程序員 sql面試
Today, the word of the moment is DATA, this little combination of 4 letters is transforming how all companies and their employees work, but most people don’t really know how data behaves or how to access it and they also think that this is just for the tech dude from the IT team or someone who knows to code.
今天,關鍵是DATA,這四個字母的小組合正在改變所有公司及其員工的工作方式,但是大多數人并不真正了解數據的行為方式或訪問方式,他們還認為這僅僅是來自IT團隊或知道編碼的人的技術花花公子。
So this article is going to explain a part of this complex world in an easy way and we shall begin by the beginning… the data.
因此,本文將以一種簡單的方式來解釋這個復雜世界的一部分,我們將從頭開始……數據。
Basically, we can segment data into two groups, Structured and Unstructured.
基本上,我們可以將數據分為兩組,即結構化和非結構化 。

As you can see, Unstructured data is way more abundant than Structured, but despite that what is more common to use in the usual day-to-day is the Structured one and this occurs for some reasons as:
如您所見,非結構化數據比結構化數據要豐富得多,盡管如此,在日常日常使用中更常見的是結構化數據,這種情況發生的原因如下:
- Can be displayed in rows and columns 可以顯示在行和列中
- Requires less storage 需要更少的存儲空間
- Easier to manage and manipulate 易于管理和操縱
I’m not here to say that this 80% is not important, quite the opposite, but it’s just a bit more complex to deal with it so it’s no the focus of this text.
我并不是要說這80%并不重要,恰恰相反,但是處理起來稍微復雜一點,所以它不是本文的重點。
Having this explained, we know that our objective is to learn a little bit of how can we access and manipulate this kind of data.
對此進行了解釋后,我們知道我們的目標是學習一些有關如何訪問和操作此類數據的知識。
結構化數據概念 (Structured Data Concepts)
Let’s use this image below as an example:
讓我們以下面的圖片為例:
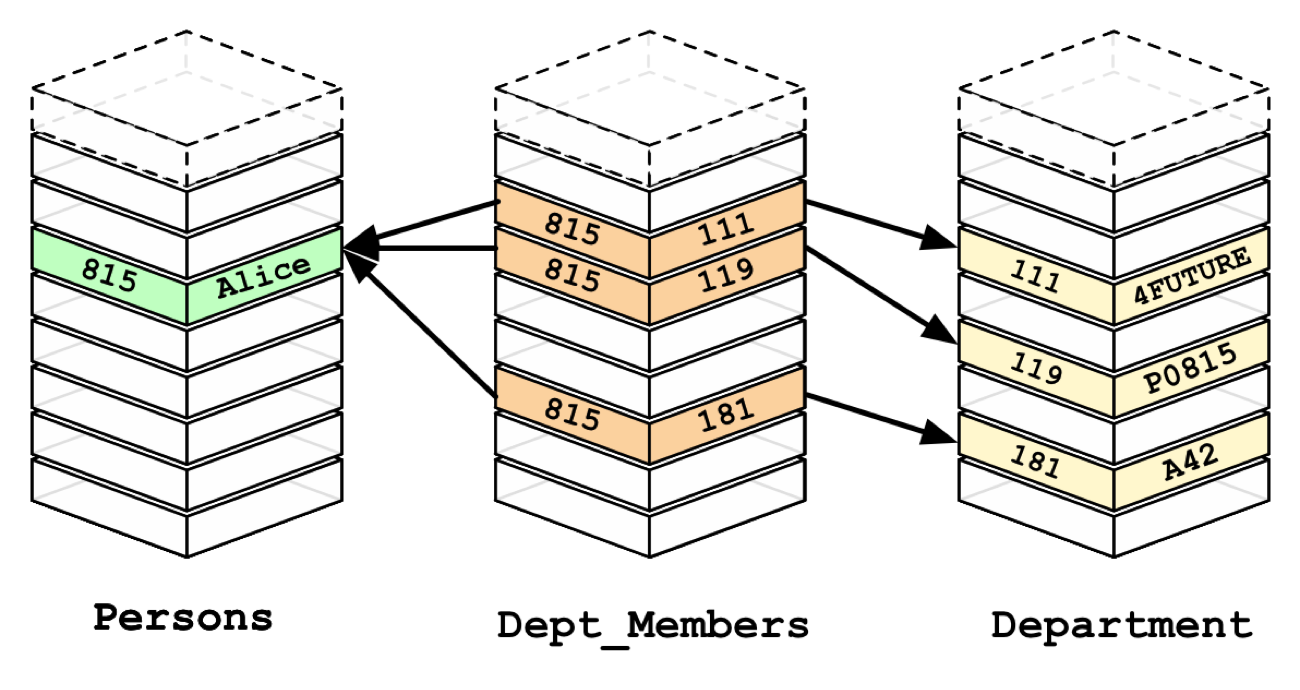
Structured data is organized in Tables, in this image, we have three and they are Persons, Dept_Members, and Department.
結構化數據按表格組織,在此圖像中,我們有三個,分別是Persons,Dept_Members和Department。
Each Table is organized in Columns and Rows.
每個表都按列和行組織。
Each column has a data type, depending on the database that you are using the name or the number of available data types can change, but basically we have in a macro vision Strings, Numbers, Dates, and Timestamps.
每列都有一種數據類型 ,具體取決于您使用的數據庫的名稱或可用數據類型的數量可以更改,但是從本質上講 ,我們在宏方面具有Strings , Numbers , Dates和Timestamps 。
- Strings: Everything that is a text. 字符串:一切都是文本。
- Numbers: Everything that is, obviously, a number. 數字:顯然所有的東西都是數字。
- Dates: Only dates are accepted, it doesn’t count with hours, minutes, and seconds. 日期:僅接受日期,不計小時,分鐘和秒。
- Timestamps: Dates with hours, minutes, and seconds. 時間戳記:帶有小時,分鐘和秒的日期。
As I said, some databases change some names or have some more specific uses, for example:
正如我所說,某些數據庫會更改某些名稱或具有某些更特定的用途,例如:
In Oracle when we want to declare a string column we can call it by VARCHAR2 or CHAR, the difference between them is the number of characters that they deal with (char stores only one character while varchar2 stores N) and if we look to Google Big Query we just have the String data type for all cases of text data.
在Oracle中,當我們想聲明一個字符串列時,可以通過VARCHAR2或CHAR來調用它,它們之間的區別是它們處理的字符數(char僅存儲一個字符,而varchar2存儲N),并且如果我們查看Google Big查詢我們僅具有用于文本數據所有情況的String數據類型。
Well, once we have spoken about the columns now what left is to talk about the rows. Basically, each row is a record of the Table and the one very important question is “How can we differentiate one record from another? What does separate them?”
好了,一旦我們談論了列,剩下的就是談論行。 基本上,每一行都是表的記錄,一個非常重要的問題是“如何區分一條記錄與另一條記錄? 它們之間有什么區別?”
The answer is the Primary Key.
答案是主鍵 。
The combination of columns of a record in a table that makes it unique is the primary key. Some tables have a specific column that works as an index, this works as a primary key too, but it does not show to you what makes it unique.
使記錄唯一的表中各列的組合是主鍵。 有些表有一個特定的列用作索引,該列也用作主鍵,但是并沒有向您顯示使其獨特的原因。
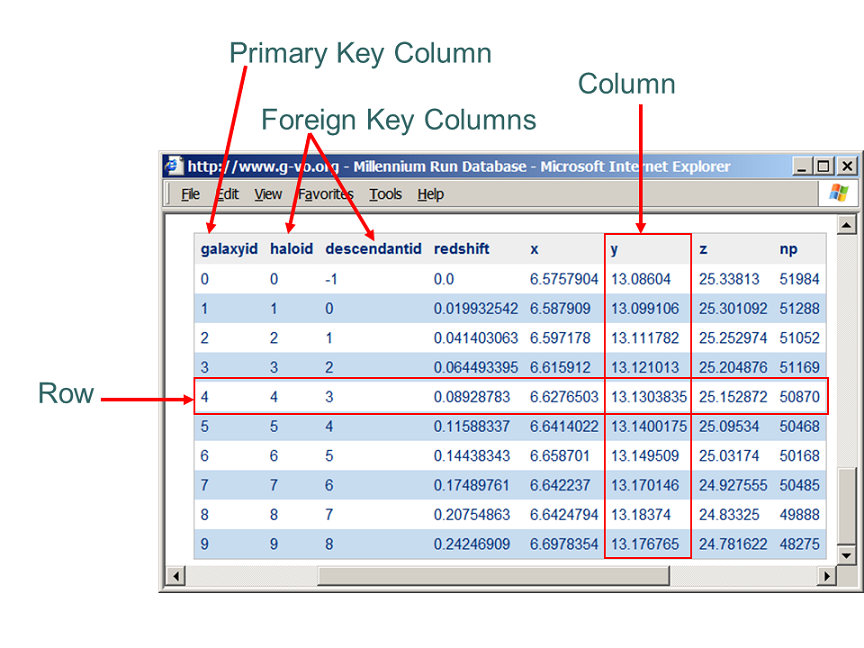

Some databases describe it in the table documentation, but if you don’t have this information don’t be afraid and explore your dataset!
一些數據庫在表文檔中對此進行了描述,但是,如果您沒有此信息,請不要害怕并探索您的數據集!
And here comes the main goal of the article: How do I explore it?
這是本文的主要目標: 如何探索它?
結構化查詢語言(SQL) (Structured Query Language (SQL))
Structured Query Language is the standard declarative search language for relational database
結構化查詢語言是關系數據庫的標準聲明式搜索語言
This text above it the dictionary explanation of what is SQL, but we can translate it by the code language that lets us get data from one table or a combination of them and how their data is related.
上面的文本對什么是SQL進行了字典解釋,但是我們可以通過使您可以從一個表或它們的組合中獲取數據以及它們的數據如何相關的代碼語言來翻譯它。
Resuming it at max we can say that the standard SQL query has “only”, with huge quotes here, 3 elements:
以最大的速度恢復它,我們可以說標準SQL查詢具有“ only”(在此處帶有引號)三個元素:
SELECT: where you define what you want to pick from your tables.
SELECT :您在其中定義要從表中選擇的內容。
FROM: where you define which tables you are going to use and their relationship.
FROM :您將在其中定義要使用的表及其關系。
WHERE: where you define what you want and do not want to see.
在哪里 :您可以在其中定義想要和不想看到的內容。
This is how a query looks like.
這就是查詢的樣子。

Now, what we can understand here:
現在,我們在這里可以理解的是:
We want to get data from columns A, B, C, and D from TABLE_1 that is in the SCHEMA_1 (that is like a folder of tables) and we desire just rows with code ‘0001’ in column A.
我們想從SCHEMA_1中的TABLE_1的A,B,C和D列獲取數據(就像表的文件夾),并且我們只希望A列中的代碼為“ 0001”的行。
It was easy, isn’t it? Let’s get a little bit more complex example.
很簡單,不是嗎? 讓我們來看一些更復雜的例子。
In column C we have a number (it could be sales quantity, stock projection, purchase order quantity, etc) and we want to sum the values by column A (again, it could be a store or product codes) and column B (maybe a date).
在C列中,我們有一個數字(可能是銷售數量,庫存預測,采購訂單數量等),我們想按A列(同樣可以是商店或產品代碼)和B列(可能是一個約會)。
We also want to order it first by column A and after column B.
我們還希望先按A列然后按B列對其進行排序。
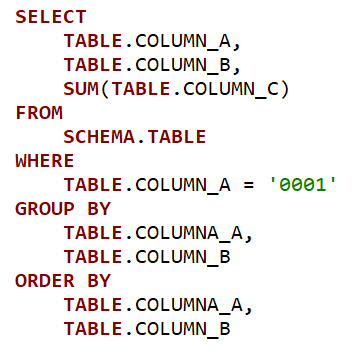
Now, when we want to aggregate some value based on another attribute we have to say “Look, I’m aggregating this guy here ( C ) this way (sum) and by these two dudes (group by A and B).”
現在,當我們要基于另一個屬性匯總一些值時,我們必須說“看,我正在以這種方式(和)并通過這兩個花花公子(按A和B分組)來匯總此人(C)。”
By the end, this isn’t too different from the last one, right?
最后,這與上一個沒有太大不同,對嗎?
表之間的關系 (Relationship Between Tables)
So, until now, all examples were for querying data of only one table at a time, but what we have to do if we want to merge data from two or more different tables?
因此,到目前為止,所有示例都僅一次查詢一個表的數據,但是如果要合并來自兩個或多個不同表的數據該怎么辦?
The answer is simples, we must say how they relate to each other by simply specifying which columns have equivalent data.
答案很簡單,我們必須通過簡單地指定哪些列具有等效數據來說明它們之間的關系。
Now our example is a sales table, and there I only have center and product codes, and product stock quantity, but I want to get product and center names too but both informations are from other tables.
現在我們的示例是一個銷售表,那里只有中心代碼和產品代碼以及產品庫存數量,但是我也想獲得產品和中心名稱,但這兩個信息都來自其他表。
I’ll say too that I just want to see the stock quantity that is higher than 100 units.
我也要說的是,我只想查看高于100個單位的庫存數量。

Let’s focus on the differences between the last example and this one. What is new here?
讓我們集中討論最后一個示例和這個示例之間的區別。 這里有什么新東西?
Tables can have nicknames, this is commonly used when the query has more than one table on it.
表格可以有昵稱 ,當查詢上有多個表格時,通常使用該昵稱 。
Using this you don’t have to write the whole table location which time you reference it.
使用此方法,您不必在引用該表時就編寫整個表的位置。
It’s also important because when we join tables we can have the same column names in both tables and we must pass in the query if we are using PLNT_CD from DIM_PLNT or from FT_SLS, otherwise, the query doesn’t know from which table it has to considerate.
這一點也很重要,因為當我們聯接表時,兩個表中的列名可以相同,并且如果我們使用的是DIM_PLNT或FT_SLS的PLNT_CD,則必須傳遞查詢,否則,查詢將不知道從哪個表周到。
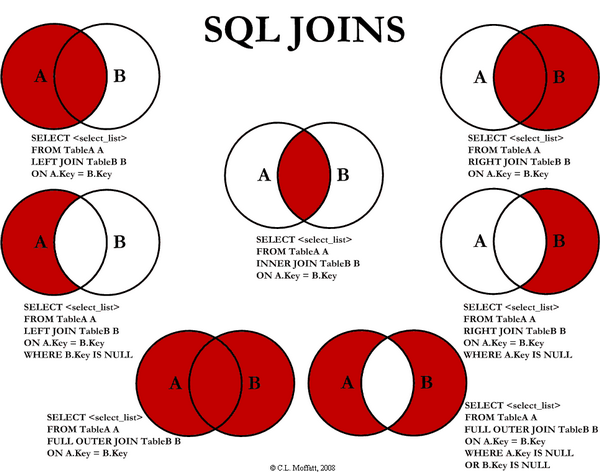
Join is the way you combine data from tables. Always think in two tables at a time, one is called Left and another is the Right.
連接是合并表中數據的方式。 總是一次在兩個表中思考,一個稱為左,另一個稱為右。
Left has a conjunct of records called L, Right has another conjunct called R and some records exist in both.
左有一個稱為L的記錄的連接,右有另一個稱為R的連接,并且兩者中都存在一些記錄。
Joins can be of several types, the one that is shown in the example is the Left Join, this means that we are going to use only the records of the left table and bring values of Right that has a corresponding value in Left.
聯接可以有幾種類型,示例中顯示的聯接是“左聯接”,這意味著我們將僅使用左表的記錄,并在“左”中帶入具有相應值的“右”值。
When we are comparing columns from tables to create the join between them we have to remember that is necessary for the relationship to be sealed they must be of the same data type.
當我們比較表中的列以創建它們之間的聯接時,我們必須記住,密封關系是必要的,它們必須具有相同的數據類型 。
In this example, we can see that in the join we had to convert the PLNT_CD field of SLS table to STRING, otherwise the join was not able to be consolidated.
在此示例中,我們可以看到在連接中我們必須將SLS表的PLNT_CD字段轉換為STRING,否則無法合并該連接。
Inside the Where clause, we have a new struct called Between, it is used to filter a range of data. By syntax, it has to be higher than the first parameter and lower than the second one.
在Where子句中,我們有一個稱為Between的新結構,用于過濾一系列數據。 通過語法,它必須高于第一個參數,并且小于第二個參數。
By last, when we have a SUM() or a MEAN() or any other math applied in the query we maybe desire to filter some more specific results and the Having helps us to achieve it by letting us filter the final result of the query before it is shown.
最后,當我們在查詢中應用了SUM()或MEAN()或任何其他數學運算時,我們可能希望過濾一些更具體的結果,而Haveing通過讓我們過濾查詢的最終結果來幫助我們實現此目標在顯示之前。
We are getting closer to the end of this article, but before we finish it…
我們接近本文的結尾,但是在完成本文之前……
提示 (Tips)
- In case you don’t know what you want to see in the table you can just use a * to return all columns of the table in the query. 如果您不知道要在表中看到什么,則可以使用*返回查詢中表的所有列。
SELECT
TABLE.*
FROM
SCHEMA.TABLE- Basically we have two types of tables, dimensional (DIM) and fact (FT). 基本上,我們有兩種類型的表,維度(DIM)和事實(FT)。
Dimensional tables store data that is attributed to a store or a product like its name, address, shape, size, etc, think about the data up to date or you maybe say it’s today’s value.
維度表存儲歸因于商店或產品的數據,例如其名稱,地址,形狀,大小等,考慮一下最新的數據,或者您可以說它是當今的價值。
Fact tables store data related to transactional information as purchase orders or sales tickets, so it brings the data of the moment of an event.
事實表將與交易信息相關的數據存儲為采購訂單或銷售單,因此它會帶來事件發生時的數據。
- Types of joins 聯接類型
There are several types of joins, I could basically write another article just with this theme, but I found this resume that explains a little bit of them.
聯接有幾種類型,我基本上可以只用該主題寫另一篇文章,但是我發現這份簡歷可以解釋其中的一些內容。
- In and not in 在而不在
Sometimes the need is to get data not of a single product or location, but of a list of them.
有時,需要獲取的數據不是單個產品或位置的數據,而是列表中的數據。
In these cases, you could use the operator IN or NOT IN in the WHERE to set as a parameter a list of desired variables instead of an infinity repetition of ANDs and ORs searching by one parameter at a time.
在這些情況下,可以在WHERE中使用運算符IN或NOT IN將所需變量列表設置為參數,而不是一次按一個參數搜索的AND和OR的無窮重復。
就是這樣! (And this is it!)
Well, with this I think you can now use SQL to access your data with a little more ease!
好吧,我想您現在可以使用SQL來更輕松地訪問數據!
I hope this article has helped you!
希望本文對您有所幫助!
翻譯自: https://medium.com/swlh/sql-use-guide-for-non-programmers-5997af000c5f
程序員 sql面試
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388469.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388469.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388469.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Apache+Tomcat集群負載均衡的兩種session處理方式

SmartSVN:File has inconsistent newlines

我要認真學Git了 - Config

計算機科學與技術科研論文,計算機科學與技術學院2007年度科研論文一覽表

r a/b 測試_R中的A / B測試

一臺機器同時運行兩個Tomcat

PHP獲取IP地址的方法,防止偽造IP地址注入攻擊

工作10年厭倦寫代碼_厭倦了數據質量討論?


oracle數據庫 日志滿了
.docx)
計算機應用基礎學生自查報告,計算機應用基礎(專科).docx


模擬一個簡單計算器_閱讀模擬器的簡單介紹

計算機部分應用顯示模糊,win10系統打開部分軟件字體總顯示模糊的解決方法-電腦自學網...


假如不工作了,你還有源源不斷的收入嗎?

turtle 20秒畫完小豬佩奇“社會人”

最佳子集aic選擇_AutoML的起源:最佳子集選擇

Java虛擬機內存溢出
