前言
今年因為這個疫情,感覺這是從工作以來過的最久的一個年了,在家呆的時間不是一般的久,算一算有好幾個月呢!我大概是3月底快4月了才出門,投了超多的簡歷,天天面試面試面試面試面試面試面試…慶幸的是還是上岸了(嘻嘻開心開心)。但其實所謂的慶幸也是靠努力堆起來的,我記憶力還比較好,背一背,沒啥難的,背了1000道題。。。(注:關于我背的這1000題,文末有分享)
眼看著6月就過去了,再過兩天就7月份了,想著面試大軍可能也過不了幾天就要來了,所以這兩天整理了一些面經,今天給大家看的是“美團+字節跳動+騰訊”這三家的,每家一二三面,我想大家可以自己測試一下能堅持到哪里。
2. ZooKeeper 介紹
2.1. ZooKeeper 由來
正式介紹 ZooKeeper 之前,我們先來看看 ZooKeeper 的由來,還挺有意思的。
下面這段內容摘自《從 Paxos 到 ZooKeeper 》第四章第一節,推薦大家閱讀一下:
ZooKeeper 最早起源于雅虎研究院的一個研究小組。在當時,研究人員發現,在雅虎內部很多大型系統基本都需要依賴一個類似的系統來進行分布式協調,但是這些系統往往都存在分布式單點問題。所以,雅虎的開發人員就試圖開發一個通用的無單點問題的分布式協調框架,以便讓開發人員將精力集中在處理業務邏輯上。
關于“ZooKeeper”這個項目的名字,其實也有一段趣聞。在立項初期,考慮到之前內部很多項目都是使用動物的名字來命名的(例如著名的 Pig 項目),雅虎的工程師希望給這個項目也取一個動物的名字。時任研究院的首席科學家 RaghuRamakrishnan 開玩笑地說:“在這樣下去,我們這兒就變成動物園了!”此話一出,大家紛紛表示就叫動物園管理員吧一一一因為各個以動物命名的分布式組件放在一起,雅虎的整個分布式系統看上去就像一個大型的動物園了,而 ZooKeeper 正好要用來進行分布式環境的協調一一于是,ZooKeeper 的名字也就由此誕生了。
2.2. ZooKeeper 概覽
ZooKeeper 是一個開源的分布式協調服務,它的設計目標是將那些復雜且容易出錯的分布式一致性服務封裝起來,構成一個高效可靠的原語集,并以一系列簡單易用的接口提供給用戶使用。
原語: 操作系統或計算機網絡用語范疇。是由若干條指令組成的,用于完成一定功能的一個過程。具有不可分割性·即原語的執行必須是連續的,在執行過程中不允許被中斷。
ZooKeeper 為我們提供了高可用、高性能、穩定的分布式數據一致性解決方案,通常被用于實現諸如數據發布/訂閱、負載均衡、命名服務、分布式協調/通知、集群管理、Master 選舉、分布式鎖和分布式隊列等功能。
另外,ZooKeeper 將數據保存在內存中,性能是非常棒的。 在“讀”多于“寫”的應用程序中尤其地高性能,因為“寫”會導致所有的服務器間同步狀態。(“讀”多于“寫”是協調服務的典型場景)。
2.3. ZooKeeper 特點
- 順序一致性: 從同一客戶端發起的事務請求,最終將會嚴格地按照順序被應用到 ZooKeeper 中去。
- 原子性: 所有事務請求的處理結果在整個集群中所有機器上的應用情況是一致的,也就是說,要么整個集群中所有的機器都成功應用了某一個事務,要么都沒有應用。
- 單一系統映像 : 無論客戶端連到哪一個 ZooKeeper 服務器上,其看到的服務端數據模型都是一致的。
- 可靠性: 一旦一次更改請求被應用,更改的結果就會被持久化,直到被下一次更改覆蓋。
2.4. ZooKeeper 典型應用場景
ZooKeeper 概覽中,我們介紹到使用其通常被用于實現諸如數據發布/訂閱、負載均衡、命名服務、分布式協調/通知、集群管理、Master 選舉、分布式鎖和分布式隊列等功能。
下面選 3 個典型的應用場景來專門說說:
- 分布式鎖 : 通過創建唯一節點獲得分布式鎖,當獲得鎖的一方執行完相關代碼或者是掛掉之后就釋放鎖。
- 命名服務 :可以通過 ZooKeeper 的順序節點生成全局唯一 ID
- 數據發布/訂閱 :通過 Watcher 機制 可以很方便地實現數據發布/訂閱。當你將數據發布到 ZooKeeper 被監聽的節點上,其他機器可通過監聽 ZooKeeper 上節點的變化來實現配置的動態更新。
實際上,這些功能的實現基本都得益于 ZooKeeper 可以保存數據的功能,但是 ZooKeeper 不適合保存大量數據,這一點需要注意。
2.5. 有哪些著名的開源項目用到了 ZooKeeper?
- Kafka : ZooKeeper 主要為 Kafka 提供 Broker 和 Topic 的注冊以及多個 Partition 的負載均衡等功能。
- Hbase : ZooKeeper 為 Hbase 提供確保整個集群只有一個 Master 以及保存和提供 regionserver 狀態信息(是否在線)等功能。
- Hadoop : ZooKeeper 為 Namenode 提供高可用支持。
3. ZooKeeper 重要概念解讀
破音:拿出小本本,下面的內容非常重要哦!
3.1. Data model(數據模型)
ZooKeeper 數據模型采用層次化的多叉樹形結構,每個節點上都可以存儲數據,這些數據可以是數字、字符串或者是二級制序列。并且。每個節點還可以擁有 N 個子節點,最上層是根節點以“/”來代表。每個數據節點在 ZooKeeper 中被稱為 znode,它是 ZooKeeper 中數據的最小單元。并且,每個 znode 都一個唯一的路徑標識。
強調一句:ZooKeeper 主要是用來協調服務的,而不是用來存儲業務數據的,所以不要放比較大的數據在 znode 上,ZooKeeper 給出的上限是每個結點的數據大小最大是 1M。
從下圖可以更直觀地看出:ZooKeeper 節點路徑標識方式和 Unix 文件系統路徑非常相似,都是由一系列使用斜杠"/"進行分割的路徑表示,開發人員可以向這個節點中寫人數據,也可以在節點下面創建子節點。這些操作我們后面都會介紹到。
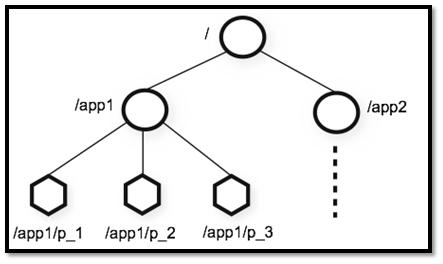
3.2. znode(數據節點)
介紹了 ZooKeeper 樹形數據模型之后,我們知道每個數據節點在 ZooKeeper 中被稱為 znode,它是 ZooKeeper 中數據的最小單元。你要存放的數據就放在上面,是你使用 ZooKeeper 過程中經常需要接觸到的一個概念。
3.2.1. znode 4種類型
我們通常是將 znode 分為 4 大類:
- 持久(PERSISTENT)節點 :一旦創建就一直存在即使 ZooKeeper 集群宕機,直到將其刪除。
- 臨時(EPHEMERAL)節點 :臨時節點的生命周期是與 客戶端會話(session) 綁定的,會話消失則節點消失 。并且,臨時節點只能做葉子節點 ,不能創建子節點。
- 持久順序(PERSISTENT_SEQUENTIAL)節點 :除了具有持久(PERSISTENT)節點的特性之外, 子節點的名稱還具有順序性。比如
/node1/app0000000001、/node1/app0000000002。 - 臨時順序(EPHEMERAL_SEQUENTIAL)節點 :除了具備臨時(EPHEMERAL)節點的特性之外,子節點的名稱還具有順序性。
3.2.2. znode 數據結構
每個 znode 由 2 部分組成:
- stat :狀態信息
- data : 節點存放的數據的具體內容
言盡于此,完結
無論是一個初級的 coder,高級的程序員,還是頂級的系統架構師,應該都有深刻的領會到設計模式的重要性。
- 第一,設計模式能讓專業人之間交流方便,如下:
程序員A:這里我用了XXX設計模式
程序員B:那我大致了解你程序的設計思路了
- 第二,易維護
項目經理:今天客戶有這樣一個需求…
程序員:明白了,這里我使用了XXX設計模式,所以改起來很快
- 第三,設計模式是編程經驗的總結
程序員A:B,你怎么想到要這樣去構建你的代碼
程序員B:在我學習了XXX設計模式之后,好像自然而然就感覺這樣寫能避免一些問題
- 第四,學習設計模式并不是必須的
程序員A:B,你這段代碼使用的是XXX設計模式對嗎?
程序員B:不好意思,我沒有學習過設計模式,但是我的經驗告訴我是這樣寫的
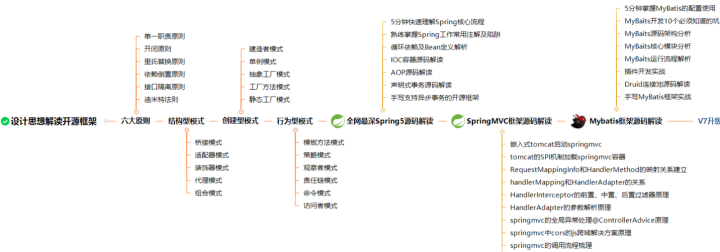
從設計思想解讀開源框架,一步一步到Spring、Spring5、SpringMVC、MyBatis等源碼解讀,我都已收集整理全套,篇幅有限,這塊只是詳細的解說了23種設計模式,整理的文件如下圖一覽無余!
資料領取方式:點擊這里下載
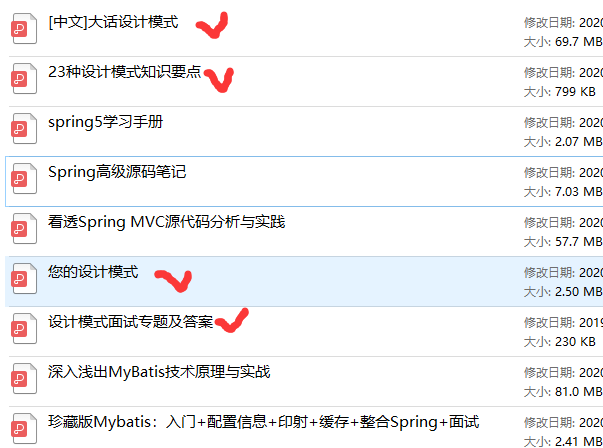
式,整理的文件如下圖一覽無余!
資料領取方式:點擊這里下載
[外鏈圖片轉存中…(img-mtlMurhw-1622454514723)]
搜集費時費力,能看到此處的都是真愛!




方法的簡單練習 #2 -- ItemUpdting事件中抓取「修改后」的值)

![[學習之道] 修福不修慧,大象披瓔珞; 修慧不修福,羅漢托空缽 (學習寫程序,只靠補習上課嗎?)...](http://pic.xiahunao.cn/[學習之道] 修福不修慧,大象披瓔珞; 修慧不修福,羅漢托空缽 (學習寫程序,只靠補習上課嗎?)...)










![[New Portal]Windows Azure Web Site (4) Web Site Gallery](http://pic.xiahunao.cn/[New Portal]Windows Azure Web Site (4) Web Site Gallery)

