盛嚴謹,嚴謹,再嚴謹。
The human resources industry relies heavily on a wide range of assessments to support its functions. In fact, to ensure unbiased and fair hiring practices the US department of labor maintains a set of guidelines (Uniform Guidelines) to aid HR professionals in their assessment development ventures.
人力資源行業嚴重依賴各種評估來支持其職能。 實際上,為了確保公正和公平的雇用做法,美國勞工部維護了一套準則( 統一準則 ),以協助HR專業人士進行評估開發。
Personality assessments are often used in selection batteries to determine cultural fit into a company. Cognitive ability (ie. IQ) tests are consistently found to be the best overall predictor of job performance across all types and levels of jobs (Schmidt & Hunter, 1998). Structured interviews are used extensively in hiring decisions as they help to remove bias by standardizing the question and scoring. Performance reviews use rigorous Likert assessments that ask managers and co-workers to rate employees of their performance (ie. behaviorally anchored rating scales). Employee engagement surveys assess the extent employees feel satisfaction, passion, effort, and commitment to their employer and job. Last but not least, employee exit surveys are often employed upon the termination of an employee in order to determine how the employee felt about a range of topics related to the organization.
個性評估通常用于選擇人員,以確定公司的文化契合度。 一直以來,認知能力(即智商)測試是所有類型和級別的工作績效的最佳總體預測指標(Schmidt&Hunter,1998)。 結構化面試廣泛用于招聘決策,因為它們有助于通過標準化問題和評分來消除偏見。 績效評估使用嚴格的李克特評估,要求經理和同事對員工的績效進行評估(即行為錨定的評估量表)。 員工敬業度調查可評估員工對自己的雇主和工作的滿意度,熱情,努力和承諾的程度。 最后但并非最不重要的一點是,通常在員工離職后進行員工離職調查,以確定員工對與組織相關的一系列主題的感覺。
This extensive use of employee assessment has given rise to a multi-billion dollar industry specializing in the development of a wide range of tests. Let’s focus our attention on employee attitude surveys as they form a very large segment of this industry. If one is to purchase a survey how can you be sure you are getting a quality product? Any reputable developer should supply you with not only a manual but also a validation report which outlines the steps taken to make sure the survey is actually measuring what it’s meant to measure.
員工評估的這種廣泛使用已催生了數十億美元的行業,專門從事各種測試的開發。 讓我們將注意力集中在員工態度調查上,因為它們構成了該行業的很大一部分。 如果要購買一份調查表,如何確定獲得優質產品? 任何有信譽的開發人員都不僅應向您提供手冊,而且還應提供驗證報告,該報告概述了為確保調查實際在測量所要測量的內容而采取的步驟。
In this article, I would like to examine an employee exit survey and determine the quality of the survey based on a selected few metrics. Therefore, when you are handed a validation report from a survey vendor you will know and understand the metrics needed to make an informed purchase.
在本文中,我想檢查一下員工離職調查,并根據選定的一些指標來確定調查的質量。 因此,當您從調查供應商處收到驗證報告時,您將了解并了解進行明智購買所需的度量。
調查發展過程 (Survey Development Process)
Before we jump into our metrics and code, let’s take a few mins to review how a statistically rigorous survey is developed and validated.
在我們進入指標和代碼之前,讓我們花一些時間回顧一下如何開發和驗證統計上嚴格的調查。
The process begins with a question.
該過程從一個問題開始。
For example: “Are my employees happy with their jobs and the company?”
例如:“我的員工對他們的工作和公司滿意嗎?”
- How do we define “Happiness”? Before we can start writing survey questions we need to operationally define “happiness”. We scour the literature for employee happiness research. Undoubtedly, you will arrive at topics such as employee satisfaction, commitment, and engagement. You will read dozens of studies proposing unique models of employee satisfaction. Hackman & Oldham’s Job Characteristics model is often sited when developing employee satisfaction surveys for its comprehensiveness and statistical validity. Validity in the sense that many researchers have adopted this model in their research and/or assessments and found that it holds true. 我們如何定義“幸福”? 在開始寫調查問題之前,我們需要在操作上定義“幸福”。 我們搜尋有關員工幸福感研究的文獻。 毫無疑問,您將遇到諸如員工滿意度,承諾和敬業度等主題。 您將閱讀數十項提出獨特的員工滿意度模型的研究。 Hackman&Oldham的工作特征模型通常在開發員工滿意度調查時因其全面性和統計有效性而使用。 從許多研究人員在他們的研究和/或評估中采用這種模型的意義上講,其有效性是正確的。
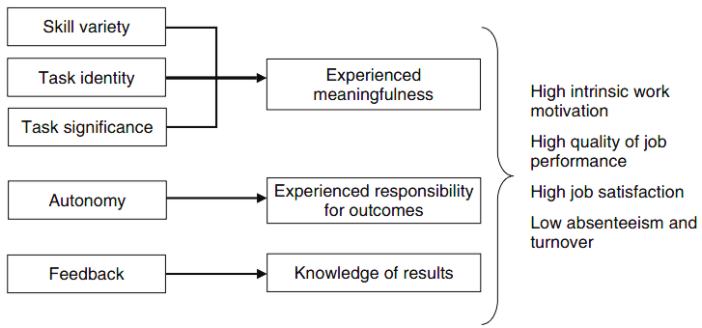
- The selected model will serve as the basis for the questions or items composing the survey. Depending on the length of the survey, we will write 3–10 items for each component (ie. skill variety, task identity, autonomy, etc.) of the model. We write multiple questions to confirm the sentiment of an employee on each model component. We will be focusing on quantitative items that require the employee to select a label on a continuous scale which corresponds with their internal attitude (ie. Likert-Scale). 選擇的模型將作為構成調查的問題或項目的基礎。 根據調查的時間長短,我們將為模型的每個組件(即技能種類,任務標識,自主權等)編寫3-10個項目。 我們編寫多個問題以確認員工在每個模型組件上的情緒。 我們將專注于要求員工選擇與其內部態度相對應的連續比例的標簽(即李克特量表)的定量項目。
- Each question can be validated (content validation) by allowing prominent researchers in the area of study (ie. employee satisfaction) to scrutinize each question. Content validity is very often cited in legal proceedings when an employee is under litigation for improper hiring decisions. Other forms of validation include construct and criterion validity. 通過允許研究領域中的杰出研究人員(即員工滿意度)對每個問題進行審查,可以驗證每個問題(內容驗證)。 當員工因不當雇用決定而受到訴訟時,通常會在法律訴訟中提及內容有效性。 驗證的其他形式包括構造和準則有效性。
- Upon completion of the first draft, a pilot test is conducted with a sample of employees closely resembling the full employee population. It is important to obtain a large and representative sample in order to be confident in the results. 初稿完成后,將對與全體員工非常相似的員工樣本進行試點測試。 重要的是要獲得大量有代表性的樣本,以便對結果有信心。
- Once the survey has been administered and the data collected, certain psychometric properties need to be examined, namely reliability and validity. Based on the psychometric results the survey is revised until optimal psychometrics can be achieved. 一旦完成了調查并收集了數據,就需要檢查某些心理測量特性,即可靠性和有效性。 根據心理測量結果,對調查進行修訂,直到可以實現最佳心理測量。
員工離職調查示例 (Employee Exit Survey Example)
First and foremost, this fictional dataset and its results should be treated as such, fictional. Secondly, termination reason (ie. voluntary, involuntary, retirement, etc.) have been omitted from the loaded dataset as this article will focus exclusively on the psychometric properties on the Likert-scale questions.
首先,這個虛構的數據集及其結果應被視為虛構的。 其次,已終止的原因(即自愿,非自愿,退休等)已從加載的數據集中省略,因為本文將只關注Likert量表問題的心理計量學特性。
import pandas as pd
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
import pingouin as pg
from factor_analyzer import FactorAnalyzer
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
from factor_analyzer import ConfirmatoryFactorAnalyzer, ModelSpecificationParserimport warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', None)
%matplotlib inlinewith open('likert.csv') as f:
likert_items = pd.read_csv(f)
f.close()likert_items.head()
len(likert_items), likert_items.describe().T
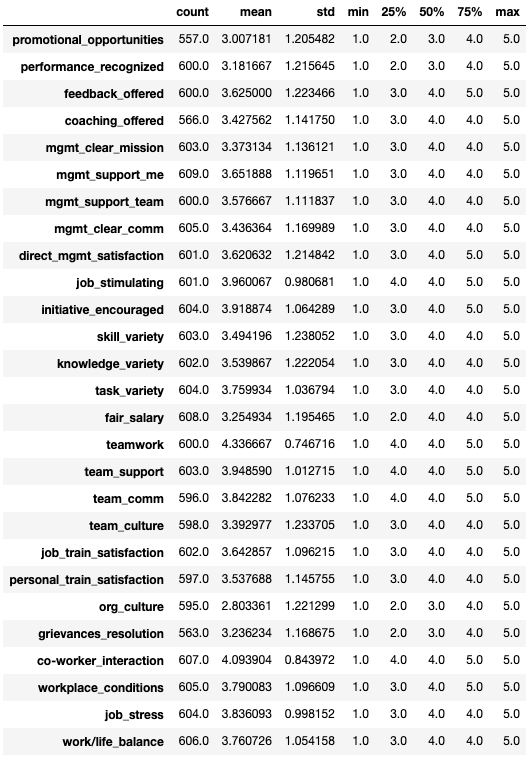
Upon loading our libraries, we have a dataset of about 702 employees who answered 27 Likert-type questions where 1 is strongly disagree and 5 is strongly agree. The questions asked terminated employees on their perceptions on promotional opportunities, manager satisfaction, job satisfaction, training, and work/life balance.
加載我們的圖書館后,我們有大約702名員工的數據集,它們回答了27個Likert類型的問題,其中1個強烈不同意,5個強烈同意。 提出的問題終止了員工對晉升機會,經理滿意度,工作滿意度,培訓和工作/生活平衡的看法。
We have to acknowledge the fact that terminated employees are not required to fill out an exit survey. It is completely at their discretion and as such the results from such survey may be skewed
我們必須承認以下事實:被解雇的員工不需要填寫退出調查。 這完全由他們自己決定,因此該調查的結果可能會有所偏差。
潛在因素 (Underlying Latent Factors)
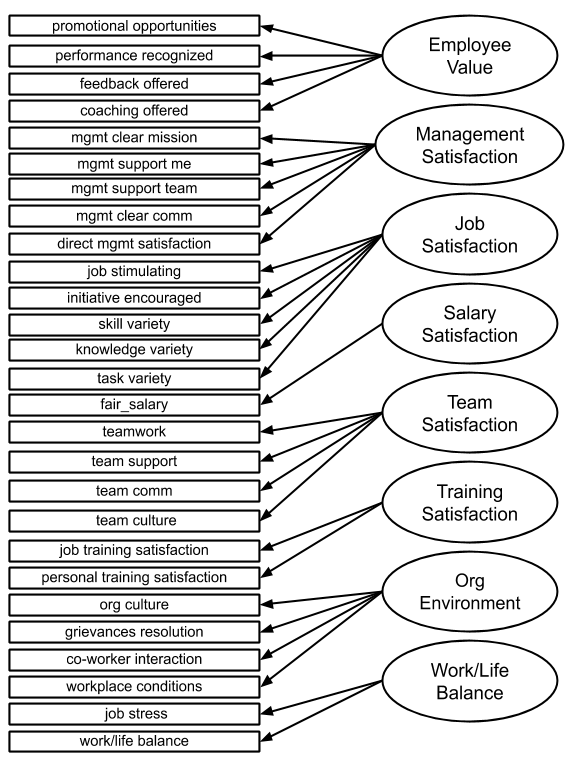
As discussed above, carefully designed surveys have their roots in validated scholarly models and this survey is no different. The 27 individual items have been developed to assess 8 underlying or latent factors.
如上所述,精心設計的問卷調查源于經過驗證的學術模型,該問卷調查沒有什么不同。 已經開發了27個單獨的項目來評估8個潛在或潛在因素。
相關性 (Correlations)
likert_corr = likert_items.corr()plt.figure(figsize=(25,15))
mask = np.zeros_like(likert_corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
plt.figure(figsize=(70,40))
plt.xticks(fontsize=50)
plt.yticks(fontsize=50)
sns.heatmap(likert_corr, cmap='coolwarm', annot=True,
fmt=".2f", annot_kws={'size': 40, 'color': 'black'}, linewidths=2,
vmin=-0.5, mask=mask)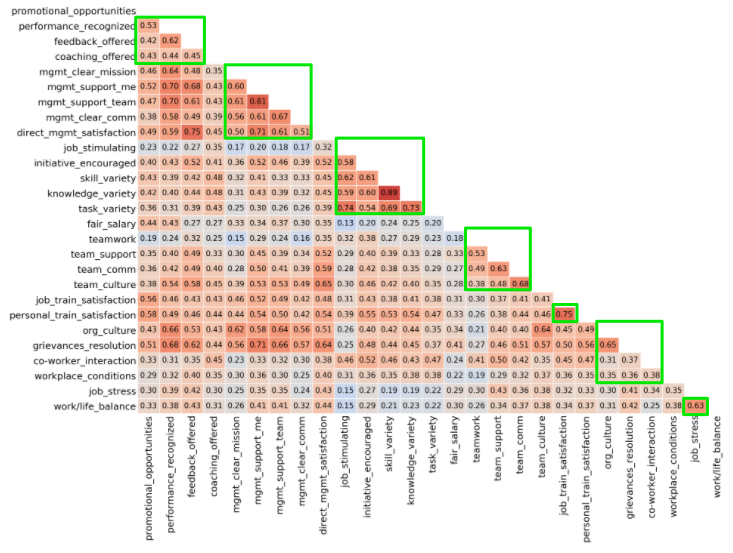
When dealing with quantitative questions the first tool at our disposal is the trusty correlation. A correlation matrix will give us the first clues as to the psychometric quality of our survey. The correlations highlighted in green are those of the items meant to measure the same underlying latent construct. These correlations should retain a relatively high correlation (0.5 to 0.7) as that would indicate the items are measuring several unique sub-components of a larger construct. However, if the correlations are too large (0.7+) that would signify the items might be measuring very similar or even the same constructs. We ultimately want our questions to be assessing different sub-components of a larger factor such as “Job Satisfaction”.
處理定量問題時,我們可以使用的第一個工具是可信賴的相關性。 相關矩陣將為我們提供有關調查的心理計量質量的第一個線索。 綠色突出顯示的相關性是那些旨在測量相同潛在潛在構造的項目的相關性。 這些相關性應保持相對較高的相關性(0.5到0.7),因為這將表明這些項目正在測量較大構造的幾個唯一子組件。 但是,如果相關關系太大(0.7+),則表示項目可能測量的結構非常相似甚至相同。 我們最終希望我們的問題是評估更大因素的不同子成分,例如“工作滿意度”。
On the other hand, correlations outside of the highlighted areas should remain as low as possible. That would indicate that the items are measuring vastly different constructs. For example, the high correlation between direct_mgmt_satisfaction and feed_offered (0.75) is rather discouraging as they are measuring different latent constructs (employee value and management satisfaction). On the other hand, this correlation also gives us a glimpse into a miss-classification of the “feedback_offered” item as it is the manager that most often provides constructive feedback and, therefore, one might reason this item is actually assessing management satisfaction instead.
另一方面,突出顯示區域之外的相關性應保持盡可能低。 這將表明這些項目正在衡量截然不同的結構。 例如,direct_mgmt_satisfaction和feed_offered(0.75)之間的高度相關性令人沮喪,因為它們正在測量不同的潛在構造(員工價值和管理滿意度)。 另一方面,這種相關性也使我們瞥見了“ feedback_offered”項目的錯誤分類,因為經理經常提供建設性的反饋,因此,有人可能會認為該項目實際上是在評估管理滿意度。
Overall, looking at the correlation matrix it would seem management satisfaction, job satisfaction, team satisfaction, training satisfaction, and work/life balance are relatively strong latent factors. On the other hand, employee value and organizational environment are rather weak. Finally, salary satisfaction is composed of one question.
總體而言,從相關矩陣中可以看出,管理滿意度,工作滿意度,團隊滿意度,培訓滿意度以及工作/生活平衡是相對較強的潛在因素。 另一方面,員工價值和組織環境相對薄弱。 最后,薪水滿意度由一個問題組成。
可靠性 (Reliability)
Reliability is a measure of consistency. In other words, if someone were to take the same personality assessment multiple times their scores should not vary a large amount. The most prominent reliability metric when developing surveys is Cronbach’s Alpha and it’s a measure of internal consistency. The Alpha assumes unidimensional or that the items passed into its function are measuring one factor, therefore, we need to calculate Alpha for each latent factor separately.
可靠性是一致性的度量。 換句話說,如果某人要多次進行相同的人格評估,那么他們的分數應該不會相差很大。 進行調查時,最突出的可靠性指標是Cronbach的Alpha ,它是內部一致性的一種度量。 Alpha假定是一維的,或者傳遞到其函數中的項正在測量一個因子,因此,我們需要針對每個潛在因子分別計算Alpha。
valued = likert_items[['promotional_opportunities', 'performance_recognized', 'feedback_offered','coaching_offered']]mgmt_sati = likert_items[['mgmt_clear_mission','mgmt_support_me',
'mgmt_support_team', 'mgmt_clear_comm', 'direct_mgmt_satisfaction']]job_satisfaction = likert_items[['job_stimulating', 'initiative_encouraged', 'skill_variety','knowledge_variety', 'task_variety']]team_satisfaction = likert_items[['teamwork','team_support', 'team_comm', 'team_culture']]training_satisfaction = likert_items[['job_train_satisfaction',
'personal_train_satisfaction']]org_environment = likert_items[['org_culture', 'grievances_resolution', 'co-worker_interaction', 'workplace_conditions']]work_life_balance = likert_items[['job_stress','work/life_balance']]salary_satisfaction = likert_items[['fair_salary']]dict = {'valued': valued, 'mgmt_sati': mgmt_sati,
'job_satisfaction': job_satisfaction,
'team_satisfaction': team_satisfaction,
'training_satisfaction': training_satisfaction,
'org_condition': org_condition,
'work_life_balance': work_life_balance}for i in dict:
print('{} Alpha: {}'.format(i, pg.cronbach_alpha(data=dict[i], nan_policy='listwise'))
Mgmt satisfaction, job satisfaction, team satisfaction, and training satisfaction all exhibit high to very high alpha coefficients (0.8+). High alpha results signify the items are measuring the same underlying construct. Employee valued, org environment, and work-life balance resulted in lower alpha coefficients which means the items can be improved to better measure their constructs. We need at least 2 items to measure alpha therefore, salary_satisfaction was not included in this analysis.
管理滿意度,工作滿意度,團隊滿意度和培訓滿意度都表現出高到非常高的alpha系數(0.8+)。 高alpha結果表示這些項目正在衡量相同的基礎結構。 員工重視,組織環境和工作與生活的平衡導致較低的alpha系數,這意味著可以改進這些項目以更好地衡量其構造。 我們至少需要2個項目來衡量Alpha,因此本分析中不包括salary_satisfaction。
Another commonly used reliability measure is “Test-Retest Reliability”. The survey is administered to the same sample multiple times and the scores are compared to determine consistency.
另一個常用的可靠性度量是“重測可靠性”。 多次對同一樣本進行調查,并比較分數以確定一致性。
因子分析 (Factor Analysis)
探索性因素分析(EFA) (Exploratory Factor Analysis (EFA))
Factor analysis or more specifically Exploratory Factor Analysis is often used in the survey development process. It is used to conduct a preliminary exploration of the assessment during the development stage. Factor analysis is a data reduction technique that attempts to extract the commonly held variance between features into a factor. In other words, survey items that are meant to assess a common latent factor will covary together. Covary in the sense that if someone answers “strongly agree” on the first question they will most likely answer in a similar fashion on a different question which is meant to assess the underlying latent factor.
因子分析或更具體地說是探索性因子分析經常在調查開發過程中使用。 它用于在開發階段對評估進行初步探索。 因子分析是一種數據縮減技術,試圖將要素之間的共同保留的方差提取到因子中。 換句話說,旨在評估共同潛在因素的調查項目將同時出現。 某種意義上說,如果有人回答第一個問題“強烈同意”,那么他們很可能會以類似的方式回答另一個問題,以評估潛在的潛在因素。
EFA vs PCA
全民主場迎戰PCA
EFA is similar to a PCA (principal component analysis) in terms of dimensionality reduction but it has certain differences:
EFA在降維方面類似于PCA(主要成分分析),但存在某些差異:
- An EFA identifies latent factors that can be interpreted because the latent factors were developed on purpose. EFA識別可以解釋的潛在因素,因為潛在因素是有意開發的。
- PCA attempts to explain the maximum variance (PC1 will hold most variance) which EFA attempts to explain the covariance among the features. PCA試圖解釋最大方差(PC1將保持最大方差),而EFA試圖解釋特征之間的協方差。
- PCA performs its analysis without regard for underlying latent constructs, it simply wants to account for all the variance in the features. PCA進行分析時不考慮潛在的潛在結構,它只想考慮特征中的所有差異。
- PCA components are orthogonal (uncorrelated) by design but EFA factors don’t need to be (depending on the rotation). PCA組件在設計上是正交的(不相關),但不需要EFA因子(取決于旋轉)。
Bartlett’s Test of Sphericity
巴特利特的球性測試
Before attempting to use a factor analysis one should conduct the “Bartlett’s Test of Sphericity” which examines whether or not there are multiple features that can be reduced to latent factors. The result of Bartlett’s test is significant (p=0.00) which means the data can be reduced and we can continue with the factor analysis.
在嘗試使用因子分析之前,應進行“巴特利特球性測試”,以檢查是否存在可以簡化為潛在因子的多個特征。 Bartlett檢驗的結果很顯著(p = 0.00),這意味著數據可以減少,我們可以繼續進行因子分析。
chi_square_value,p_value=calculate_bartlett_sphericity(likert_items)
chi_square_value, p_value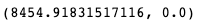
factor = FactorAnalyzer()
factor.fit(likert_items)ev, v = factor.get_eigenvalues()
plt.figure(figsize=(15,10))
plt.plot(range(1, likert_items.shape[1]+1), ev, marker='X', markersize=12)
plt.xlabel('# of Factors')
plt.ylabel('Eigenvalues')
plt.grid()
plt.show()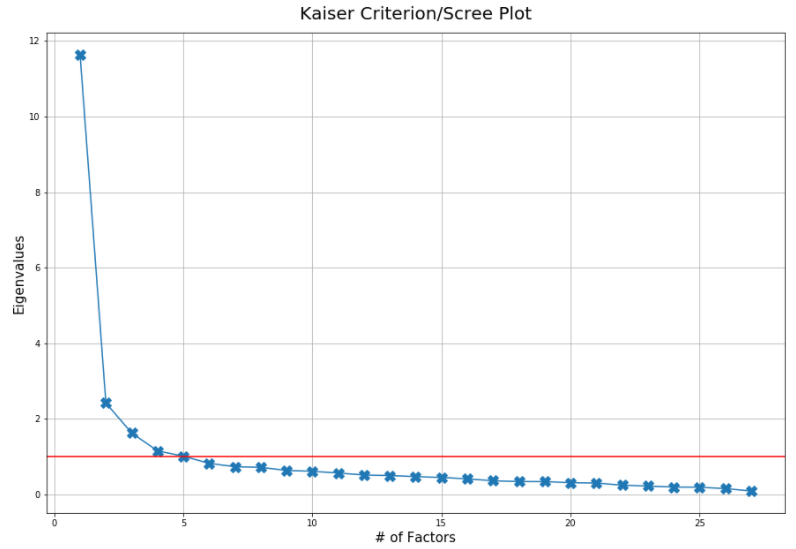
We can use a scree plot to determine the optimal number of factors. The Kaiser criteria mentions a factor should account for a certain amount of variance for it to be considered a valid factor. We typically set the cut-off at 1 eigenvalue.
我們可以使用碎石圖來確定最佳因素數。 凱澤(Kaiser)標準提到因素應考慮一定數量的方差才能被視為有效因素。 我們通常將截止值設置為1個特征值。
factor = FactorAnalyzer(8, rotation='promax', method='ml', impute='mean')factor.fit(likert_items)
factors = factor.loadings_
factors_df = pd.DataFrame(factors, columns=['factor1', 'factor2', 'factor3','factors4','factor5', 'factor6', 'factor7', 'factor8'] index=likert_items.columns)factors_df.style.bar(subset=['factor1', 'factor2', 'factor3',
'factors4','factor5', 'factor6','factor7','factor8'], color='green')
Despite the scree plot of 5 optimal factors, we know the survey was developed to contain 8 latent factors. Finally, the cut-off value for loading scores is rather subjective but we are going to use 0.5.
盡管有5個最佳因素的散布圖,但我們知道該調查包含8個潛在因素。 最后,載入分數的臨界值相當主觀,但我們將使用0.5。
Factor 1: All but one “management satisfaction” item seem to load very highly on this factor. We also have items from “employee_valued”, and “org_environment” loading highly onto Factor 1. Furthermore, it would seem the items assessing the “management satisfaction” construct situate the survey taker in a holistic organizational perspective or mindset when answering the questions. In other words, the individual is asked to think about management holistically. However, when the survey taker comes to the “direct_mgmt_satisfaction” question their perspective is narrowed and despite enjoying the broader organizational leadership their opinion of their direct manager might differ. This might explain why the “direct_mgmt_satisfaction” item loads so low on factor 1.
因素1:除一項“管理滿意度”項目外,其他因素似乎都非常重視這一因素。 我們還從“員工價值”和“組織環境”兩個項目中高度關注因素1。此外,似乎在評估“管理滿意度”構造的項目在回答問題時從整體組織角度或心態定位了調查接受者。 換句話說,要求個人從整體上考慮管理。 但是,當調查接受者提出“ direct_mgmt_satisfaction”問題時,他們的視野就會縮小,盡管享有更廣泛的組織領導權,但他們對直接經理的看法可能會有所不同。 這可能可以解釋為什么“ direct_mgmt_satisfaction”項加載的系數如此之低。
I would suggest the survey to separate out the management latent construct into broad leadership and direct manager satisfaction. Furthermore, I would strongly suggest the “employee_value” construct needs to be rethought as the items do not load together on any factor.
我建議該調查將管理潛能結構分為廣泛的領導和直接的經理滿意度。 此外,我強烈建議您需要重新考慮“ employee_value”構造,因為這些項目不會在任何因素上一起加載。
Factor 2: This factor almost perfectly loads onto the “job satisfaction” construct. This would indicate the items have been well developed and are measuring what they indented to measure.
因素2:該因素幾乎完美地加載到“工作滿意度”結構中。 這將表明這些項目已經開發完善,并且正在衡量它們要衡量的內容。
Factor 3: “Training satisfaction” perfectly loads onto factor 3. However, it is important to mention the item “assessing promotional_opportunities” has a somewhat positive loading. This would make sense as an organization which offers training opportunities for their employees is surely to have a good succession plan in place.
因素3: “培訓滿意度”完全符合因素3。但是,重要的是要提及“評估proportation_opportunities”項具有一定的積極影響。 對于為員工提供培訓機會的組織,一定要制定一個好的繼任計劃。
Factor 4: Factor 4 seems to correspond with the “team_satisfaction” construct. Although, the “team_culture” item needs to be improved due to its low loading. Items that attempt to assess ambiguous topics such as “culture” often present with low loadings onto their designated constructs. Perhaps focusing the item on one or two specific components of an organizational culture model would definitely help to narrow down the question.
因素4:因素4似乎與“ team_satisfaction”構造相對應。 雖然,“ team_culture”項目由于其低負載而需要改進。 試圖評估模棱兩可主題(例如“文化”)的項目通常在其指定結構上的負荷較低。 也許將項目重點放在組織文化模型的一個或兩個特定組成部分上肯定會有助于縮小問題的范圍。
Factor 5: This factor loads great with the “work/life balance” latent construct.
因素5:這個因素在“工作/生活平衡”潛在結構中起著很大的作用。
Factor 6: It is interesting to see that both “team_comm” and “team_culture” load very highly onto factor 6 despite the fact “team_comm” also loads onto factor 4. Because “team_comm” loads highly on two factors, this would indicate the question might be interpreted differently by the survey takers. Perhaps adding some context into the question might help to improve its loading onto factor 4. Finally, simply changing the order of the questions which assess “team satisfaction” might help these two items to load better on factor 4.
因子6:有趣的是,盡管“ team_comm”也加載到因子4上,“ team_comm”和“ team_culture”都非常高地加載到因子6上。受訪者可能對它的解釋有所不同。 也許在問題中添加一些上下文可能有助于改善因素4的負荷。最后,簡單地更改評估“團隊滿意度”的問題的順序可能有助于這兩項在因素4上的負荷更好。
Factor 7: We are not seeing any identifiable constructs loading onto factor 7.
因素7:我們看不到任何可識別的結構加載到因素7上。
Factor 8: This is the only factor where the “fair_salary” item seems to load. This construct certainly needs additional questions before any recommendations can be made.
因素8:這是“ fair_salary”項目似乎加載的唯一因素。 在提出任何建議之前,此結構肯定需要其他問題。
驗證性因素分析(CFA) (Confirmatory Factor Analysis (CFA))
A confirmatory factor analysis is used most often to confirm already validated assessments. For example, you wish to conduct an employee engagement assessment using an off-the-shelf survey purchased from a vendor. It might be a good idea to run a pilot test using the survey on your specific organizational sample of employees. A CFA would be a great tool to confirm the underlying constructs the survey purports to measure but using your sample of employees.
驗證性因素分析最常用于確認已經驗證的評估。 例如,您希望使用從供應商處購買的現成調查來進行員工敬業度評估。 使用針對您的特定組織樣本的調查進行試點測試可能是一個好主意。 CFA將是確認調查所要衡量但使用您的員工樣本的基礎結構的好工具。
In reality, researchers will often use both factor analyses to validate their assessments. There is nothing wrong with using an EFA to observe purposefully developed constructs. I have found that the results of an EFA can be tremendously helpful in distilling issues with the individual items. Once you have improved the items based on the EFA results the CFA results will typically increase as well.
實際上,研究人員通常會同時使用兩種因子分析來驗證其評估。 使用EFA觀察有目的開發的結構沒有錯。 我發現,EFA的結果對于提煉單個項目的問題非常有幫助。 一旦您基于EFA結果改進了項目,CFA結果通常也會增加。
model_dict = {'valued_employee': ['promotional_opportunities', 'performance_recognized','feedback_offered', 'coaching_offered'],'mgmt_sati':['mgmt_clear_mission', 'mgmt_support_me', 'mgmt_support_team','mgmt_clear_comm', 'direct_mgmt_satisfaction'],'job_satisfaction': ['job_stimulating', 'initiative_encouraged',
'skill_variety','knowledge_variety','task_variety'],'salary_satisfaction': ['salary_satisfaction'],'team_satisfaction': ['teamwork','team_support', 'team_comm', 'team_culture'],'training_satisfaction': ['job_train_satisfaction', 'personal_train_satisfaction'],'org_condition': ['org_culture', 'grievances_resolution', 'co-worker_interaction','workplace_conditions'],'work_life_balance': ['job_stress','work/life_balance']}model_spec = ModelSpecificationParser.parse_model_specification_from_dict(
likert_items, model_dict)cfa = ConfirmatoryFactorAnalyzer(model_spec, disp=False)
cfa.fit(likert_items)cfa_factors_df = pd.DataFrame(cfa.loadings_, columns=['factor1', 'factor2','factor3','factors4','factor5','factor6','factor7', 'factor8'],index=likert_items.columns)cfa_factors_df.style.bar(subset=['factor1','factor2','factor3',
'factors4','factor5','factor6','factor7','factor8'], color='orange')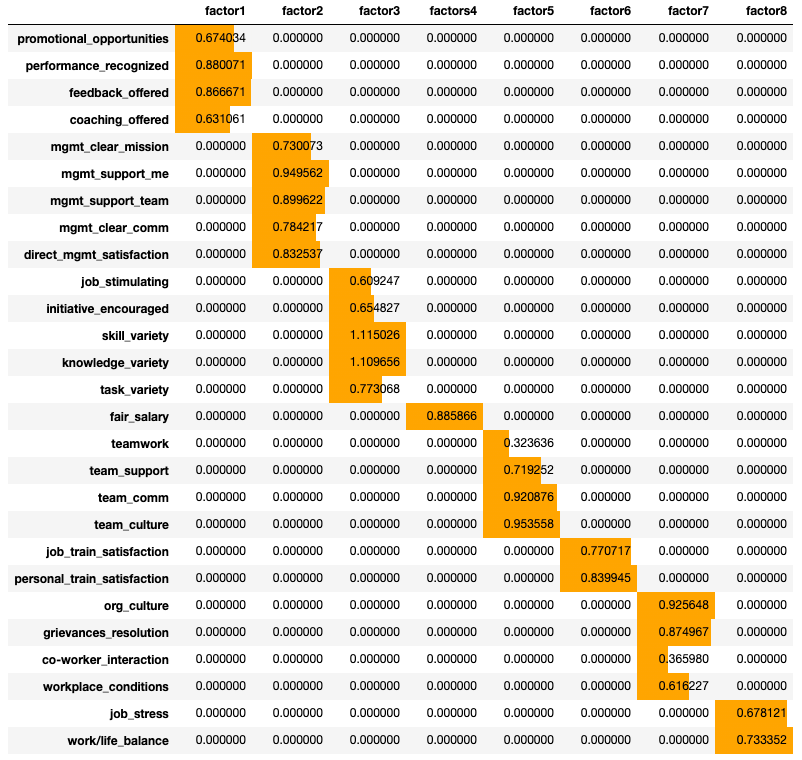
摘要 (Summary)
員工價值 (Employee Value)
The CFA results seem to mostly confirm the results obtained from the correlation matrix, alpha reliability, and EFA. The items assessing the “employee_value” construct certainly need to be polished as there seems to be some confusion about what is being measured. “Performance_recognized” and “feedback_offered” seem to be measuring one underlying construct as their correlation is 0.63 and their loadings on both the EFA and CFA are high. The alpha reliability for this construct is borderline acceptable (0.79) and as we look at additional metrics there is certainly work needed to be done on this construct.
CFA結果似乎主要證實了從相關矩陣,α可靠性和EFA獲得的結果。 評估“ employee_value”構造的項目當然需要完善,因為似乎對所測量的內容有些困惑。 “ Performance_recognized”和“ feedback_offered”似乎正在衡量一種基礎結構,因為它們的相關性為0.63,并且它們在EFA和CFA上的負載都很高。 此結構的alpha可靠性是可接受的邊界(0.79),并且當我們查看其他指標時,肯定需要在此結構上進行工作。
管理滿意度 (Management Satisfaction)
With the exception of “direct _mgmt_satisfaction,” the items measuring management satisfaction are well developed and stands up to the rigorous testing of correlations, alpha reliability, and factor analysis. As mentioned previously, there might be a scale issue with the “direct _mgmt_satisfaction” question compared to the rest of the questions. Survey takers are mostly answering questions regarding the broader leadership construct and this question asks about their direct manager.
除了“直接的_mgmt_satisfaction”外,衡量管理滿意度的項目也很完善,可以經受嚴格的相關性,alpha可靠性和因子分析測試。 如前所述,與其他問題相比,“直接_mgmt_satisfaction”問題可能存在規模問題。 受訪者大多是在回答有關更廣泛的領導力結構的問題,而這個問題是關于他們的直接經理的。
工作滿意度 (Job Satisfaction)
All 4 analyses support the quality of the items assessing this construct. I wouldn’t change a thing :)
所有4種分析均支持評估此結構的項目的質量。 我不會改變任何事情:)
團隊滿意度 (Team Satisfaction)
This construct had some contradicting loading results when comparing the EFA and CFA. Nevertheless, these contradictions, borderline alpha reliability, and less than stunning correlations among the items point to much needed revision of the questions. I believe the construct of a team is well operationalized but the notion of “team culture” might be interpreted differently among those taking the survey.
比較EFA和CFA時,此結構的加載結果有些矛盾。 但是,這些矛盾,臨界的alpha可靠性以及各項之間不夠驚人的相關性都表明,急需對該問題進行修訂。 我相信團隊的構建可以很好地運作,但是“團隊文化”的概念在接受調查的人中可能會有所不同。
培訓滿意度 (Training Satisfaction)
It is important to offer at least 3 questions per construct in order to establish credible reliability and construct validity. The two items measuring this construct are very well written and seem to be assessing one factor. I would like to see additional questions. Kirkpatrick’s training evaluation model can serve as the basis for additional questions.
重要的是,每個結構至少要提供3個問題,以建立可信的可靠性和結構有效性。 衡量此構造的兩個項目寫得很好,似乎正在評估一個因素。 我想看看其他問題。 柯克帕特里克(Kirkpatrick)的培訓評估模型可以作為其他問題的基礎。
組織環境 (Organizational Environment)
Unfortunately, much like “employee value” this construct needs major edits. All the metrics resulted in subpar results and from a face-validity perspective, it is simply difficult to mentally encompass these items into one cohesive construct.
不幸的是,這種構造很像“員工價值”,需要進行大量修改。 所有度量標準均得出不及格的結果,并且從臉部有效性的角度來看,僅是很難在精神上將這些項目包含在一個有凝聚力的結構中。
工作與生活的平衡 (Work/life Balance)
Much like “training satisfaction” this construct has performed well but we would like to see at least 3 items per construct.
就像“培訓滿意度”一樣,此構造的效果很好,但我們希望每個構造至少看到3個項目。
工資滿意度 (Salary Satisfaction)
This construct was composed of one item and from a practical perspective, it is simply lacking. Even Cronbach’s alpha requires at least 2 questions.
這種構造只包含一個項目,從實際的角度來看,它只是缺乏。 甚至Cronbach的alpha也至少需要2個問題。
結論 (Conclusion)
There is certainly a large amount of work which goes into developing employee surveys. What’s more, when the survey becomes an assessment (ie. cognitive ability or skill test) used in a hiring process the rigor and documentation increases exponentially. I hope you enjoyed a glimpse into some of the work I/O psychologists perform. As always I welcome your feedback.
當然,開展員工調查需要大量工作。 更重要的是,當調查成為招聘過程中使用的評估(即認知能力或技能測試)時,嚴謹性和文件記錄成倍增加。 我希望您對I / O心理學家執行的某些工作有所了解。 一如既往,我歡迎您的反饋。
翻譯自: https://towardsdatascience.com/assessing-statistical-rigor-of-employee-surveys-1d27e3df998a
盛嚴謹,嚴謹,再嚴謹。
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388831.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388831.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388831.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

復權就是對股價和成交量進行權息修

![[MySQL] INFORMATION_SCHEMA 數據庫包含所有表的字段](http://pic.xiahunao.cn/[MySQL] INFORMATION_SCHEMA 數據庫包含所有表的字段)
[MySQL] INFORMATION_SCHEMA 數據庫包含所有表的字段

開根號的筆算算法圖解_一個數的開根號怎么計算

arima 預測模型_預測未來:學習使用Arima模型進行預測

net程序員的iPhone開發-MonoTouch

ASP防止SQL注入

protobuf java 生成_protobuf代碼生成

bigquery_在BigQuery中鏈接多個SQL查詢

允許指定IP訪問遠程桌面
)
大理石在哪兒 (Where is the Marble?,UVa 10474)

Volley 源碼解析之網絡請求

為什么修改了ie級別里的activex控件為啟用后,還是無法下載,顯示還是ie級別設置太高?

mysql 遷移到tidb_通過從MySQL遷移到TiDB來水平擴展Hive Metastore數據庫

兩個日期相差月份 java_Java獲取兩個指定日期之間的所有月份

js前端日期格式化處理

如何用sysbench做好IO性能測試

XCode、Objective-C、Cocoa 說的是幾樣東西
)
