
寫在前面
本文組織方式:
-
K8S的架構、作用和目的。需要首先對K8S整體有所了解。
K8S是什么?
為什么是K8S?
K8S怎么做? -
K8S的重要概念,即K8S的API對象。要學習和使用K8S必須知道和掌握的幾個對象。
Pod 實例
Volume 數據卷
Container 容器
Deployment 和 ReplicaSet
Service和Ingress
namespace 命名空間
其他
I. K8S概覽
1.1 K8S是什么?
K8S是Kubernetes的全稱,官方稱其是:
Kubernetes is an open source system for managing containerized applications across multiple hosts. It provides basic mechanisms for deployment, maintenance, and scaling of applications.
用于自動部署、擴展和管理“容器化(containerized)應用程序”的開源系統。
翻譯成大白話就是:“K8S是負責自動化運維管理多個Docker程序的集群”。 那么問題來了:Docker運行可方便了,為什么要用K8S,它有什么優勢?
插一句題外話:
- 為什么Kubernetes要叫Kubernetes呢?維基百科已經交代了(老美對星際是真的癡迷):
Kubernetes(在希臘語意為“舵手”或“駕駛員”)由Joe Beda、Brendan Burns和Craig
McLuckie創立,并由其他谷歌工程師,包括Brian Grant和Tim Hockin等進行加盟創作,并由谷歌在2014年首次對外宣布
。該系統的開發和設計都深受谷歌的Borg系統的影響,其許多頂級貢獻者之前也是Borg系統的開發者。在谷歌內部,Kubernetes的原始代號曾經是Seven,即星際迷航中的Borg(博格人)。Kubernetes標識中舵輪有七個輪輻就是對該項目代號的致意。 - 為什么Kubernetes的縮寫是K8S呢?我個人贊同Why Kubernetes is Abbreviated
k8s中說的觀點“嘛,寫全稱也太累了吧,不如整個縮寫”。其實只保留首位字符,用具體數字來替代省略的字符個數的做法,還是比較常見的。
1.2 為什么是K8S?
試想下傳統的后端部署辦法:把程序包(包括可執行二進制文件、配置文件等)放到服務器上,接著運行啟動腳本把程序跑起來,同時啟動守護腳本定期檢查程序運行狀態、必要的話重新拉起程序。
有問題嗎?顯然有!最大的一個問題在于:如果服務的請求量上來,已部署的服務響應不過來怎么辦? 傳統的做法往往是,如果請求量、內存、CPU超過閾值做了告警,運維馬上再加幾臺服務器,部署好服務之后,接入負載均衡來分擔已有服務的壓力。
問題出現了:從監控告警到部署服務,中間需要人力介入!那么,有沒有辦法自動完成服務的部署、更新、卸載和擴容、縮容呢?
這,就是K8S要做的事情:自動化運維管理Docker(容器化)程序。
1.3 K8S怎么做?
我們已經知道了K8S的核心功能:自動化運維管理多個容器化程序。那么K8S怎么做到的呢?這里,我們從宏觀架構上來學習K8S的設計思想。首先看下圖,圖片來自文章Components of Kubernetes Architecture:

K8S是屬于主從設備模型(Master-Slave架構),即有Master節點負責核心的調度、管理和運維,Slave節點則在執行用戶的程序。但是在K8S中,主節點一般被稱為Master Node或者Head Node(本文采用Master Node稱呼方式),而從節點則被稱為Worker Node或者Node(本文采用Worker Node稱呼方式)。
要注意一點:Master Node和Worker Node是分別安裝了K8S的Master和Woker組件的實體服務器,每個Node都對應了一臺實體服務器(雖然Master Node可以和其中一個Worker Node安裝在同一臺服務器,但是建議Master Node單獨部署),所有Master Node和Worker Node組成了K8S集群,同一個集群可能存在多個Master Node和Worker Node。
首先來看Master Node都有哪些組件:
- API Server。K8S的請求入口服務。API Server負責接收K8S所有請求(來自UI界面或者CLI命令行工具),然后,API
Server根據用戶的具體請求,去通知其他組件干活。 - Scheduler。K8S所有Worker Node的調度器。當用戶要部署服務時,Scheduler會選擇最合適的Worker Node(服務器)來部署。
- Controller Manager。K8S所有Worker Node的監控器。Controller Manager有很多具體的Controller,在文章Components of Kubernetes Architecture中提到的有Node Controller、Service Controller、Volume Controller等。Controller負責監控和調整在Worker Node上部署的服務的狀態,比如用戶要求A服務部署2個副本,那么當其中一個服務掛了的時候,Controller會馬上調整,讓Scheduler再選擇一個Worker Node重新部署服務。
- etcd。K8S的存儲服務。etcd存儲了K8S的關鍵配置和用戶配置,K8S中僅API Server才具備讀寫權限,其他組件必須通過API
Server的接口才能讀寫數據(見Kubernetes Works Like an Operating System)。
接著來看Worker Node的組件,筆者更贊同HOW DO APPLICATIONS RUN ON KUBERNETES文章中提到的組件介紹:
- Kubelet。Worker Node的監視器,以及與Master Node的通訊器。Kubelet是Master
Node安插在Worker Node上的“眼線”,它會定期向Worker
Node匯報自己Node上運行的服務的狀態,并接受來自Master Node的指示采取調整措施。 - Kube-Proxy。K8S的網絡代理。私以為稱呼為Network-Proxy可能更適合?Kube-Proxy負責Node在K8S的網絡通訊、以及對外部網絡流量的負載均衡。
- Container Runtime。Worker Node的運行環境。即安裝了容器化所需的軟件環境確保容器化程序能夠跑起來,比如Docker Engine。大白話就是幫忙裝好了Docker運行環境。
- Logging Layer。K8S的監控狀態收集器。私以為稱呼為Monitor可能更合適?Logging
Layer負責采集Node上所有服務的CPU、內存、磁盤、網絡等監控項信息。 - Add-Ons。K8S管理運維Worker Node的插件組件。有些文章認為Worker
Node只有三大組件,不包含Add-On,但筆者認為K8S系統提供了Add-On機制,讓用戶可以擴展更多定制化功能,是很不錯的亮點。
總結來看,K8S的Master Node具備:請求入口管理(API Server),Worker Node調度(Scheduler),監控和自動調節(Controller Manager),以及存儲功能(etcd);而K8S的Worker Node具備:狀態和監控收集(Kubelet),網絡和負載均衡(Kube-Proxy)、保障容器化運行環境(Container Runtime)、以及定制化功能(Add-Ons)。
II. K8S重要概念
2.1 Pod實例
官方對于Pod的解釋是:
Pod是可以在 Kubernetes 中創建和管理的、最小的可部署的計算單元。
這樣的解釋還是很難讓人明白究竟Pod是什么,但是對于K8S而言,Pod可以說是所有對象中最重要的概念了!因此,我們必須首先清楚地知道“Pod是什么”,再去了解其他的對象。
從官方給出的定義,聯想下“最小的xxx單元”,是不是可以想到本科在學校里學習“進程”的時候,教科書上有一段類似的描述:資源分配的最小單位;還有”線程“的描述是:CPU調度的最小單位。什么意思呢?”最小xx單位“要么就是事物的衡量標準單位,要么就是資源的閉包、集合。前者比如長度米、時間秒;后者比如一個”進程“是存儲和計算的閉包,一個”線程“是CPU資源(包括寄存器、ALU等)的閉包。
同樣的,Pod就是K8S中一個服務的閉包。這么說的好像還是有點玄乎,更加云里霧里了。簡單來說,Pod可以被理解成一群可以共享網絡、存儲和計算資源的容器化服務的集合。再打個形象的比喻,在同一個Pod里的幾個Docker服務/程序,好像被部署在同一臺機器上,可以通過localhost互相訪問,并且可以共用Pod里的存儲資源(這里是指Docker可以掛載Pod內的數據卷,數據卷的概念,后文會詳細講述,暫時理解為“需要手動mount的磁盤”)。筆者總結Pod如下圖,可以看到:同一個Pod之間的Container可以通過localhost互相訪問,并且可以掛載Pod內所有的數據卷;但是不同的Pod之間的Container不能用localhost訪問,也不能掛載其他Pod的數據卷。

對Pod有直觀的認識之后,接著來看K8S中Pod究竟長什么樣子,具體包括哪些資源?
K8S中所有的對象都通過yaml來表示,筆者從官方網站摘錄了一個最簡單的Pod的yaml:
apiVersion: v1
kind: Pod
metadata:name: memory-demonamespace: mem-example
spec:containers:- name: memory-demo-ctrimage: polinux/stressresources:limits:memory: "200Mi"requests:memory: "100Mi"command: ["stress"]args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]volumeMounts:- name: redis-storagemountPath: /data/redisvolumes:- name: redis-storageemptyDir: {}
看不懂不必慌張,且耐心聽下面的解釋:
- apiVersion記錄K8S的API Server版本,現在看到的都是v1,用戶不用管。
- kind記錄該yaml的對象,比如這是一份Pod的yaml配置文件,那么值內容就是Pod。
- metadata記錄了Pod自身的元數據,比如這個Pod的名字、這個Pod屬于哪個namespace(命名空間的概念,后文會詳述,暫時理解為“同一個命名空間內的對象互相可見”)。
- spec記錄了Pod內部所有的資源的詳細信息,看懂這個很重要:
- containers記錄了Pod內的容器信息,containers包括了:name容器名,image容器的鏡像地址,resources容器需要的CPU、內存、GPU等資源,command容器的入口命令,args容器的入口參數,volumeMounts容器要掛載的Pod數據卷等。可以看到,上述這些信息都是啟動容器的必要和必需的信息。
- volumes記錄了Pod內的數據卷信息,后文會詳細介紹Pod的數據卷。
2.2 Volume 數據卷
K8S支持很多類型的volume數據卷掛載,具體請參見K8S卷。前文就“如何理解volume”提到:“需要手動mount的磁盤”,此外,有一點可以幫助理解:數據卷volume是Pod內部的磁盤資源。
其實,單單就Volume來說,不難理解。但是上面還看到了volumeMounts,這倆是什么關系呢?
volume是K8S的對象,對應一個實體的數據卷;而volumeMounts只是container的掛載點,對應container的其中一個參數。但是,volumeMounts依賴于volume,只有當Pod內有volume資源的時候,該Pod內部的container才可能有volumeMounts。
2.3 Container 容器
本文中提到的鏡像Image、容器Container,都指代了Pod下的一個container。關于K8S中的容器,在2.1Pod章節都已經交代了,這里無非再啰嗦一句:一個Pod內可以有多個容器container。
在Pod中,容器也有分類,對這個感興趣的同學歡迎自行資料:
- 標準容器 Application Container。
- 初始化容器 Init Container。
- 邊車容器 Sidecar Container。
- 臨時容器 Ephemeral Container。
一般來說,我們部署的大多是標準容器( Application Container)。
2.4 Deployment 和 ReplicaSet(簡稱RS)
除了Pod之外,K8S中最常聽到的另一個對象就是Deployment了。那么,什么是Deployment呢?官方給出了一個要命的解釋:
一個 Deployment 控制器為 Pods 和 ReplicaSets 提供聲明式的更新能力。 你負責描述 Deployment 中的
目標狀態,而 Deployment 控制器以受控速率更改實際狀態, 使其變為期望狀態。你可以定義 Deployment 以創建新的
ReplicaSet,或刪除現有 Deployment,并通過新的 Deployment 收養其資源。
翻譯一下:Deployment的作用是管理和控制Pod和ReplicaSet,管控它們運行在用戶期望的狀態中。哎,打個形象的比喻,Deployment就是包工頭,主要負責監督底下的工人Pod干活,確保每時每刻有用戶要求數量的Pod在工作。如果一旦發現某個工人Pod不行了,就趕緊新拉一個Pod過來替換它。
新的問題又來了:那什么是ReplicaSets呢?
ReplicaSet 的目的是維護一組在任何時候都處于運行狀態的 Pod 副本的穩定集合。 因此,它通常用來保證給定數量的、完全相同的
Pod 的可用性。
再來翻譯下:ReplicaSet的作用就是管理和控制Pod,管控他們好好干活。但是,ReplicaSet受控于Deployment。形象來說,ReplicaSet就是總包工頭手下的小包工頭。
筆者總結得到下面這幅圖,希望能幫助理解:

新的問題又來了:如果都是為了管控Pod好好干活,為什么要設置Deployment和ReplicaSet兩個層級呢,直接讓Deployment來管理不可以嗎?
回答:不清楚,但是私以為是因為先有ReplicaSet,但是使用中發現ReplicaSet不夠滿足要求,于是又整了一個Deployment(有清楚Deployment和ReplicaSet聯系和區別的小伙伴歡迎留言啊)。
但是,從K8S使用者角度來看,用戶會直接操作Deployment部署服務,而當Deployment被部署的時候,K8S會自動生成要求的ReplicaSet和Pod。在K8S官方文檔中也指出用戶只需要關心Deployment而不操心ReplicaSet:
This actually means that you may never need to manipulate ReplicaSet
objects: use a Deployment instead, and define your application in the
spec section.
這實際上意味著您可能永遠不需要操作ReplicaSet對象:直接使用Deployments并在規范部分定義應用程序。
補充說明:在K8S中還有一個對象 — ReplicationController(簡稱RC),官方文檔對它的定義是:
ReplicationController 確保在任何時候都有特定數量的 Pod 副本處于運行狀態。
換句話說,ReplicationController 確保一個 Pod 或一組同類的 Pod 總是可用的。
怎么樣,和ReplicaSet是不是很相近?在Deployments, ReplicaSets, and pods教程中說“ReplicationController是ReplicaSet的前身”,官方也推薦用Deployment取代ReplicationController來部署服務。
2.5 Service和Ingress
吐槽下K8S的概念/對象/資源是真的多啊!前文介紹的Deployment、ReplicationController和ReplicaSet主要管控Pod程序服務;那么,Service和Ingress則負責管控Pod網絡服務。
我們先來看看官方文檔中Service的定義:
將運行在一組 Pods 上的應用程序公開為網絡服務的抽象方法。 使用 Kubernetes,您無需修改應用程序即可使用不熟悉的服務發現機制。
Kubernetes 為 Pods 提供自己的 IP 地址,并為一組 Pod 提供相同的 DNS 名, 并且可以在它們之間進行負載均衡。
翻譯下:K8S中的服務(Service)并不是我們常說的“服務”的含義,而更像是網關層,是若干個Pod的流量入口、流量均衡器。
那么,為什么要Service呢?
私以為在這一點上,官方文檔講解地非常清楚:
Kubernetes Pod 是有生命周期的。 它們可以被創建,而且銷毀之后不會再啟動。 如果您使用 Deployment
來運行您的應用程序,則它可以動態創建和銷毀 Pod。 每個 Pod 都有自己的 IP 地址,但是在 Deployment
中,在同一時刻運行的 Pod 集合可能與稍后運行該應用程序的 Pod 集合不同。 這導致了一個問題: 如果一組
Pod(稱為“后端”)為群集內的其他 Pod(稱為“前端”)提供功能, 那么前端如何找出并跟蹤要連接的 IP
地址,以便前端可以使用工作量的后端部分?
補充說明:K8S集群的網絡管理和拓撲也有特別的設計,以后會專門出一章節來詳細介紹K8S中的網絡。這里需要清楚一點:K8S集群內的每一個Pod都有自己的IP(是不是很類似一個Pod就是一臺服務器,然而事實上是多個Pod存在于一臺服務器上,只不過是K8S做了網絡隔離),在K8S集群內部還有DNS等網絡服務(一個K8S集群就如同管理了多區域的服務器,可以做復雜的網絡拓撲)。
此外,筆者推薦k8s外網如何訪問業務應用對于Service的介紹,不過對于新手而言,推薦閱讀前半部分對于service的介紹即可,后半部分就太復雜了。我這里做了簡單的總結:
Service是K8S服務的核心,屏蔽了服務細節,統一對外暴露服務接口,真正做到了“微服務”。舉個例子,我們的一個服務A,部署了3個備份,也就是3個Pod;對于用戶來說,只需要關注一個Service的入口就可以,而不需要操心究竟應該請求哪一個Pod。優勢非常明顯:一方面外部用戶不需要感知因為Pod上服務的意外崩潰、K8S重新拉起Pod而造成的IP變更,外部用戶也不需要感知因升級、變更服務帶來的Pod替換而造成的IP變化,另一方面,Service還可以做流量負載均衡。
但是,Service主要負責K8S集群內部的網絡拓撲。那么集群外部怎么訪問集群內部呢?這個時候就需要Ingress了,官方文檔中的解釋是:
Ingress 是對集群中服務的外部訪問進行管理的 API 對象,典型的訪問方式是 HTTP。 Ingress 可以提供負載均衡、SSL
終結和基于名稱的虛擬托管。
翻譯一下:Ingress是整個K8S集群的接入層,復雜集群內外通訊。
最后,筆者把Ingress和Service的關系繪制網絡拓撲關系圖如下,希望對理解這兩個概念有所幫助:

2.6 namespace 命名空間
和前文介紹的所有的概念都不一樣,namespace跟Pod沒有直接關系,而是K8S另一個維度的對象。或者說,前文提到的概念都是為了服務Pod的,而namespace則是為了服務整個K8S集群的。
那么,namespace是什么呢?
上官方文檔定義:
Kubernetes 支持多個虛擬集群,它們底層依賴于同一個物理集群。 這些虛擬集群被稱為名字空間。
翻譯一下:namespace是為了把一個K8S集群劃分為若干個資源不可共享的虛擬集群而誕生的。
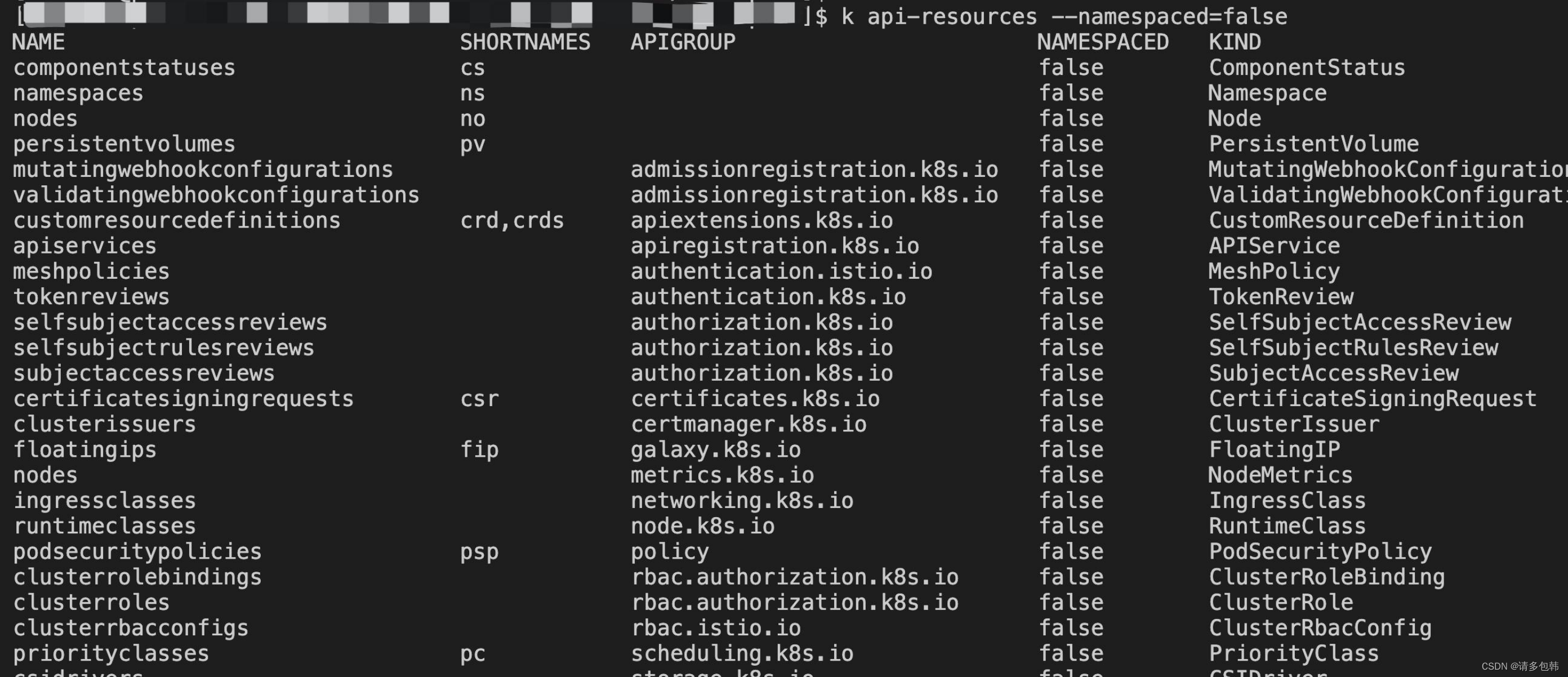
也就是說,可以通過在K8S集群內創建namespace來分隔資源和對象。比如我有2個業務A和B,那么我可以創建ns-a和ns-b分別部署業務A和B的服務,如在ns-a中部署了一個deployment,名字是hello,返回用戶的是“hello a”;在ns-b中也部署了一個deployment,名字恰巧也是hello,返回用戶的是“hello b”(要知道,在同一個namespace下deployment不能同名;但是不同namespace之間沒有影響)。前文提到的所有對象,都是在namespace下的;當然,也有一些對象是不隸屬于namespace的,而是在K8S集群內全局可見的,官方文檔提到的可以通過命令來查看,具體命令的使用辦法,筆者會出后續的實戰文章來介紹,先貼下命令:
# 位于名字空間中的資源
kubectl api-resources --namespaced=true
?
# 不在名字空間中的資源
kubectl api-resources --namespaced=false
不在namespace下的對象有:
在namespace下的對象有(部分):
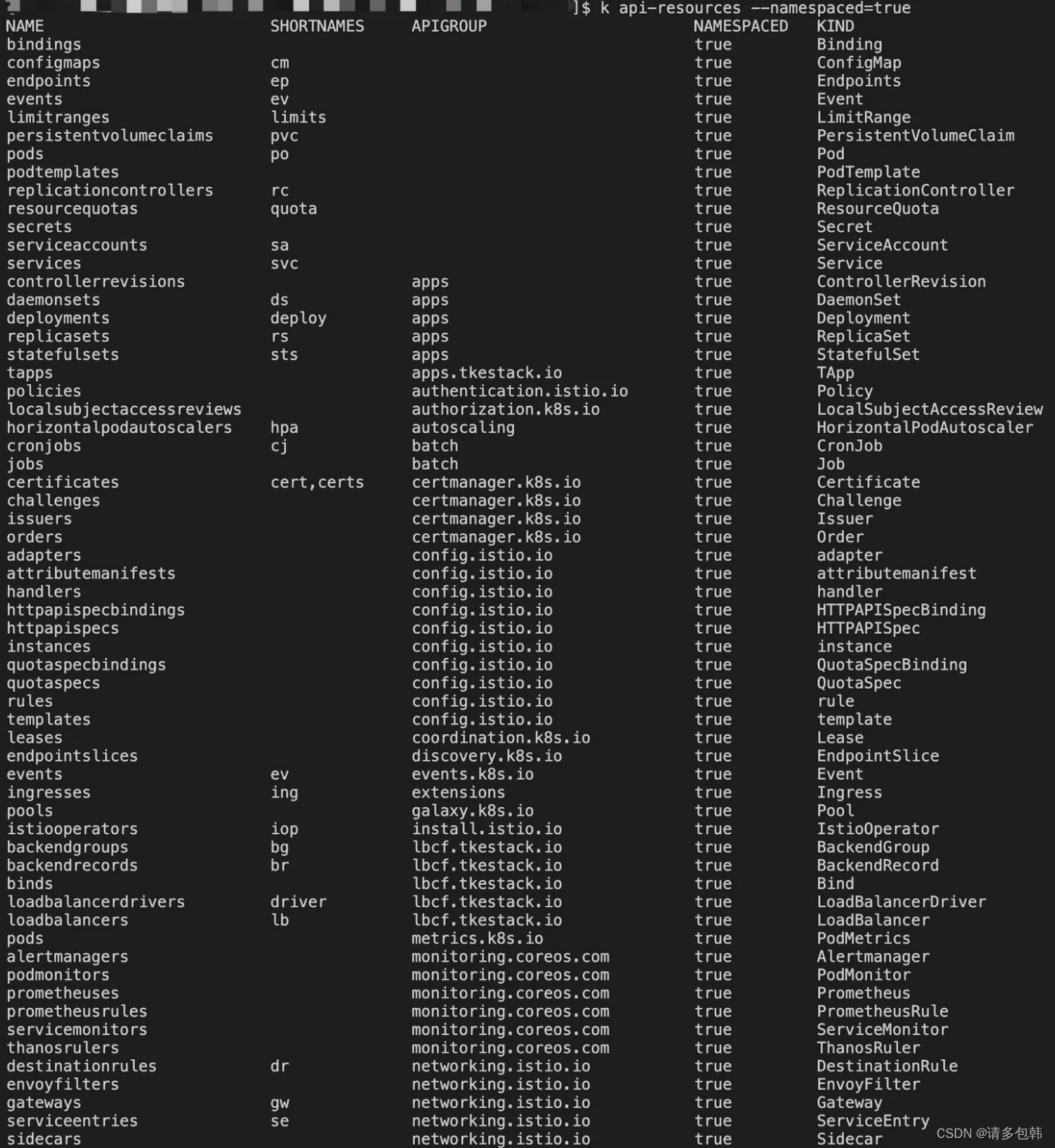
2.7 其他
K8S的對象實在太多了,2.1-2.6介紹的是在實際使用K8S部署服務最常見的。其他的還有Job、CronJob等等,在對K8S有了比較清楚的認知之后,再去學習更多的K8S對象,不是難事。
寫在后面
本文是K8S系列文章第一篇,希望能夠幫助對K8S不了解的新手快速了解K8S。如果文章中有紕漏,非常歡迎留言或者私信指出;有理解錯誤的地方,更是歡迎留言或者私信告知。
筆者一邊寫文章,一邊查閱和整理K8S資料,過程中越發感覺K8S架構的完備、設計的精妙,是值得深入研究的,K8S大受歡迎是有道理的!再次感嘆下。






數據類型(基礎類型和任意類型))
及其在網絡安全與爬蟲中的應用)
)








)

