r a/b 測試
什么是A / B測試? (What is A/B Testing?)
A/B testing is a method used to test whether the response rate is different for two variants of the same feature. For instance, you may want to test whether a specific change to your website like moving the shopping cart button to the top right hand corner of your web page instead of on the right hand panel changes the number of people that click on the shopping cart and buy a product.
A / B測試是一種用于測試同一功能的兩個變體的響應率是否不同的方法。 例如,您可能想測試對網站的特定更改(例如將購物車按鈕移至網頁的右上角而不是在右側面板上)是否會更改點擊購物車的人數,以及購買產品。
A/B testing is also called split testing where two variants of the same web page are shown to different samples from your population of visitors to the website at the same time. Then, the number of conversions are compared for the two variants. Generally, the variant that gives a higher proportion of variants is the winning variant.
A / B測試也稱為拆分測試,在該測試中,同一網頁的兩個變體會同時顯示來自您網站訪問者群體的不同樣本。 然后,比較兩個變體的轉化次數。 通常,給出較高比例變體的變體是獲勝變體。
However, as this is a data science blog, we want to ensure that the difference in proportion of conversions for the two variants is statistically significant. We may also want to understand what attributes of the visitors is driving those conversions. So, let’s move on to your data problem.
但是,由于這是一個數據科學博客,我們希望確保兩個變體的轉換比例差異在統計上是顯著的。 我們可能還想了解訪問者的哪些屬性正在推動這些轉化。 因此,讓我們繼續您的數據問題。
數據問題 (The Data Problem)
- An A/B test was recently run and the Product Manager of your company wants to know whether the new variant of the web page resulted in more conversions. Make a recommendation to your Product Manager based on your analysis 最近運行了A / B測試,您公司的產品經理想知道網頁的新版本是否帶來了更多的轉化。 根據您的分析向產品經理提出建議
- The CRM Manager is interested in knowing how accurately we can predict whether users are likely to engage with our emails based on the attributes we collected about the users when they first visit the website. Report back to the CRM Manager on your findings. CRM經理有興趣了解如何根據用戶首次訪問網站時收集到的有關用戶的屬性來預測用戶是否可能與我們的電子郵件互動。 向您的CRM報告報告您的發現。
數據集 (The Dataset)
Four datasets are provided.
提供了四個數據集。
- Visits contains data from 10,000 unique users and has the following columns: 訪問次數包含來自10,000個唯一用戶的數據,并包含以下列:
- user_id: unique identifier for the user user_id:用戶的唯一標識符
- visit_time: timestamp indicating date and time of visit to website visit_time:表示網站訪問日期和時間的時間戳記
- channel: marketing channel that prompted the user to visit the website 渠道:提示用戶訪問網站的營銷渠道
- age: user’s age at time of visiting website 年齡:用戶訪問網站時的年齡
- gender: user’s gender 性別:用戶的性別
- Email engagement contains data on those users that engaged with a recent email campaign. The file contains the following columns: 電子郵件參與度包含有關最近參與電子郵件活動的那些用戶的數據。 該文件包含以下列:
- user_id: unique identifier for the user user_id:用戶的唯一標識符
- clicked_on_email: flag to indicate that the user engaged with the email where 1 indicates that the user clicked on the email clicked_on_email:標志,表示用戶與電子郵件互動,其中1表示用戶單擊了電子郵件
- Variations contains data indicating which of the variations each user saw of the A/B test. The file has the following columns: 變體包含指示每個用戶在A / B測試中看到了哪些變體的數據。 該文件包含以下列:
- user_id: unique identifier for the user user_id:用戶的唯一標識符
- variation: variation (control or treatment) that the user saw 差異:用戶看到的差異(控制或處理)
- Test conversions contains data on those users that converted as a result of the A/B test. The file contains the following columns: 測試轉換包含有關由于A / B測試而轉換的用戶的數據。 該文件包含以下列:
- user_id: unique identifier for the user user_id:用戶的唯一標識符
- converted: flag to indicate that the user converted (1 for converted convert:標志,指示用戶已轉換(1表示已轉換
導入數據集并清理 (Importing the dataset and cleaning)
I always start by first combining the files using a primary key or a unique identifier. I then decide what to do with the data. I find this approach useful as I can get rid of what I don’t need later. It also helps me view the dataset on a holistic level.
我總是首先使用主鍵或唯一標識符組合文件。 然后,我決定如何處理數據。 我發現這種方法很有用,因為我以后可以擺脫不需要的東西。 這也有助于我全面地查看數據集。
In this instance, our unique identifier is user_id. After merging the files using the following code,
在這種情況下,我們的唯一標識符是user_id。 使用以下代碼合并文件后,
merge_1<-merge(variations_df,visits_df,by.x="user_id",by.y="user_id")
merge_2<-merge(merge_1,test_conv_df,by.x="user_id",by.y="user_id",all.x=TRUE)
merge_3<-merge(merge_2,eng_df,by.x="user_id",by.y="user_id",all.x=TRUE)I discovered that I had to create my own binary variable for whether or not a user converted and whether or not they had clicked on an email. This was based on their user ID not being found in the test_conversions.csv and email_engagement.csv files. I did this by replacing all “NA”s with 0's.
我發現我必須創建自己的二進制變量來確定用戶是否轉換以及他們是否單擊了電子郵件。 這是基于在test_conversions.csv和email_engagement.csv文件中找不到用戶ID的原因。 我通過將所有“ NA”替換為0來做到這一點。
merge_3$converted<-if_else(is.na(merge_3$converted),0,1)
merge_3$clicked_on_email<-if_else(is.na(merge_3$clicked_on_email),0,1)
merge_3$converted<-as.factor(merge_3$converted)
merge_3$clicked_on_email<-as.factor(merge_3$clicked_on_email)The next task was to convert variables like visit time into information that would provide meaningful information on the users.
下一個任務是將諸如訪問時間之類的變量轉換為可以為用戶提供有意義信息的信息。
merge_3$timeofday<- mapvalues(hour(merge_3$visit_time),from=c(0:23),
to=c(rep("night",times=5), rep("morning",times=6),rep("afternoon",times=5),rep("night", times=8)))
merge_3$timeofday<-as.factor(merge_3$timeofday)Now, that the data had been cleaned it was time to explore the data to understand whether there was an association between user conversion and the variation they visited on the website.
現在,已經清理了數據,是時候探索數據了,以了解用戶轉換與他們在網站上訪問的變化之間是否存在關聯。
數據探索和可視化 (Data Exploration and Visualization)
The simplest aspect of the data to check for is to determine whether there is indeed a difference in the proportion of users that converted based on the type of variation they viewed. Running the code provided at the end of the blog post gives the following graph and proportions:
要檢查的數據最簡單的方面是,根據他們查看的變化類型來確定轉化用戶的比例是否確實存在差異。 運行博客文章末尾提供的代碼將給出以下圖形和比例:
control : 0.20 treatment : 0.24
控制:0.20處理:0.24
統計測試對A / B測試的重要性 (Statistical testing for significance of A/B Testing)
To test whether the difference in proportions is statistically significant, we can either carry out a difference in proportions test or a chi-squared test of independence where the null hypothesis is that there is no association between whether or not a user converted and the type of variation they visited.
為了檢驗比例差異是否在統計上具有顯著性,我們可以進行比例差異檢驗或獨立性的卡方檢驗,其中零假設是用戶是否轉換與用戶類型之間沒有關聯。他們參觀的變化。
For both tests, a p-value < 0.05 was observed indicating a statistically significant difference in proportions.
對于兩種測試,均觀察到p值<0.05,表明各比例的統計學差異顯著。
I went a step further and ran logistic regression to understand how the other attributes of the users contributed to the difference in proportions. Only the type of variation and income (p-values less than 0.05) appeared to contribute to the difference in conversion proportions. A calculation of McFadden’s R-squared tells us that only 12.94% of the variation in proportions can be explained by the variation type and user attributes provided within our dataset. Hence, my response to the Product Manager would be as follows:
我走了一步,并進行了邏輯回歸,以了解用戶的其他屬性如何導致比例差異。 僅差異類型和收入類型(p值小于0.05)對轉化比例的差異有所貢獻。 麥克法登(McFadden)的R平方計算表明,只有12.94%的比例變化可以由我們數據集中提供的變化類型和用戶屬性來解釋。 因此,我對產品經理的回復如下:
There is a statistically significant difference in conversion rates for those that visited the treatment variation vs the control variation. However, it is difficult to understand why this is the case. It would be best to repeat this test 2–3 more times to cross-validate results.
訪視治療差異與對照差異的轉化率在統計上存在顯著差異。 但是,很難理解為什么會這樣。 最好再重復進行2-3次此測試以交叉驗證結果。
探索性數據分析,以了解用戶參與電子郵件的動因 (Exploratory Data Analysis to understand drivers of user engagement with emails)
Barplots were produced to check for a visual relationship between user attributes and whether or not they clicked on an email.
制作了條形圖,以檢查用戶屬性之間的視覺關系以及它們是否單擊了電子郵件。
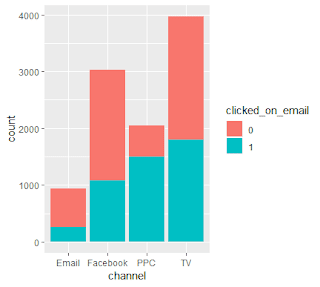
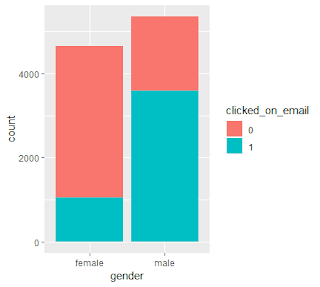
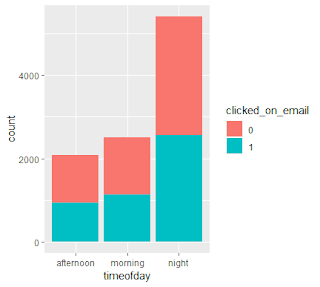
While running the exploratory data analysis, I noticed that the age was missing for 1,243 users. These users were omitted from analysis as I cannot impute their ages without any knowledge. Boxplots and numerical summaries were produced to understand any difference in average age of users that clicked on emails.
在進行探索性數據分析時,我注意到1,243位用戶缺少該年齡。 由于我無法在沒有任何知識的情況下估算他們的年齡,因此從分析中忽略了這些用戶。 制作了箱線圖和數字摘要,以了解單擊電子郵件的用戶平均年齡的任何差異。
It was found that those that clicked on emails (“1”) on average had higher income than those that didn’t. However, both groups have very high standard deviations, thus income does not appear to be a useful indicator.
結果發現,平均而言,點擊電子郵件的人(“ 1”)的收入要高于沒有點擊電子郵件的人。 但是,兩組的標準差都很高,因此收入似乎不是有用的指標。
使用統計建模進行重要性測試 (Using statistical modelling for significance testing)
The dataset was randomly split into training (70%) and test (30%) sets for modelling. Logistic regression was run to determine which attributes had a statistically significant contribution in explaining whether users clicked or did not click on an email.
數據集被隨機分為訓練(70%)和測試(30%)集以進行建模。 運行Logistic回歸以確定在解釋用戶是否單擊電子郵件時,哪些屬性在統計上具有重要作用。
The model was trained on the training set and predictions were carried out on the test set for accuracy. An ROC curve was generated by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings. The AUC is the area under the ROC curve. As a rule of thumb, a model with good predictive ability should have an AUC closer to 1 (1 is ideal) than to 0.5. In our example, we have an AUC of 0.84, showing pretty good accuracy.
在訓練集上對模型進行了訓練,并在測試集上進行了準確性的預測。 通過在各種閾值設置下繪制真實陽性率(TPR)相對于陰性陽性率(FPR)繪制ROC曲線。 AUC是ROC曲線下的面積。 根據經驗,具有良好預測能力的模型的AUC應該接近于1(理想值為1)而不是接近0.5。 在我們的示例中,我們的AUC為0.84,顯示出非常好的準確性。
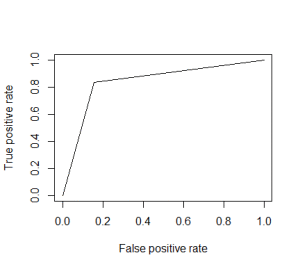
Though the score is good, it would be good to carry out some form of cross-validation to validate the results further and ensure reproducibility.
盡管分數不錯,但最好進行某種形式的交叉驗證以進一步驗證結果并確保可重復性。
A summary of the logistic regression model confirms what we saw visually that the top predictors of the likelihood of a user clicking on an email are:
logistic回歸模型的摘要確認了我們在視覺上看到的結果,即用戶單擊電子郵件的可能性最大的預測因素是:
- channel
-頻道
- age
-年齡
- gender
- 性別
My response to the CRM Manager would be that the top predictors of email conversion are age (older users are more likely to click), channel (PPC being popular amongst users that click) and gender (males are more likely to click than females). However, I would like to validate these results via a larger sample to allow for cross-validation.
我對CRM Manager的回答是,電子郵件轉換的主要預測因素是年齡(老用戶點擊的可能性更高),渠道(PPC在點擊用戶中很受歡迎)和性別(男性比女性更有可能點擊)。 但是,我想通過更大的樣本來驗證這些結果,以便進行交叉驗證。
最后的想法 (Final Thoughts)
Hopefully, this blog post has demystified A/B testing to some extent, given you some ways to test for statistical significance and shown you how exploratory data analysis and statistical testing work together to validate results.
希望該博客文章在一定程度上消除了A / B測試的神秘性,為您提供了一些測試統計意義的方法,并向您展示了探索性數據分析和統計測試如何共同驗證結果。
Please note that a very small sample size was used in this example (around 4000 users) and as such it did not make sense to run and train a complex machine learning algorithm.
請注意,在此示例中使用了非常小的樣本量(大約4000個用戶),因此運行和訓練復雜的機器學習算法沒有意義。
I would love your feedback and suggestions and all useful code is provided below and on github for download. :)
我希望收到您的反饋和建議,所有有用的代碼都在下面和github上提供,以供下載。 :)
https://gist.github.com/shedoesdatascience/de3c5d3c2c88132339347c7da838a126
https://gist.github.com/shedoesdatascience/de3c5d3c2c88132339347c7da838a126
翻譯自: https://towardsdatascience.com/a-b-testing-in-r-ae819ce30656
r a/b 測試
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388464.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388464.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388464.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

一臺機器同時運行兩個Tomcat

PHP獲取IP地址的方法,防止偽造IP地址注入攻擊

工作10年厭倦寫代碼_厭倦了數據質量討論?


oracle數據庫 日志滿了
.docx)
計算機應用基礎學生自查報告,計算機應用基礎(專科).docx


模擬一個簡單計算器_閱讀模擬器的簡單介紹

計算機部分應用顯示模糊,win10系統打開部分軟件字體總顯示模糊的解決方法-電腦自學網...


假如不工作了,你還有源源不斷的收入嗎?

turtle 20秒畫完小豬佩奇“社會人”

最佳子集aic選擇_AutoML的起源:最佳子集選擇

Java虛擬機內存溢出

spring boot構建

用戶輸入漢字時計算機首先將,用戶輸入漢字時,計算機首先將漢字的輸入碼轉換為__________。...

從最終用戶角度來看外部結構_從不同角度來看您最喜歡的游戲

apache+tomcat配置

記自己在spring中使用redis遇到的兩個坑
