在當今數據密集型的業務環境下,傳統的集中式架構已經難以滿足高可用性和高并發性的要求。而去中心化微服務集群則通過分散式的架構,將系統劃分為多個小型的、獨立部署的微服務單元,每個微服務負責特定的業務功能,實現了系統的高度模塊化。下面,我們將深入探討這一架構的優勢及其在數據集成中的應用場景。
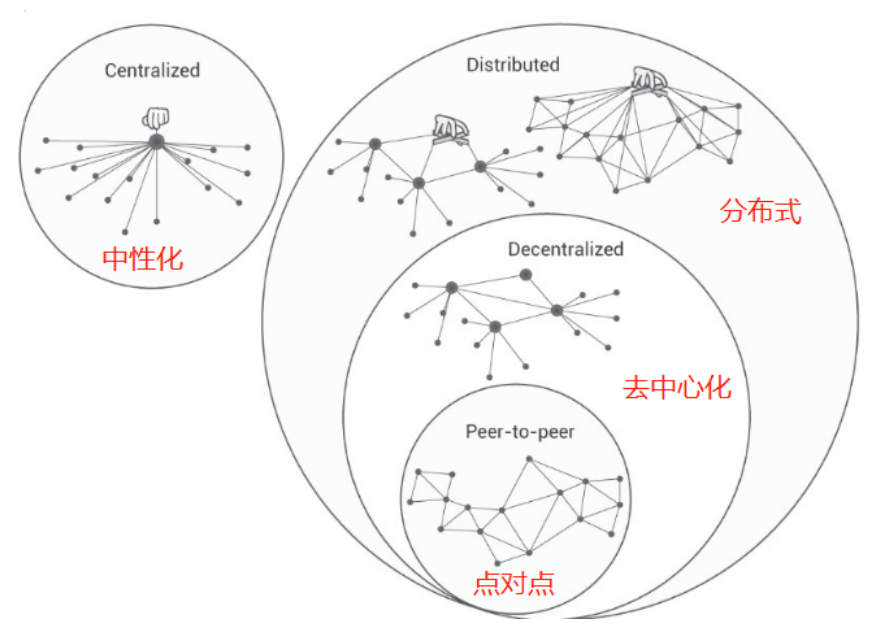
1. 去中心化微服務集群的優勢
1.1 高可用性與容錯性
去中心化的架構使得微服務集群可以在分布式環境中運行,從而實現高可用性。每個微服務單元都是相對獨立的,因此在一個微服務發生故障時,其他微服務仍然可以繼續運行,避免了整個系統的崩潰。此外,容錯機制可以保障在微服務失敗時進行自動重試,確保數據集成任務的連續性。
1.2 彈性擴展與動態調整
微服務集群架構支持根據實際負載需求進行彈性擴展。當數據集成任務的需求增長時,可以動態地增加微服務實例,以應對高并發情況。反之,在需求減少時可以縮減實例,從而實現資源的最優利用。
1.3 自定義負載均衡與性能優化
去中心化微服務集群允許使用自定義的負載均衡策略,根據任務類型、數據量等因素進行動態調整。這樣可以確保不同任務在集群中的分配均衡,從而提高整體性能。
1.4 數據隔離與安全性增強
每個微服務單元都運行在獨立的容器中,這意味著不同任務的數據被隔離開來,降低了數據泄露和安全風險。此外,微服務集群支持按需進行訪問控制和權限管理,進一步增強數據集成的安全性。
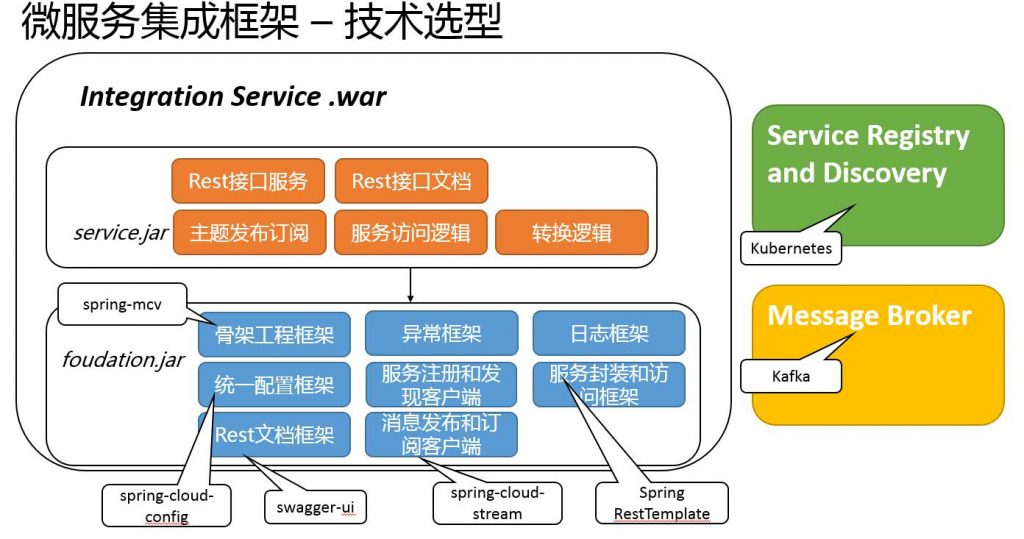
2. 去中心化微服務集群的應用場景
2.1 大數據批處理任務
在處理大規模數據批處理任務時,去中心化微服務集群可以將數據分片處理,提高任務執行效率。每個微服務負責一部分數據處理,通過并行計算縮短任務完成時間。
2.2 實時數據流集成
對于實時數據集成,微服務集群可以分別處理不同數據源的數據,并將其實時匯總。這種架構能夠應對多樣的數據格式和頻率,確保數據流的準確性和實時性。
2.3 跨系統數據同步
在跨多個系統進行數據同步時,微服務集群可以分別處理不同系統的數據映射與轉換,保證數據在不同系統間的一致性。同時,由于微服務的獨立性,單個系統的故障不會影響整體數據同步流程。
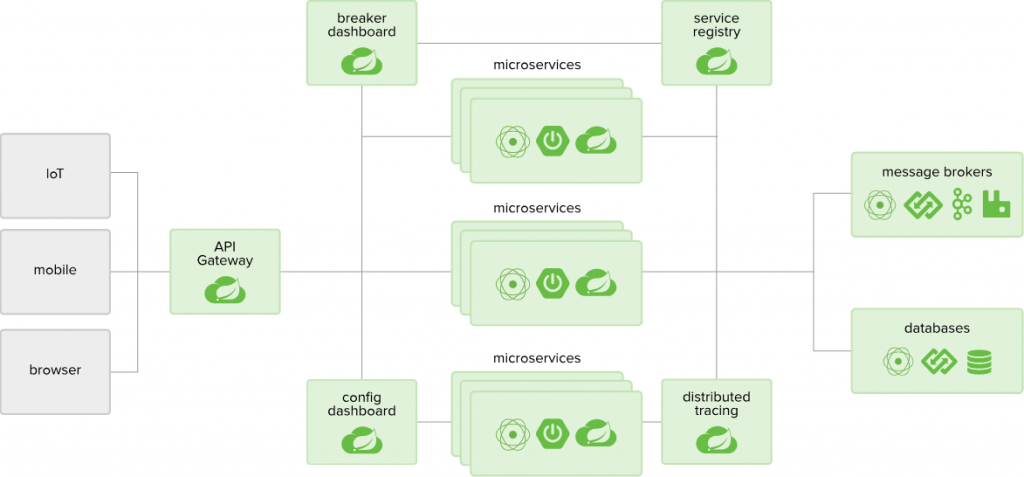
3. 總結
去中心化微服務集群作為數據集成工具領域的一項創新,帶來了高可用性、彈性擴展、自定義負載均衡和安全性增強等諸多優勢。在大數據批處理、實時數據流集成和跨系統數據同步等應用場景下,這一架構展現出巨大的潛力。通過將任務分解為獨立的微服務單元,去中心化微服務集群為數據集成工作賦予了新的活力,助力企業應對日益復雜的數據挑戰。
是一款低代碼/高效率的ETL工具,同時也是一款數據集成工具,它可以幫助企業提高數據治理效率和質量。滿足了去中心化微服務集群,能同時滿足高可用、高并發等要求,并支持各模塊微服務部署、動態擴縮、故障遷移、自定義負載均衡、任務容錯與重試等各類場景。
了解更多數據倉庫與數據集成關干貨內容請關注>>>
https://www.finedatalink.com/tb/
免費試用、獲取更多信息,點擊了解更多>>>
https://www.finedatalink.com/?utm_source=baijiahao&utm_medium=csdn&utm_term=seo437
)










簡介以及如何收集event和基于event告警)







)