spotify 數據分析
For many data science students, collecting data is seen as a solved problem. It’s just there in Kaggle or UCI. However, that’s not how data is available daily for working Data Scientists. Also, many of the datasets used for learning have been largely explored, so how innovative would be building a portfolio based on them? What about building your dataset by combining different sources?
對于許多數據科學專業的學生來說,收集數據被視為已解決的問題。 它就在Kaggle或UCI中。 但是,這不是每天為工作的數據科學家提供數據的方式。 此外,已經廣泛探索了許多用于學習的數據集,因此如何基于這些數據集構建投資組合? 如何通過組合不同的來源來構建數據集?
Let’s dive in.
讓我們潛入。
為什么選擇重金屬數據? (Why Heavy Metal data?)
Seen by many as a very strict music genre (screaming vocals, fast drums, distorted guitars), it actually goes the other way round. Metal music it’s not as mainstream as most genres but it has, without question, the largest umbrella of subgenres with so many distinct sounds. Therefore, seeing its differences through data could be a good idea, even for the listener not familiarized with it.
被許多人視為非常嚴格的音樂類型(尖叫的人聲,快速的鼓聲,失真的吉他),但實際上卻相反。 金屬音樂不像大多數流派那樣流行,但是毫無疑問,它擁有最大的亞流派,并具有如此多的獨特聲音。 因此,即使對于聽眾不熟悉的數據,通過數據查看其差異也是一個好主意。
為什么選擇維基百科? 怎么樣? (Why Wikipedia? How?)
Wikipedia is frequently updated and it presents relevant information on almost every topic. Also, it gathers many useful links in every page. With heavy metal, it would be no different, especially listing the most popular subgenres and their most relevant bands.
維基百科經常更新,并提供幾乎每個主題的相關信息。 而且,它在每個頁面中收集許多有用的鏈接。 對于重金屬,這沒什么兩樣,特別是列出了最受歡迎的子類型及其最相關的樂隊。
The following page presents not only a historic perspective of the style, but also hyperlinks for many other subgenres and fusion genres in the bottom. The idea here is to collect metal genres only by this starting point.
下一頁不僅顯示了樣式的歷史觀點,還顯示了底部許多其他子類型和融合類型的超鏈接。 這里的想法是僅在此起點上收集金屬類型。
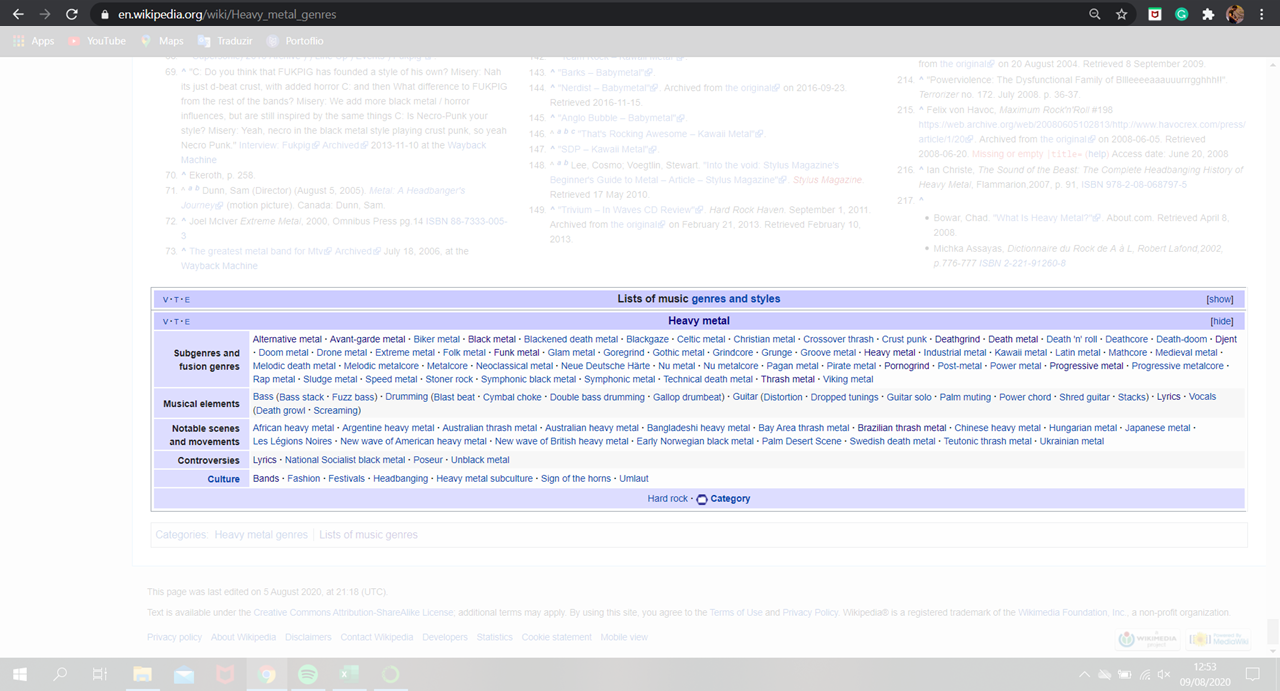
Therefore, the genres’ names in the table were scrapped and compiled in a Python list.
因此,表格中的流派名稱被廢棄并編譯到Python列表中。
from bs4 import BeautifulSoup
import requests
import pandas as pd
import numpy as np
import re# Getting URLssource = 'https://en.wikipedia.org/wiki/Heavy_metal_genres'
response = requests.get(source)
soup = BeautifulSoup(response.text, 'html.parser')
pages = soup.find(class_='navbox-list navbox-odd')
pages = pages.findAll('a')links = []for page in pages:
links.append(('List_of_' + page.get('title').lower().replace(' ','_') + '_bands').replace('_music',''))After inspecting some of the genres’ pages, we discovered that the most relevant ones have pages listing their most important bands. The pages’ URLs can be presented in one or more of the following patterns:
在檢查了某些類型的頁面后,我們發現最相關的頁面中列出了其最重要的樂隊。 頁面的URL可以以下一種或多種模式顯示:
“https://en.wikipedia.org/wiki/List_of_” + genre + “_bands”
“ https://en.wikipedia.org/wiki/List_of_” +類型+“ _bands”
“https://en.wikipedia.org/wiki/List_of_” + genre + “_bands,_0–K”
“ https://zh.wikipedia.org/wiki/List_of_” +類型+“ _ bands,_0–K”
“https://en.wikipedia.org/wiki/List_of_” + genre + “_bands,_L–Z”
“ https://zh.wikipedia.org/wiki/List_of_” +類型+“ _bands,_L–Z”
After inspecting the links, we were able to detect that the band names were presented in varying forms according to each page. Some were tables, some alphabetical lists and some in both. Each presentation form required a different scrapping approach.
在檢查了鏈接之后,我們能夠檢測到根據每個頁面以不同形式顯示的樂隊名稱。 有些是表格,有些是字母順序的列表,而兩者都有。 每個演示文稿表格都需要不同的報廢方法。
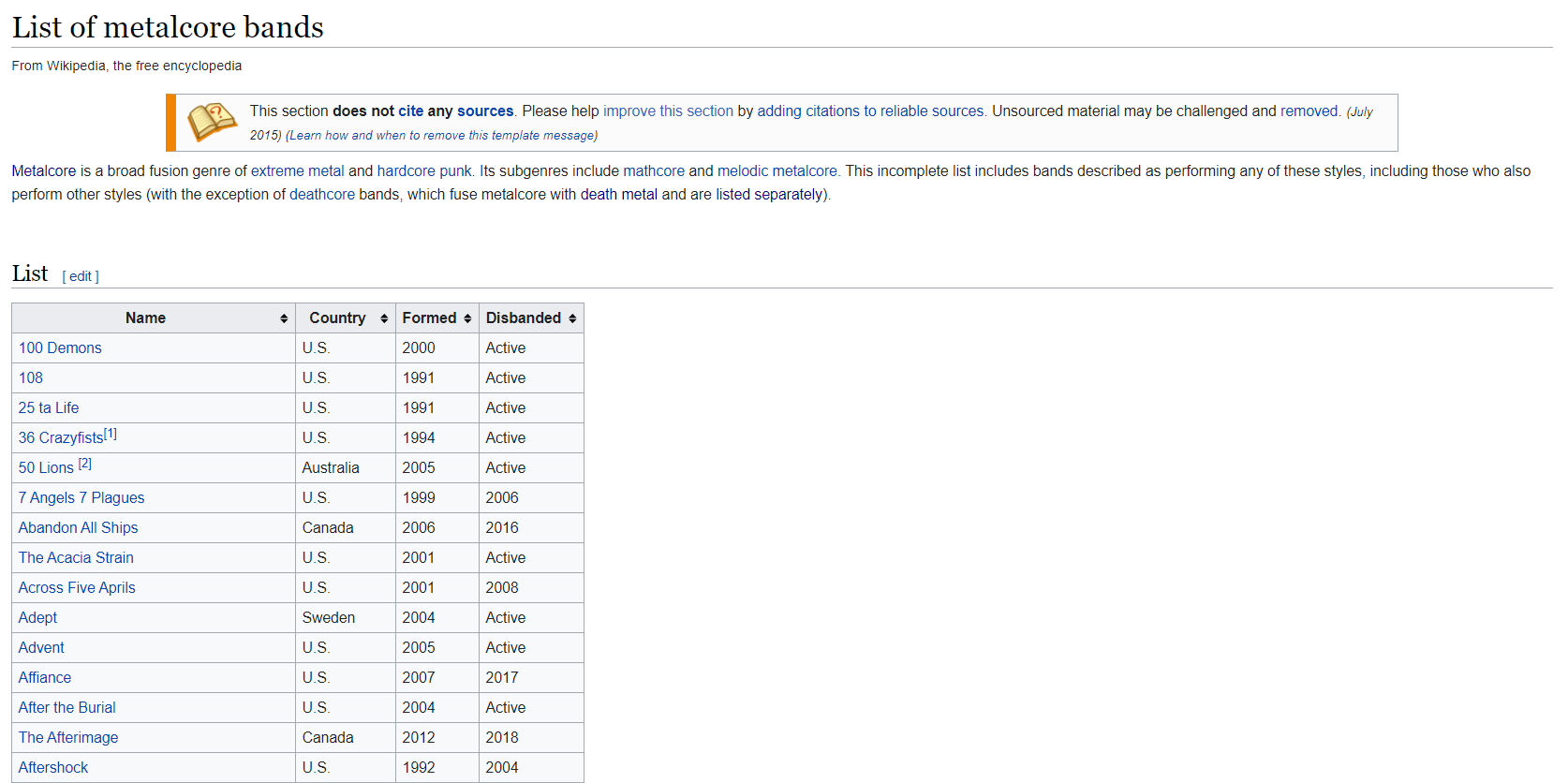
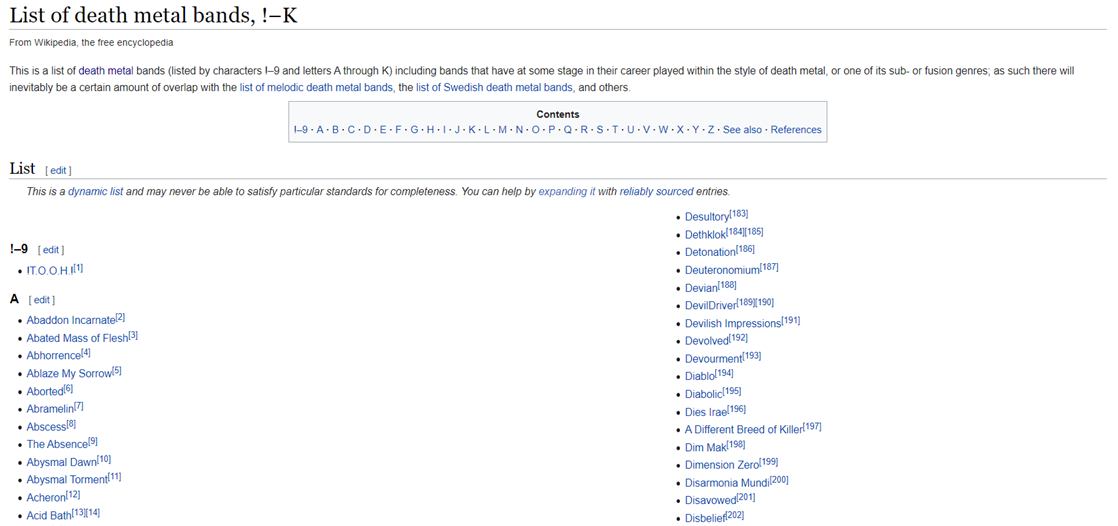
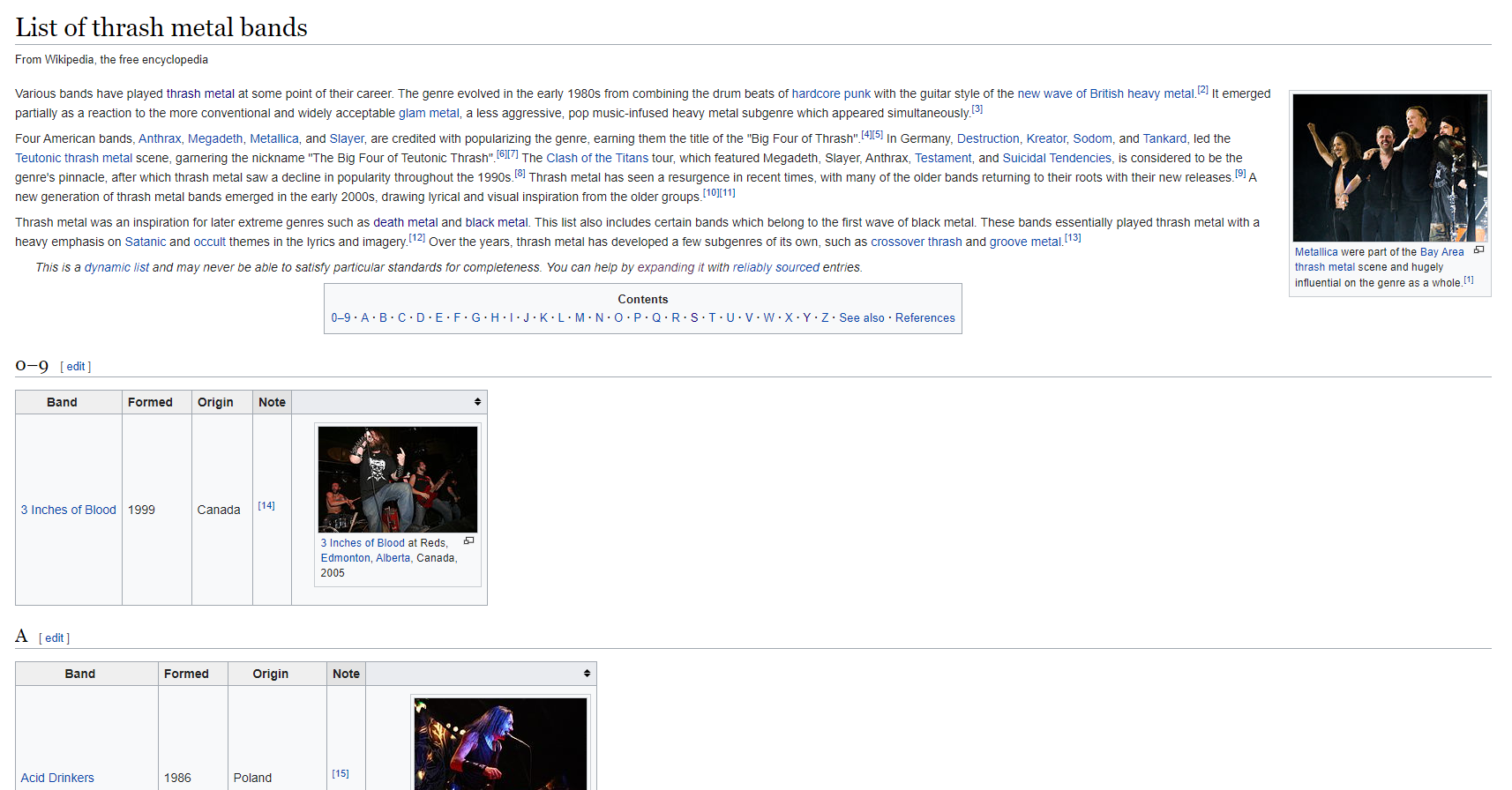
Some band names were polluted with additional characters (mostly for notes or referencing), so a function was developed to deal with these issues.
一些樂隊名稱被附加字符污染(大多數用于注釋或參考),因此開發了一個功能來處理這些問題。
def string_ajustment(band):
"""Ajustment of the retrieved band name string"""
end = band.find('[') # Remove brackets from band name
if end > -1:
band = band[:end]
else:
band = band
end = band.find('(') # Remove parentesis from band name
if end > -1:
band = band[:end]
band = band.title().rstrip() # Uppercase in first letters; last space removal
return bandThe scrapping code gathered the data which was later compiled into a Pandas dataframe object.
剪貼代碼收集了數據,這些數據隨后被編譯為Pandas數據框對象。
%%timedata = []
genres = []for link in links:
url = 'https://en.wikipedia.org/wiki/' + link
genre = url[url.rfind('/') + 1:]
list_from = ['List_of_', '_bands', ',_!–K', ',_L–Z', '_']
list_to = ['', '', '', '', ' ']
for idx, element in enumerate(list_from):
genre = genre.replace(list_from[idx], list_to[idx])
genre = genre.title()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Table detection
tables = []
tables = soup.find_all('table', {'class':'wikitable'}) # 1st attempt
if len(tables) == 0:
tables = soup.find_all('table', {'class':'wikitable sortable'}) # 2nd attempt
# Getting table data
if len(tables) > 0: # pages with tables
genres.append(genre)
for table in tables:
table = table.tbody
rows = table.find_all('tr')
columns = [v.text.replace('\n', '') for v in rows[0].find_all('th')]for i in range(1, len(rows)):
tds = rows[i].find_all('td')
band = tds[0].text.replace('\n', '')
band = string_ajustment(band)
values = [band, genre]
data.append(pd.Series(values)) # Append band
else:
# Getting data in lists
groups = soup.find_all('div', class_ = 'div-col columns column-width') # Groups being lists of bands, 1st attempt
if len(groups) == 0:
groups = soup.find_all('table', {'class':'multicol'}) # Groups being lists of bands, 2nd attempt
for group in groups:
genres.append(genre)
array = group.text.split('\n')[1:len(group.text.split('\n'))-1]
for band in array:
if (band != '0-9'):
band = string_ajustment(band)
if (band.find('Reference') > -1) or (band.find('See also') > -1): # Remove text without band name
break
elif len(band) > 1:
values = [band, genre]
data.append(pd.Series(values)) # Append band
if genre not in genres: # Two possibilities: either data in multiple urls or no data available (non-relevant genre)
additional_links = [link + ',_!–K', link + ',_L–Z']
for additional_link in additional_links:
url = 'https://en.wikipedia.org/wiki/' + additional_link
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
groups = soup.find_all('table', {'class':'multicol'}) # Groups being lists of bands
for group in groups:
genres.append(genre)
array = group.text.split('\n')[1:len(group.text.split('\n'))-1]
for band in array:
if (band != '0-9'):
band = string_ajustment(band)
if (band.find('Reference') > -1) or (band.find('See also') > -1): # Remove text without band name
break
elif len(band) > 1:
values = [band, genre]
data.append(pd.Series(values)) # Append bandCreating the Pandas dataframe object:
創建熊貓數據框對象:
df_bands = pd.DataFrame(data)
df_bands.columns = ['Band', 'Genre']
df_bands.drop_duplicates(inplace=True)df_bands
Adding a label to anything is hard and with music genres, it wouldn’t be different. Some bands played different styles through the years and other bands made crossovers between varying musical elements. If the band is listed in multiple Wikipedia pages, our Pandas dataframe presents it multiple times, each time with a different label/genre.
在任何事物上加上標簽都是很困難的,而且對于音樂流派來說,也沒有什么不同。 多年來,有些樂隊演奏風格各異,另一些樂隊則在不同的音樂元素之間進行了轉換。 如果樂隊在多個Wikipedia頁面上列出,則我們的Pandas數據框會多次顯示該樂隊,每次帶有不同的標簽/流派。
You might be asking how to deal with it.
您可能會問如何處理它 。
Well, it depends on your intentions with the data.
好吧,這取決于您對數據的意圖 。
If the intention is to create a genre classifier given the songs’ attributes, the most relevant label could be kept. This information could be found scrapping the number of Google Search results of the band name and the genre, for example. The one with most results should be kept. If the intention is to develop a multi output-multiclass classifier, there is no need to drop the labels.
如果打算根據歌曲的屬性創建流派分類器 ,則可以保留最相關的標簽。 例如,可以找到這些信息,刪除了樂隊名稱和流派的Google搜索結果數量。 結果最多的一個應該保留。 如果要開發多輸出多類分類器 ,則無需刪除標簽。
為什么選擇Spotify? 怎么樣? (Why Spotify? How?)
Differently from Wikipedia, Spotify provides an API for data collection. Based on this video by CodingEntrepreneurs with minor changes, we were able to collect an artists’ albums, tracks and its features. The first thing to access the API is to register your application in Spotify’s developer’s page. You’ll be able to find your client_id and your client_secret after registering.
與Wikipedia不同,Spotify提供了用于數據收集的API。 根據CodingEntrepreneurs的 這段視頻進行了微小的更改,我們就可以收集藝術家的專輯,曲目及其功能。 訪問API的第一件事是在Spotify開發人員頁面上注冊您的應用程序。 注冊后,您將可以找到client_id和client_secret 。
Before using this approach, I’ve tried using Spotipy. However, the amount of data we were trying to collect was requiring too much token refreshes (also in a non-understandable pattern). Thus, we changed our approach to match CodingEntrepreneurs’, which became much more reliable.
在使用這種方法之前,我嘗試使用Spotipy 。 但是,我們試圖收集的數據量需要太多的令牌刷新(也是一種不可理解的模式)。 因此,我們更改了方法以匹配CodingEntrepreneurs ,這變得更加可靠。
import base64
import requests
import datetime
from urllib.parse import urlencodeclient_id ='YOUR_CLIENT_ID'
client_secret = 'YOUR_CLIENT_SECRET'class SpotifyAPI(object):
access_token = None
access_token_expires = datetime.datetime.now()
access_token_did_expire = True
client_id = None
client_secret = None
token_url = 'https://accounts.spotify.com/api/token'
def __init__(self, client_id, client_secret, *args, **kwargs):
super().__init__(*args, **kwargs)
self.client_id = client_id
self.client_secret = client_secret
def get_client_credentials(self):
"""
Returns a base64 encoded string
"""
client_id = self.client_id
client_secret = self.client_secret
if (client_id == None) or (client_secret == None):
raise Exception('You must set client_id and client secret')
client_creds = f'{client_id}:{client_secret}'
client_creds_b64 = base64.b64encode(client_creds.encode())
return client_creds_b64.decode()
def get_token_headers(self):
client_creds_b64 = self.get_client_credentials()
return {
'Authorization': f'Basic {client_creds_b64}' # <base64 encoded client_id:client_secret>
}
def get_token_data(self):
return {
'grant_type': 'client_credentials'
}
def perform_auth(self):
token_url = self.token_url
token_data = self.get_token_data()
token_headers = self.get_token_headers()
r = requests.post(token_url, data=token_data, headers=token_headers)
if r.status_code not in range(200, 299):
raise Exception('Could not authenticate client.')
data = r.json()
now = datetime.datetime.now()
access_token = data['access_token']
expires_in = data['expires_in'] # seconds
expires = now + datetime.timedelta(seconds=expires_in)
self.access_token = access_token
self.access_token_expires = expires
self.access_token_did_expire = expires < now
return True
def get_access_token(self):
token = self.access_token
expires = self.access_token_expires
now = datetime.datetime.now()
if expires < now:
self.perform_auth()
return self.get_access_token()
elif token == None:
self.perform_auth()
return self.get_access_token()
return token
def get_resource_header(self):
access_token = self.get_access_token()
headers = {
'Authorization': f'Bearer {access_token}'
}
return headers
def get_resource(self, lookup_id, resource_type='albums', version='v1'):
if resource_type == 'tracks':
endpoint = f'https://api.spotify.com/{version}/albums/{lookup_id}/{resource_type}'
elif resource_type == 'features':
endpoint = f'https://api.spotify.com/{version}/audio-features/{lookup_id}'
elif resource_type == 'analysis':
endpoint = f'https://api.spotify.com/{version}/audio-analysis/{lookup_id}'
elif resource_type == 'popularity':
endpoint = f'https://api.spotify.com/{version}/tracks/{lookup_id}'
elif resource_type != 'albums':
endpoint = f'https://api.spotify.com/{version}/{resource_type}/{lookup_id}'
else:
endpoint = f'https://api.spotify.com/{version}/artists/{lookup_id}/albums' # Get an Artist's Albums
headers = self.get_resource_header()
r = requests.get(endpoint, headers=headers)
if r.status_code not in range(200, 299):
return {}
return r.json()
def get_artist(self, _id):
return self.get_resource(_id, resource_type='artists')
def get_albums(self, _id):
return self.get_resource(_id, resource_type='albums')
def get_album_tracks(self, _id):
return self.get_resource(_id, resource_type='tracks')
def get_track_features(self, _id):
return self.get_resource(_id, resource_type='features')def get_track_analysis(self, _id):
return self.get_resource(_id, resource_type='analysis')
def get_track_popularity(self, _id):
return self.get_resource(_id, resource_type='popularity')
def get_next(self, result):
""" returns the next result given a paged result
Parameters:
- result - a previously returned paged result
"""
if result['next']:
return self.get_next_resource(result['next'])
else:
return None
def get_next_resource(self, url):
endpoint = url
headers = self.get_resource_header()
r = requests.get(endpoint, headers=headers)
if r.status_code not in range(200, 299):
return {}
return r.json()
def base_search(self, query_params): # search_type = spotify's type
headers = self.get_resource_header()
endpoint = 'https://api.spotify.com/v1/search'
lookup_url = f'{endpoint}?{query_params}'
r = requests.get(lookup_url, headers=headers)
if r.status_code not in range(200, 299):
return {}
return r.json()
def search(self, query=None, operator=None, operator_query=None, search_type='artist'):
if query == None:
raise Exception('A query is required.')
if isinstance(query, dict):
query = ' '.join([f'{k}:{v}' for k, v in query.items()])
if operator != None and operator_query != None:
if (operator.lower() == 'or') or (operator.lower() == 'not'): # Operators can only be OR or NOT
operator = operator.upper()
if isinstance(operator_query, str):
query = f'{query} {operator} {operator_query}'
query_params = urlencode({'q': query, 'type': search_type.lower()})
return self.base_search(query_params)We implemented our functions to retrieve more specific data, such as band_id given band name, albums given band_id, tracks given album, features given track and popularity given track. To have more control during the process, each one of these processes were performed in a different for-loop and aggregated in a dataframe. Different approaches in this part of the data collection are encouraged, especially aiming performance gain.
我們實現了檢索特定數據的功能,例如, band_id指定樂隊名稱 , 專輯指定band_id , 曲目指定專輯 , 功能指定曲目 , 流行度指定曲目 。 為了在此過程中擁有更多控制權 ,這些過程中的每一個都在不同的for循環中執行,并匯總在一個數據幀中。 鼓勵在數據收集的這一部分采用不同的方法, 尤其是針對性能提升 。
Below, we sample the code used to catch band_id given band name.
下面,我們對用于捕獲給定樂隊名稱的band_id的代碼進行示例。
spotify = SpotifyAPI(client_id, client_secret)%%timebands_id = []
bands_popularity = []for band in df_unique['Band']:
id_found = False
result = spotify.search(query=band, search_type='artist')
items = result['artists']['items']
if len(items) > 0: # Loop to check whether more than one band is in items and retrieve desired band
i = 0
while i < len(items):
artist = items[i]
if band.lower() == artist['name'].lower():
bands_id.append(artist['id'])
bands_popularity.append(artist['popularity'])
id_found = True
break
i = i + 1
if (id_found == False) or (len(items) == 0): # If band not found
bands_id.append(np.nan)
bands_popularity.append(np.nan)df_unique['Band ID'] = bands_id
df_unique['Band Popularity'] = bands_popularity
df_unique = df_unique.dropna() # Dropping bands with uri not found
df_unique.sort_values('Band')
df_uniqueFinally, one could store it in a SQL database, but we did save it into a .csv file. At the end, our final dataframe contained 498576 songs. Not bad.
最后,可以將其存儲在SQL數據庫中,但是我們確實將其保存到.csv文件中。 最后,我們的最終數據幀包含498576首歌曲。 不錯。

下一步是什么? (What’s next?)
After collecting all this data there are many possibilities. As exposed earlier, one could create genre classifiers giving audio features. Another possibility is to use the features to create playlists/recommender systems. Regression analysis could be applied to predict song/band popularity. Last but not least, developing an exploratory data analysis could mathematically show how each genre differs from each other. What would you like to see?
收集所有這些數據之后,有很多可能性。 如前所述,可以創建提供音頻功能的流派分類器。 另一種可能性是使用這些功能來創建播放列表/推薦系統 。 回歸分析可用于預測歌曲/樂隊的受歡迎程度。 最后但并非最不重要的一點是,進行探索性數據分析可以從數學上顯示出每種流派之間的差異。 你想看見什么?
翻譯自: https://medium.com/swlh/no-data-no-problem-how-to-collect-heavy-metal-data-from-wikipedia-and-spotify-f879762046ff
spotify 數據分析
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388767.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388767.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388767.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

stack 的一些用法

IS環境下配置PHP5+MySql+PHPMyAdmin


input在iOS里的兼容性

kaggle數據集_Kaggle上有170萬份ArXiv文章的數據集
![java用接口實例化對象_[求助]迷茫中,接口可以直接實例化對象嗎?](http://pic.xiahunao.cn/java用接口實例化對象_[求助]迷茫中,接口可以直接實例化對象嗎?)
java用接口實例化對象_[求助]迷茫中,接口可以直接實例化對象嗎?
)
異常作業2(2018.08.22)

深度學習數據集中數據差異大_使用差異隱私來利用大數據并保留隱私
)
C#圖片處理基本應用(裁剪,縮放,清晰度,水印)

java建立tcp服務器長連接_B/S 架構下后端能否建立 TCP 長連接?
)
Java客戶端訪問HBase集群解決方案(優化)


PostGIS容器運行

小型數據庫_如果您從事“小型科學”工作,那么您是否正在利用數據存儲庫?

BitmapEffect位圖效果是簡單的像素處理操作。它可以呈現下面幾種特殊效果。

AutoScaling 與函數計算結合,賦予更豐富的彈性能力


java語言靜態分析工具_PMD 6.16.0 發布,跨語言靜態代碼自動分析工具
![B1922 [Sdoi2010]大陸爭霸 最短路](http://pic.xiahunao.cn/B1922 [Sdoi2010]大陸爭霸 最短路)
B1922 [Sdoi2010]大陸爭霸 最短路
