precision. The top-performing model for each metric is highlighted automatically by pycaret.
繁榮! 它所compare_models()只是compare_models()來獲得15種分類建模算法的結果,這些算法在交叉驗證的各個分類指標之間進行了比較。 一目了然,我們可以看到CatBoost分類器在大多數指標上表現最佳,其中Naive-Bayes在召回率方面表現出色,而在精度方面則表現出Gradient Boosting 。 pycaret自動突出顯示每個指標的性能最高的模型。
Depending on the model evaluation metric(s) we are interested in pycaret helps us to straightaway zoom in on the top-performing model which we can further tune using the hyper-parameters. More on this in the upcoming Articles.
根據模型評估指標,我們對pycaret感興趣,可以幫助我們Swift放大性能最高的模型,我們可以使用超參數進一步對其進行調整。 在即將到來的文章中對此有更多的了解。
In conclusion, we have briefly seen glimpses of how pycaret can help us to fast track through the ML project life cycle through minimal code combined with extensive and comprehensive customization of the critical data pre-processing stages.
總之,我們已經簡要了解了pycaret如何通過最少的代碼以及對關鍵數據預處理階段的廣泛而全面的自定義,可以幫助我們快速跟蹤ML項目生命周期。
You may also be interested in my other articles on awesome packages that use minimal code to deliver maximum results in Exploratory Data Analysis(EDA) and Visualization.
您可能還對我的其他有關超棒軟件包的文章感興趣,這些文章使用最少的代碼來在探索性數據分析(EDA)和可視化中提供最大的結果。
Thanks for reading and would love to hear your feedback. Cheers!
感謝您的閱讀,并希望聽到您的反饋。 干杯!
翻譯自: https://towardsdatascience.com/pycaret-the-machine-learning-omnibus-dadf6e230f7b
機器學習 綜合評價
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388858.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388858.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388858.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

silverlight 3D 游戲開發

redis終端簡單命令

python中ix用法_Python中使用ix的數據幀子集

LintCode 16. 帶重復元素的排列

皮爾遜相關系數 相似系數_皮爾遜相關系數
![【洛谷】P1641 [SCOI2010]生成字符串(思維+組合+逆元)](http://pic.xiahunao.cn/【洛谷】P1641 [SCOI2010]生成字符串(思維+組合+逆元))
【洛谷】P1641 [SCOI2010]生成字符串(思維+組合+逆元)

Kubernetes持續交付-Jenkins X的Helm部署
暑期集訓--二進制(BZOJ5294)【線段樹】)
中國石油大學(華東)暑期集訓--二進制(BZOJ5294)【線段樹】

2018年10個最佳項目管理工具及鏈接

Java 8 新特性之Stream API
![[Python設計模式] 第17章 程序中的翻譯官——適配器模式](http://pic.xiahunao.cn/[Python設計模式] 第17章 程序中的翻譯官——適配器模式)
[Python設計模式] 第17章 程序中的翻譯官——適配器模式

Ubuntu中NS2安裝詳細教程


帶你利用一句話完成轉場動畫

14.vue路由腳手架

工程師、產品經理、數據工程師是如何一起工作的?

linux-buff/cache過大導致內存不足-程序異常
)
Android 適配(一)
)
Source Insight 創建工程(linux-2.6.22.6內核源碼)
