python全棧開發筆記第二模塊
?
第四章 :常用模塊(第二部分)
? ? 一、os 模塊的 詳解
1、os.getcwd()? ? :得到當前工作目錄,即當前python解釋器所在目錄路徑
import os j = os.getcwd() # 返回當前python所在路徑,在哪里執行python,返回哪里目錄 print(j)
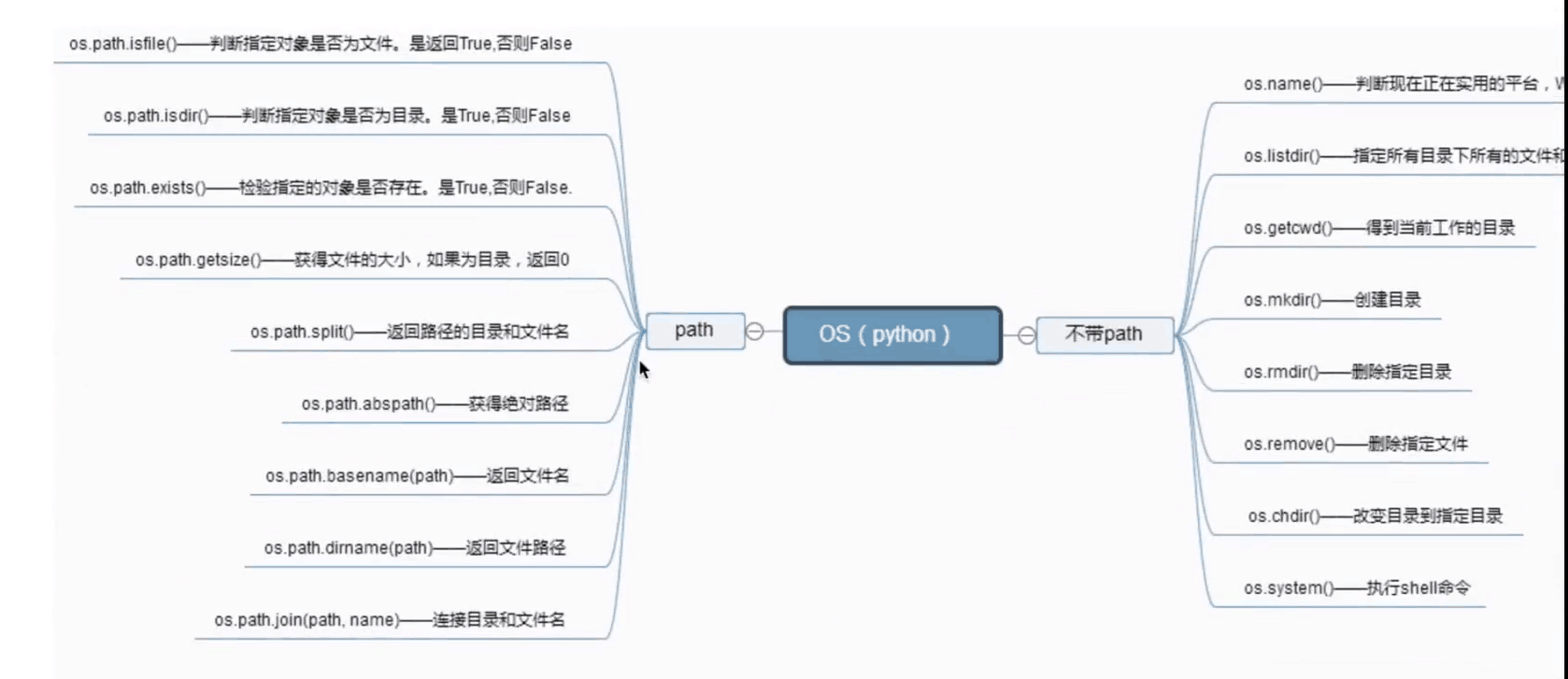
C:\Users\57098\PycharmProjects\untitled\python學習第二模塊\第四章\常用模塊import os # 導入os 模塊 os.getcwd() # 返回當前 python 所在文件路徑(在哪里執行python,返回哪里) os.listdir(".") # 返回指定目錄下的所有文件和目錄名("."代表當前目錄) os.remove() # 刪除指定文件(括號內填寫文件地址) os.removedirs(r"%s"%**) # 刪除多個文件,需要讀取文件的路徑 os.path.isfile("文件") # 判斷是否為一個文件,返回(True/False) os.path.isdir("目錄") # 判斷是否為一個目錄,返回(True/False) os.path.isabs("絕對路徑") # 判斷是否為絕對路徑,返回(True/False)
os.path.exists("檢驗內存") # 檢驗路徑是否為真,返回(True/False) os.path.split("文件名和目錄名") # 返回路徑的文件名和目錄名并分開 os.path.splitext("分離擴展") # 返回路徑的文件名和文件,并分離后綴 os.path.dirname("路徑名") # 獲取路徑名 os.path.abspath("絕對路徑") # 獲取絕對路徑 os.path.basename("文件名") # 獲取文件名 os.system("模擬電腦系統") # 運行電腦自帶系統命令(模擬電腦系統,執行正確返回 0 執行錯誤返回其他) os.getenv("HOME") # 讀取操作系統環境變量 HOME 的值 os.environ # 打印當前系統的所有變量(不加括號) os.environ.setdefault("hello", "/home/guoyilong") # 設置臨時系統變量,僅程序運行時有效(交互器退出,自動刪除)
os.linesep # 返回當前平臺使用的換行符( windows 返回 "\n""\r" , Linux 和 Mac 返回 "\n")
os.name # 返回當前系統操作平臺(返回通用接口協議代號 windows 為 "nt"而 linux 和 unix 則返回"posix")
os.rename("舊文件名", "新文件名") # 文件重命名(如果新文件名已存在,或許會報錯)
os.makedirs(r"c:\d\c\b\a") # 創建多級文件(遞歸式的創建文件)如果一級目錄不存在,會挨個創建到所有路徑實現
os.mkdir("創建單個目錄") # 創建單個目錄
os.stat("python3.txt") # 執行一個文件(需輸入目錄下的文件全稱(包括后綴))
os.stat_result st_mode=33206, # 文件權限 st_ino=9851624184895828, # 節點號 st_dev=2557137489, # 接口(存到硬盤上的地址類)(駐留的設備) st_nlink=1, # 連接數 st_uid=0,# 用戶 ID st_gid=0, # 群組ID st_size=1425,# 文件大小 (常用的就是能拿到文件大小) st_atime=1547046564, # 最后訪問時間戳 st_mtime=1547046564,# 最后修改時間戳 st_ctime=1543572800,# 最后修改權限時間戳
os.chmod("文件") # 修改文件權限與時間戳 os._exit("文件") # 終止參數內文件的進程 os.path.getsize("文件名") # 獲取文件大小 os.path.join("目錄名", "文件名") # 結合目錄名和文件名(只要是真實的文件名和目錄名就會返回) os.fchdir("要改變的目錄地址") # 改變文件目錄到指定路徑
jk = os.get_terminal_size() # 獲取當前終端大小(在python解釋器執行)
os.terminal_size(columns=133,lines=44)
# columns=133 每行能寫133個字符 lines=44 可寫44行(視解釋器窗口而定,可自己決定窗口的大小)
os.kill("進程號", "需導入 signal 模塊", "執行命令") # 殺死或終止當前進程,需要和 signal (信號處理模塊)配合使用
總結:有點多,不好記。需要分類,python 的 os 模塊主要分為 2 大類,
一個是帶 .path ,一個是不帶
二、sys 模塊的詳解
import sys # 導入模塊 sys.argv # 打印程序的當前路徑 sys.exit("bye-bye") # 退出程序并打印參數,不再執行其他 sys.version # 打印當前解釋器版本 sys.maxsize # 打印 int 最大數值 sys.path # 打印解釋器的環境變量(模塊的初始路徑) sys.platform # 打印操作系統平臺版本
k6 = sys.stdout # 標準輸出
<_io.TextIOWrapper name='<stdout>' mode='w' encoding='UTF-8'>?
# io 代表文件讀寫操作, 后面的代表操作輸入文件格式
k = sys.getrecursionlimit() # 獲取最大遞歸層數 sys.getrecursionlimit(1200) # 設置最大遞歸層數 sys.getdefaultencoding() # 獲取解釋器默認編碼 sys.getfilesystemencoding() # 獲取內存數據存到文件里
?三、shutil 模塊詳解(做文件處理,壓縮解壓常用到的模塊)
注意:
-
-
- ?以下幾個模塊注意編碼的轉換,
-
?pycharm 所用的編碼默認 utf-8 ,
-
?windows 系統默認編碼為 unicode 或者 GBK,
-
在文件處理方面要提前轉好統一代碼才能實現互通無阻
-
? ? ? ? 1、shutil 模塊詳解
* shutil.copyfileobj拷貝文件(通過文件讀寫)
import shutil # 創建模塊的文件名不能和導入的標準庫的模塊同名,否則會報錯 f1 = open("模塊語法.py", "r", encoding="utf-8") f2 = open("module__copy.py", "w", encoding="utf-8") shutil.copyfileobj(f1, f2) # 讀寫方式創建新文件
*?shutil.copyfile拷貝文件(通過文件名稱)?
f3 = "模塊語法.py" f4 = "語法復制.py" shutil.copyfile(f3, f4) # 直接拷貝文件不用讀寫
? * 其他 shutil 的應用
shutil.copymode() # 僅拷貝權限(內容、組和用名都不變) shutil.copystat() # 拷貝狀態信息包括(mode(權限), bits, atime, fiage) shutil.copy() # 拷貝文件和權限 shutil.copy2() # 拷貝文件和狀態信息
? * shutil 模塊的組合使用
? 遞歸拷貝文件(在同目錄下,拷貝多級目錄的大文件)(拷貝目錄用得到)
f5 = shutil.ignore_patterns("__init__.py", "kk") # 忽略拷貝目錄內的文件名需在參數內填寫 shutil.copytree("包的解析與應用", "常用模塊副本", symlinks=False, ignore=f5)
# 以上兩個組合使用(注意括號內參數軟鏈接、和忽略拷貝的對象)
? * shutil.rmtree? 遞歸刪除文件或路徑內文件
shutil.rmtree(path="%s"%"常用模塊副本",) # 遞歸刪除文件路徑內全部文件并忽略報錯信息
?* shutil.move 移動或創建
shutil.move("常用模塊副本", "astr") # 需同級目錄下進行,如果移動到的文件名不存在,會重新創建(就像剪切一樣)
****重點**** 壓縮包的創建
#重點** 創建壓縮包并返回文件路徑
shutil.make_archive(base_name,format,.....) # base_name : 壓縮包的文件名,也可以是文件路徑。只是文件時,則保存至當前目錄,否則保存指定路徑 # 如: staff:保存當前路徑, /User/57098/Dskfmmn/ ; 則保存至此路徑下 # format :壓縮包類型,("zip", "tar", "bztar", "gztar") # root_dir : 要壓縮的文件路徑(默認當前目錄) # owner :用戶(默認當前用戶) # group :組(默認當前組) # logger : 用于記錄日志,通常是logging.Logger對象
shutil.make_archive("fffff", "zip", root_dir="包的解析與應用") # 壓縮包只能壓縮普通文件,不支持多級目錄的文件夾壓縮 #("fffff" 和 root_dir="包的解析與應用",可更換不的同路徑地址)#沒有路徑格式默認打包當前目錄下的文件存到當前目錄下,如果不把壓縮包放在同一目錄,需指定目錄#shutil 對壓縮包的處理是調用 ZipFile 和 TarFile 兩個模塊來進行處理的
?2、zipfile (壓縮打包)模塊詳解
# # 壓縮文件
import zipfile
f6 = zipfile.ZipFile("f1f2.zip", "w", ) # 先創建壓縮包的名稱和讀寫方式 f6.write("語法復制.py") # 寫入的文件 f6.write("astr") # 寫入的文件夾 f6.write("包的解析與應用") f6.close() # 關閉文件
# # 解壓文件 f7 = zipfile.ZipFile("f1f2.zip", "r") # 解壓壓縮包 f7.extractall() # 內置解壓包語法 f7.close()
? 3、tarfile (只打包)模塊解析
f8 = tarfile.open("f3f4.zip", "w") # 創建打包名稱和讀寫方式 f8.add("包的解析與應用", arcname="包") # 要打包的路徑或同目錄下的文件名(Windows系統,注意編碼的轉換),arcname=為打包后為包重新命名 f8.add("壓縮解壓專用") f8.close() # 此方法會打包文件夾下所有內容
?注意:
-
-
- tayfile和 zipfile 模塊的區別;
- zipfile 打包多級文件夾時,只能打包目錄下的空文件夾,?
- 而 tarfile 則是打包文件夾內的所有目錄及內容
-
?四、序列化模塊(json、pickle 和 shelve)
1、json 模塊詳解
(1)、只在內存執行
import json date = {"狀態": {"英雄": ["德瑪", "亞索", "蔚"],"怪": ["大龍", "小龍", "藍Buf", "紅Buf"]}} # 轉換成系統識別的字符 g = json.dumps(date) # 把內容轉成字符串(電腦識別的格式)unicode或者其他格式 print(g, type(date)) # 已轉成字符 # 系統識別字符轉換成正常格式 g2 = json.loads(g) # 轉成相應的數據類型,和上一個語法是相應的 print(g2)
?(2)轉換字符串并存進文件?
fd = open("date.json", "w", encoding="utf-8") # 注意命名規范(json 序列化化轉變文件一般都會有 .json 的后綴)便于識別文件 g5 = json.dump(date, fd) # 轉換成 unicode 編碼格式(或者其他編碼格式)并存進指定文件 # 自動識別把文件內容轉換相應格式 fs = open("date.json", "r", encoding="utf-8") # 注意讀寫模式 g6 = json.load(fs) # 轉換成相應格式
(3) 把數據類型轉成字符串存在內存的意義( json.dumps json.loads )
(1、把內存的數據,通過網絡,共享給其他人
(2、跨平臺,跨語言,定義了不同語言溝通之前的交互規則和方法
*純文本文件,缺點是:不能共享復雜的數據類型
**xml 文件, 缺點; 占用空間大
*** json 處理 , 簡單,可讀性好,是所有語言共同的交互平臺,也是最常用方法、
注意:dump 和 load 不支持同一文件夾多次執行,都屬于一次性的,執行多次會帶來很多麻煩?
???2、pickle 模塊詳解
pickle 和 json 的方法基本相同
import pickle h = {"alex": "will", "will": 1233}# 在內存執行 h3 = pickle.dumps(h) # 會轉成存進硬盤的bytes類型(二進制格式)# 存文件執行 ph = open("will", "wb") # 注意讀寫類型,由于存的是二進制編碼,必須是 wb 或者 rb 模式 pickle.dump(h, ph) # 存進自己能識別的數據(可能看的時候是亂碼), 自己能識別并能轉回 ph2 = open("will", "rb") # 打開文件(rb格式) ph3 = pickle.load(ph2, encoding="utf-8") # 可定義轉成為什么格式的字
3、shelve 模塊的詳解
* shelve 操作轉換類型,通常以字典形式存儲和讀取,還可寫多行轉換(就像json 內的 dump 可執行多行)
import shelve f = shelve.open("shelve_file") # shelve模式打開文件 s = {"hello": "will", "alex": 25} # 創建2個類型 sa = ["hello my name is will", "i'm is age 27", 13555555555] f["info"] = s f["info_age"] = sa # 直接調用f,并以字典形式創建 value 并對應賦值 f.close() # 關閉文件
f = shelve.open("shelve_file") sc = list(f.keys()) # 字典形式讀取文件內的數據(不抓換字典嗎,打印的是一個內存地址) sd = list(f.values()) # 返回字典內的 value 值 se = f.get("info_age") # 查看字典內 info 對應值
** 不但可以獲取還可以刪除、創建 和修改文件內容 f = shelve.open("shelve_file") # 打開文件 del f["info"] # 刪除文件 f["info"] = [1, 4, 5, 2, "asdd", 5, 8, 55] # 重新創建(也可視為重新修改,但是不能修改局部,只能修改整體) f.close() f = shelve.open("shelve_file") se = f.get("info")
***總結:json 和 pickle 的區別
1、json優點:可以跨平臺、跨語言實現互通
缺點:轉換類型是有限的 (只支持 字符串str、數字int、列表list、字典dict、元祖tuple)
不能支持太復雜的數據結構
2、pickle 優點: 支持 python 內所有數據類型(轉成二進制格式,再按照所需轉成指定編碼)
缺點:只局限于 python ,不可跨平臺、夸語言
五、xml 模塊詳解
-
- xml 模塊為不同語言或程序之間進行數據交互的協議,
- ? json 出來之前的老模塊,適用于老互聯網模式比如金融行業
- ? ? ? ? 現已很少用,( 大部分都在用 json 類的標準化模塊 )金融累還有部分在應用
- ? ? ? ?下面以操作 xml 文件為例學習
- ? ? ? ? xml 是類似于網絡前段的形式存儲文件的,在很多語言都有支持
<data><country name="Liechtenstein"><rank updated="yes">2</rank><year attr_test="yes" update="yes">2039</year><gdppc>141100</gdppc><neighbor direction="E" name="Austria" /><neighbor direction="W" name="Switzerland" /></country><country name="Singapore"><rank updated="yes">5</rank><year attr_test="yes" update="yes">2042</year><gdppc>59900</gdppc><neighbor direction="N" name="Malaysia" /></country><country name="Panama"><rank updated="yes">69</rank><year attr_test="yes" update="yes">2042</year><gdppc>13600</gdppc><neighbor direction="W" name="Costa Rica" /><neighbor direction="E" name="Colombia" /></country><state><name>德國</name><population>首爾</population></state>
</data> * xml是通過 <>來標記區別數據結構的,xml 模塊在各種語言里都是支持的,在python中可以導入以下模塊來進行操作
import xml.etree.ElementTree as ET (一)1、先查看下它的對應功能
char = ET.parse("xml test") # 和 open()打開文件一個道理 pych = char.getroot() # 找到根目錄地址相當于用處理文件內的f.seek(0) print(dir(pych )) # 查看對應功能 print(pych.tag) # 返回 xml 入口標簽
?2、遍歷文件
# 遍歷循環 xml 文檔 for srr in pych:print("------")print(srr.tag, srr.attrib) # 依次取標簽內節點的值(srr = county 的標簽值)for y in srr:print(y.tag, y.text) # 取出每一個 county 內的子標簽的值# 也可只遍歷子節點中的某一個節點 for f in pych.iter("gdppc"): # 你要找什么,就把對應的名字填上print(f.tag, f.text) # 打印對應名字和對應值
3、xml 文件的修改
# xml 文件的修改 char = ET.parse("xml test") pych = char.getroot() # 拿到節點起始的數據(seek(0))# 把每個年份都加10 for v in pych.iter("year"):new = int(v.text) + 10 # 把屬性內的值轉回數字并相加v.text = str(new) # 所有的文件都是字符串,所以還要再轉回字符串v.set("update", "yes") # 可自行添加一些特殊標注(字符串形式) char.write("xml test") # 寫進原文件(修改成功)
4、xml 部分刪除
# 刪除部分信息 for country in pych.findall("country"): # 用到 findallrank = int(country.find("rank").text) # 拿到值 轉回數字if rank > 50:pych.remove(country) # 刪除對應值 char.write("xml del test") # 寫進新文件(刪除成功)
(二) 創建 xml 文件
xml_info = ET.Element("name_dict") # 創建根目錄節點
?1、創建第一個節點
name = ET.SubElement(xml_info, "name", attrib={"enrolled": "yes"}) # 創建第一個節點 age = ET.SubElement(name, "age", attrib={"chord": "no"}) # 創建節點屬性 sex = ET.SubElement(age, "sex") # 在目錄下創建屬性 name_ = ET.SubElement(name, "name") name_.text = "will Guo" sex.text = "male" # 賦值操作
? 2、創建第二個節點
name_two = ET.SubElement(xml_info, "name_two", attrib={"enrolled": "not"}) # 創建第二個節點 age = ET.SubElement(name_two, "age") age.text = "19"
3、生成文件對象 et = ET.ElementTree(xml_info) # 生成文件對象 et.write("text.xml", encoding="utf-8", xml_declaration=True)
# 寫進文件命名為“text.xml”, 編碼格式為 utf-8 , 版本號為默認True
總結:
xml 文件操作,相對其他操作方法,會麻煩很多,不建議用,但是老程序的文件也要會操作
六、configParser 模塊( 主要應用于配置文檔的操作 ) -
- 在 pycharm 內,到相應目錄下創建一個普通文件, 以 .ini 結尾都會自動識別為配置文件
- 配置文件內,一般分為三部分,可以根據配置軟件的不同,設置相應配置?
import configparserconf = configparser.ConfigParser() # 定義打開格式并賦值 t = conf.read("appr.ini") # 得到執行方法(執行文件) ta = conf.sections() # 執行得到配置文件內的后兩段配置編碼名, 配置文件第一段為默認配置(不寫也會有) tb = conf.default_section # 拿到默認配置碼的名(第一段)
1、拿到配置文件內的對應值(操作方法與字典內取值相似) tc = dir(conf["bitbucket.org"]) # 查看有多少可執行的方法(和字典的參數和操作有點相同) td = list(conf["bitbucket.org"].keys()) # 執行取出所有 keys (和字典相同)拿到的是一個內存地址,需轉成列表方可看 te = conf["bitbucket.org"]["user"] # 得到參數內的 key ,和字典一樣找出對應對的值
? ?2、循環節點下所有的值并作出判斷
for tf, tv in conf["bitbucket.org"].items(): # 填寫的 第二段編碼的值卻取出目錄節點下所有值 # 在原文件內修改第二段編碼,發現也會 一起打印所有值, # 是因為不管操作哪個群文件[DEFAULT] 是一個默認值,即便不調用,也會出現在操作的文件中 # 同樣如果在每一個節點段落內,都要有相同的參數在內,可以把他寫進第一個節點段落內,這樣每次執行 都會出現
? ?3、判斷條件在不在文件內
# 判斷條件在不在文件內 if "sdf" in conf["bitbucket.org"]:print("info") else:print("def")
? 4、配置文件的增刪改查 # 配置文件的增刪改查 conf = configparser.ConfigParser() conf.read("add.ini")print(dir(conf)) # 查看語法 fk = conf.options("date1") # 會拿到對應節點下的所有 key fm = conf["date1"]["key2"] # 拿到對應 key 的值(和字典操作相同)
??5、增加文件配置
# 增加一個配置 conf.add_section("date3") # 創建新的節點 conf["date3"]["name"] = "will" # 創建節點內容 conf["date3"]["age"] = "26" conf.write(open("add.ini", "r+")) # 寫入創建的節點 conf.set("date2", "name", "will") # 也可在節點內新增內容 conf.write(open("add.ini", "w")) # 寫入新增值
? 6、刪除文件內的節點或節點內容?
# 刪除節點或內容 conf.remove_section("date3") # 刪除節點和節點內全部內容 conf.write(open("add.ini", "w"))conf.remove_option("date3", "") # 可以選擇刪除節點內的某一項和對應值 conf.write(open("add.ini", "w"))
? 七、 hashlib(加密處理)模塊詳解
? ?hashlib 加密模塊和之前學的 hash 函數有一些關系,還包括 MD5 的算法結合
(一)、hash 的函數,就是把普通的字符串、數字、列表 等一系列正常字符通過內部轉換,
生成一串不可反解(也稱不可逆)的數字進行 基礎加密,也就是找到一種數據類型和內存地址有關的映射關系
(二)、MD5 加密算法,是一種被廣泛應用的密碼雜湊函數, 可以生成一個 128 位的散列值,用于確保信息傳輸的完整一致,
MD5 的前身:MD2、MD3、MD4。
1、MD5 的功能:
輸入任意長度信息都會返回128位的信息(數字指紋 ),每一次 輸入都不會有相同的返回值。
2、MD5 算法的特點:
①壓縮性(輸入的任意長度,輸出的 MD5 值都是固定的長度)
②容易計算(從原數據計算出 MD5 很容易)
③抗修改性(對原數據進行任何改動,ND5 的值都不會一致,哪怕只是一個字符)
④強抗碰撞(即使得知原數據和 MD5 的值,也不會再次生成相同的值(即偽造數據)
3、MD5 算法 是否可逆(反解):MD5 算法不可逆,即唯一值,因為是其中一種散列函數,
使用了 hash 算法,計算中只抽取部分數據
網絡上的破解算法是通過撞庫來查找數據庫得出相應的值
(提前把簡單的數值對應加密算法得出的結果存進數據庫以供查詢)
4、MD5 用途:
① 防止被篡改(發送郵件前后對照 MD5 生成值,下載文件前公布 MD5 供下載后對照是否相同)
SVN 在檢測文件是否在 CheckOut 被篡改過,也會用到MD5
② 防止直接看到明文(很多登錄系統,都是通過 MD5 加密存儲的用戶數據,就算得到用戶數據,也不能使用)
只有用戶自己登陸,將字符轉換后與數據庫對比正確了,才能登錄。這樣就保證了用戶數據的安全性)
③ 防止抵賴(就像數字簽名:經過第三方認證之后,就會防止抵賴不承認)
(三)MD5 算法的生成(語法必須在python交互器執行)
# MD5 算法的生成 # 必須在 python 交互器進行 >>> import hashlib # 導入 hashlib 模塊 >>> m = hashlib.md5() # 調用 MD5 并賦值 >>> m.update(b"will") # 以二進制格式輸入要加密的字符串(b"****") >>> m.hexdigest() # 調用生成算法 '18218139eec55d83cf82679934e5cd75' # 加密生成
八、subprocess模塊(此模塊需注意:Windows、Unix 和 Mac 不一樣的系統執行命令) 官方推出subprocess模塊是為了提供統一的模塊來實現對系統命令或腳本的調用。
三種執行命令的方法
-
-
- subprocess.run()
- subprocess.call()
- subprocess.Popen()
-
? ?1、run()方法
subprocess.run(['df', '-h'], stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True)
stdout標準輸出,stdin標準輸入,stderr標準錯誤
subprocess.PIPE是把結果存到管道里進行緩存
涉及管道符的命令需寫 subprocess.run("df -h|grep disk1",shell=True) shell 意思是交給系統執行命令
此處需要用到windows? 的 cmd 系統命令
有關某個命令的詳細信息,請鍵入 HELP 命令名 ASSOC 顯示或修改文件擴展名關聯。 ATTRIB 顯示或更改文件屬性。 BREAK 設置或清除擴展式 CTRL+C 檢查。 BCDEDIT 設置啟動數據庫中的屬性以控制啟動加載。 CACLS 顯示或修改文件的訪問控制列表(ACL)。 CALL 從另一個批處理程序調用這一個。 CD 顯示當前目錄的名稱或將其更改。 CHCP 顯示或設置活動代碼頁數。 CHDIR 顯示當前目錄的名稱或將其更改。 CHKDSK 檢查磁盤并顯示狀態報告。 CHKNTFS 顯示或修改啟動時間磁盤檢查。 CLS 清除屏幕。 CMD 打開另一個 Windows 命令解釋程序窗口。 COLOR 設置默認控制臺前景和背景顏色。 COMP 比較兩個或兩套文件的內容。 COMPACT 顯示或更改 NTFS 分區上文件的壓縮。 CONVERT 將 FAT 卷轉換成 NTFS。你不能轉換當前驅動器。 COPY 將至少一個文件復制到另一個位置。 DATE 顯示或設置日期。 DEL 刪除至少一個文件。 DIR 顯示一個目錄中的文件和子目錄。 DISKPART 顯示或配置磁盤分區屬性。 DOSKEY 編輯命令行、撤回 Windows 命令并創建宏。 DRIVERQUERY 顯示當前設備驅動程序狀態和屬性。 ECHO 顯示消息,或將命令回顯打開或關閉。 ENDLOCAL 結束批文件中環境更改的本地化。 ERASE 刪除一個或多個文件。 EXIT 退出 CMD.EXE 程序(命令解釋程序)。 FC 比較兩個文件或兩個文件集并顯示它們之間的不同。 FIND 在一個或多個文件中搜索一個文本字符串。 FINDSTR 在多個文件中搜索字符串。 FOR 為一組文件中的每個文件運行一個指定的命令。 FORMAT 格式化磁盤,以便用于 Windows。 FSUTIL 顯示或配置文件系統屬性。 FTYPE 顯示或修改在文件擴展名關聯中使用的文件類型。 GOTO 將 Windows 命令解釋程序定向到批處理程序中某個帶標簽的行。 GPRESULT 顯示計算機或用戶的組策略信息。 GRAFTABL 使 Windows 在圖形模式下顯示擴展字符集。 HELP 提供 Windows 命令的幫助信息。 ICACLS 顯示、修改、備份或還原文件和目錄的 ACL。 IF 在批處理程序中執行有條件的處理操作。 LABEL 創建、更改或刪除磁盤的卷標。 MD 創建一個目錄。 MKDIR 創建一個目錄。 MKLINK 創建符號鏈接和硬鏈接 MODE 配置系統設備。 MORE 逐屏顯示輸出。 MOVE 將一個或多個文件從一個目錄移動到另一個目錄。 OPENFILES 顯示遠程用戶為了文件共享而打開的文件。 PATH 為可執行文件顯示或設置搜索路徑。 PAUSE 暫停批處理文件的處理并顯示消息。 POPD 還原通過 PUSHD 保存的當前目錄的上一個值。 PRINT 打印一個文本文件。 PROMPT 更改 Windows 命令提示。 PUSHD 保存當前目錄,然后對其進行更改。 RD 刪除目錄。 RECOVER 從損壞的或有缺陷的磁盤中恢復可讀信息。 REM 記錄批處理文件或 CONFIG.SYS 中的注釋(批注)。 REN 重命名文件。 RENAME 重命名文件。 REPLACE 替換文件。 RMDIR 刪除目錄。 ROBOCOPY 復制文件和目錄樹的高級實用工具 SET 顯示、設置或刪除 Windows 環境變量。 SETLOCAL 開始本地化批處理文件中的環境更改。 SC 顯示或配置服務(后臺進程)。 SCHTASKS 安排在一臺計算機上運行命令和程序。 SHIFT 調整批處理文件中可替換參數的位置。 SHUTDOWN 允許通過本地或遠程方式正確關閉計算機。 SORT 對輸入排序。 START 啟動單獨的窗口以運行指定的程序或命令。 SUBST 將路徑與驅動器號關聯。 SYSTEMINFO 顯示計算機的特定屬性和配置。 TASKLIST 顯示包括服務在內的所有當前運行的任務。 TASKKILL 中止或停止正在運行的進程或應用程序。 TIME 顯示或設置系統時間。 TITLE 設置 CMD.EXE 會話的窗口標題。 TREE 以圖形方式顯示驅動程序或路徑的目錄結構。 TYPE 顯示文本文件的內容。 VER 顯示 Windows 的版本。 VERIFY 告訴 Windows 是否進行驗證,以確保文件正確寫入磁盤。 VOL 顯示磁盤卷標和序列號。 XCOPY 復制文件和目錄樹。 WMIC 在交互式命令 shell 中顯示 WMI 信息。有關工具的詳細信息,請參閱聯機幫助中的命令行參考。
2、call()方法
a = subprocess.call(['df', '-h'])
執行命令,返回命令執行狀態,(0 或 非0)
subprocess.check_call(['ls', '-l'])
如果命令結果為0,就返回,否則拋出異常
subprocess.getstatusoutput('ls /bin/ls')
接收字符串格式命令,返回元組形式,第一個元素為執行狀態,第二個元素為命令結果(0,'/bin/ls')
subprocess.getoutput('ls /bin/ls')
接收字符串格式命令,返回結果
a = subprocess.check_output(['ls', '-l'])
執行命令并返回結果,需要有接收返回值的變量
3、Popen()方法
(以上2個方法都是通過本方法封裝而成,也就是說上面2個方法的底層代碼都是通過本方法實現的)
常用參數:
args: shell命令,可以是字符串或者序列類型(如:list,元組)
stdin, stdout, stderr:分別表示程序的標準輸入、輸出、錯誤句柄
preexec_fn: 只在 Unix平臺下有效,用于指定一個可執行對象(callable object),
它將在子進程運行之前被調用
shell:同上
cwd:用于設置子進程的當前目錄
env:用于指定子進程的環境變量。如果env = None,子進程的環境變量將從父進程中繼承。
a = subprocess.run('sleep 10', shell=True, stdout=subprocess.PIPE)
a = subprocess.Popen('sleep 10', shell=True, stdout=subprocess.PIPE)
注意:windows? ?encoding='gbk'? ? linux/mac 默認uft-8
print(a.stdout.read())輸出結果
run方法 ? 在主程序執行
Popen方法 發起一個新的子進程,不影響主程序
pid ? ? 獲取所啟動的進程的進程號
poll() ?檢測子進程是否終止,返回代碼
wait() ?等待發起的進程結束
terminate() ? 終止所啟動的進程 ?
kill() ? ? ? ?殺死所啟動的進程
communicate() ? ? ? 和啟動的進程交互,通過stdin發送數據,通過stdout接收輸出數據 ? ?只能交互一次
f = subprocess.Popen("dir", shell=True,stdout=subprocess.PIPE) # 執行 cmd 命令 print(f.pid) # 拿到執行進程的編號 f = f.stdout.read() # 得到執行結果 # (由于用 windows 系統默認編碼為 GBK 所以需要把當前執行所用的 utf-8 轉為 GBK) f = f.decode(encoding="GBK") # 轉換成 windows 系統的默認編碼 print(f) # 正常顯示 f.terminate(8896) # 殺掉執行的進程
?九、logging日志模塊(編寫日志)
在開發中,記錄日志,是一個必不可少的過程,包含內容廣泛,有正常訪問程序的日志,還有錯誤、警告等信息輸出,
提供了標準的日志接口,可以儲各種格式日志,其中包括:
日志由上到下,級別由低到高,(debug級別最低,critical級別最高)
- debug() # 調試模式(開發時調試需用)
- info() # 普通的記錄(錯誤除外)
- warning() # 即將發生的錯誤或者潛在的問題
- error() # 出問題,報錯,錯誤
- critical() # 嚴重問題,影響正常運行或即將癱瘓
(一)logging 基礎語語法和應用 logging.warning("user Will attrs wrong module python3 is not yes") # 基礎語法 logging.critical("hello bye_bye") # 更高等級
?
1、寫入日志的語法
創建日志文件時,level=日志級別過濾條件(如果是 DEBUG 則所有的都會寫進去,如果更高級別,則低級別的會被忽略寫入) logging.basicConfig(filename="logging.log", # 創建日志文件level=logging.DEBUG, # 指定寫入級別format='%(asctime)s:' # 指定寫入時間(固定格式)'%(levelname)s:' # 輸出日記級別'%(filename)s:' # 輸出輸出模塊的文件名'%(funcName)s:' # 輸出其在的函數名'%(lineno)d:' # 輸出其所在文件的行列'%(relativeCreated)d:' # 輸出創建以來的毫秒'%(process)d:' # 輸出進程編號'%(message)s', # 用戶輸出的消息datefmt="%Y-%m-%d %I:%M:%S %p") # 指定寫入時間格式(注意大小寫) def haha(): # 寫入一個函數logging.error("hello my name's will")haha()logging.debug("hello my name is will , i'm age 22") logging.info("is ides not logging for file") logging.warning("error is windows10 not python3") # 寫入日志文件
**可以寫入時間格式,還可以增加很多方法格式
%(name)s # logger的名字 %(levelno)s # 數字形式的日志級別,會根據輸入的語法級別用(10--60)表示最低和最高級別的日志 %(levelname)s # 文本形式的日志級別,會把寫入的日志級別的名字,同步寫進日志 %(pathname)s # 調用日志輸出函數的模塊和完整路徑名(把執行時所在目錄和生成的日志全部寫入**不常用) %(filename)s # 調用日志輸出函數模塊的文件名 %(module)s # 調用日志輸出函數的模塊名 %(funcName)s # 調用日志輸出函數的函數名(日志中表明其所在的函數名) %(lineno)d # 調用日志輸出函數語句所在的代碼行列(注意后綴字符)(輸出其所在文件內的多少行) %(created)f # 當前時間(用 Unix 標準的表示時間的浮點數表示)(注意后綴字符) %(relativeCreated)d # 輸出日志信息時,自logger 創建以來的毫秒數 (調試時會有用) %(asctime)s # 字符串形式的當前時間,默認格式“年-月-日 時:分:秒(精確到微秒) %(thread)d # 線程 ID (可能沒有) %(threadName)s # 線程名稱(可能沒有) %(process)d # 進程 ID (執行程序的進程號)(可能沒有)(調試會用到) %(message)s # 用戶輸出的消息
?
(二)logging 模塊進階(同時輸出到屏幕和文件)
python使用的 logging 模塊日志涉及 4 個主要類:
- logger 提供了應用程序可直接使用的接口
- handler將(logger創建的)日志發送到合適的位置輸出
- filter提供了輸出日志記錄的過濾,細化設置決定輸出哪條日志記錄
- formatter 決定了日志記錄的最終輸出格式
1、logger 的的使用:每個程序在輸出信息之前都要獲得一個 logger。logger通常對應程序的模塊名
(如:聊天工具的圖形界面)模塊可以以此獲得他的logger
log = logging.getLogger("chat.gui")
而核心模塊可以這樣 LOG = logging.getLogger("chat.kernel")
?
還可以綁定 handler 和 filters logging.Logger.setLevel(lel) # 指定最低的日志級別,低于lel級別的將被忽略 debug 為最低級別,critical為最高級別 logging.Logger.addFilter(filter=) # 添加指定的 filter logging.Logger.removeFilter(filter=) # 刪除指定的 filter logging.Logger.addHandler(hdlr=) # 添加指定的 handler logging.Logger.removeHandler(hdlr=) # 刪除指定的 handler 可以指定的日志級別 logging.Logger.debug() # 最低級 logging.Logger.info() logging.Logger.warning() logging.Logger.error() logging.Logger.critical() # 最高級
?
? 2、handler 的使用:handler對象負責發送信至指定位置,python 的日志系統有多個 handler 函數可用,
可以輸送到控制臺,也可輸出信息至文件內,還可以把信息發送網絡上,如果有其他要求,更可以自己編寫 handler
還可通過 addHandler()方法添加多個 handler 進行操作
也可設置級別
logging.Handler.setLevel(lel) # 指定被處理信息級別,低于指定級別的將被忽略 logging.Handler.setFormatter() # 指定 handler 的輸出對象和輸出格式 logging.Handler.addFilter(filter()) # 新增 filter 對象 logging.Handler.removeFilter(filter=) # 刪除 filter 對象 # 每一個 logger 都可以附加多個 Handler
?
3、常用 handler 的方法需導入模塊(logging.handlers)
3.1、logging.StreamHandler :
使用這個 handler 可向類似于 sys.stdouut 、sys.stderr 的任何文件對象( fileobject )輸出信息
3.2、logging.FileHandler :
和上一個(logging.StreamHandlerS)類似,用于向一個文件輸出日志信息。不過本語法會自動打開文件
3.3、logging.handlers.RotatingFileHandler :
這個語法類似(logging.FileHandler)的作用,區別在于本方法可以管理文件大小,當文件達到一定容量,
將當前文件改名,自動創建新的同名文件繼續輸出,(比如當前文件為:handler.log , 如果此文件容量不足,
本方法會將裝滿內容的文件命名為 handler.log.1 或 繼續增加,然后重新再創建一個 handler.log 的文件寫入)(末尾數字越大代表文件越早)
它的函數是: logging.handlers.RotatingFileHandler(filename=[, mode[, maxBytes[, backupCount]]])
其中 filename 和 mode 兩個參數和 FileHandler 一樣,
import logging from logging import handlers # 日志文件自動截取(注意需要導入logging的子模塊 handlers) logger = logging.getLogger("web") # 生成 logger 對象,設置并創建日志文件# 2、生成 handler 對象,按大小自動截取文件 fh = logging.handlers.RotatingFileHandler(filename="web.log", mode="S", maxBytes=50, backupCount=3) # ① maxBytes :用于指定文件的容量,如果此參數為 0 ,則表示文件可以無限大,也不會創建新文件 # ② backupCount :用于指定保留備份文件的數量,如:指定文件為 2 則表示重命名創建文件過程中, # 只能存在 2 個文件(handler.log.1 和 handler.log)其余文件會被清理刪除 logger.addHandler(fh) fc = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') fh.setFormatter(fc) logger.debug("最低級別") logger.info("中低級別") logger.error("中級") logger.warning("中高級") logger.critical("最高級別") # 寫入日志內容,不設置日志級別,默認級別為 warning
?
?3.4、logging.handlers.TimedRotatingFileHandler :
import logging from logging import handlers # 日志文件自動截取(注意需要導入logging的子模塊 handlers) logger = logging.getLogger("web") # 生成 logger 對象,設置并創建日志文件 # 2、生成 handler 對象,按時間自動截取文件 # 這個和上一個類似,不同之處是:它不是通過文件大小判斷是否創建新文件,而是間隔一定時間,自動創建新的文件 # 它的函數是:logging.handlers.TimedRotatingFileHandler(filename=[, when[, interval[, backupCount]]]) # 其中,filename 參數和 backupCount 和 RotatingFileHandler 具有相同的意義 ch = logging.handlers.TimedRotatingFileHandler("web.log", when="s", interval=4, backupCount=3) # ① interval :是設定間隔時間(大部分都只是個數值) # ② when= :是一個字符串,表示時間的間隔單位,不區分大小寫。 # 取值范圍 【S:秒 M:分 H:時 D:天 W:周( interval==0 時,代表周一 ),midnight為每天凌晨】 logger.addHandler(ch) fd = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s') ch.setFormatter(fd logger.debug("最低級別") logger.info("中低級別") logger.error("中級") logger.warning("中高級") logger.critical("最高級別") # 寫入日志內容,不設置日志級別,則默認級別為 warning
?
4、formatter 組件:日志的 formatter 是一個獨立的組件,可以配合 handler 使用
# -*- coding:utf-8 -*- import logging
# 1、生成 logger 對象 logger = logging.getLogger("web") # 設置并創建日志文件 logger.setLevel(logging.INFO) # 設置全局最高權限日志級別(不設置默認級別為 warning ) logger.setLevel(logging.DEBUG) # 如果把全局的等級設置最低,則相當于下放權限給子級別權限設置# 2、生成 handler 對象 ch = logging.StreamHandler() # 生成屏幕輸出 ch.setLevel(logging.DEBUG) # 為屏幕輸出時,設置局部級別(子級別權限,會受到最高權限的影響)
fh = logging.FileHandler("web.log") # 生成文件輸出 fh.setLevel(logging.WARNING) # 為生成文件輸出時,設置輸出局部級別(子級別權限,會受到最高權限的影響)# 2.1、把 handler 對象綁定到 logger logger.addHandler(ch) logger.addHandler(fh)# 3.生成 formatter 對象 fc = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') fd = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s')# 3.1、把 formatter 對象綁定到 handler 對象 ch.setFormatter(fd) fh.setFormatter(fc)logger.debug("最低級別") # 寫入日志內容 logger.info("中低級別") logger.error("中級") logger.warning("中高級") logger.critical("最高級別") # 不設置日志級別,默認級別為 warning
?
? 5、filter組件:如果要過濾日志內容,可以自定義一個 filter
# -*- coding:utf-8 -*- import loggingclass IgnoreBackupLogFilter(logging.Filter): # 創建類"""忽略帶db backup的日志"""def filter(self, record): # 固定寫法( filter 過濾語法用的少 )return "db backup" not in record.getMessage() # 如果"db backup"不在獲取的日志行列,# 注意:filter 會執行后返回 True 或 False ,logger 會根據此值決定是否輸出日志# 1、生成 logger 對象 logger = logging.getLogger("web") # 設置并創建日志文件 logger.setLevel(logging.INFO) # 設置全局最高權限日志級別(不設置默認級別為 warning ) logger.setLevel(logging.DEBUG) # 如果把全局的等級設置最低,則相當于下放權限給子級別權限設置# 1.1、把 filter 添加到 logger 中 logger.addFilter(IgnoreBackupLogFilter()) # 就會把符合條件的過濾掉# 2、生成 handler 對象 ch = logging.StreamHandler() # 生成屏幕輸出 # ch.setLevel(logging.DEBUG) # 為屏幕輸出時,設置局部級別(子級別權限,會受到最高權限的影響) fh = logging.FileHandler("web.log") # 生成文件輸出 # fh.setLevel(logging.WARNING) # 為生成文件輸出時,設置輸出局部級別(子級別權限,會受到最高權限的影響)# 2.1、把 handler 對象綁定到 logger logger.addHandler(ch) logger.addHandler(fh)# 3.生成 formatter 對象 fc = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') fd = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s')# 3.1、把 formatter 對象綁定到 handler 對象 ch.setFormatter(fd) fh.setFormatter(fc)logger.debug("最低級別") # 寫入日志內容 logger.info("中低級別") logger.error("中級,db backup") logger.warning("中高級") logger.critical("最高級別") # 不設置日志級別,默認級別為 warning





筆記 : 1.使用launch file在gazebo中生成urdf機器人)
![[asp.net] 利用WebClient上傳圖片到遠程服務](http://pic.xiahunao.cn/[asp.net] 利用WebClient上傳圖片到遠程服務)







筆記 : 2.創建并配置package)




