mysql 遷移到tidb
Industry: Knowledge Sharing
行業:知識共享
Author: Mengyu Hu (Platform Engineer at Zhihu)
作者:胡夢瑜(Zhhu的平臺工程師)
Zhihu which means “Do you know?” in classical Chinese, is the Quora of China: a question-and-answer website where all kinds of questions are created, answered, edited, and organized by the community of its users. As China’s biggest knowledge sharing platform, we have 220 million registered users and 30 million questions with more than 130 million answers on the site. In August 2019, we completed $450 million in F-round funding.
智虎 ,意思是“你知道嗎?” 在古漢語中,中國的Quora是一個問答網站,由用戶社區創建,回答,編輯和組織各種問題。 作為中國最大的知識共享平臺 ,我們擁有2.2億注冊用戶和3000萬個問題,網站上有1.3億多個答案。 2019年8月,我們完成了4.5億美元的F輪融資 。
At Zhihu, we used MySQL as the Hive Metastore. With data growth in Hive, MySQL stored about 60 GB of data, and the largest table had more than 20 million rows of data. Although the data volume was not excessive for a standalone MySQL database, running queries or writing data in Hive caused frequent operations in Metastore. In this case, MySQL, Metastore’s backend database, became the bottleneck for the entire system. We compared multiple solutions and found that TiDB, an open-source distributed Hybrid Transactional/Analytical Processing (HTAP) database was the optimal solution. Thanks to TiDB’s elastic scalability, we can horizontally scale our metadata storage system without worrying about database capacity.
在Zhihu,我們使用MySQL作為Hive Metastore。 隨著Hive中數據的增長,MySQL存儲了大約60 GB的數據,而最大的表具有超過2000萬行的數據。 盡管對于獨立MySQL數據庫而言,數據量并不算太大,但在Hive中運行查詢或寫入數據會導致Metastore中的頻繁操作。 在這種情況下,Metastore的后端數據庫MySQL成為整個系統的瓶頸。 我們比較了多種解決方案,發現TiDB ,一個開源分布式混合事務/分析處理 (HTAP)數據庫是最佳的解決方案。 由于TiDB的彈性可伸縮性,我們可以水平擴展元數據存儲系統,而不必擔心數據庫容量。
Last year, we published a post that showed how we kept our query response times at milliseconds levels despite having over 1.3 trillion rows of data. This post became a hit on various media platforms like Hacker News and DZone. Today, I’ll share with you how we use TiDB to horizontally scale Hive Metastore to meet our growing business needs.
去年,我們發表了一篇文章 ,展示了盡管有超過1.3萬億行數據,我們如何將查詢響應時間保持在毫秒級。 這篇文章在Hacker News和DZone等各種媒體平臺上都很受歡迎。 今天,我將與您分享我們如何使用TiDB橫向擴展Hive Metastore以滿足我們不斷增長的業務需求。
我們的痛點 (Our pain point)
Apache Hive is a data warehouse software project built on top of Apache Hadoop that provides data query and analysis. Hive Metastore is Hive’s metadata management tool. It provides a series of interfaces for operating metadata, and its backend storage generally uses a relational database like Derby or MySQL. In addition to Hive, many computing frameworks support using Hive Metastore as a metadata center to query the data in the underlying Hadoop ecosystem, such as Presto, Spark, and Flink.
Apache Hive是建立在Apache Hadoop之上的數據倉庫軟件項目,可提供數據查詢和分析。 Hive Metastore是Hive的元數據管理工具。 它提供了用于操作元數據的一系列接口,并且其后端存儲通常使用諸如Derby或MySQL之類的關系數據庫。 除了Hive外,許多計算框架還支持使用Hive Metastore作為元數據中心來查詢基礎Hadoop生態系統中的數據,例如Presto,Spark和Flink。
At Zhihu, we used MySQL as the Hive Metastore. As data grew in Hive, a single table stored more than 20 million rows of data in MySQL. When a user’s task had intensive operations in Metastore, it often ran slow or even timed out. This greatly affected task stability. If this continued, MySQL would be overwhelmed. Therefore, it was critical to optimize Hive Metastore.
在Zhihu,我們使用MySQL作為Hive Metastore。 隨著Hive中數據的增長,單個表在MySQL中存儲了超過2000萬行數據。 當用戶的任務在Metastore中進行大量操作時,它通常運行緩慢甚至超時。 這極大地影響了任務的穩定性。 如果這種情況持續下去,MySQL將不堪重負。 因此,優化Hive Metastore至關重要。
To reduce MySQL’s data size and ease the pressure on Metastore, we regularly deleted metadata in MySQL. However, in practice this policy had the following drawbacks:
為了減少MySQL的數據大小并減輕對Metastore的壓力,我們定期刪除MySQL中的元數據。 但是,實際上,此策略具有以下缺點:
- Data grew much faster than it was deleted. 數據增長的速度比刪除速度快得多。
When we deleted partitions of a very large partitioned table that had millions of partitions, it caused pressure on MySQL. We had to control the concurrency of such queries, and at peak hours only one query could be executed at a time. Otherwise, this would affect other operations in Metastore such as
SELECTandUPDATEoperations.當我們刪除具有數百萬個分區的超大型分區表的分區時,這給MySQL造成了壓力。 我們必須控制此類查詢的并發性,并且在高峰時段一次只能執行一個查詢。 否則,這將影響Metastore中的其他操作,例如
SELECT和UPDATE操作。- At Zhihu, when metadata was deleted, the corresponding data was also deleted. (We deleted outdated data in the Hadoop Distributed File System to save costs.) In addition, Hive users would sometimes improperly create tables and set a wrong partition path. This resulted in data being deleted by mistake. 在Zhihu,刪除元數據時,相應的數據也被刪除。 (為了節省成本,我們刪除了Hadoop分布式文件系統中的過時數據。)此外,Hive用戶有時會不正確地創建表并設置錯誤的分區路徑。 這導致數據被錯誤地刪除。
Therefore, we began to look for another solution.
因此,我們開始尋找另一種解決方案。
我們比較的解決方案 (Solutions we compared)
We compared multiple options and chose TiDB as our final solution.
我們比較了多種選擇,并選擇TiDB作為最終解決方案。
MySQL分片 (MySQL sharding)
We considered using MySQL sharding to balance the load of multiple MySQL databases in a cluster. However, we decided against this policy because it had these issues:
我們考慮過使用MySQL分片來平衡集群中多個MySQL數據庫的負載。 但是,我們決定反對此政策,因為它存在以下問題:
- To shard MySQL, we would need to modify the Metastore interface to operate MySQL. This would involve a lot of high-risk changes, and it would make future Hive upgrades more complicated. 要分片MySQL,我們需要修改Metastore接口以運行MySQL。 這將涉及很多高風險的更改,并使將來的Hive升級更加復雜。
- Every day, we replicated MySQL data to Hive for data governance and data life cycle management. We used the internal data replication platform to replicate data. If we had used MySQL sharding, we would need to update the replication logic for the data replication platform. 每天,我們將MySQL數據復制到Hive進行數據治理和數據生命周期管理。 我們使用內部數據復制平臺來復制數據。 如果使用MySQL分片,則需要更新數據復制平臺的復制邏輯。
使用聯盟擴展Metastore (Scaling Metastore using Federation)
We thought we could scale Hive Metastore using Federation. We could form an architecture that consisted of MySQL and multiple sets of Hive Metastore and add a proxy in front of Metastore to distribute requests according to certain rules.
我們認為可以使用聯盟擴展Hive Metastore。 我們可以形成一個包含MySQL和多組Hive Metastore的架構,并在Metastore前面添加一個代理,以根據某些規則分配請求。
But after investigation, we found this policy also had flaws:
但是經過調查,我們發現此政策也有缺陷:
- To enable Federation on Hive Metastore, we wouldn’t need to modify Metastore, but we would have to maintain a set of routing components. What’s more, we need to carefully set routing rules. If we divided the existing MySQL store to different MySQL instances, divisions might be uneven. This would result in unbalanced loads among subclusters. 要在Hive Metastore上啟用聯合身份驗證,我們不需要修改Metastore,但我們必須維護一組路由組件。 此外,我們需要仔細設置路由規則。 如果我們將現有MySQL存儲區劃分為不同MySQL實例,則劃分可能會不均勻。 這將導致子集群之間的負載不平衡。
- Like the MySQL sharing solution, we would need to update the replication logic for the data replication platform. 像MySQL共享解決方案一樣,我們將需要更新數據復制平臺的復制邏輯。
具有彈性可伸縮性的TiDB是完美的解決方案 (TiDB, with elastic scalability, is the perfect solution)
TiDB is a distributed SQL database built by PingCAP and its open-source community. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability. It’s a one-stop solution for both OLTP and OLAP workloads. You can learn more about TiDB’s architecture here.
TiDB是由PingCAP及其開源社區構建的分布式SQL數據庫。 它與MySQL兼容,具有水平可伸縮性,強一致性和高可用性。 它是OLTP和OLAP工作負載的一站式解決方案。 您可以在此處了解有關TiDB架構的更多信息。
As you recall, our problem was that when the data size increased, MySQL, limited by its standalone performance, could not deliver good performance. When individual MySQL databases formed a cluster, the complexity drastically increased. If we could find a distributed, MySQL-compatible database, we could solve this problem. Therefore, TiDB is a perfect match.
您還記得,我們的問題是,當數據大小增加時,受其獨立性能限制MySQL無法提供良好的性能。 當單個MySQL數據庫形成集群時,復雜性急劇增加。 如果我們可以找到一個分布式的,兼容MySQL的數據庫,則可以解決此問題。 因此,TiDB是絕配。
We chose TiDB because it had the following advantages:
我們選擇TiDB是因為它具有以下優點:
TiDB is compatible with the MySQL protocol. Our tests showed that TiDB supported all inserts, deletes, updates, and selects in Metastore. Using TiDB would not bring any compatibility-related issues. Therefore, all we needed to do is dump MySQL data to TiDB.
TiDB與MySQL協議兼容。 我們的測試表明,TiDB支持Metastore中的所有插入,刪除,更新和選擇。 使用TiDB不會帶來任何與兼容性相關的問題。 因此,我們要做的就是將MySQL數據轉儲到TiDB。
Due to its distributed architecture, TiDB far outperforms MySQL on large data sets and large number of concurrent queries.
由于其分布式架構, TiDB在大數據集和大量并發查詢方面遠遠勝過MySQL。
TiDB has excellent horizontal scalability. It supports elastic scalability. Whether we choose MySQL sharding or Hive Metastore Federation, we could encounter bottlenecks again. Then, we would need to do sharding or Hive Metastore Federation again. But TiDB solves this problem.
TiDB具有出色的水平可伸縮性。 它支持彈性可伸縮性。 無論我們選擇MySQL分片還是Hive Metastore Federation,我們都可能再次遇到瓶頸。 然后,我們將需要再次進行分片或Hive Metastore Federation。 但是TiDB解決了這個問題。
TiDB is widely used in Zhihu, and the related technologies are relatively mature, so we can control the migration risk.
TiDB在枝湖地區被廣泛使用,相關技術相對成熟,因此可以控制遷移風險。
Hive架構 (The Hive architecture)
遷移到TiDB之前 (Before migration to TiDB)
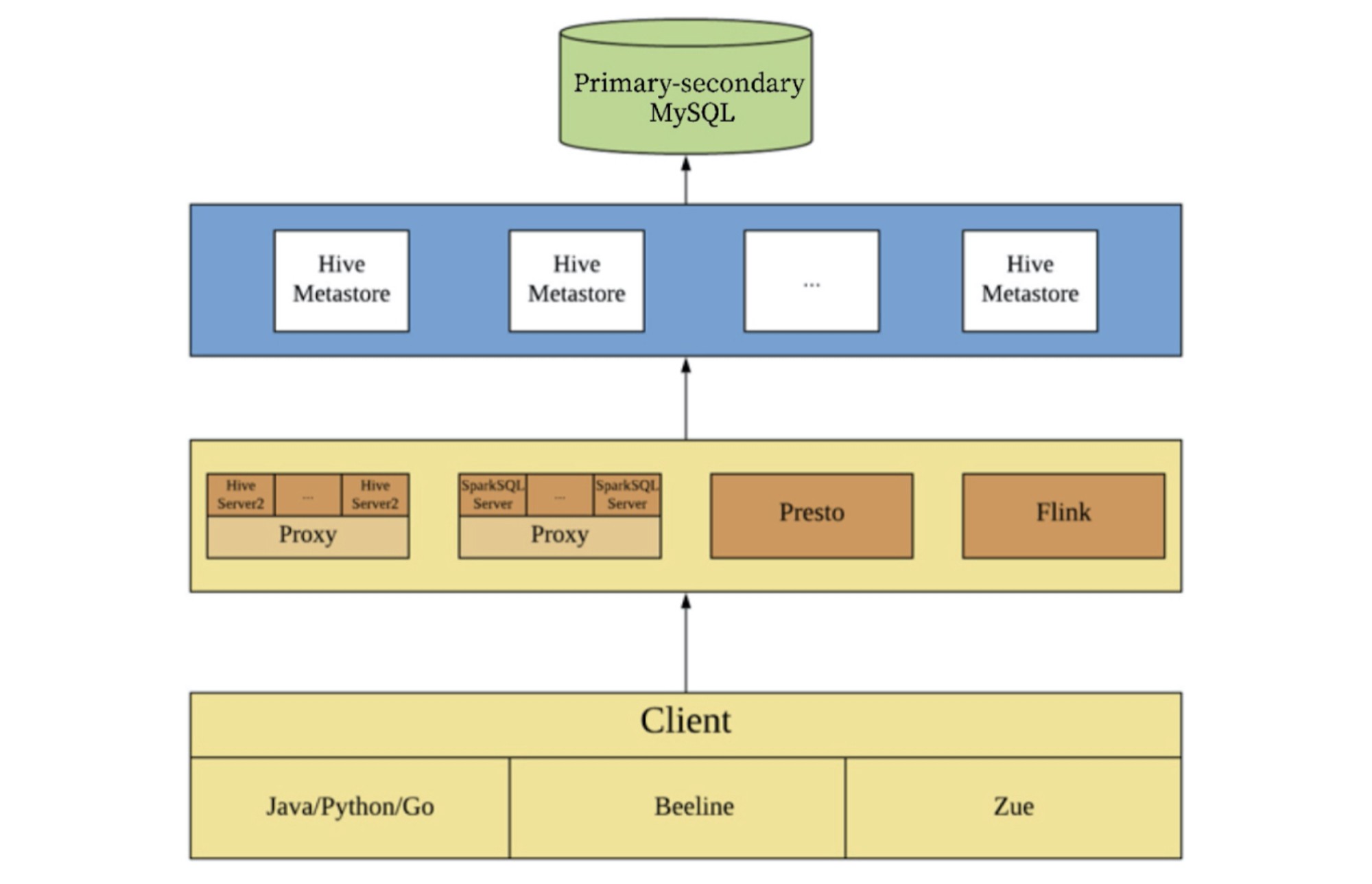
Before we migrated from MySQL to TiDB, our Hive architecture was as follows. In this architecture, Zue is a visual query interface for Zhihu’s internal use.
從MySQL遷移到TiDB之前,我們的Hive架構如下。 在此體系結構中,Zue是Zhihu內部使用的可視化查詢界面。
遷移到TiDB之后 (After migration to TiDB)
After we migrated from MySQL to TiDB, the Hive architecture looks like this:
從MySQL遷移到TiDB之后,Hive架構如下所示:
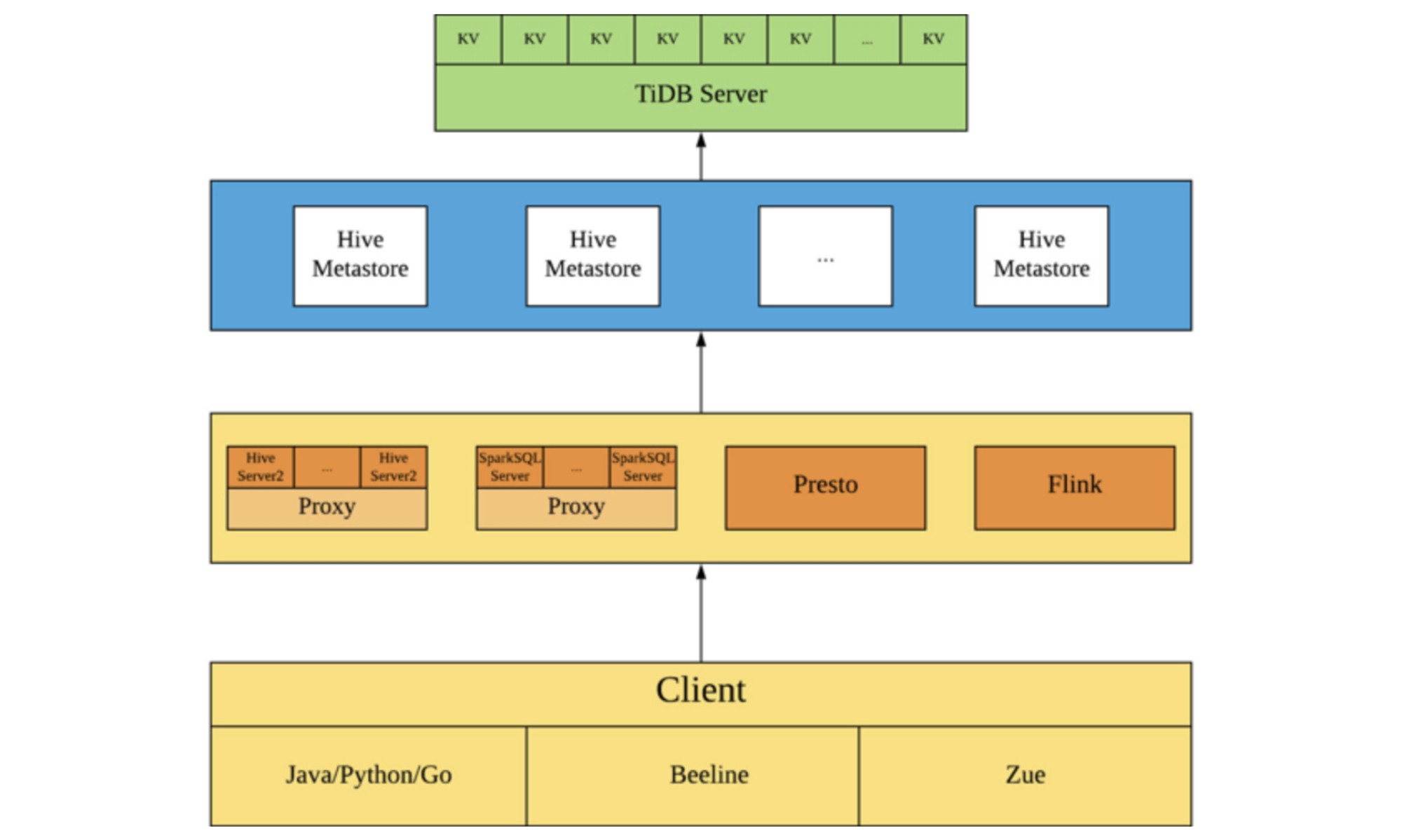
You can see that after we migrated metadata to TiDB, the architecture has almost no change. The query requests, which were on a single MySQL node, are now distributed in the TiDB cluster. The larger the TiDB cluster, the higher the query efficiency and the greater the performance improvement.
您可以看到,在將元數據遷移到TiDB之后,該架構幾乎沒有變化。 現在,在單個MySQL節點上的查詢請求已分發到TiDB集群中。 TiDB集群越大,查詢效率越高,性能提升也就越大。
遷移過程 (The migration process)
We migrated from MySQL to TiDB this way:
我們以這種方式從MySQL遷移到TiDB:
- We used MySQL as the primary database and TiDB as the secondary database to replicate data from MySQL to TiDB in real time. 我們使用MySQL作為主要數據庫,使用TiDB作為輔助數據庫,以將數據從MySQL實時復制到TiDB。
- We reduced the number of Metastore nodes to one to prevent multiple Metastore nodes from writing to MySQL and TiDB simultaneously, which would cause inconsistent metadata. 我們將Metastore節點的數量減少到一個,以防止多個Metastore節點同時寫入MySQL和TiDB,這將導致元數據不一致。
- During the application’s off-peak hours, we switched from the primary database to the secondary. We used TiDB as the primary and restarted Metastore. 在應用程序的非高峰時段,我們從主數據庫切換到了輔助數據庫。 我們使用TiDB作為主要的并重新啟動的Metastore。
- We added back Metastore nodes. 我們添加回Metastore節點。
During the migration process, the application was not affected. Now TiDB successfully runs in our production environment.
在遷移過程中,該應用程序不受影響。 現在,TiDB已在我們的生產環境中成功運行。
應用程序的運行狀態 (The application’s running status)
應用程序高峰中的操作執行時間 (Operation execution time in the application peak)
We tested the database from the Hive level, simulated the application peak, and concurrently deleted and added partitions for tables with millions of partitions. We executed Hive SQL statements as follows:
我們從Hive級別測試了數據庫,模擬了應用程序高峰,并為具有數百萬個分區的表同時刪除和添加了分區。 我們執行Hive SQL語句如下:
ALTER TABLE '${table_name}' DROP IF EXISTS PARTITION(...);
ALTER TABLE '${table_name}' ADD IF NOT EXISTS PARTITION(...);The operation execution time dropped from 45–75 seconds before migration to under 10 seconds after migration.
操作執行時間從遷移前的45-75秒減少到遷移后的10秒以下。
大型查詢對數據庫的影響 (The impact of large queries on the database)
From the Metastore level, we tested some of the SQL statements submitted by Metastore, especially SQL statements that would cause great pressure on the Metastore, for example:
從Metastore級別,我們測試了Metastore提交的一些SQL語句,特別是會對Metastore造成很大壓力SQL語句,例如:
SELECT `A0`.`PART_NAME`,`A0`.`PART_NAME` AS `NUCORDER0` FROM `PARTITIONS` `A0` LEFT OUTER JOIN `TBLS` `B0` ON `A0`.`TBL_ID` = `B0`.`TBL_ID` LEFT OUTER JOIN `DBS` `C0` ON `B0`.`DB_ID` = `C0`.`DB_ID` WHERE `C0`.`NAME` = '${database_name}' AND `B0`.`TBL_NAME` = '${table_name}' ORDER BY `NUCORDER0`When the number of partitions of a Hive table was very large, this SQL statement would trigger great pressure on the Metastore. Before migration to TiDB, the execution time of this type of SQL statement in MySQL was 30–40 seconds. After migration, the execution time was 6–7 seconds. What a remarkable improvement!
當Hive表的分區數量很大時,此SQL語句將對Metastore施加巨大壓力。 在遷移到TiDB之前,MySQL中此類SQL語句的執行時間為30-40秒。 遷移后,執行時間為6-7秒。 多么了不起的進步!
復制時間 (Replication time)
The safety data sheet (SDS) table, with more than 10 million rows of data, is one of the biggest tables in Metastore. The replication time of the SDS table in Metastore on the data replication platform was reduced from 90 seconds to 15 seconds.
安全數據表(SDS)表具有超過一千萬行的數據,是Metastore中最大的表之一。 數據復制平臺上Metastore中SDS表的復制時間從90秒減少到15秒。
下一步是什么 (What’s next)
In the Hive Metastore case, TiDB helps us horizontally scale our metadata storage database so we no longer need to worry about our database storage capacity. We hope that, in the future, TiDB can provide cross-data center (DC) services: through the cross-DC deployment of data replicas, TiDB could connect online and offline scenarios so we can do real-time extract, transform, load (ETL) tasks offline without causing pressure on online services. This will improve offline ETL tasks’ real-time performance. Therefore, we’re developing TiBigData.
在Hive Metastore案例中,TiDB幫助我們水平擴展了元數據存儲數據庫,因此我們不再需要擔心數據庫的存儲容量。 我們希望,將來TiDB可以提供跨數據中心(DC)服務:通過跨DC部署數據副本,TiDB可以連接在線和離線場景,以便我們可以進行實時提取,轉換,加載( ETL)任務脫機而不會給在線服務造成壓力。 這將提高離線ETL任務的實時性能。 因此,我們正在開發TiBigData 。
This project was initiated by Xiaoguang Sun, a TiKV Maintainer at Zhihu. Currently, it’s an incubation project in PingCAP Incubator. PingCAP Incubator aims to establish an incubation system for TiDB ecological open-source projects. For all projects, see pingcap-incubator on GitHub. You can check out PingCAP Incubator’s documentation here.
該項目由Zhihu的TiKV維護者Sun Xiaoguang發起。 目前,這是PingCAP Incubator中的孵化項目。 PingCAP孵化器旨在為TiDB生態開源項目建立一個孵化系統。 對于所有項目,請參閱GitHub上的pingcap-incubator 。 您可以在此處查看PingCAP孵化器的文檔。
The TiBigData project has provided the read-only support of Presto and Flink for TiDB. In the future, with the support of the PingCAP Incubator plan, we hope to build the TiBigData project together with the community and strive to enhance TiDB’s big data capabilities.
TiBigData項目為TiDB提供了Presto和Flink的只讀支持。 將來,在PingCAP孵化器計劃的支持下,我們希望與社區一起構建TiBigData項目,并努力增強TiDB的大數據功能。
Originally published at www.pingcap.com on July 24, 2020
最初于 2020年7月24日 發布在 www.pingcap.com 上
翻譯自: https://medium.com/swlh/horizontally-scaling-the-hive-metastore-database-by-migrating-from-mysql-to-tidb-4636fed170ce
mysql 遷移到tidb
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388817.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388817.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388817.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

兩個日期相差月份 java_Java獲取兩個指定日期之間的所有月份

js前端日期格式化處理

如何用sysbench做好IO性能測試

XCode、Objective-C、Cocoa 說的是幾樣東西
)
java http2_探索HTTP/2: HTTP 2協議簡述(原)


Android類庫介紹

遞歸函數基例和鏈條_鏈條和叉子

的實現原理)
java lock 信號_java各種鎖(ReentrantLock,Semaphore,CountDownLatch)的實現原理

Intent.ACTION_MAIN

足球預測_預測足球熱

C#的特性Attribute

java 技能鑒定_JAVA試題-技能鑒定

ADD_SHORTCUT_ACTION

python3中樸素貝葉斯_貝葉斯統計:Python中從零開始的都會都市

java映射的概念_Java 反射 概念理解

【轉載】移動端布局概念總結

深入淺出:HTTP/2
