
?

?
? ?
? 
?
? ? ? ? ? ?
? ? ? ? ? 

Adagrad //適合稀疏樣本
RMSprop//借鑒Adagrad的思想,改進使得不會出現學習率越來越低的問題
? ?
? 
由此可見Adadelta既不需要輸入學習率等參數,而且表現得非常好!!但是我試了幾次,這個優化器效果極差!!還是具體問題具體分析吧
?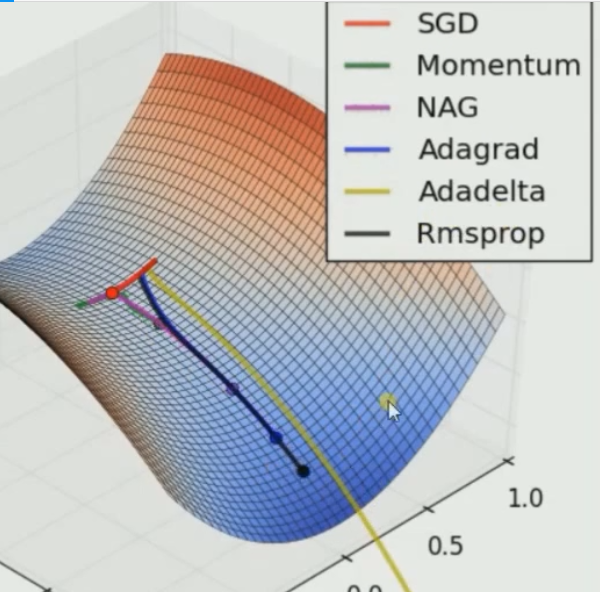 ?由此可見只有SGD無法逃離局部最小值,此處仍然是Adadelta速度最快
?由此可見只有SGD無法逃離局部最小值,此處仍然是Adadelta速度最快
但是我們并不能因此不使用SGD,因為評價一個訓練器的好壞不是靠速度,而是靠最終的準確率!
最好的訓練器是在訓練速度適中的情況下,準確率最高的!吳推薦Adam,具體是什么得因問題而定!
還是使用Adam吧!這個訓練器很強!
?

方法的簡單練習 #2 -- ItemUpdting事件中抓取「修改后」的值)

![[學習之道] 修福不修慧,大象披瓔珞; 修慧不修福,羅漢托空缽 (學習寫程序,只靠補習上課嗎?)...](http://pic.xiahunao.cn/[學習之道] 修福不修慧,大象披瓔珞; 修慧不修福,羅漢托空缽 (學習寫程序,只靠補習上課嗎?)...)










![[New Portal]Windows Azure Web Site (4) Web Site Gallery](http://pic.xiahunao.cn/[New Portal]Windows Azure Web Site (4) Web Site Gallery)




