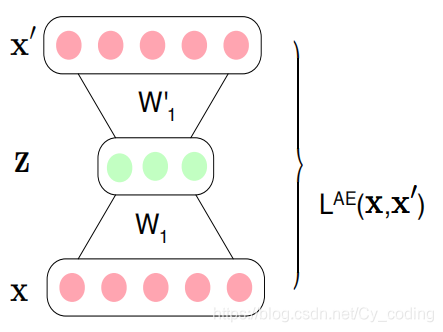
Autoencoder是常見的一種非監督學習的神經網絡。它實際由一組相對應的神經網絡組成(可以是普通的全連接層,或者是卷積層,亦或者是LSTMRNN等等,取決于項目目的),其目的是將輸入數據降維成一個低維度的潛在編碼,再通過解碼器將數據還原出來。因此autoencoder總是包含了兩個部分,編碼部分以及解碼部分。編碼部分負責將輸入降維編碼,解碼部分負責讓輸出層通過潛在編碼還原出輸入層。我們的訓練目標就是使得輸出層與輸入層之間的差距最小化。
我們會發現,有一定的風險使得訓練出的AE模型是一個恒等函數,這是一個需要盡量避免的問題。
Autoencoder CNN 卷積自編碼器
下面我們就用一個簡單的基于mnist數據集的實現,來更好地理解autoencoder的原理。
首先是import相關的模塊,定義一個用于對比顯示輸入圖像與輸出圖像的可視化函數。
# Le dataset MNIST
from tensorflow.keras.datasets import mnist
import tensorflow as tf
from tensorflow.keras.layers import Input,Dense, Conv2D, Conv2DTranspose, MaxPooling2D, Flatten, UpSampling2D, Reshape
from tensorflow.keras.models import Model,Sequential
import numpy as np
import matplotlib.pyplot as pltdef MNIST_AE_disp(img_in, img_out, img_idx):num_img = len(img_idx)plt.figure(figsize=(18, 4))for i, image_idx in enumerate(img_idx):# 顯示輸入圖像ax = plt.subplot(2, num_img, i + 1)plt.imshow(img_in[image_idx].reshape(28, 28))plt.gray()ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)# 顯示輸出圖像ax = plt.subplot(2, num_img, num_img + i + 1)plt.imshow(img_out[image_idx].reshape(28, 28))plt.gray()ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)plt.show()
加載數據并對mnist圖像數據進行預處理,包括正則化以及將圖片擴充成28,28,1的三維。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 正則化 [0, 255] à [0, 1]
x_train=x_train.astype('float32')/float(x_train.max())
x_test=x_test.astype('float32')/float(x_test.max())x_train=x_train.reshape(len(x_train),x_train.shape[1], x_train.shape[2], 1)
x_test=x_test.reshape(len(x_test),x_test.shape[1], x_test.shape[2], 1)
接下來就是自編碼器神經網絡的構建了。這里編碼器與解碼器都由兩個卷積層構成,編碼部分的池化層,對應了解碼部分的upsampling層,以此來保證輸入輸出層的維度是一致的。
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model# 編碼
input_img = Input(shape=(28,28,1))
x = Conv2D(filters=16, kernel_size=(3,3), activation='relu', padding='same')(input_img)
x = MaxPooling2D(pool_size=(2,2))(x)
encoded = Conv2D(filters=8, kernel_size=(3,3), activation='relu', padding='same')(x)# 解碼
x = Conv2D(filters=16, kernel_size=(3,3), activation='relu', padding='same')(encoded)
x = UpSampling2D(size=(2,2))(x)
decoded = Conv2D(filters=1,kernel_size=(3,3), activation='sigmoid', padding='same')(x)autoencodeur = Model(input_img, decoded)
autoencodeur.summary()
Model: "model_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_10 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d_36 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d_17 (MaxPooling (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_37 (Conv2D) (None, 14, 14, 8) 1160
_________________________________________________________________
conv2d_38 (Conv2D) (None, 14, 14, 16) 1168
_________________________________________________________________
up_sampling2d_9 (UpSampling2 (None, 28, 28, 16) 0
_________________________________________________________________
conv2d_39 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 2,633
Trainable params: 2,633
Non-trainable params: 0
_________________________________________________________________接下來就是AE神經網絡的訓練,與一般的神經網絡不同的地方在于,在上述問題中訓練自編碼器時,輸入輸出都是同樣的mnist圖像,以保證在最后輸出層能夠無限接近輸入層,損失降低到最小。
autoencodeur.compile(optimizer='Adam',loss='binary_crossentropy')
autoencodeur.fit(x_train, x_train, batch_size=256, epochs=5)
由于mnist數據集較為簡單,在經過五個epoch之后AE模型基本收斂。
Epoch 1/5
235/235 [==============================] - 59s 250ms/step - loss: 0.3742
Epoch 2/5
235/235 [==============================] - 59s 250ms/step - loss: 0.0706
Epoch 3/5
235/235 [==============================] - 59s 250ms/step - loss: 0.0676
Epoch 4/5
235/235 [==============================] - 59s 251ms/step - loss: 0.0666
Epoch 5/5
235/235 [==============================] - 59s 249ms/step - loss: 0.0658
我們從數據集中隨機選取10張圖片,來對比一下通過自編碼器后輸入輸出的圖片的區別。
# 挑選十個隨機的圖片
num_images=10
np.random.seed(42)
random_test_images=np.random.randint(x_test.shape[0], size=num_images)
# 預測輸出圖片
decoded_img=autoencodeur.predict(x_test)
# 顯示并對比輸入與輸出圖片
MNIST_AE_disp(x_test, decoded_img, random_test_images)

我們從上述例子中可以看到,輸出層與輸入層相差無幾,但是也并不是完全一致的,這說明了我們的自編碼器運作正常且并沒有生成一個恒等模型。接下來我們通過AE來構建一個去噪模型。
Autoencoder denoising 降噪自編碼器
在這個部分中,我們將利用自編碼器來實現對圖片的降噪功能。首先我們生成一些帶噪點的圖片。
noise_factor = 0.4
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape) # clip 用于規定最小值和最大值,array中的值如果小于0則變為0 如果大于1則變為1
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
直接使用上述已經訓練好的模型,來看看當輸入是帶噪點的圖像時,我們的卷積自編碼器的輸出是什么樣的。
num_images=10
np.random.seed(42)
random_test_images_noisy=np.random.randint(x_test_noisy.shape[0], size=num_images) # list that contains the index of images chosen
print(random_test_images)
# On détermine l'image encodée et l'image décodée
decoded_img_noisy=autoencodeur.predict(x_test_noisy)
# visialisation
MNIST_AE_disp(x_test_noisy, decoded_img_noisy, random_test_images_noisy)

第一行對應的圖片是我們手動生成的有噪點的圖像,第二行對應的圖片則是我們通過卷積自編碼器后的輸出圖像。可以發現,輸出的圖像并沒有完全一致,而是一定程度上已經去噪了,其實這可以進一步地佐證卷積神經網絡處理帶噪數據體現出的魯棒性,即相較全連接層而言,對噪聲的敏感程度更低。當然,這個降噪效果還不是很理想,因此我們創建一個新的autoencoder用于處理這一類降噪問題。
DAE = Model(input_img, decoded)
DAE.summary()
DAE.compile(optimizer='Adam', loss='binary_crossentropy')
DAE.fit(x_train_noisy, x_train, batch_size=256, epochs=5)
這個降噪用的自編碼器,其架構與上述卷積自編碼器相同,唯一有區別的地方在于訓練時,我們的輸入層變成了帶噪圖片,而輸出層是沒有噪聲的圖片,以此來達到降噪的訓練目的。
同樣的隨機在數據集中選取圖片進行對比,我們發現通過這個降噪自編碼器后,圖像的噪點明顯減少了,而且與使用單純的卷積自編碼器不同的是,圖像沒有明顯的鈍化,清晰度很高。

在mnist數據集上的實現,同樣可以給我們在其他的圖片降噪問題上以啟發,可以推測的是,更復雜的有噪圖片通過類似的處理,也可以達到類似優秀的降噪效果。



















