本文主要總結了GAN(Generative Adversarial Networks) 生成對抗網絡的基本原理并通過mnist數據集展示GAN網絡的應用。
GAN網絡是由兩個目標相對立的網絡構成的,在所有GAN框架中都至少包含了兩個部分,生成模型部分和判別模型部分。生成模型的目標是制造出一些與真實數據十分相似的偽造數據而判別模型的目標則恰恰相反,是找到如何分辨這些真實的數據以及偽造數據。
下圖可以用來比較簡明地理解GAN的工作原理 :
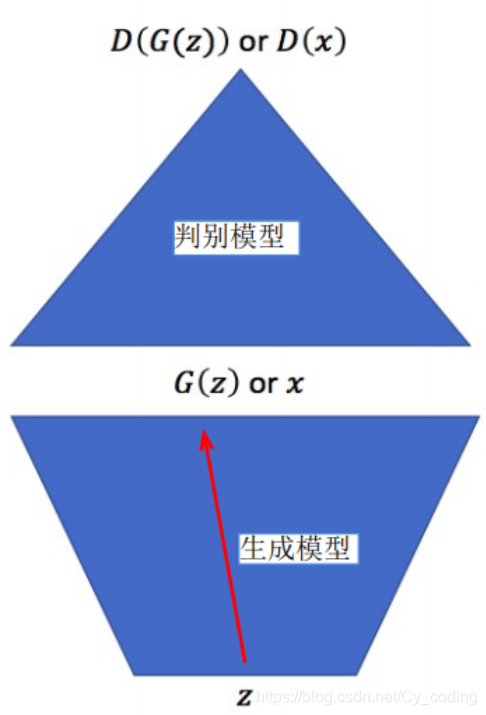
生成模型的輸入是隨機的噪聲編碼zzz,通過這個噪聲生成的數據 G(z)G(z)G(z) 就是我們偽造出的數據了。判別模型的輸入是一組混合了真實數據xxx以及偽造的數據G(z)G(z)G(z)的混合數據并輸出D(G(z))D(G(z))D(G(z)) 以及D(x)D(x)D(x),代表了對真實數據和偽造數據的判定。如果我們把偽造數據的標簽定為0,真實數據的標簽定為1,那么判別模型的訓練目標就是使D(G(z))D(G(z))D(G(z))無限接近0,使D(x)D(x)D(x)無限接近1,以此來達到分辨真實數據和偽造數據的目的。相反的,生成模型的訓練目標則是要使得D(G(z))D(G(z))D(G(z))接近1,即達到欺騙判別模型,以假亂真的目的。我們不難發現,實際生成模型的訓練離不開判別模型的判定,而判別模型的訓練也需要生成模型生成的偽造數據,二者相輔相成。這一點在下面基于mnist數據集的訓練代碼中也會有所體現。
首先是import所需庫并導入mnist數據,我們通過全部除以255的方法正則化用于訓練和測試的圖像。
import tensorflow as tf
from tensorflow import keras
from matplotlib import pyplot as plt
from keras.layers import Dense, Conv2DTranspose, BatchNormalization, Reshape, LeakyReLU, Conv2D
import numpy as np# load data from database mnist
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(path="mnist.npz")# normaliser à [0,1]
x_train = x_train/255.0
x_test = x_test/255.0
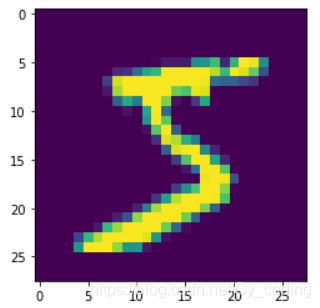
訓練集x_train中包含了60000張 28*28的單通道灰度圖片,每張圖片對應標簽為0-9的十個數字,下面展示其中一張代表了數字5的圖片。
1. 生成模型部分
首先是我們的生成模型,如上所說,生成模型的輸入為隨機噪聲,輸出為偽造的數據。在這個例子中,我們最終要輸出一張與真實圖片大小一致的灰度圖。生成模型由兩類主要的層構成,其中之一就是全連接層dense,這個層實際上類似于CNN卷積神經網絡中代表特征 feature 的一層,我們可以理解為它由數個低解析度的圖像組成。之后需要的就是將解析度提升至的操作,這里用了Conv2DTranspose層,可以理解為是一個反向的pooling池化層(用于還原參數和數據)和一個2D卷積層的結合。Conv2DTranspose層中的參數stride設置為(2, 2) 即保證了每經過一次該層,輸出的寬度和高度都擴大一倍。如下例所示,由7 * 7 經過兩次Conv2DTranspose層使得最終輸出的灰度圖寬度和高度為 28 * 28 。生成模型的輸出層是一個簡單的2D卷積層,使用activation激勵函數為sigmoid,這是由于sigmoid函數可以使得輸出值屬于[0, 1]的區間,也對應了我們在一開始在數據預處理的時候,將數據正則化至[0, 1]的操作。
# creation of a generator
def creation_generateur(dim_latent=10):generator = keras.models.Sequential()generator.add(Dense(128*7*7, input_dim=dim_latent))generator.add(Reshape((7,7,128)))# upsampling generator.add(Conv2DTranspose(filters=128,kernel_size=(5,5),strides=(2,2),padding="same"))generator.add(LeakyReLU(alpha=0.2))# upsampling generator.add(Conv2DTranspose(filters=128,kernel_size=(5,5),strides=(2,2),padding="same"))generator.add(LeakyReLU(alpha=0.2))generator.add(Conv2D(1, kernel_size=(7, 7), activation='sigmoid', padding="same"))return generator
2. 判別模型部分
接著我們創建GAN中的判別模型,相比生成模型而言,判別模型就更加簡明,其實質就是一個classifier二元分類器。他由多個卷積層構成,其中添加了drop out用于防止過擬合。輸出層是一個僅有一個神經元的全連接層,使用sigmoid作為激勵函數。正如我們前文所提到的,判別模型會對輸入進行分類,判別輸入究竟是真實圖像還是由生成模型偽造的圖像。
# creation of a discriminator
def creation_discriminateur():discriminator = keras.models.Sequential()discriminator.add(Conv2D(filters=64, kernel_size=(5,5),strides=(2,2), input_shape=(28,28,1), padding="same")) discriminator.add(LeakyReLU(alpha=0.2))discriminator.add(keras.layers.Dropout(0.4))discriminator.add(Conv2D(filters=64, kernel_size=(3,3),strides=(2,2), padding="same"))discriminator.add(LeakyReLU(alpha=0.2))discriminator.add(keras.layers.Dropout(0.4))discriminator.add(keras.layers.Flatten())discriminator.add(keras.layers.Dense(1,activation='sigmoid'))return discriminator
3. 疊加模型(用于訓練生成模型)
有了上述兩部分代碼,接下來我們可以構建基于生成模型部分以及判別模型部分的GAN神經網絡。這里我們只是將兩部分疊加起來,而并非構建第三個神經網絡。這里構建GAN的方式與之后訓練GAN是有關系的。如下代碼所示,我們將生成模型與判別模型疊加起來,并讓判別模型中的參數在該模型中不可訓練。其實質是因為這個疊加模型GAN是用于訓練生成模型的。整體的過程如下 : 輸入是一組隨機噪聲,經過生成模型后變成了一組偽造的數字灰度圖,再經過判別模型,輸出一個0-1之間的值。這是梯度的正向傳播過程。接著我們利用反向梯度傳播來更新我們生成模型的各個權重,以此來達到使該疊加模型輸出趨向于1。 這里其實就是GAN模型訓練的重中之重,即生成模型的目標與判別模型相反,其目標為生成的偽造數據能更大概率被識別為是真實數據,即標簽1。這一點在下一個部分GAN模型的訓練中會更詳細解釋。
def creation_reseau_GAN(model_generateur, model_discriminateur):GAN = keras.models.Sequential()GAN.add(model_generateur)# 判別模型中的參數設置為不可訓練discriminateur.trainable = FalseGAN.add(model_discriminateur)optimizer_GAN = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)GAN.compile(loss='binary_crossentropy', optimizer=optimizer_GAN)return GAN
4. GAN模型的訓練過程
根據上述三個部分,我們創建完畢了所要用到的神經網絡。在這個部分中我們就進入GAN模型的訓練過程。
首先我們要給予生成模型一組隨機噪聲,以便其根據這個噪聲創造不同的偽造數據,該噪聲的意義在于避免所有的生成數據都是一樣的。可以用高斯噪聲或正態分布生成噪聲,不同的噪聲類型選取對模型訓練的影響不大。
# 隨機選取潛在編碼(噪聲)
def code_latent_aleatoire(dim_latent, nb_exemples):# distribution normal standard normal distribution# code_latent = np.random.normal(loc=0, scale=1, size=(nb_exemples, dim_latent))# code_latent = code_latent.reshape(nb_exemples, dim_latent)code_latent = np.random.randn(nb_exemples, dim_latent)return code_latent
為了判別模型的訓練,我們同時需要真實的數據和偽造的數據,因此我們定義函數用于根據現有的生成模型和隨機噪聲來生成偽造圖片,偽造圖片的標簽為0。同樣的,定義另一個函數,用于在mnist數據中隨機選取真實圖片,真實圖片的標簽為1。
def construction_image_generateur(generateur_model, dim_latent, nb_exemples):# 生成隨機噪聲X = code_latent_aleatoire(dim_latent,nb_exemples)image_fraud = generateur_model.predict(X)# 生成的圖片的真實標簽為0Label_genere = np.zeros((nb_exemples,1))return image_fraud, Label_generedef tirage_reelle_aleatoire(base_de_donnees, nb_exemples):mat_images_reel = np.zeros((nb_exemples, 28, 28))for i in range(nb_exemples):index = np.random.randint(0, base_de_donnees.shape[0])mat_images_reel[i,:,:] = base_de_donnees[index,:,:]mat_images_reel = mat_images_reel.reshape(nb_exemples, 28, 28, 1)# 從mnist數據集選取的圖片的標簽均為1labels_reel = np.ones((nb_exemples, 1))return mat_images_reel, labels_reel
接下來就是重頭戲,GAN網絡的訓練過程了。要訓練一個gan模型,我們常用的方法是利用train_on_batch函數來訓練。在每個batch中,首先訓練判別模型,我們先構建一組由真實數據和偽造數據組成的數據集,訓練判別模型使其能更準確分辨哪些數據是真實的而哪些數據是偽造的。緊接著在同一個batch中,訓練疊加模型,通過隨機噪聲進入生成模型去生成偽造的圖片,并給予他們一個假的標簽,即所有的偽造圖片我們都標為1,以此來使得生成模型向著使判別模型判定偽造圖片為真的方向進行。
# GAN 模型的訓練
def entrainement_GAN_model(model_generateur, model_discriminateur, base_de_donnees, dim_latent, GAN_model, epochs=20, batch_size=128):vector_loss_discriminateur = []vector_loss_gan = []# 通過數據集的大小以及batchsize計算每個epoch對應的batch數量total_batch = np.floor(base_de_donnees.shape[0]/batch_size).astype(np.int)# 對于每個epochfor nb_epoch in range(epochs):# 對于每個batchfor index_batch in range(total_batch):# 每個batch中有一半的圖像為偽造圖片x_fraud, y_fraud = construction_image_generateur(model_generateur, dim_latent=dim_latent, nb_exemples=int(batch_size/2))# 剩下的圖像為真實的從mnist數據集中隨機提取的圖片x_reel, y_reel = tirage_reelle_aleatoire(base_de_donnees=base_de_donnees, nb_exemples=int(batch_size/2))# 疊加所有的數據 id_exemple, 28, 28x_chaque_batch = np.vstack((x_reel, x_fraud))# 疊加所有的標簽 : id_exemple, labely_chaque_batch = np.vstack((y_reel, y_fraud))# 使用構建的一半真實一半偽造的數據訓練判別模型,更新權重。loss_discriminateur = model_discriminateur.train_on_batch(x_chaque_batch, y_chaque_batch)# 接下來是每個Batch訓練疊加模型的部分,其實質是用于訓練生成模型。x_generateur = code_latent_aleatoire(dim_latent=dim_latent, nb_exemples=batch_size)# 這里我們要使得疊加模型的輸出趨向于1,即使判別模型認為生成的圖像也是真實的。y_gan = np.ones((batch_size,1))# 使用判別模型(疊加模型)的輸出來訓練生成模型gan_loss = GAN_model.train_on_batch(x_generateur, y_gan)# 顯示每個batch對應的兩個部分的lossprint("%d epochs,%d batches, loss_discriminateur : %f, loss_gan : %f"%(nb_epoch+1, index_batch+1, loss_discriminateur, gan_loss))# 保存模型以及圖片部分if (nb_epoch + 1)%3 == 0:model_generateur.save("generateur_models/generateur_after_" + str(nb_epoch+1) + "_epoch_" + "loss_%3f"%(gan_loss) + ".h5")model_discriminateur.save("discriminateur_models/discriminateur_after_" + str(nb_epoch+1) + "_epoch_" + "loss_%3f"%(loss_discriminateur) + ".h5") GAN_model.save("gan_models/gan_after_" + str(nb_epoch+1) + "_epoch_" + "loss_%3f"%(gan_loss) + ".h5")generer_sauvegarde_images(model_generateur=model_generateur, after_epoch=nb_epoch)vector_loss_discriminateur.append(loss_discriminateur)vector_loss_gan.append(gan_loss)return vector_loss_discriminateur, vector_loss_gan
5. 附錄(完整代碼)及相關討論
該部分中我將放出完整的代碼以及結果。
import tensorflow as tf
from tensorflow import keras
from matplotlib import pyplot as plt
from keras.layers import Dense, Conv2DTranspose, BatchNormalization, Reshape, LeakyReLU, Conv2D
import numpy as np# creation of a generator
def creation_generateur(dim_latent=10):generator = keras.models.Sequential()generator.add(Dense(128*7*7, input_dim=dim_latent))generator.add(Reshape((7,7,128)))# upsampling generator.add(Conv2DTranspose(filters=128,kernel_size=(5,5),strides=(2,2),padding="same"))generator.add(LeakyReLU(alpha=0.2))# upsampling generator.add(Conv2DTranspose(filters=128,kernel_size=(5,5),strides=(2,2),padding="same"))generator.add(LeakyReLU(alpha=0.2))generator.add(Conv2D(1, kernel_size=(7, 7), activation='sigmoid', padding="same"))return generator# creation of a discriminator
def creation_discriminateur():discriminator = keras.models.Sequential()discriminator.add(Conv2D(filters=64, kernel_size=(5,5),strides=(2,2), input_shape=(28,28,1), padding="same")) discriminator.add(LeakyReLU(alpha=0.2))discriminator.add(keras.layers.Dropout(0.4))discriminator.add(Conv2D(filters=64, kernel_size=(3,3),strides=(2,2), padding="same"))discriminator.add(LeakyReLU(alpha=0.2))discriminator.add(keras.layers.Dropout(0.4))discriminator.add(keras.layers.Flatten())discriminator.add(keras.layers.Dense(1,activation='sigmoid'))return discriminatordef creation_reseau_GAN(model_generateur, model_discriminateur):GAN = keras.models.Sequential()GAN.add(model_generateur)# 判別模型中的參數設置為不可訓練discriminateur.trainable = FalseGAN.add(model_discriminateur)optimizer_GAN = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)GAN.compile(loss='binary_crossentropy', optimizer=optimizer_GAN)return GAN# 隨機選取潛在編碼(噪聲)
def code_latent_aleatoire(dim_latent, nb_exemples):# distribution normal standard normal distribution# code_latent = np.random.normal(loc=0, scale=1, size=(nb_exemples, dim_latent))# code_latent = code_latent.reshape(nb_exemples, dim_latent)code_latent = np.random.randn(nb_exemples, dim_latent)return code_latentdef construction_image_generateur(generateur_model, dim_latent, nb_exemples):# 生成隨機噪聲X = code_latent_aleatoire(dim_latent,nb_exemples)image_fraud = generateur_model.predict(X)# 生成的圖片的真實標簽為0Label_genere = np.zeros((nb_exemples,1))return image_fraud, Label_generedef tirage_reelle_aleatoire(base_de_donnees, nb_exemples):mat_images_reel = np.zeros((nb_exemples, 28, 28))for i in range(nb_exemples):index = np.random.randint(0, base_de_donnees.shape[0])mat_images_reel[i,:,:] = base_de_donnees[index,:,:]mat_images_reel = mat_images_reel.reshape(nb_exemples, 28, 28, 1)# 從mnist數據集選取的圖片的標簽均為1labels_reel = np.ones((nb_exemples, 1))return mat_images_reel, labels_reel# 用于保存和顯示圖片的函數
def generer_sauvegarde_images(model_generateur,after_epoch,nb_images_sqrt=5,dim_latent=100):nb_images = nb_images_sqrt * nb_images_sqrtimages_frauds, _ = construction_image_generateur(model_generateur,dim_latent=dim_latent,nb_exemples=nb_images)for i in range(nb_images):plt.subplot(nb_images_sqrt, nb_images_sqrt, i+1)plt.imshow(images_frauds[i].reshape(28,28))filepath = "images_fraudes_genere_%d.png" %(after_epoch+1)plt.savefig(filepath)plt.close()# GAN 模型的訓練
def entrainement_GAN_model(model_generateur, model_discriminateur, base_de_donnees, dim_latent, GAN_model, epochs=20, batch_size=128):vector_loss_discriminateur = []vector_loss_gan = []# 通過數據集的大小以及batchsize計算每個epoch對應的batch數量total_batch = np.floor(base_de_donnees.shape[0]/batch_size).astype(np.int)# 對于每個epochfor nb_epoch in range(epochs):# 對于每個batchfor index_batch in range(total_batch):# 每個batch中有一半的圖像為偽造圖片x_fraud, y_fraud = construction_image_generateur(model_generateur, dim_latent=dim_latent, nb_exemples=int(batch_size/2))# 剩下的圖像為真實的從mnist數據集中隨機提取的圖片x_reel, y_reel = tirage_reelle_aleatoire(base_de_donnees=base_de_donnees, nb_exemples=int(batch_size/2))# 疊加所有的數據 id_exemple, 28, 28x_chaque_batch = np.vstack((x_reel, x_fraud))# 疊加所有的標簽 : id_exemple, labely_chaque_batch = np.vstack((y_reel, y_fraud))# 使用構建的一半真實一半偽造的數據訓練判別模型,更新權重。loss_discriminateur = model_discriminateur.train_on_batch(x_chaque_batch, y_chaque_batch)# 接下來是每個Batch訓練疊加模型的部分,其實質是用于訓練生成模型。x_generateur = code_latent_aleatoire(dim_latent=dim_latent, nb_exemples=batch_size)# 這里我們要使得疊加模型的輸出趨向于1,即使判別模型認為生成的圖像也是真實的。y_gan = np.ones((batch_size,1))# 使用判別模型(疊加模型)的輸出來訓練生成模型gan_loss = GAN_model.train_on_batch(x_generateur, y_gan)# 顯示每個batch對應的兩個部分的lossprint("%d epochs,%d batches, loss_discriminateur : %f, loss_gan : %f"%(nb_epoch+1, index_batch+1, loss_discriminateur, gan_loss))# 保存模型以及圖片部分if (nb_epoch + 1)%3 == 0:model_generateur.save("generateur_models/generateur_after_" + str(nb_epoch+1) + "_epoch_" + "loss_%3f"%(gan_loss) + ".h5")model_discriminateur.save("discriminateur_models/discriminateur_after_" + str(nb_epoch+1) + "_epoch_" + "loss_%3f"%(loss_discriminateur) + ".h5") GAN_model.save("gan_models/gan_after_" + str(nb_epoch+1) + "_epoch_" + "loss_%3f"%(gan_loss) + ".h5")generer_sauvegarde_images(model_generateur=model_generateur, after_epoch=nb_epoch)vector_loss_discriminateur.append(loss_discriminateur)vector_loss_gan.append(gan_loss)return vector_loss_discriminateur, vector_loss_gan# load data from database mnist
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(path="mnist.npz")
# normaliser à [0,1]
x_train = x_train/255.0
x_test = x_test/255.0
dim_code_latent = 100
generateur = creation_generateur(dim_latent=dim_code_latent)
discriminateur = creation_discriminateur()
opt_discriminateur = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
discriminateur.compile(loss=keras.losses.binary_crossentropy, optimizer=opt_discriminateur)
GAN = creation_reseau_GAN(generateur, discriminateur)
loss_discriminateur, loss_gan = entrainement_GAN_model(model_generateur=generateur, model_discriminateur=discriminateur,base_de_donnees=x_train, GAN_model=GAN, epochs=21, batch_size=256, dim_latent=dim_code_latent)
訓練過后的生成模型就可以用來生成偽造圖片,下圖為經過9個epoch的訓練后,所生成的偽造圖片,我們可以發現生成的圖像中已經有可以辨認出的數字,例如5,7,9。有理由認為我們在經過更多的epoch訓練后,生成模型的細節將進一步完善。

小tips : 在訓練GAN模型時,要時刻關注判別模型的loss以及accuracy。如果判別模型的loss下降的太快,這就意味著生成模型正在給我們生成一些垃圾數據,這些數據輕易地就被判別模型給判定為偽造了。一般而言,維持判別模型的loss在一定范圍內會對整個GAN模型的訓練有幫助。更進一步的說,一個完美的判別模型,即可以完美分辨真偽圖片的判別模型不能給予生成模型足夠的信息來產生合理的偽造圖片,因此在訓練的過程中時刻保持判別模型的非完美性是有必要的,這也增加了在處理更復雜問題時,GAN模型在調參方面的困難程度。



















