思維導圖

前言
在很多時候,我們都可以在各種框架應用中看到ZooKeeper的身影,比如Kafka中間件,Dubbo框架,Hadoop等等。為什么到處都看到ZooKeeper?
一、
前些年,互聯網行業里對架構師這個崗位的標準還不是很清晰。所以,很多架構師的工作往往就是一些技術被公司認可的資深工程師負責。
彼時,正巧我也是這類人員之一,故也得到了一個從零開始架設一套廣告投放平臺的機會。
我很喜歡鉆研技術,對這種機會自然很看重。
那時候,架構并無如今這么復雜,一開始就是前面搞幾個 Web 應用,后面共享個數據庫。大致像這樣:
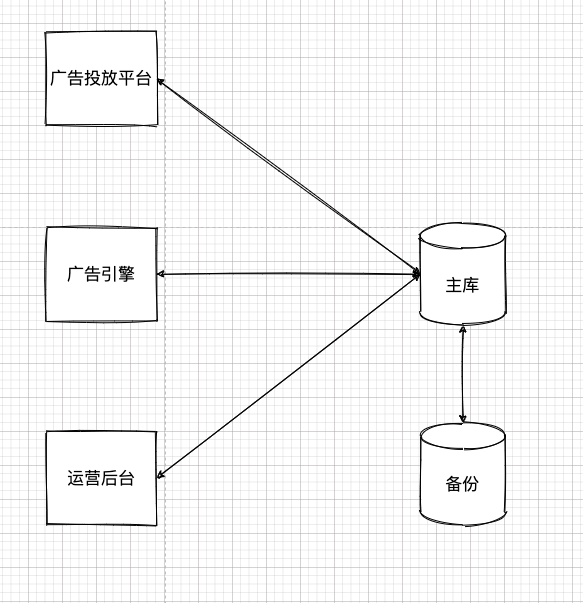
當然,上面的架構其實做了很多簡化,省略了很多細節。比如,為了提高性能做的緩存,為了提高吞吐做的負載均衡統統沒有在上圖給出。因為這些和本章話題無關,暫時咱們就忽略這些東西,只看核心部分。
這套架構初期運行還是沒什么問題的,再加上一些緩存機制,初期一些性能問題都通過調整緩存提升緩存的碰撞率應付了過去。
可是,隨著廣告投放量的增大,廣告的訪問量也在暴漲。這些暴漲的訪問量引發了性能問題。當時,由于前端有負載均衡,應用層倒是沒出現什么問題……
問題出在后面的數據庫上
二、
這套架構數據庫用的是 MySQL,本身也只有一臺主庫在對外服務,另外一臺備庫采用了 MySQL 自己的全同步機制做實時備份。
當廣告訪問量暴漲的時候,因為業務需要,很多數據需要在數據庫中做實時插入,這就導致了大量的磁盤 IO 產生。這些大量的磁盤 IO 造成了數據庫本身性能的急劇下降。
悲催的是,整套廣告平臺的所有功能又都是共享一個數據庫的,所以隨著數據庫本身的性能下降,平臺的所有功能都受到了影響。
由于問題主要在于大量廣告流量的寫入,所以,靠讀寫分離的方案去緩解問題這條路就走不通了。
只好先升級硬件了。在經過了幾輪硬件升級和數據庫調優之后,單數據庫再也無法支撐不斷上漲的流量了。沒辦法,要考慮搞數據庫切分了。
那時候,我個人是很恐懼數據庫切分的。
原因不僅僅在于需要在應用層多寫很多復雜的邏輯,其根本原因是當時流行的 2PC(兩階段提交)方案,這個方案本身能保證在數據庫切分的情況下,原來的事務依然保留著自身的 ACID 性質。即:
- Atomicity(原子性),不管事務里執行多少命令,對外它們都是一體的,要么都執行,要么都不執行。
- Consistency(一致性),正因為事務里要么做要么都不做,所以數據庫的狀態變化只能由事務變更后,才會叫一致性狀態。
- Isolation(隔離性),事務里做的事兒事務外面誰也看不到,就跟個盒子把數據罩起來一樣,到底中間怎么變化的,事務外面的觀察不到。
- Durability(持久性),事務確認成功了,那這狀態就永久不變了。
但也正因為這 4 個特性,2PC 才讓我顧慮重重。
顧慮1:首先,數據庫拆分了,那么根據事務的原子性,事務自身必須是一體的,那么事務涉及到的不同的數據庫就必須都訪問一遍,而這本身就意味著很高的通信成本。
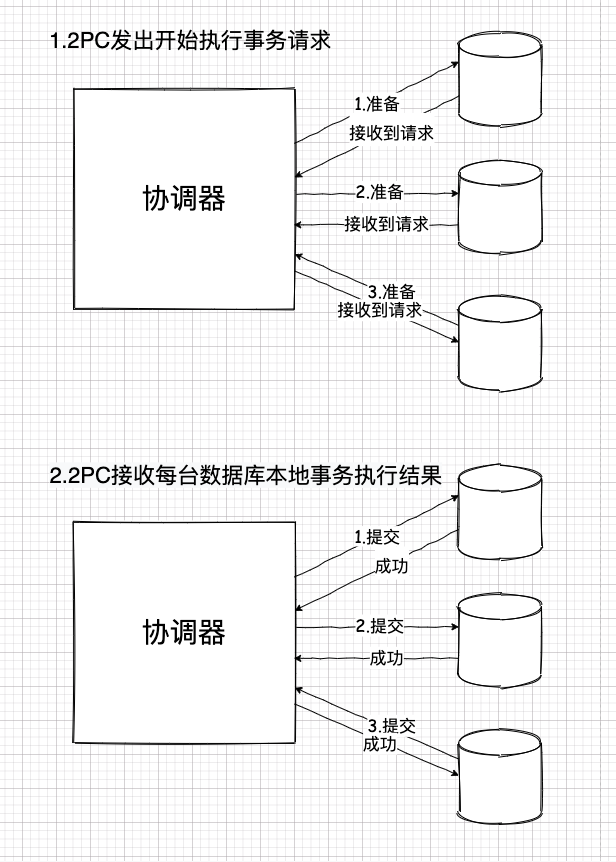
再加上,為了保持一致性,事務失敗后,還必須恢復各個數據庫原來的狀態,這就必須讓已經成功執行過本地事務的數據庫全部回滾。
而稍微懂點數據庫的人都知道,這個成本有多大。
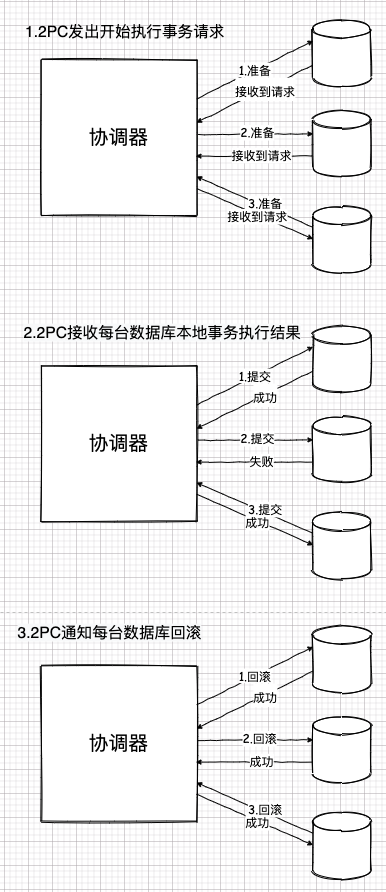
更可怕的是,本身事務的隔離性還可能加上鎖。一旦一個熱點數據區域被大量訪問,最差情況就可能出現串行訪問。而這對此套平臺,包括我自己都將是個悲劇。
顧慮2:數據庫的拆分會造成整個平臺的可用性下降。
假設我現在有一臺數據庫,它的可用性是 99.9%。如果因為分庫,數據庫從一臺變成兩臺,那么平臺的可用性就會變成:
平臺的可用性 = 99.9% * 99.9% = 99.8%
從 99.9% 變成了 99.8%,這意味著可用性下降了 0.1%,每個月的不可用時間會增加 43 分鐘之多。
一邊是硬件升級已經到頂,單機數據庫也優化到了極限,再不做數據庫拆分,平臺可能隨時癱瘓。一邊是沒有好的策略,可能拆分數據庫后,每個月都有宕機的風險,同時性能也可能會出現劇烈的下降。
我被逼入了死角。
三、
這種痛苦的糾結折磨了我大概一周,直到我看到了 CAP 定理。當 CAP 定理說分布式系統在分區容錯的時候,只能一致性和可用性二選一時,我高興的蹦了起來。
原來,可用性和一致性是不能兼得的。
為何我會那么高興?因為逼我入死角的可不僅是技術上的問題了,我還承受著來自于業務方和領導的壓力。每天一上班,我就需要面對業務各方的抱怨,以及領導一輪又一輪的催促。
有了 CAP 定理的支持,我知道我最終是要面臨選擇的。既然在這個世界上做分布式架構的所有人都要面臨選擇,那我又怎么可能獨善其身呢?
在對單機數據庫引發的各種問題做了一次徹底的各種歸因以后,我下了決心:
一定要搞定拆分數據庫并給出良好方案。
只是,2PC 這個攔路虎,它成為了我的大敵。通過 CAP 定理,我非常肯定,只要我選了 2PC 方案,可用性就一定會出現嚴重的問題,這個方案也肯定不可能拿出來丟人現眼的。
我唯一的方向就是去犧牲一些一致性,往可用性方向走。可是,怎么走呢?
也許是老天眷顧,也許是大家都承受著和我一樣夜不能寐的壓力,很快,BASE 理論在國內傳開了。
BASE 理論讓我知道了,這個世上能排到前幾名的技術大公司也一樣會出問題,也一樣會對這些問題進行妥協。而且 BASE 理論的思想讓我的思路一下子就打開了,苦思而不得的問題開始有了頭緒。
我要開始著手制定技術方案了。
四、
BASE 思想中的 BA(Basically Available)基本可用,是鼓勵通過預先的架構設計或者前期規劃,盡量在分布式的系統中,把以前可能影響全平臺的嚴重問題,變成只會影響平臺中的一部分數據或者功能的非嚴重問題。
有了這個思想之后,我就對廣告平臺中的很多重要的數據表進行了拆分,并將這些表的數據分散到了不同的數據庫中。
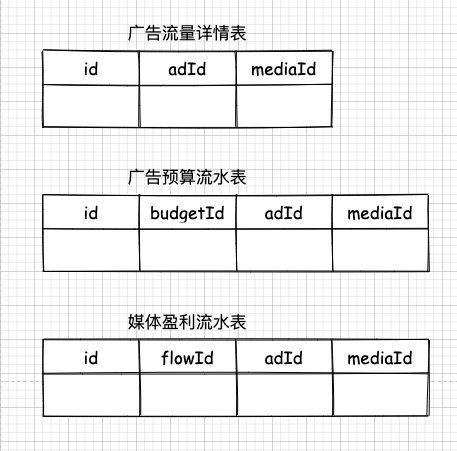
比如,有個廣告流量詳情表,每當用戶點擊廣告或者廣告展示出來的時候,為了保證不丟失,這些數據都是實時插入到這個表里的。
我對這張表是怎么切分的呢?
當有人點擊廣告了,他的點擊記錄會被傳到我的應用層,然后我會在應用層根據廣告 ID 做哈希,再根據哈希結果的不同,分別存到不同的數據庫中去。
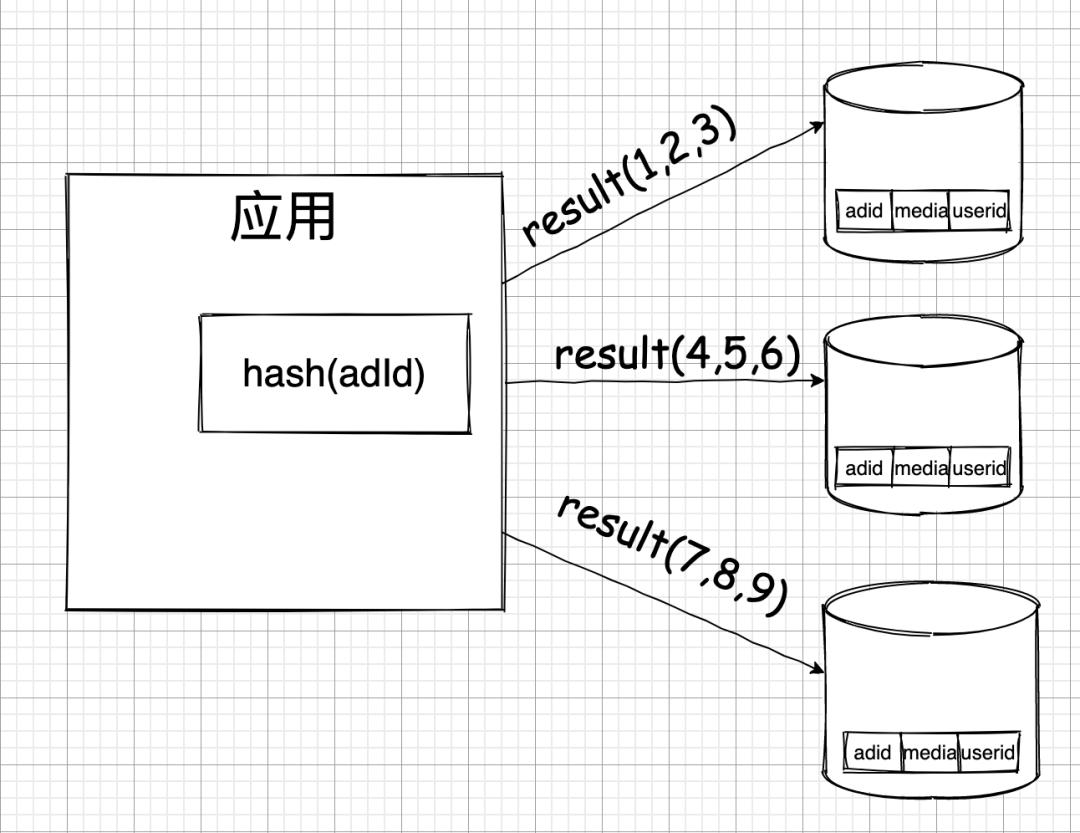
假如這三個數據庫中的一個出現了問題,則只會有三分之一的數據受到影響。這就實現了 BASE 理論中的 BA——基本可用了。基本可用其實也真的就是表達的這么一回事:
通過一些架構設計,即使平臺中某部分組件出現了問題,也不會導致整個平臺不可用。
好了,既然采取了數據庫拆分的策略,又根據 BASE 理論中的 BA 思想拆分了一些重要的表,那么,到了現在,可能也無從后悔,只能繼續沿著 BASE 這條路,一條路走到黑了。
五、
接下來,需要著手解決性能問題了。2PC 方案……算了……它瘋狂的一致性性格會要了我的狗命的。
那么極端點,我們不搞事務可不可以呢?
還用前面說的那套廣告平臺舉例。
當時,從業務上,要求廣告的訪問數據都要保證及時入庫不能丟,因為丟了就可能造成計費的損失,而這些損失全是錢。所以,每當用戶點擊廣告或者廣告展示出來的時候,為了保證不丟失,這些數據都是實時入庫的。
又根據業務需求,當廣告流量入庫時,還需要往廣告預算表和媒體流水表里同時根據這筆流量進行記賬,以供后續財務計算。
如果完全不考慮事務,則拆分庫后,操作可能會是這個樣子。
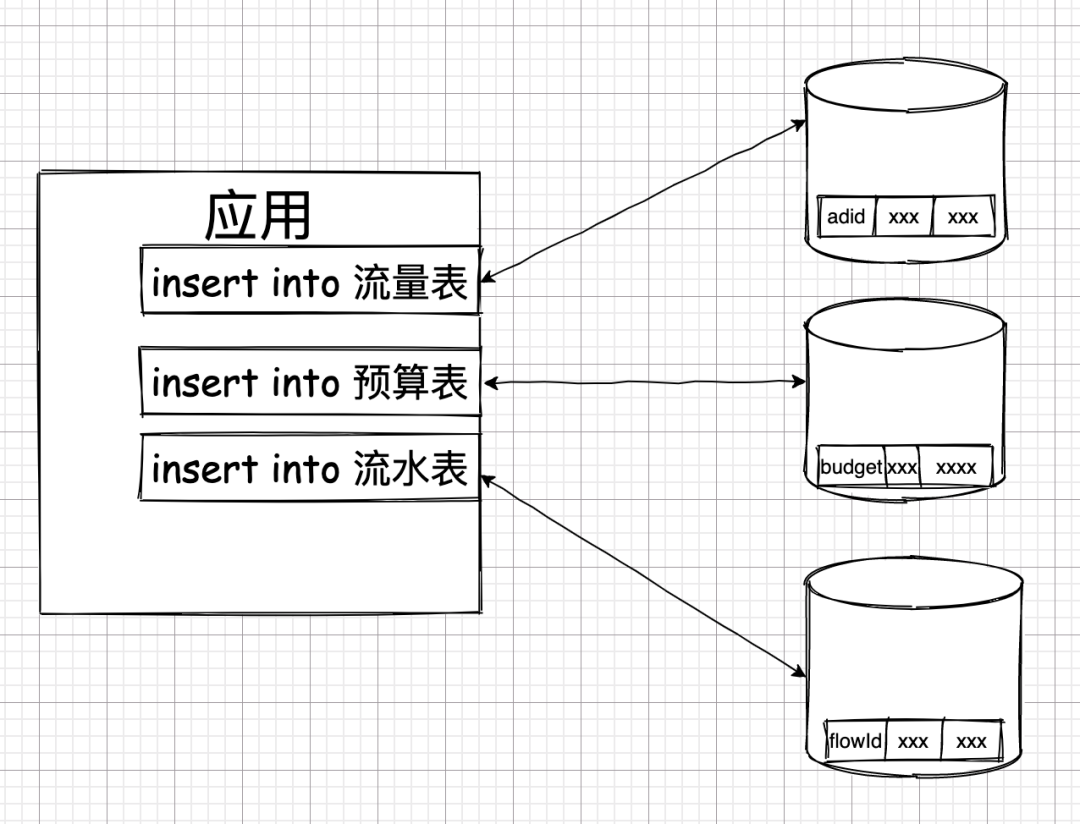
這三個操作可能會并行發往不同的數據庫執行。由于三個操作之間沒有事務的約束,所以,一個操作出問題了,另外的操作并不會受到影響。
而這卻也引發了另外一個問題,數據狀態不一致。
如果在上面的業務中,插入廣告流量表的操作失敗了,但其余兩張表插入成功了,業務就會面臨一個很尷尬的情況:他們算出的財務報表沒有依據。財務流水中找不到產生了這筆流水的依據。
而這種不一致的狀態由于已經被持久化到了數據庫中,就會導致這種不一致的狀態永久存在了數據庫中。這業務能接受嗎?但凡有點職業精神的程序員能接受嗎?
給大家分享下我的復習的面試資料
這些面試全部出自大廠面試真題和面試合集當中,小編已經為大家整理完畢(PDF版)
資料獲取方式:戳這里前往我的騰訊文檔免費下載
- 第一部分:Java基礎-中級-高級

- 第二部分:開源框架(SSM:Spring+SpringMVC+MyBatis)

- 第三部分:性能調優(JVM+MySQL+Tomcat)

- 第四部分:分布式(限流:ZK+Nginx;緩存:Redis+MongoDB+Memcached;通訊:MQ+kafka)
- 第五部分:微服務(SpringBoot+SpringCloud+Dubbo)

- 第六部分:其他:并發編程+設計模式+數據結構與算法+網絡

進階學習筆記pdf
都已整理好,需免費下載點擊這里即可
- Java架構進階之架構筑基篇(Java基礎+并發編程+JVM+MySQL+Tomcat+網絡+數據結構與算法)
- Java架構進階之開源框架篇(設計模式+Spring+SpringMVC+MyBatis)
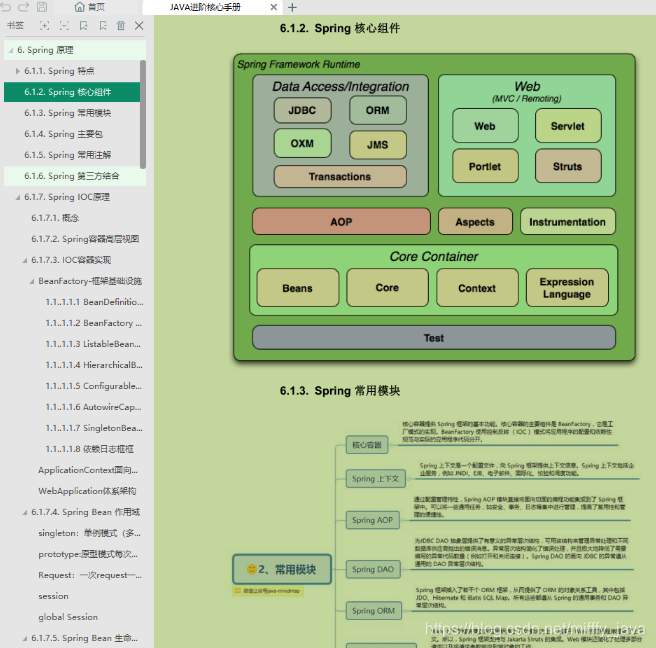
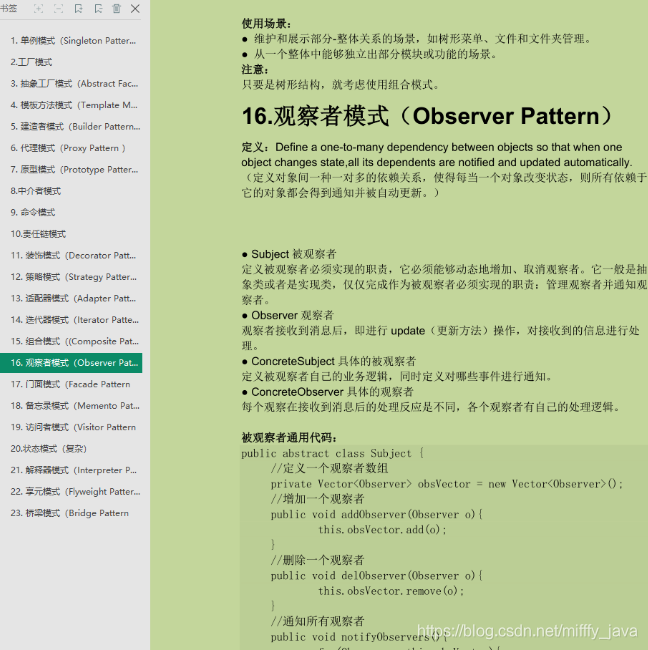
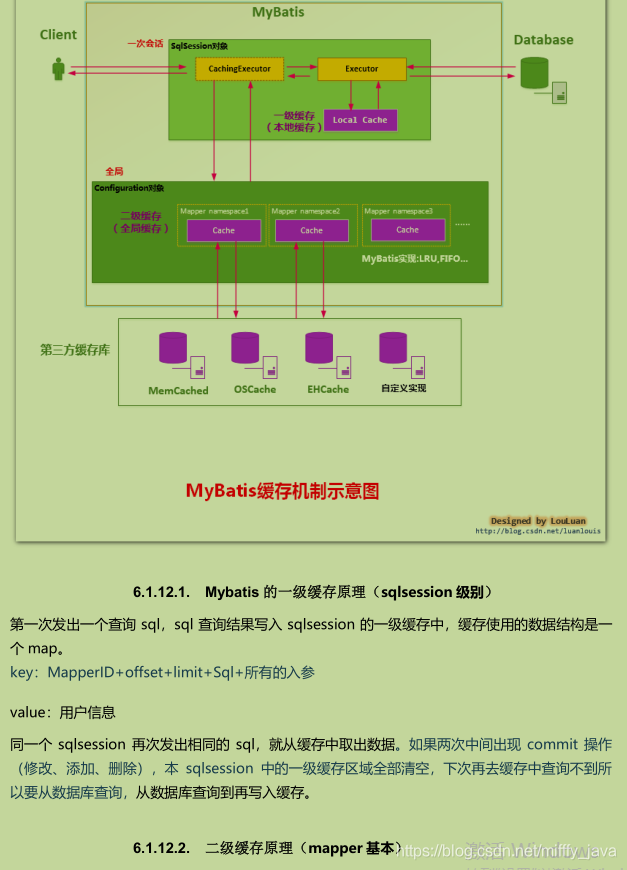
- Java架構進階之分布式架構篇 (限流(ZK/Nginx)+緩存(Redis/MongoDB/Memcached)+通訊(MQ/kafka))
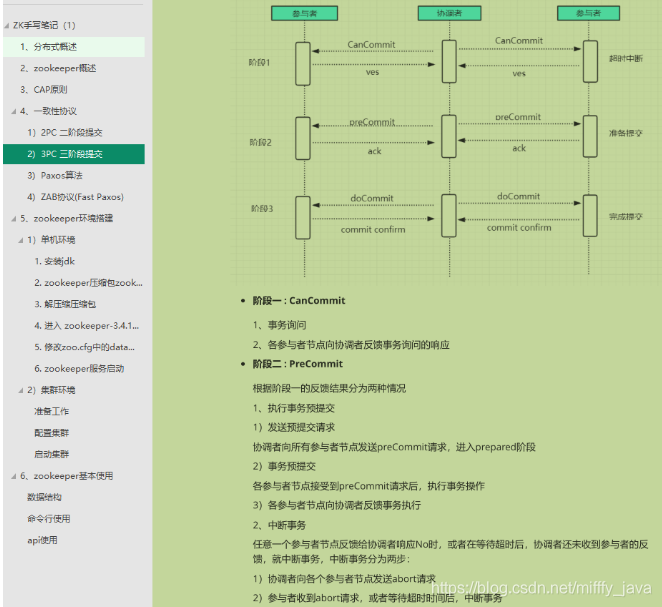
- Java架構進階之微服務架構篇(RPC+SpringBoot+SpringCloud+Dubbo+K8s)
647883)]
[外鏈圖片轉存中…(img-YgbLqlyf-1622454647884)]
- Java架構進階之微服務架構篇(RPC+SpringBoot+SpringCloud+Dubbo+K8s)
[外鏈圖片轉存中…(img-zhclYh1U-1622454647885)]
[外鏈圖片轉存中…(img-P3ZBq2h0-1622454647886)]
![[學習之道] 修福不修慧,大象披瓔珞; 修慧不修福,羅漢托空缽 (學習寫程序,只靠補習上課嗎?)...](http://pic.xiahunao.cn/[學習之道] 修福不修慧,大象披瓔珞; 修慧不修福,羅漢托空缽 (學習寫程序,只靠補習上課嗎?)...)










![[New Portal]Windows Azure Web Site (4) Web Site Gallery](http://pic.xiahunao.cn/[New Portal]Windows Azure Web Site (4) Web Site Gallery)







