TensorFlow Probability uses structural time series models to conduct time series forecasting. In particular, this library allows for a “scenario analysis” form of modelling — whereby various forecasts regarding the future are made.
TensorFlow概率使用結構時間序列模型進行時間序列預測。 尤其是,該庫允許進行“情景分析”形式的建模,從而做出有關未來的各種預測。
Structural time series modelling takes the inherent characteristics of the time series into account when making forecasts. This includes factors such as the local linear trend, seasonal, residual and autoregressive components. The greater the variation surrounding these components — the more uncertain the forecast.
結構時間序列建模在進行預測時會考慮時間序列的固有特征。 這包括局部線性趨勢 , 季節 , 殘差和自回歸成分等因素。 這些組件之間的差異越大,預測就越不確定。
The examples illustrated in this article use the template from the Structural Time Series modeling in TensorFlow Probability tutorial, of which the original authors (Copyright 2019 The TensorFlow Authors) have made available under the Apache 2.0 license.
本文中說明的示例使用TensorFlow概率教程中的結構時間序列建模中的模板,該模板的原始作者(Copyright 2019 The TensorFlow Authors)已獲得Apache 2.0許可。
聯合航空旅客數據 (United Airlines Passenger Data)
For this example, a structural time series model is built in TensorFlow Probability to forecast air passenger data. The data is sourced from San Francisco Open Data: Air Traffic Passenger Statistics.
對于此示例,在TensorFlow概率中構建了一個結構時間序列模型來預測航空乘客數據。 該數據來自“舊金山開放數據:空中交通旅客統計” 。
In particular, passenger numbers for United Airlines from February 2014 — June 2020 are analysed. The specific segment of passengers analysed are enplaned, domestic, departing from Terminal 3 at Boarding Area E.
特別是分析了2014年2月至2020年6月聯合航空的乘客數量。 從3號航站樓E登機區出發的經過分析的特定旅客是國內旅客。
Here is a visual overview of the time series:
這是時間序列的直觀概述:
We can see that passenger numbers have traditionally ranged between 200,000 to 350,000 — before plummeting to a low of 7,115 in May 2020.
我們可以看到,旅客人數傳統上介于200,000至350,000之間,然后在2020年5月跌至7,115的低點。
It is wishful thinking to expect that any time series model would have been able to forecast this — such a drop was very sudden and completely out of line with the overall trend.
一廂情愿的期望是,任何時間序列模型都能夠預測到這一點-這種下降是非常突然的,并且與總體趨勢完全不符。
However, could TensorFlow Probability have potentially identified a drop of a similar scale? Let’s find out.
但是,TensorFlow概率是否有可能識別出類似規模的下降? 讓我們找出答案。
TensorFlow概率模型 (TensorFlow Probability Model)
The model is fitted with a local linear trend, along with a monthly seasonal effect.
該模型符合局部線性趨勢以及每月的季節性影響。
def build_model(observed_time_series):
trend = sts.LocalLinearTrend(observed_time_series=observed_time_series)
seasonal = tfp.sts.Seasonal(
num_seasons=12, observed_time_series=observed_time_series)
residual_level = tfp.sts.Autoregressive(
order=1,
observed_time_series=observed_time_series, name='residual')
autoregressive = sts.Autoregressive(
order=1,
observed_time_series=observed_time_series,
name='autoregressive')
model = sts.Sum([trend, seasonal, residual_level, autoregressive], observed_time_series=observed_time_series)
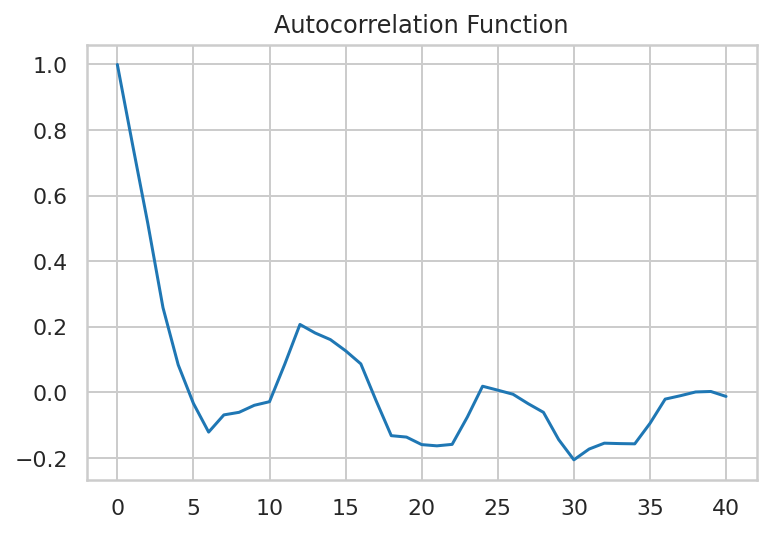
return modelNote that since autocorrelation is detected as being present in the series — an autoregressive component is also added to the model.
請注意,由于檢測到序列中存在自相關,因此還將自回歸分量添加到模型中。
Here is a plot of the autocorrelation function for the series:
這是該系列的自相關函數的圖:
The time series is split into training and test data for the purposes of comparing the forecasts with the actual values.
時間序列分為訓練和測試數據,目的是將預測值與實際值進行比較。
The forecast is made using the assumption of a posterior distribution — that is, a distribution comprised of the prior distribution (prior data) and a likelihood function.
預測是使用后驗分布 (即由先驗分布(先驗數據)和似然函數組成的分布)的假設進行的。
In order to effect this forecast, the TensorFlow Probability model minimises the loss in the variational posterior as follows:
為了實現此預測,TensorFlow概率模型將變后驗中的損失最小化,如下所示:
#@title Minimize the variational loss.# Allow external control of optimization to reduce test runtimes.
num_variational_steps = 200 # @param { isTemplate: true}
num_variational_steps = int(num_variational_steps)optimizer = tf.optimizers.Adam(learning_rate=.1)
# Using fit_surrogate_posterior to build and optimize the variational loss function.@tf.function(experimental_compile=True)
def train():
elbo_loss_curve = tfp.vi.fit_surrogate_posterior(
target_log_prob_fn=tseries_model.joint_log_prob(
observed_time_series=tseries_training_data),
surrogate_posterior=variational_posteriors,
optimizer=optimizer,
num_steps=num_variational_steps)
return elbo_loss_curveelbo_loss_curve = train()plt.plot(elbo_loss_curve)
plt.title("Loss curve")
plt.show()# Draw samples from the variational posterior.
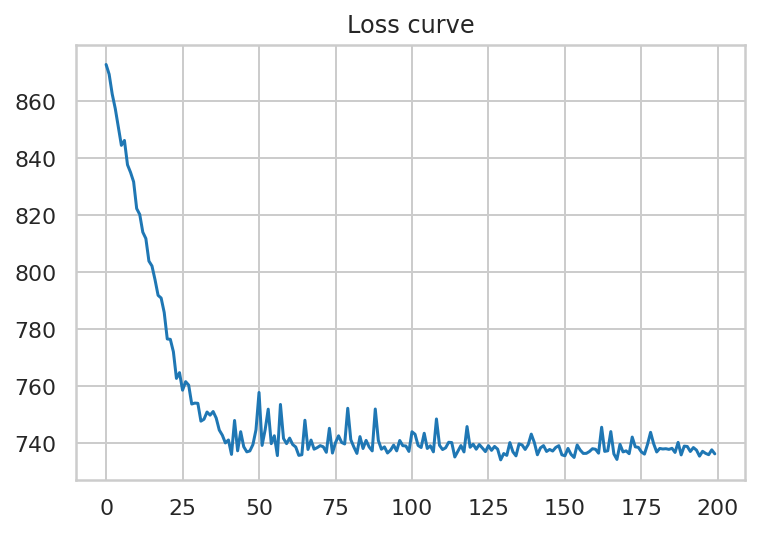
q_samples_tseries_ = variational_posteriors.sample(50)Here is a visual of the loss curve:
這是損耗曲線的外觀:
預報 (Forecasts)
20 samples (or 20 separate forecasts) are made using the model:
使用該模型制作了20個樣本(或20個單獨的預測):
# Number of scenarios
num_samples=20tseries_forecast_mean, tseries_forecast_scale, tseries_forecast_samples = (
tseries_forecast_dist.mean().numpy()[..., 0],
tseries_forecast_dist.stddev().numpy()[..., 0],
tseries_forecast_dist.sample(num_samples).numpy()[..., 0])Here is a plot of the forecasts:
這是預測的圖:
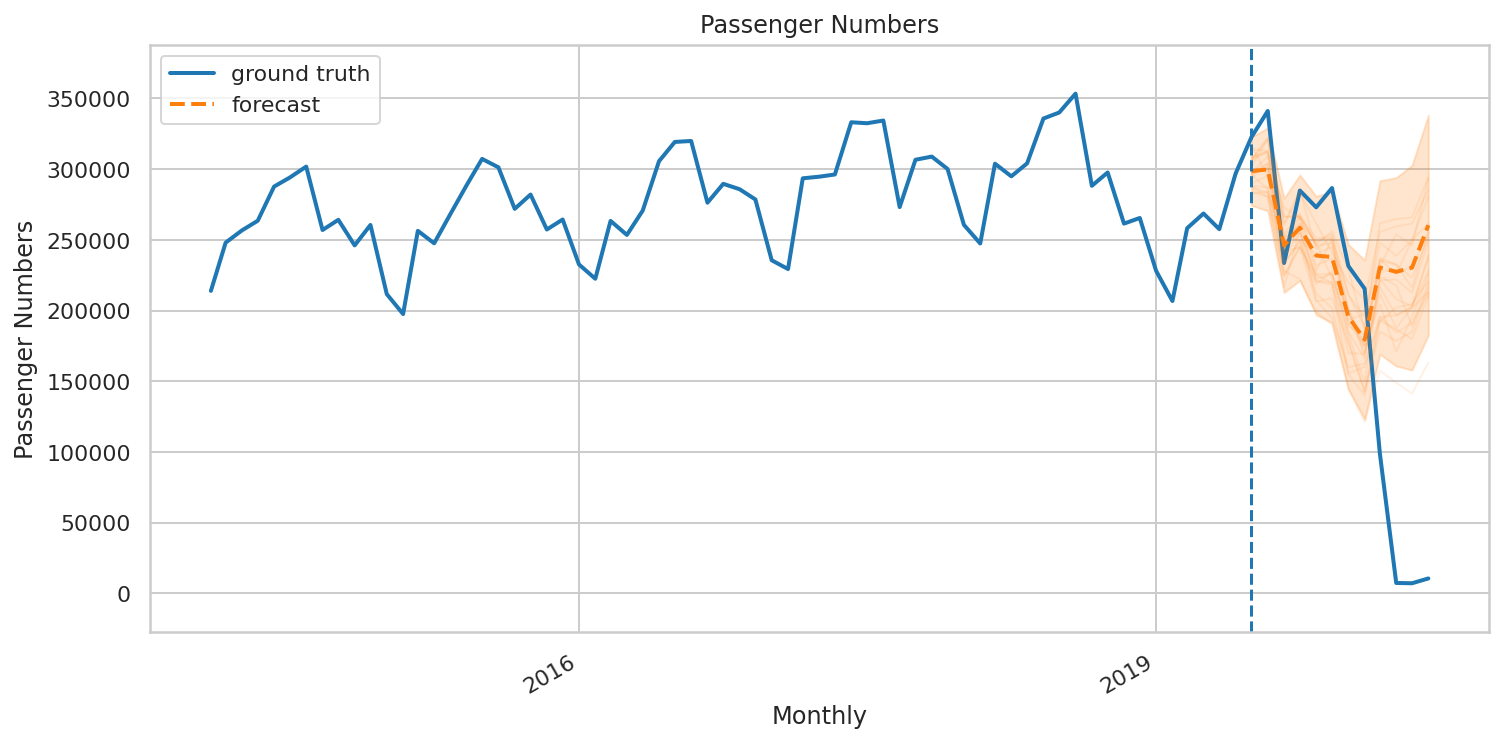
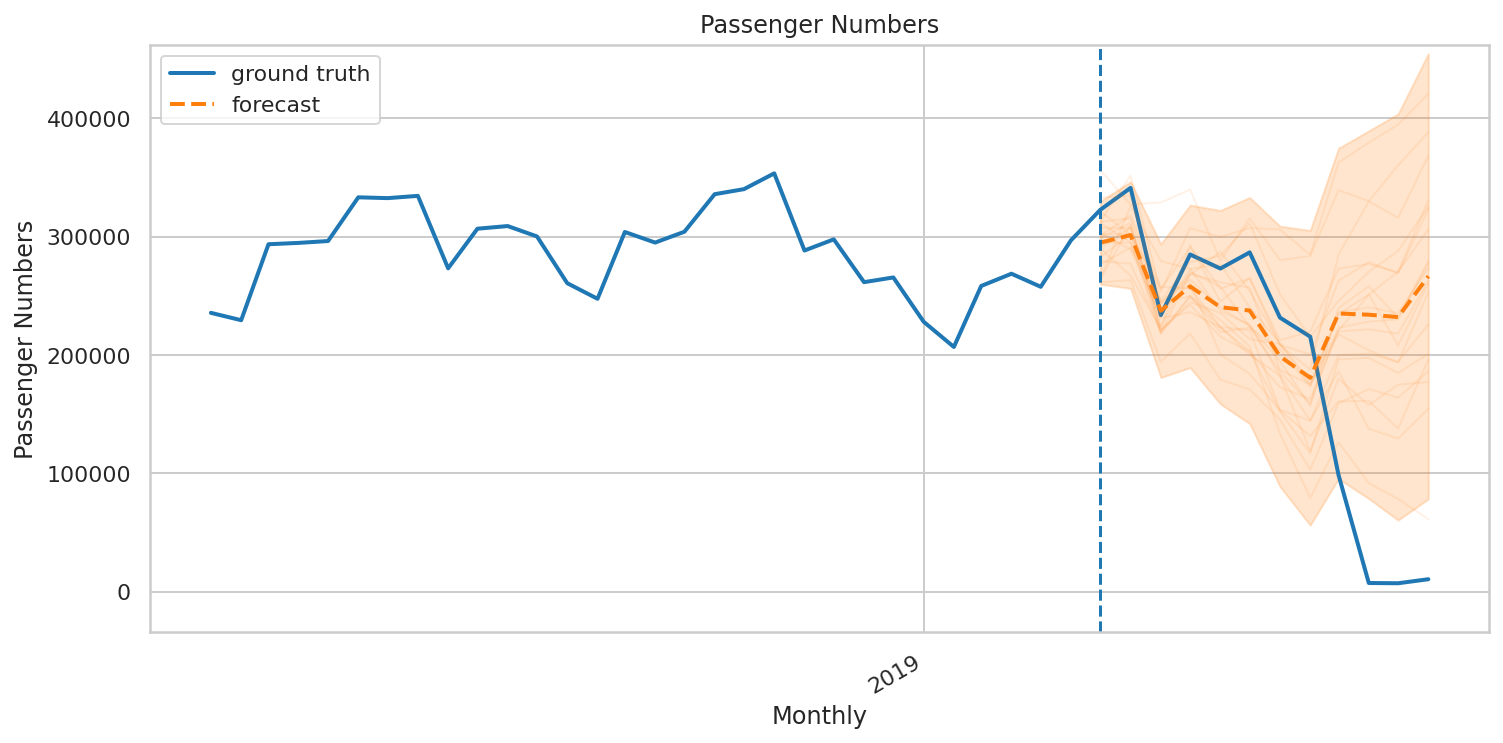
We can see that while the worst case scenario forecasted a drop to 150,000 passengers — the model generally could not forecast the sharp drop we have seen in passenger numbers.
我們可以看到,即使在最壞的情況下,預測的乘客量將下降到15萬人,但該模型通常無法預測我們所看到的乘客人數的急劇下降。
Here is an overview of the time series components:
以下是時間序列組件的概述:
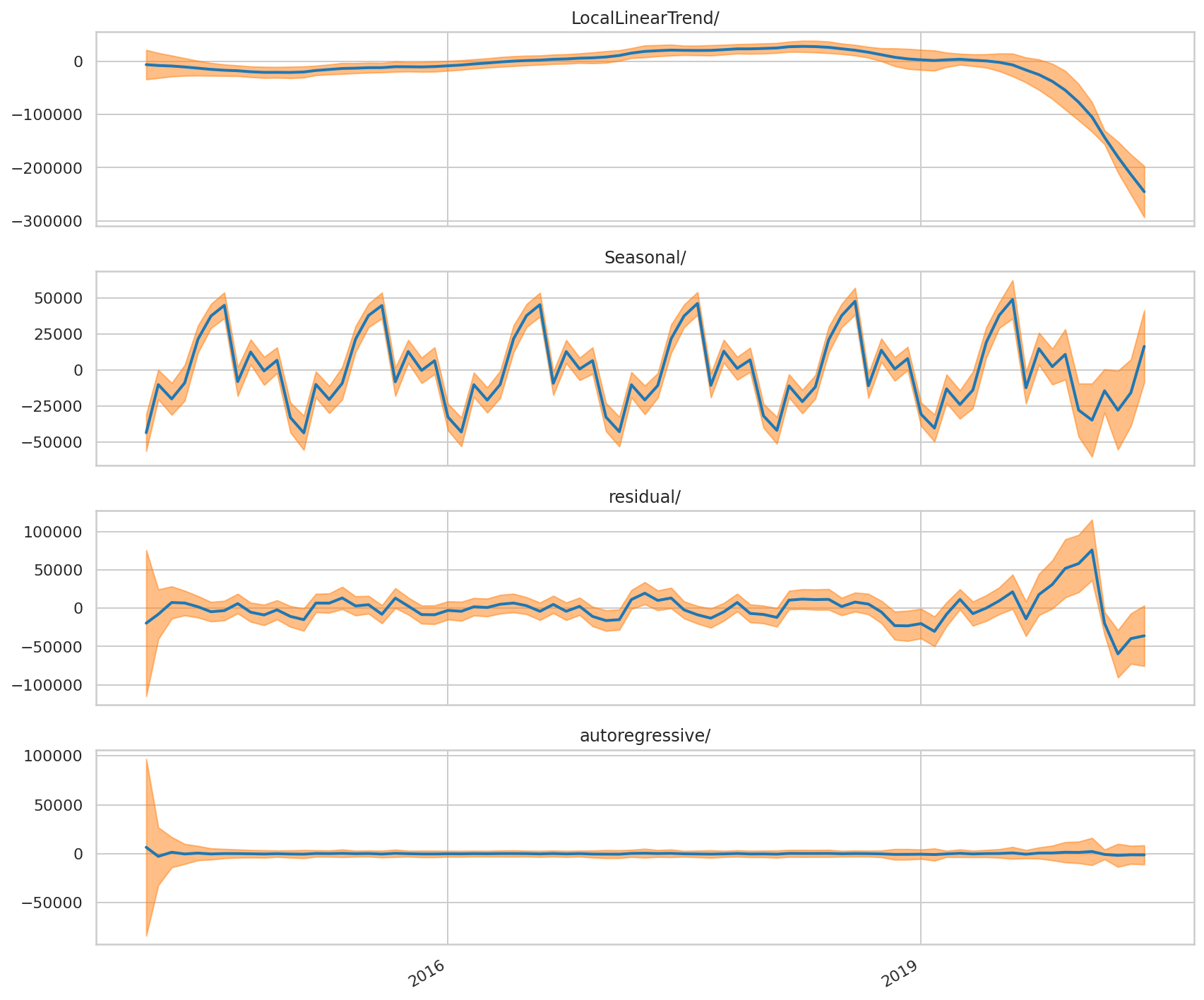
In particular, we can see that towards the end of the series — we see a widening of variation in the autoregressive and seasonal components — indicating that the forecasts have become more uncertain as a result of this higher variation.
特別是,我們可以看到在系列末期(我們看到自回歸和季節成分的變化范圍擴大了),這表明由于這種較高的變化,預測變得更加不確定。
However, what if we were to shorten the time series? Let’s rebuild the model using data from January 2017 onwards and see how this affects the forecast.
但是,如果我們要縮短時間序列怎么辦? 讓我們使用2017年1月以后的數據重建模型,看看這如何影響預測。
We can see that the “worst-case scenario” forecast comes in at roughly 70,000 or so. While this is still significantly above the actual drop in passenger numbers — this model is doing a better job at indicating that a sharp drop in passenger numbers potentially lies ahead.
我們可以看到“最壞情況”的預測大約為70,000。 盡管這仍大大高于實際的乘客人數下降,但該模型在表明潛在的乘客人數急劇下降方面做得更好。
Let’s analyse the time series components for this forecast:
讓我們分析此預測的時間序列成分:
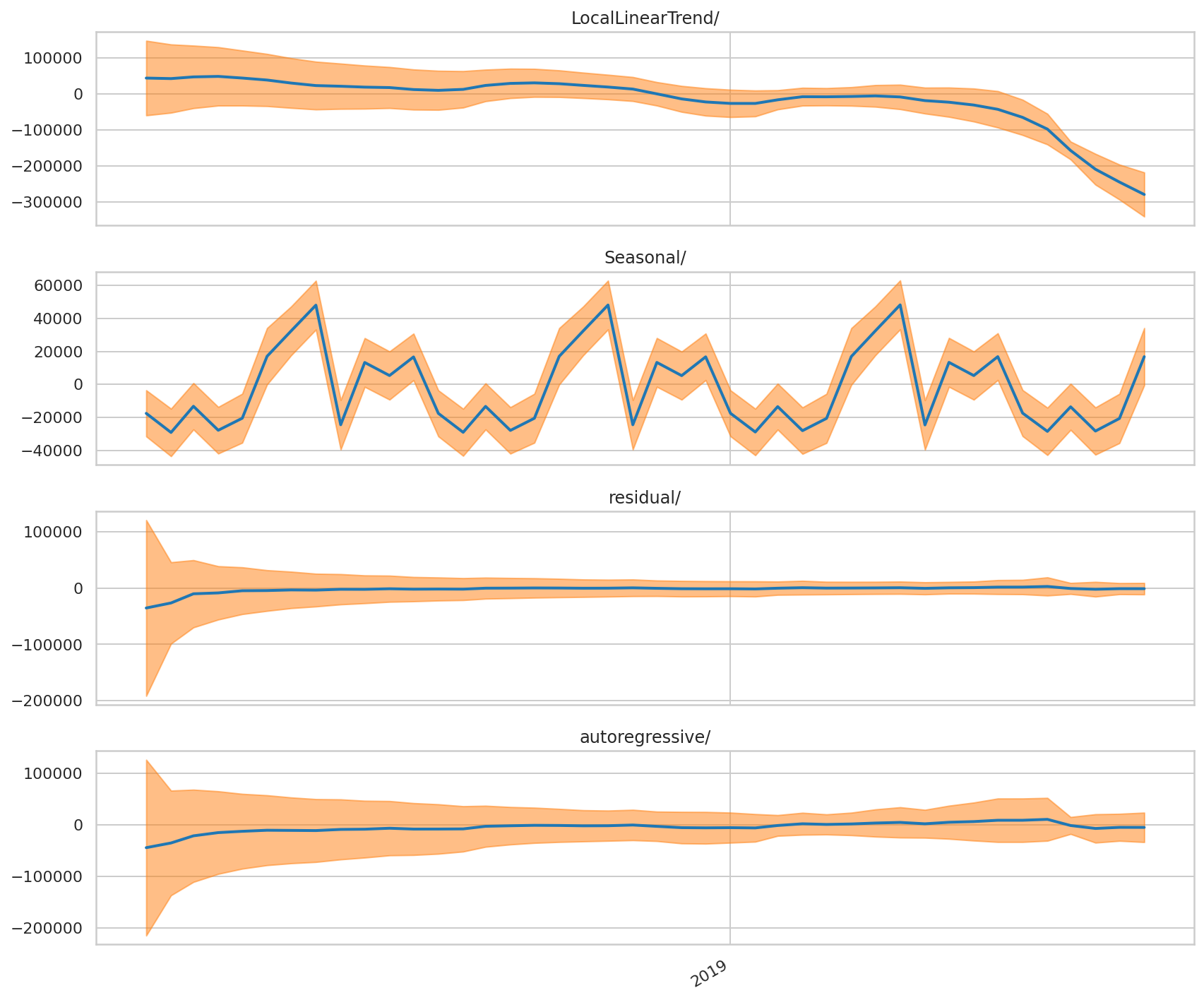
Unlike in the last forecast, we can see that the autoregressive, residual and seasonal components are actually narrowing in this instance — indicating more certainty behind the forecasts. In this regard, incorporating more recent data into this forecast has allowed the model to determine that a significant drop in passenger numbers could lie ahead — which ultimately came to pass.
與上次預測不同,我們可以看到在這種情況下自回歸,殘差和季節性成分實際上正在縮小,這表明預測的確定性更高。 在這方面,將更多最新數據納入此預測已使該模型能夠確定未來可能會出現旅客數量的大幅下降,而這種下降最終將成為現實。
Note that a main forecast (as indicated by the dashed orange line) is also given. Under normal circumstances, the model indicates that while there would have been a dip in passenger numbers to 200,000 — numbers would have rebounded to 250,000 in June. This is still less than the nearly 300,000 passengers recorded for the month of June — indicating that downward pressure on passenger numbers was an issue before COVID-19 — though nowhere near to that which has actually transpired, of course.
注意,還給出了主要預測(如橙色虛線所示)。 在正常情況下,該模型表明,盡管旅客人數將下降至20萬人,但6月份的人數將回升至25萬人。 這仍然低于6月份記錄的近30萬名乘客-這表明在COVID-19之前,乘客人數的下降壓力是一個問題-當然,距離實際發生的事情還差得很遠。
結論 (Conclusion)
This has been an overview of how TensorFlow Probability can be used to conduct forecasts — in this case using air passenger data.
這是如何使用TensorFlow概率進行預測的概述-在這種情況下,使用航空乘客數據。
Hope you found this article of use, and any feedback or comments are greatly welcomed. The code and datasets for this example can be found at my GitHub repository here.
希望您能找到本文的使用,并歡迎任何反饋或意見。 該示例的代碼和數據集可以在我的GitHub存儲庫中找到 。
Disclaimer: This article is written on an “as is” basis and without warranty. It was written with the intention of providing an overview of data science concepts, and should not be interpreted as professional advice in any way.
免責聲明:本文按“原樣”撰寫,不作任何擔保。 它旨在提供數據科學概念的概述,并且不應以任何方式解釋為專業建議。
翻譯自: https://towardsdatascience.com/forecasting-air-passenger-numbers-with-tensorflow-probability-1b53e5e5fea2
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388474.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388474.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388474.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

python畫激活函數圖像

計算機網絡管理SIMP,計算機網絡管理實驗報告.docx


pdf.js插件使用記錄,在線打開pdf

程序員 sql面試_非程序員SQL使用指南

Apache+Tomcat集群負載均衡的兩種session處理方式

SmartSVN:File has inconsistent newlines

我要認真學Git了 - Config

計算機科學與技術科研論文,計算機科學與技術學院2007年度科研論文一覽表

r a/b 測試_R中的A / B測試

一臺機器同時運行兩個Tomcat

PHP獲取IP地址的方法,防止偽造IP地址注入攻擊

工作10年厭倦寫代碼_厭倦了數據質量討論?


oracle數據庫 日志滿了
.docx)
計算機應用基礎學生自查報告,計算機應用基礎(專科).docx


模擬一個簡單計算器_閱讀模擬器的簡單介紹

