小程序 國際化
The hidden bugs waiting to be found by your international users
您的國際用戶正在等待發現的隱藏錯誤
While internationalizing our applications, we focus on the things we can see: text, tool-tips, error messages, and the like. But, hidden in our code there are places requiring internationalization that tend to be missed until found by our international users and reported as a bug.
在對我們的應用程序進行國際化的同時,我們專注于可以看到的內容:文本,工具提示,錯誤消息等。 但是,在我們的代碼中隱藏著一些需要國際化的地方,在我們的國際用戶發現并報告為錯誤之前,這些地方往往會被遺漏。
Here’s a big one: regular expressions. You likely use these handy, flexible, programming features to parse text entered by users. If your regular expressions are not internationalized, more specifically, if they are not written to handle Unicode characters, they will fail in subtle ways.
這是一個很大的:正則表達式。 您可能會使用這些方便,靈活的編程功能來解析用戶輸入的文本。 如果您的正則表達式沒有被國際化,更具體地說,如果它們不被編寫為處理Unicode字符,它們將以微妙的方式失敗。
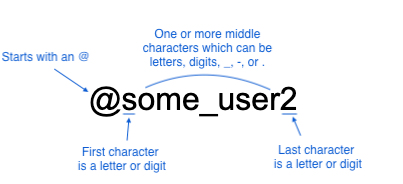
Here’s an example: imagine a commenting system in your application that allows users to type at-mentions of other users or user groups. People at-mentioned are notified that the comment needs their attention. Your system may have the requirement that the at-mention format is something like:
^ h ERE是一個例子:想象你的應用程序中的評論系統,允許用戶輸入其他用戶或用戶組的AT-提及。 通知所提及的人該評論需要引起他們的注意。 您的系統可能要求注意格式為:
Writing a regular expression to find and parse the usernames out of these strings is the most direct way for handling this. In Java, JavaScript, and other languages, the regular expression might look like this:
編寫正則表達式以從這些字符串中查找和解析用戶名是處理此問題的最直接方法。 在Java,JavaScript和其他語言中,正則表達式可能如下所示:
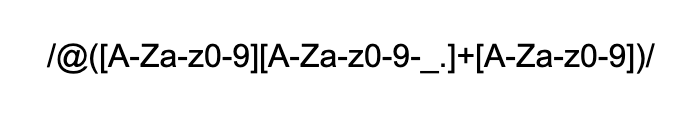
This expression specifies that we’re looking for an ‘@’ followed by a letter or number, followed by one or more letters, numbers, dashes, underscores, or dots, and ending with a letter or number. The parentheses tell the expression to capture this string and return it to us.
此表達式指定我們要查找的是“ @”,后跟一個字母或數字,然后是一個或多個字母,數字,破折號,下劃線或點,并以字母或數字結尾。 括號告訴表達式捕獲該字符串并將其返回給我們。
We can test it using the regex101 tester:
我們可以使用regex101測試儀進行測試:
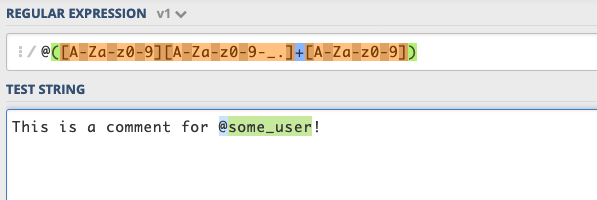
So that regex works great! But now let’s test it against some comment text containing Unicode characters:
因此,正則表達式效果很好! 但是,現在讓我們針對一些包含Unicode字符的注釋文本進行測試:
“This comment mentions @Adriàn, @Fran?ois, @No?l, @David, and @ひなた”
“此評論提到@Adriàn,@ Fran?ois,@No?l,@ David和@ひなた”
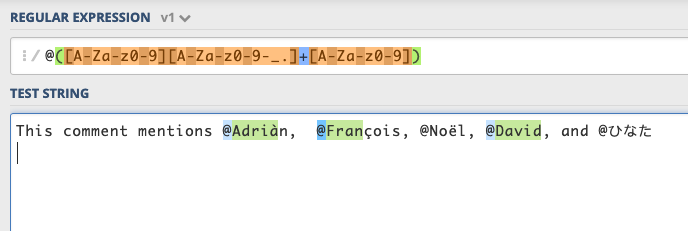
Unicode characters are not matched, so we either get incomplete usernames or no username at all.
Unicode字符不匹配,因此我們得到的用戶名不完整或根本沒有用戶名。
The solution:
噸他的解決方案:
Unicode is a character set that aims to define all characters and glyphs from all human languages, living and dead.”
Unicode是一種字符集,旨在定義所有人類語言(生與死)中的所有字符和字形。”
http://www.regular-expressions.info/unicode.html
http://www.regular-expressions.info/unicode.html
It would seem incredibly difficult to write a regular expression encompassing the Unicode mission statement quoted above, but it’s fairly straight forward. To match a single letter grapheme (a complete letter as rendered on screen), we use the \p{L} notation.
編寫包含上面引用的Unicode Mission語句的正則表達式似乎非常困難,但這很簡單。 為了匹配單個字母字素(屏幕上呈現的完整字母),我們使用\ p {L}表示法。
Updating our regex to use this Unicode friendly notation for letters, we get:
更新我們的正則表達式以對字母使用此Unicode友好符號,我們得到:
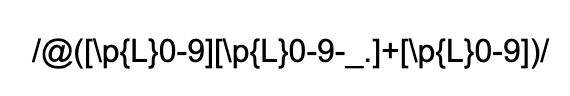
Let’s try it out in the regex101 tester:
讓我們在regex101測試儀中嘗試一下:
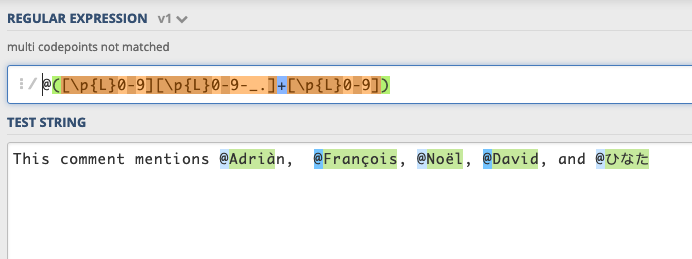
Close! But @Adriàn is not getting fully parsed. In fact, the string returned from the capture group is ‘Adria’, so we’ve got an incomplete username and lost the grave accent over the a. What’s going on?
關! 但是@Adriàn尚未完全解析。 實際上,從捕獲組返回的字符串是“ Adria”,因此我們的用戶名不完整,并且丟失了a字母的重音。 這是怎么回事?
To understand this, let’s take a look at how single characters rendered on a screen or page are represented in Unicode. The à is actually two Unicode characters, U+0061 representing the a and U+0300 representing the grave accent above the a. The grave accent is a combining mark. A character can be followed by any number of combining marks which will be assembled together when rendered.
為了理解這一點,讓我們看一下屏幕或頁面上呈現的單個字符如何以Unicode表示。 à實際上是兩個 Unicode字符,U + 0061代表a ,U + 0300代表a上方的重音。 重音是一個結合的標志 。 字符后可以跟任意數量的組合標記,這些標記在渲染時將組裝在一起。
Fortunately, our regex can look for combining marks as well with the \p{M} specifier. This matches on a Unicode character that is a combining mark. Our usernames as defined will never start with a combining mark, but we do need to check for them in the middle and at the end of the strings. The new regex looks like this:
幸運的是,我們的正則表達式也可以使用\ p {M}說明符來查找標記組合。 這與作為組合標記的Unicode字符匹配。 我們定義的用戶名永遠不會以組合標記開頭,但是我們確實需要在字符串的中間和結尾檢查它們。 新的正則表達式如下所示:
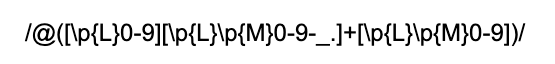
Testing it:
測試它:
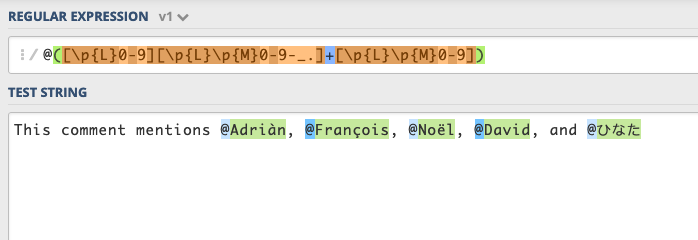
Success!
成功!
One detail worth knowing is that some combined characters like the à can also be specified in Unicode with a single character (U+00E0 in this case). But with our regex, it doesn’t matter. We’ll match the character if it has a single representation, with the /p{L} specifier, or if it is a combination of two characters, with the /p{M} specifier.
值得一提的一個細節是,也可以使用單個字符(在本例中為U + 00E0)在Unicode中指定諸如à之類的一些組合字符。 但是使用我們的正則表達式,沒關系。 如果字符具有單個表示,則將其與/ p {L}說明符相匹配,或者,如果它是兩個字符的組合,則將與/ p {M}說明符相匹配。
As long as we’re internationalizing, let’s deal with the digits as well. Unicode regex handling gives us a safe way to match any representation of the digits 0 through 9 using the \p{Nd} specifier. Using it, we get our final internationalized regular expression for matching and returning usernames in the body of a comment’s text:
只要我們正在國際化,我們也要處理數字。 Unicode正則表達式處理為我們提供了一種安全的方式,可以使用\ p {Nd}說明符來匹配數字0到9的任何表示形式。 使用它,我們得到了最終的國際化正則表達式,用于匹配和返回注釋文本正文中的用戶名:
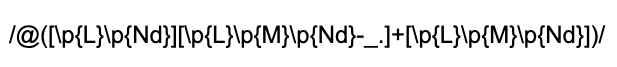
The exact details for handling Unicode in regular expressions can vary from language to language, so be sure to check out the differences for your code. The site regular-expressions.info is an excellent source for regular expression information in all programming languages and is what lead me to the solution I described in this article.
在不同的語言中,使用正則表達式處理Unicode的確切細節可能有所不同,因此請務必檢查出代碼的差異。 該網站regular-expressions.info是所有編程語言中正則表達式信息的絕佳來源,也是使我引向本文所述解決方案的原因。
翻譯自: https://medium.com/@kennyflutes/the-one-thing-you-forgot-while-internationalizing-your-application-72c3323b253c
小程序 國際化
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/387841.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/387841.shtml 英文地址,請注明出處:http://en.pswp.cn/news/387841.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


PCA主成分分析Python實現


robo 3t連接_使用robo 3t studio 3t連接到地圖集

JavaWeb--JavaEE

軟件需求規格說明書通用模版_通用需求挑戰和機遇
)
python版PCA(主成分分析)

干貨|Spring Cloud Bus 消息總線介紹

一類動詞二類動詞三類動詞_基于http動詞的完全無效授權技術
詳解)
主成份分析(PCA)詳解

thinkphp5記錄

portainer容器可視化管理部署簡要筆記

證明您履歷表經驗的防彈五步法

2018-2019-1 20165231 實驗四 外設驅動程序設計

如何安裝pylab:python如何導入matplotlib模塊

微信掃描二維碼和瀏覽器掃描二維碼 ios和Android 分別進入不用的提示頁面
函數與緩沖區)
詳解getchar()函數與緩沖區

windows下python安裝Numpy、Scipy、matplotlib模塊

