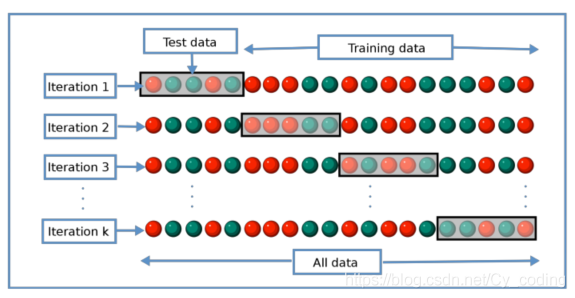
交叉驗證,cross validation是機器學習中非常常見的驗證模型魯棒性的方法。其最主要原理是將數據集的一部分分離出來作為驗證集,剩余的用于模型的訓練,稱為訓練集。模型通過訓練集來最優化其內部參數權重,再在驗證集上檢驗其表現。
比較常見的交叉驗證方法K折疊交叉驗證,(K-fold Cross Validation)如下圖所示,我們將數據分為K個部分,其中K-1個部分作為訓練集,剩余的作為驗證集。每個epoch循環,都選取不一樣的一個部分作為驗證集。
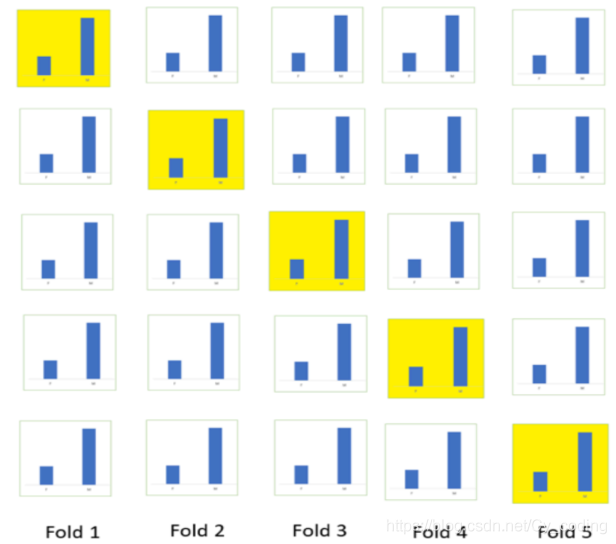
在使用K折疊或者別的交叉驗證的方法時,我們需要注意的是,在很多問題中,類與類在數據集中的分布不一定是均勻的。因此,我們往往需要在折疊的過程中使得每個fold都有著相同或至少近似的類的分布。
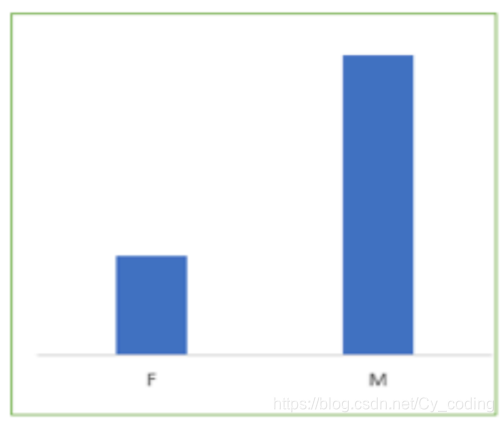
例如在下列性別二分類問題中,原始數據中女性與男性的樣本數量如下。那么我們在劃分K折疊的時候,也要將這個分布情況在每個折疊上還原,即保證在每個折疊上女性與男性的樣本數量的比例與整體數據的比例是一致的。如果沒有滿足這個條件,在上述例子中,很可能出現訓練時模型過多得受到了了男性樣本得影響,而導致其在女性樣本為主的驗證集上表現很差。因此,保證K折疊每一個部分的類分布是均勻的,也能在一定程度上提升訓練后模型的魯棒性。