nosql
數據科學 (Data Science)
Knowledge on NoSQL databases seems to be an increasing requirement in data science applications, yet, the taxonomy is so diverse and problem-centered that it can be a challenge to grasp them. This post attempts to shed light on some of the concepts, often delving into each design’s specificities.
關于NoSQL數據庫的知識似乎已成為數據科學應用程序中日益增長的需求,但是,分類法是如此多樣且以問題為中心,以至于難以掌握它們。 這篇文章試圖闡明一些概念,經常深入研究每種設計的特性。
We start by briefly introducing NoSQL and the reasoning behind its appearance, followed by an analysis of each of the four members of the NoSQL family, their behavior, and main mechanisms, in addition to their advantages, disadvantages, and typical use cases.
我們首先簡要介紹NoSQL及其出現的原因,然后分析NoSQL家族的四個成員中的每個成員,其行為和主要機制,以及它們的優點,缺點和典型用例。
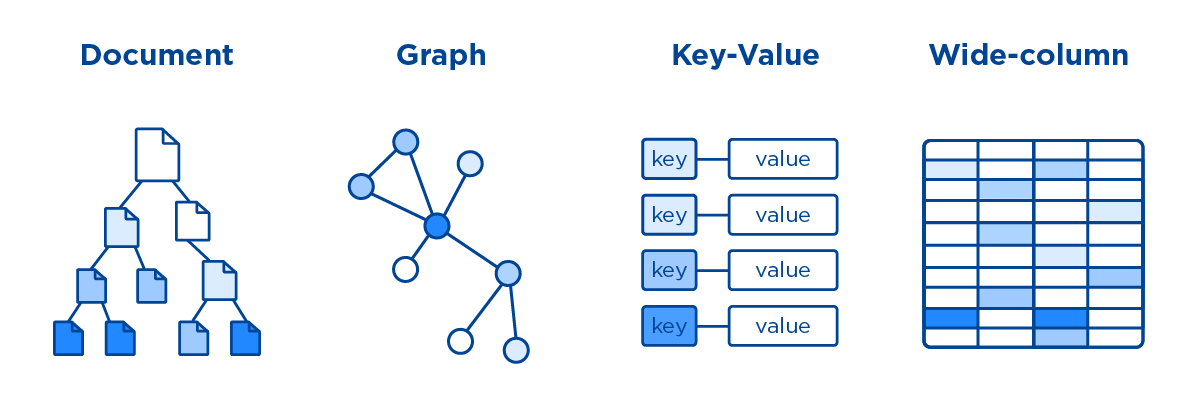
什么是NoSQL? (What is NoSQL?)
NoSQL (Not-only SQL) came into prominence in the mid-late-2000s as alternatives to traditional SQL. Instigated by the Web 2.0 industry, it allows for horizontal scaling, distributed databases, and flexible models (schema-less design). This paradigm shift means developers can focus more of their time in growing features and less time in database design. Typically, NoSQL solutions are presented as a cost-effective alternative to their SQL counterpart which relaxes RDBM’s rigidity.
NoSQL(非唯一SQL)在2000年代中期開始成為傳統SQL的替代方法。 在Web 2.0行業的倡導下,它允許水平縮放,分布式數據庫和靈活的模型(無模式設計)。 這種模式轉變意味著開發人員可以將更多的時間投入到不斷增長的功能上,而將更少的時間集中在數據庫設計上。 通常,NoSQL解決方案是其SQL替代方案的一種經濟高效的替代方案,從而減輕了RDBM的剛性。
Initially, NoSQL languages focused on key-value models effectively removing the need for SQL hence the name, NoSQL, as an abbreviation of “No SQL Support”. Over time the community realized that each tool filled a specific need, abandoning the “death to SQL” feeling over a coexistence-driven approach, with NoSQL seeing its meaning changing to “Not-only SQL”.
最初,NoSQL語言專注于鍵值模型,從而有效地消除了對SQL的需求,因此將名稱NoSQL縮寫為“ No SQL Support”。 隨著時間的流逝,社區意識到每種工具都滿足了特定的需求,并沒有采用共存驅動的方法來拋棄“ SQL的死亡”的感覺,而NoSQL則將其含義更改為“非SQL”。
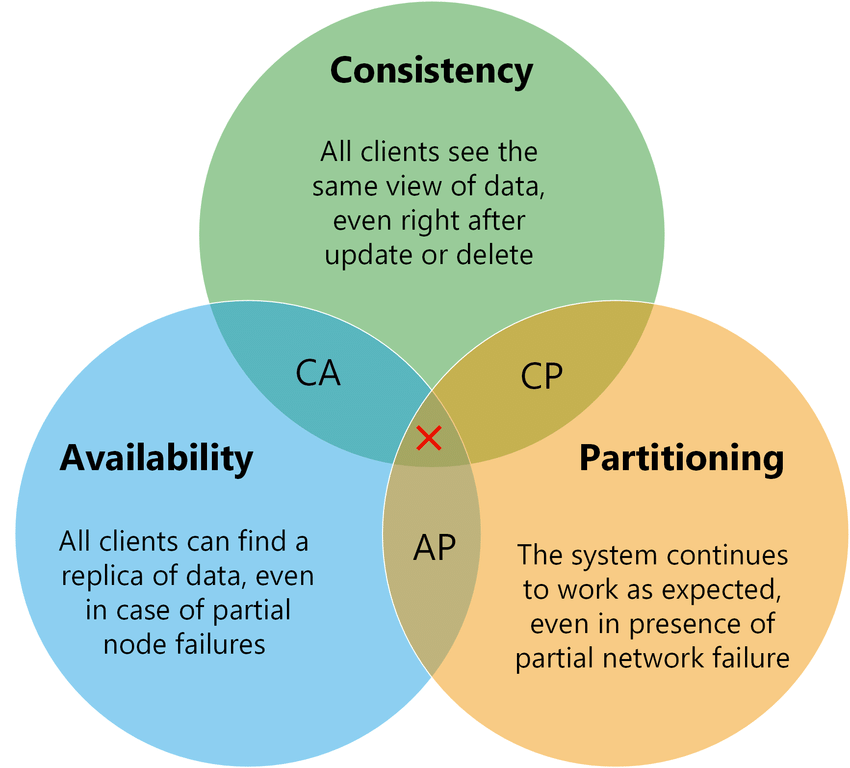
The figure on the left represents the CAP theorem, which states that is is impossible for a distributed data store to simultaneously provide more than two of the three guarantees.
左圖代表CAP定理,該定理指出,分布式數據存儲不可能同時提供三個保證中的兩個以上。
Whereas traditional RDBMs focus on the left side of the diagram, (Consistency and Availability, CA), NoSQL databases allow for horizontal partitioning and speed by sacrificing Consistency in favor of Availability and Partition Tolerance (AP).
傳統的RDBM集中在圖表的左側(一致性和可用性,CA),而NoSQL數據庫則通過犧牲一致性來支持可用性和分區容忍(AP),從而實現了水平分區和速度。
Although some do have ACID compliance, most NoSQL databases revolve around what is known as “Eventual Consistency”, abiding by the BASE properties instead. Eventual consistency stipulates that eventually, all the nodes within the cluster will contain the same data version. Referred to as stale reads, it means that multiple queries may return different results, temporarily, a direct result of relaxing the Consistency guarantee.
盡管有些確實符合ACID標準,但大多數NoSQL數據庫都圍繞著所謂的“最終一致性”,而是遵循BASE屬性。 最終的一致性規定最終,集群中的所有節點將包含相同的數據版本。 稱為過時的讀取,意味著多個查詢可能暫時返回不同的結果,這是放寬一致性保證的直接結果。
So when to use NoSQL? Simply put: when ACID compliance is not a requirement, fast and cheap scalability is mandatory or your application falls into the Big Data category.
那么何時使用NoSQL? 簡而言之:當不需要ACID合規性時,必須具有快速廉價的可伸縮性,或者您的應用程序屬于大數據類別。
Before proceeding, keep in mind that NoSQL design is drastically different from that of its RDBMs counterparts, in the former, data tends to be denormalized and often repeated as storage is considered a cheap commodity when compared with access speed and availability. This paradigm combined with the no consistency guarantee is bound to generate temporary divergences.
在繼續之前,請記住NoSQL設計與RDBM的設計完全不同,在前者中,數據趨于非規范化并且經常重復,因為與訪問速度和可用性相比,存儲被認為是便宜的商品。 這種范例與不一致性保證相結合必然會產生暫時的分歧。
Note #1: Several authors consider that NoSQL has clearly failed its goal, paving the way for the accommodation of NoSQL-like features in traditional SQL via NewSQL or Distributed SQL. But let us skip this topic for the time being.
注意事項1:幾位作者認為NoSQL顯然沒有實現其目標,這為通過NewSQL或Distributed SQL在傳統SQL中容納類似NoSQL的功能鋪平了道路。 但是,讓我們暫時跳過此主題。
Note #2: Some Document-Value NoSQL databases allow for ACID-like transactions as long as performed within the same collection, referred to as entity group transactions in Azure Table Storage; MongoDB added support for ACID-like distributed transactions in version 4.2.
注意#2:某些Document-Value NoSQL數據庫允許類似ACID的事務,只要在同一集合中執行,即在Azure表存儲中稱為實體組事務; MongoDB在版本4.2中添加了對類似于ACID的分布式事務的支持。
Note #3: Some SQL databases are able to combine horizontal sharding/scaling and distributed queries using, for instance, the Citus extension for PostgresSQL.
注意#3:某些SQL數據庫能夠使用例如用于PostgresSQL的Citus擴展來組合水平分片/擴展和分布式查詢。
鍵值數據庫 (Key-Value Databases)
The simplest flavor of NoSQL databases revolves around the concept of associative arrays, in other words, it simply ties a given key to a record of any type, from a simple string or JSON to video files.
NoSQL數據庫的最簡單形式圍繞著關聯數組的概念,換句話說,它簡單地將給定鍵與 任何類型 的記錄 (從簡單的字符串或JSON到視頻文件)聯系起來。
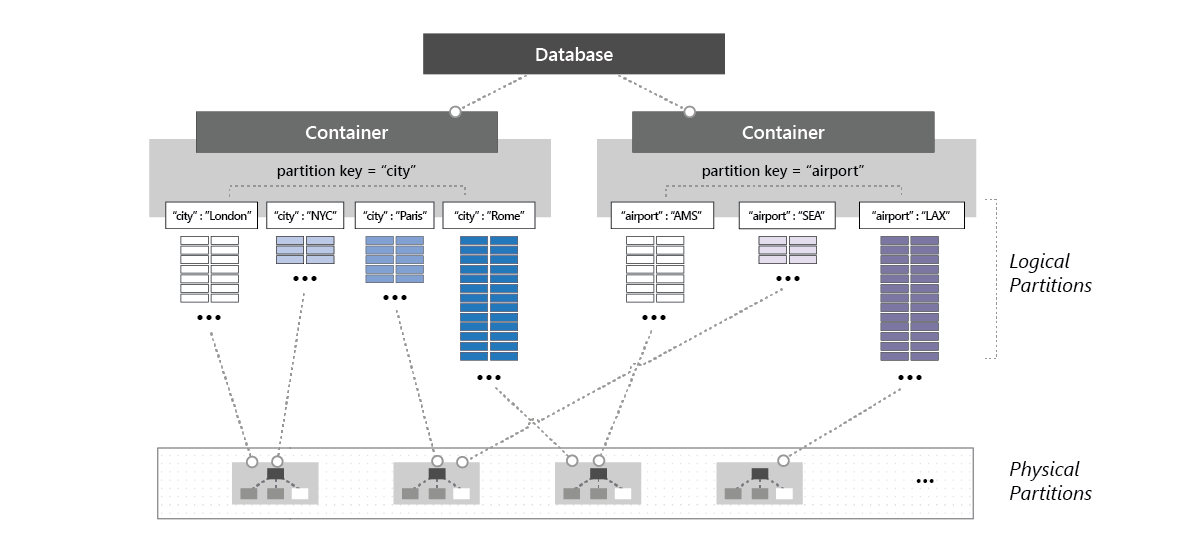
Key-value databases are organized into partitions or buckets, which can contain one or several entities, and each record is represented by a unique row key. Records in turn contain one or multiple fields. The concept of partition and row keys is one of the most critical aspects of NoSQL as it allows for logical partitions (defined by the partition key) to be moved around physical partitions (nodes) according to their workload. At the same time, its one of the major hindrances for newcomers: selecting the wrong key will spell disaster should your queries not take advantage of the selected key, and once you’ve selected it, there is no turning back.
鍵值數據庫組織為分區或存儲桶,可以包含一個或幾個實體,每個記錄由唯一的行鍵表示。 記錄又包含一個或多個字段。 分區鍵和行鍵的概念是NoSQL的最關鍵方面之一,因為它允許邏輯分區(由分區鍵定義)根據工作負載在物理分區(節點)周圍移動。 同時,這也是新來者的主要障礙之一:如果您的查詢沒有利用所選的鍵,那么選擇錯誤的鍵將帶來災難,一旦選擇,就無法回頭。
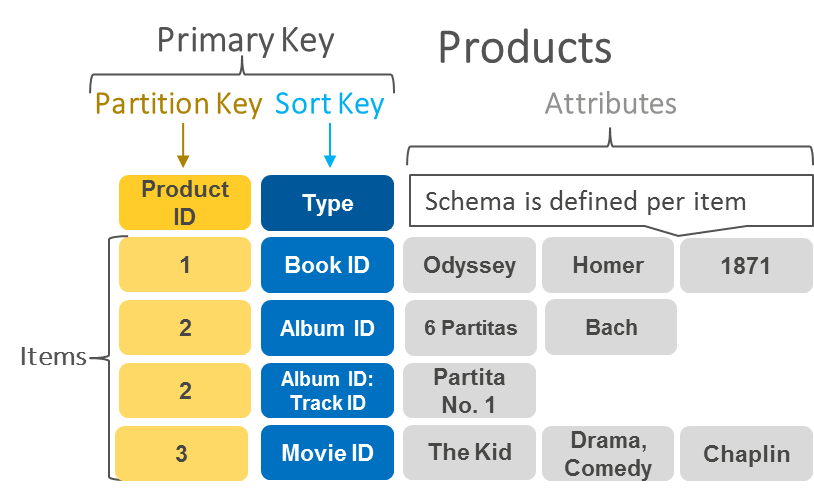
The choice of the partition key and row key is particularly challenging for key-value databases given you can only query via its key. What does this mean? In key-value terms, a JSON can be represented by a horizontal diagram with the id field representing the record’s key which is linked to the JSON’s values.
分區鍵和行鍵的選擇對于鍵值數據庫特別具有挑戰性,因為您只能通過其鍵查詢。 這是什么意思? 用鍵值術語,JSON可以用水平圖表示,其中id字段表示記錄的鍵,該鍵鏈接到JSON的值。
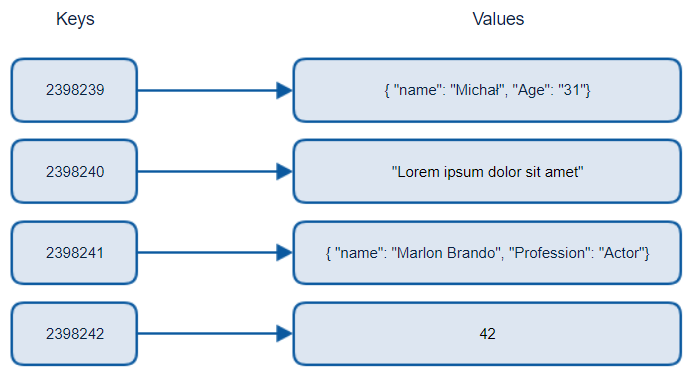
As long as you know the partition and record keys, CRUD operations are blazing fast. But what if you want to retrieve all cases where the “name” field equals “Michal”? Unlike in document databases, fields are not automatically indexed, which means that such a query will require going through every record to see if it contains the “name” field and it is equal to “Michal” — analogous to a full table scan in SQL. I hope this clarifies how important row key selection is, and why its important to know the system’s purpose beforehand. Of course, these systems are not designed to be field-queried, but we’re merely stating their limitations as a general-purpose database.
只要您知道分區和記錄鍵,CRUD操作就可以快速進行。 但是,如果要檢索“名稱”字段等于“ Michal”的所有情況怎么辦? 與文檔數據庫中的字段不同,字段不會自動建立索引,這意味著此類查詢將需要遍歷每條記錄以查看其是否包含“名稱”字段并且等于“ Michal”,這與SQL中的全表掃描類似。 我希望這可以弄清行鍵選擇的重要性,以及為什么事先知道系統目的很重要。 當然,這些系統并非旨在進行現場查詢,而只是在說明它們作為通用數據庫的局限性。
A typical key would be anything that can be considered to be unique, customerID, supplierID, sessionID, etc. Most developers opt for using composite keys, for instance, UserID.session would store session data; UserID.user in turn would represent the user’s cached information, simplifying the value for single fields instead of a dictionary-like structure, speeding up CRUD operations.
典型的密鑰可以是任何可以視為唯一的密鑰, customerID , supplierID , sessionID等 。 大多數開發人員選擇使用復合鍵,例如, UserID.session將存儲會話數據。 UserID.user依次表示用戶的緩存信息,從而簡化了單個字段的值,而不是類似字典的結構,從而加快了CRUD操作。
How about partition keys? In the beginning, we stated that partition keys allow for the system to move partitions around according to their workload. Hence the obvious and most direct consequence of improper partition key selection is creating hot partitions — groups of entities that are frequently accessed but can’t be distributed given they operate as a single unit (a single partition). With this in mind, a partition could be the UserID, whilst the keys would represent different user attributes, UserID.Name, UserID.Location, UserID.Height. If a physical partition contains several hot logical partitions (e.g. a set of users that request data frequently) the engine is able to distribute the logical partitions spreading the workload across different clusters. Without an appropriate partition key, the logical partition may be unary thus impossible to distribute.
分區鍵如何? 首先,我們說過分區鍵允許系統根據其工作負荷來移動分區。 因此,分區鍵選擇不正確的最明顯和最直接的結果就是創建了熱分區-經常訪問但不能作為實體運行(因為它們作為一個單元(一個分區)運行)的實體組。 考慮到這一點,分區可以是UserID ,而鍵則代表不同的用戶屬性UserID.Name , UserID.Location , UserID.Height 。 如果物理分區包含多個熱邏輯分區(例如,一組頻繁請求數據的用戶),則引擎能夠分配邏輯分區,從而將工作負載分散到不同的群集中。 沒有適當的分區鍵,邏輯分區可能是一元的,因此無法分發。
Another important feature of key-value databases is the fact that their records can have a time to live (TTL), an automatic expiration date that can be controlled. This makes them strong candidates for session-driven storage.
鍵值數據庫的另一個重要特征是它們的記錄可以有生存時間(TTL),這是可以控制的自動到期日期。 這使它們成為會話驅動存儲的理想候選者。
Advantages
優點
- Scalability 可擴展性
- Very fast read speed 讀取速度非常快
- Simple and flexible data model 簡單靈活的數據模型
Disadvantages
缺點
- No relationship between entities 實體之間沒有關系
- No transaction-like behavior 沒有類似交易的行為
- Only per-key queries are supported 僅支持每鍵查詢
- No support for retrieving multiple keys at once 不支持一次檢索多個密鑰
- Slow multiple updates and collection scans 減慢多個更新和集合掃描的速度
Vendors
供應商
- Redis 雷迪斯
- Riak 里亞克
- Memcached 記憶快取
- Azure Table Store Azure表存儲
Use cases
用例
- Web session cache Web會話緩存
- Store user preferences 存儲用戶首選項
文件資料庫 (Document Databases)
Document Store databases build on the concept behind key-value, extending it to support complex multi-layered objects named documents. This seemingly simple difference has several consequences: because the engine is familiar with the multi-level or nested concept, all fields, including nested fields, are indexed allowing for specific field query and selection; documents can be queried against themselves but not between each other; denormalized design patterns allow for direct data retrieval without requiring joins; some document store databases implement ACID-like properties.
Document Store數據庫建立在鍵值背后的概念上,并將其擴展為支持名為文檔的復雜多層對象。 這種看似簡單的差異會帶來多種后果:由于引擎熟悉多級或嵌套概念,因此對所有字段(包括嵌套字段)都進行了索引,以允許進行特定的字段查詢和選擇; 可以查詢自己的文件,但不能互相查詢; 非規范化設計模式允許直接數據檢索而無需聯接; 一些文檔存儲數據庫實現類似于ACID的屬性。
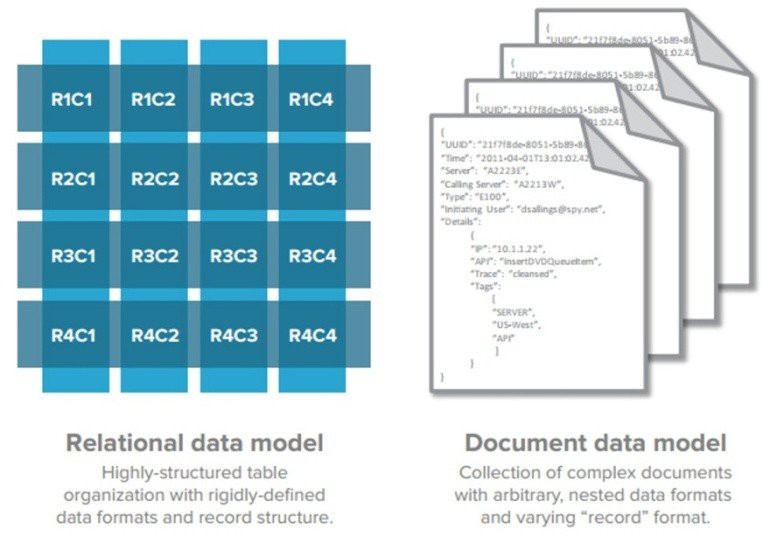
Each document can be thought of as a row in a relational model only the former’s schema is not predefined not the object type needs to be equal.
可以將每個文檔視為關系模型中的一行,只有前者的架構未預定義,而對象類型不需要相等。

Like its key-value predecessor, document databases are also structured into collections which in turn, contain partitions and their nested entities. The same caution on selecting partition and document (not row) keys are mandatory. However, as stated above, the values in a document database are automatically indexed allowing them to be queried. Nonetheless, the query’s efficiency will still be drastically hindered by querying fields.
像其鍵值前身一樣,文檔數據庫也被構造為集合,這些集合又包含分區及其嵌套實體。 在選擇分區和文檔(非行)鍵時,同樣的警告是必須的。 但是,如上所述,文檔數據庫中的值會自動建立索引,以便對其進行查詢。 但是,查詢字段仍然會嚴重阻礙查詢的效率。
Note that due to this document-oriented structure, unlike its key-value counterpart, in document store databases there isn’t a strong need to create composite keys since per-field access is integrated within the engine.
請注意,由于這種面向文檔的結構(與鍵值對應物不同),在文檔存儲數據庫中,由于在引擎中集成了按字段訪問,因此不需要創建復合鍵。
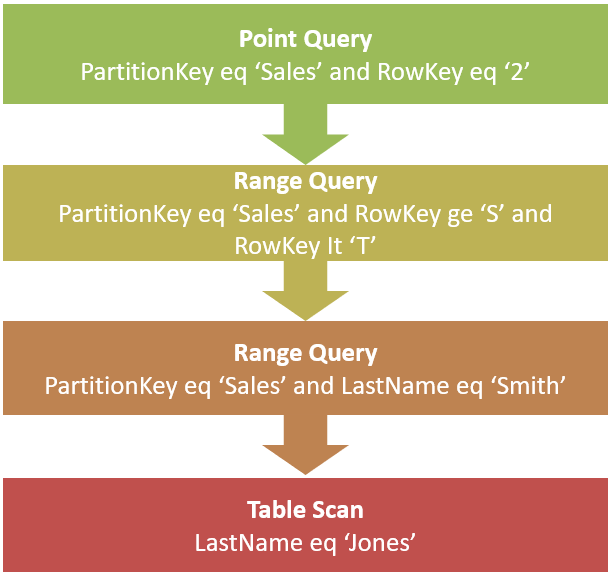
The following diagram showcases the performance obtained per query type in Azure Cosmos DB, although extensible to a document store database. The diagram flows from the most efficient, point query, to the less efficient, table scans.
下圖展示了Azure Cosmos DB中按查詢類型獲得的性能,盡管可以擴展到文檔存儲數據庫。 該圖從效率最高的點查詢到效率較低的表掃描。
At the start of this primer we stipulated that NoSQL databases are located in the AP spectrum of the CAP theorem. In practice, due to continuous developments, some NoSQL databases have the ability to switch between CAP guarantees, allowing the developer to create tailored solutions.
在本入門的開始,我們規定NoSQL數據庫位于CAP定理的AP頻譜中。 實際上,由于不斷的發展,某些NoSQL數據庫具有在CAP保證之間切換的能力,從而使開發人員可以創建量身定制的解決方案。


Advantages
優點
- Scalability for complex objects 復雜對象的可伸縮性
- Document-oriented data model, JSON or XML allows for complex and schema-less structure 面向文檔的數據模型,JSON或XML允許復雜且無模式的結構
- Supports queries and joins within the document 支持查詢和文檔內的聯接
- Data modeling paradigm allows storing all the data in a single document 數據建模范例允許將所有數據存儲在一個文檔中
- Fast read and writes 快速讀寫
Disadvantages
缺點
- Data modeling paradigm leads to having data duplicated among documents 數據建模范例導致數據在文檔之間重復
- Complex design leads to inconsistency 復雜的設計導致不一致
Vendors
供應商
- MongoDB MongoDB
- Azure Document DB Azure文檔數據庫
- AWS Dynamo DB AWS Dynamo數據庫
- OrientDB 東方數據庫
- CouchDB CouchDB
Use cases:
用例:
- Social networks 社交網絡
- eCommerce 電子商務
- Anything in which you can relax ACID compliance 任何可以放松ACID合規性的地方
列族數據庫 (Column Family Databases)
Column family databases share concepts with both RDBMS and key-value stores. You can think of the rows as keys in a key-value store, and the columns as the value. Their optimal use case is for large data ingestion or data analytics, being suitable for storing billions of rows and tens of thousands of columns.
列族數據庫與RDBMS和鍵值存儲共享概念。 您可以將行視為鍵值存儲中的鍵,將列視為值。 它們的最佳用例是用于大數據攝取或數據分析,適合存儲數十億行和數萬列。
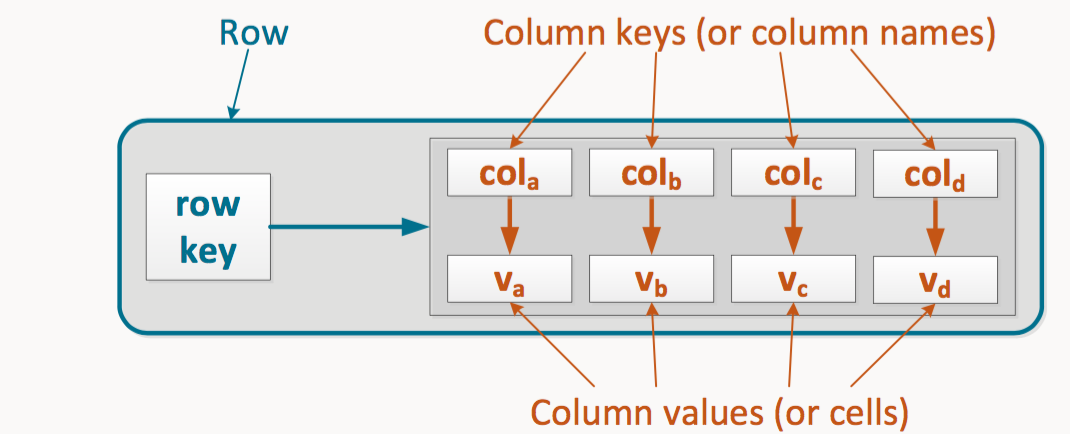
The data model behind the column means it can efficiently handle sparse matrices, a major hindrance to traditional RDBMS. Whereas in the latter all columns must be filled — recall NULL is a value and the occupied space corresponds to the column’s type — occupying storage, the former does not, in fact, it only stores existing values per column, for each row (or key).
該列后面的數據模型意味著它可以有效地處理稀疏矩陣,這是傳統RDBMS的主要障礙。 在后一種情況下,必須填充所有列-回憶NULL是一個值,并且已占用的空間對應于該列的類型-占用存儲空間,實際上前者并沒有為每行(或鍵)僅存儲每列的現有值)。
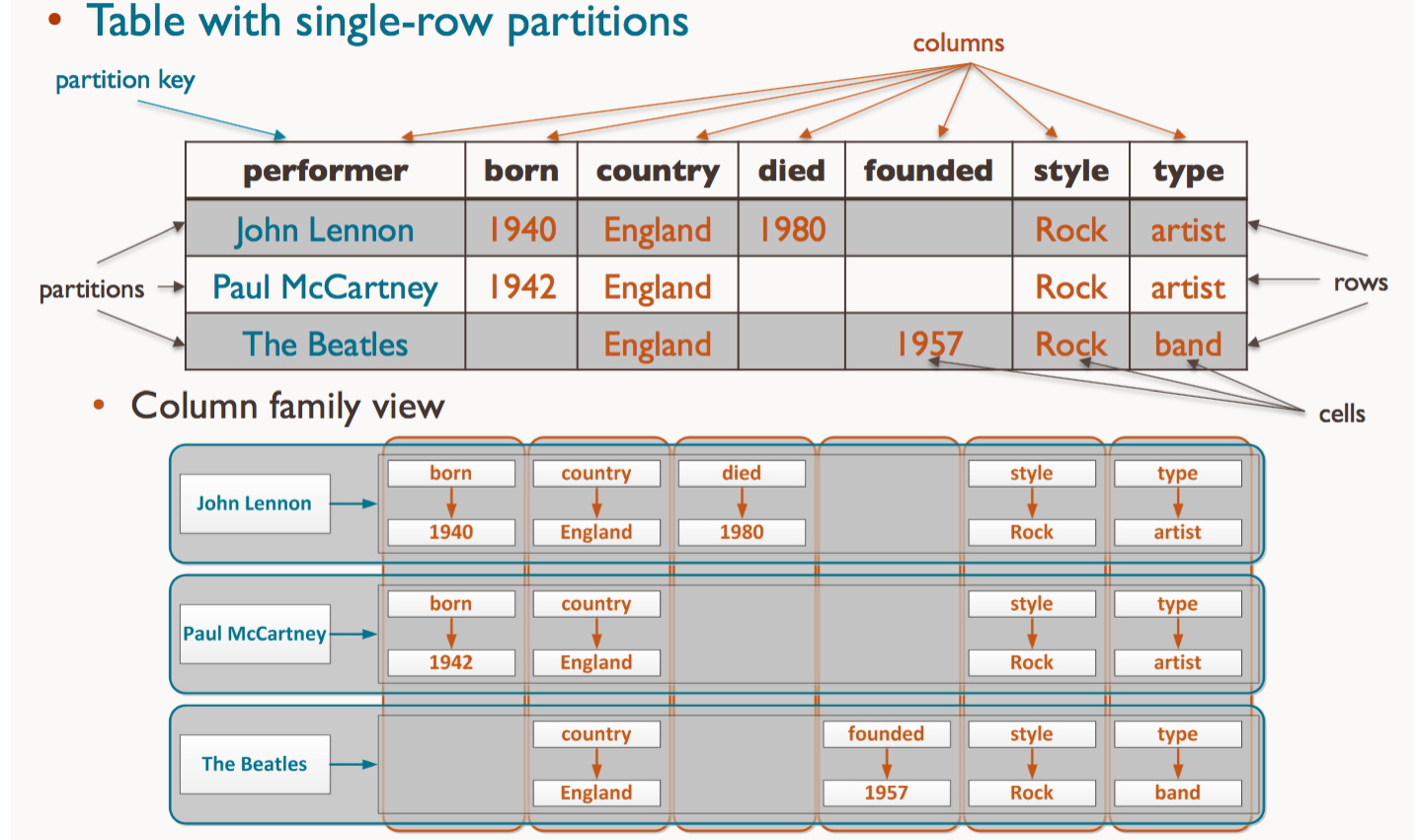
In the previous figure, notice how the keys “John Lennon” and “Paul McCartney” do not have a value set for the founded column, where you see a gap is actually a non-existing column. You can think of the columns as a variable-length collection — e.g. a Dictionary in Python — where each item is optional. In such a case, the first row could be represented in Python as:
在上圖中,請注意鍵“ John Lennon”和“ Paul McCartney”是如何沒有為founded列設置值的,在該列中您實際上看到的是一個不存在的空白。 您可以將這些列視為可變長度的集合(例如,Python中的Dictionary),其中每個項目都是可選的。 在這種情況下,第一行可以用Python表示為:
As expected, just like in the other members of the NoSQL family, the choice of partition key plays a critical role, as it dictates what is stored contiguously and what can be broken into smaller chunks in addition to speeding up the index-based queries.
正如預期的那樣,就像在NoSQL系列的其他成員中一樣,分區鍵的選擇起著至關重要的作用,因為它決定了連續存儲的內容以及除加速基于索引的查詢之外還可以分解成較小的塊的內容。
Advantages
優點
- Scalability 可擴展性
- Fast write/read 快速寫入/讀取
Disadvantages
缺點
- Update/modification operations are slow 更新/修改操作緩慢
Vendors
供應商
- Cassandra 卡桑德拉
- HBase HBase的
- Google BigTable Google BigTable
- Druid 德魯伊
Use cases:
用例:
- Telemetry 遙測
- IoT 物聯網
- Reporting 報告中
圖數據庫 (Graph Databases)
The last NoSQL database types shift the focus onto the relationship between entities. Entities, such as users, are represented by nodes, whereas the connections between entities dictate how they are related.
最后一種NoSQL數據庫類型將重點轉移到實體之間的關系上。 諸如用戶之類的實體由節點表示,而實體之間的連接決定了它們之間的關系。
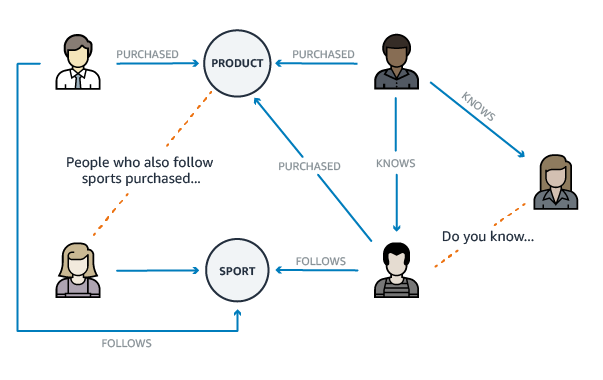
Graph databases store the relationship information within each node, by doing so, the need for lookup operations needed in relational databases is removed, saving much-needed resources.
圖形數據庫將關系信息存儲在每個節點內,這樣就消除了對關系數據庫中所需的查找操作的需求,從而節省了急需的資源。
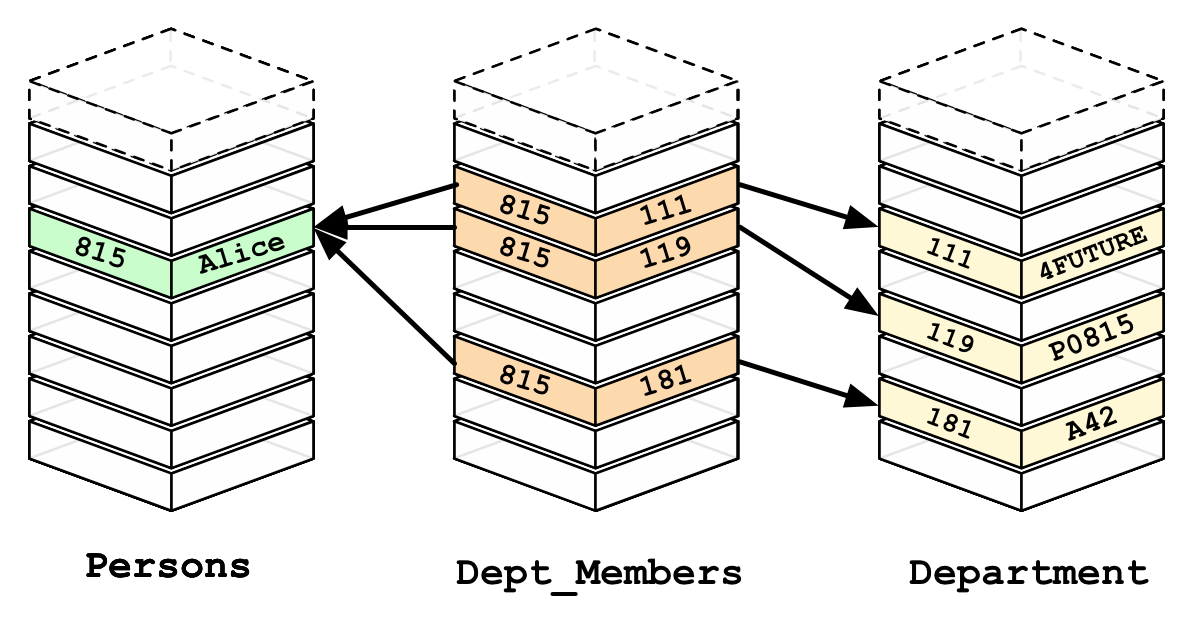
The graph database on the other hand, as the relations are pre-computed, queries are faster as they do not require a lookup.
另一方面,由于圖形數據庫是預先計算的關系,因此查詢更快,因為它們不需要查找。
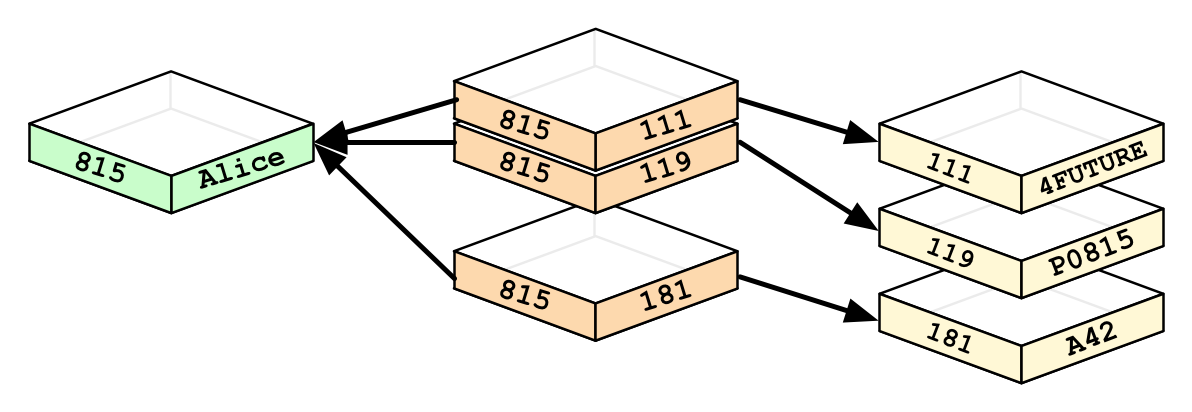
Vendors
供應商
- Neo4j Neo4j
- OrientDB 東方數據庫
- ArangoDB ArangoDB
Use cases:
用例:
- Knowledge Graphs 知識圖
- Identity Graphs 身份圖
- Fraud Detection 欺詐識別
- Recommendation Engines 推薦引擎
- Social Networks 社交網絡
結論 (Conclusion)
Like in most technologies, it is the developer’s responsibility to select the tool suited for the problem at hand. The first pillar is always the same: make sure you understand the business problem at hand before delving into the technology.
與大多數技術一樣,開發人員有責任選擇適合當前問題的工具。 第一個Struts始終是相同的:在研究技術之前,請確保您了解手頭的業務問題。
Hopefully, this post helped you in said goal!
希望這篇文章對您達成目標有所幫助!
Next up: NewSQL and Distributed SQL, thanks for reading!
接下來:NewSQL和分布式SQL,感謝您的閱讀!
翻譯自: https://medium.com/towards-artificial-intelligence/exploring-the-nosql-family-49e9f23313ad
nosql
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388543.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388543.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388543.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

C++TCP和UDP屬于傳輸層協議

程序員如何利用空閑時間掙零花錢

編寫程序乘法口訣表C語言,陳廣川問:c語言編程九九乘法口訣表 怎樣用c語言寫九九乘法口訣表?...

PHP中文亂碼解決辦法

python中api_通過Python中的API查找相關的工作技能
識別欺詐性的招聘廣告)
欺詐行為識別_使用R(編程)識別欺詐性的招聘廣告

PE文件的感染C++源代碼

c語言實驗四報告,湖北理工學院14本科C語言實驗報告實驗四數組


rabbitmq channel參數詳解【轉】
)
感染EXE文件代碼(C++)

nlp gpt論文_GPT-3:NLP鎮的最新動態

真實不裝| 阿里巴巴新人上路指北


tomcat java環境配置

uber 數據可視化_使用R探索您在Uber上的活動:如何分析和可視化您的個人數據歷史記錄
Ribbon)
java B2B2C springmvc mybatis電子商城系統(四)Ribbon

c語言函數的形參有幾個,C中子函數最多有幾個形參

Linux上Libevent的安裝
