什么是自旋鎖和互斥鎖?
由于CLH鎖是一種自旋鎖,那么我們先來看看自旋鎖是什么?
自旋鎖說白了也是一種互斥鎖,只不過沒有搶到鎖的線程會一直自旋等待鎖的釋放,處于busy-waiting的狀態,此時等待鎖的線程不會進入休眠狀態,而是一直忙等待浪費CPU周期。因此自旋鎖適用于鎖占用時間短的場合。
這里談到了自旋鎖,那么我們也順便說下互斥鎖。這里的互斥鎖說的是傳統意義的互斥鎖,就是多個線程并發競爭鎖的時候,沒有搶到鎖的線程會進入休眠狀態即sleep-waiting,當鎖被釋放的時候,處于休眠狀態的一個線程會再次獲取到鎖。缺點就是這一些列過程需要線程切換,需要執行很多CPU指令,同樣需要時間。如果CPU執行線程切換的時間比鎖占用的時間還長,那么可能還不如使用自旋鎖。因此互斥鎖適用于鎖占用時間長的場合。
1、為什么要使用消息隊列?
分析:一個用消息隊列的人,不知道為啥用,有點尷尬。沒有復習這點,很容易被問蒙,然后就開始胡扯了。
回答:這個問題,咱只答三個最主要的應用場景(不可否認還有其他的,但是只答三個主要的),即以下六個字:解耦、異步、削峰
(1)解耦
傳統模式:
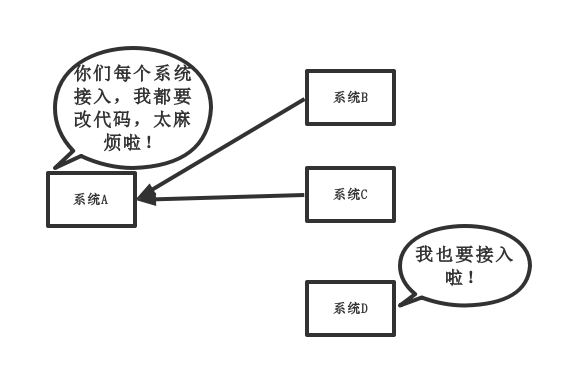
傳統模式的缺點:
- 系統間耦合性太強,如上圖所示,系統A在代碼中直接調用系統B和系統C的代碼,如果將來D系統接入,系統A還需要修改代碼,過于麻煩!
中間件模式:
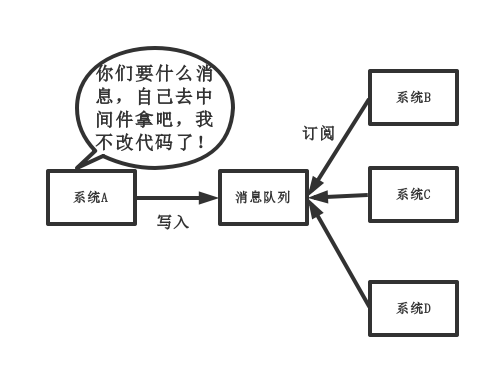
中間件模式的的優點:
- 將消息寫入消息隊列,需要消息的系統自己從消息隊列中訂閱,從而系統A不需要做任何修改。
(2)異步
傳統模式:

傳統模式的缺點:
- 一些非必要的業務邏輯以同步的方式運行,太耗費時間。
中間件模式:
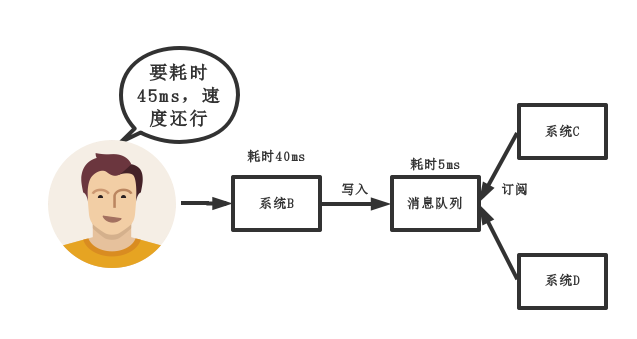
中間件模式的的優點:
- 將消息寫入消息隊列,非必要的業務邏輯以異步的方式運行,加快響應速度
(3)削峰
傳統模式
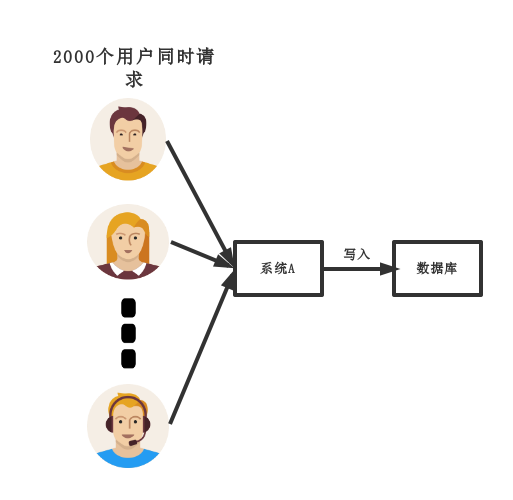
傳統模式的缺點:
- 并發量大的時候,所有的請求直接懟到數據庫,造成數據庫連接異常
中間件模式:
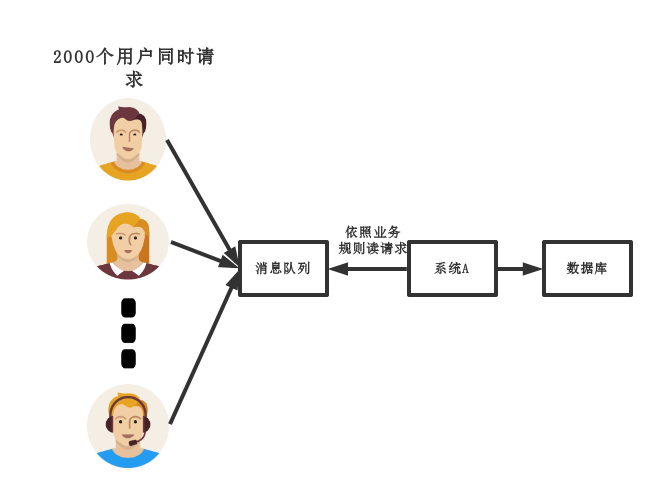
中間件模式的的優點:
- 系統A慢慢的按照數據庫能處理的并發量,從消息隊列中慢慢拉取消息。在生產中,這個短暫的高峰期積壓是允許的。
2、使用了消息隊列會有什么缺點?
分析:一個使用了MQ的項目,如果連這個問題都沒有考慮過,就把MQ引進去了,那就給自己的項目帶來了風險。
我們引入一個技術,要對這個技術的弊端有充分的認識,才能做好預防。要記住,不要給公司挖坑!
回答:回答也很容易,從以下兩個個角度來答
-
系統可用性降低:
你想啊,本來其他系統只要運行好好的,那你的系統就是正常的。
現在你非要加個消息隊列進去,那消息隊列掛了,你的系統不是呵呵了。因此,系統可用性降低
-
系統復雜性增加:
要多考慮很多方面的問題,比如一致性問題、如何保證消息不被重復消費,如何保證保證消息可靠傳輸。
因此,需要考慮的東西更多,系統復雜性增大。
但是,我們該用還是要用的。
3、消息隊列如何選型?
先說一下,博主只會ActiveMQ,RabbitMQ,RocketMQ,Kafka,對什么ZeroMQ等其他MQ沒啥理解,因此只能基于這四種MQ給出回答。
分析:既然在項目中用了MQ,肯定事先要對業界流行的MQ進行調研,如果連每種MQ的優缺點都沒了解清楚,就拍腦袋依據喜好,用了某種MQ,還是給項目挖坑。
如果面試官問:"你為什么用這種MQ?。"你直接回答"領導決定的。"這種回答就很LOW了。
還是那句話,不要給公司挖坑。
我們可以看出,RabbitMQ版本發布比ActiveMq頻繁很多。至于RocketMQ和kafka就不帶大家看了,總之也比ActiveMQ活躍的多。詳情,可自行查閱。
再來一個性能對比表
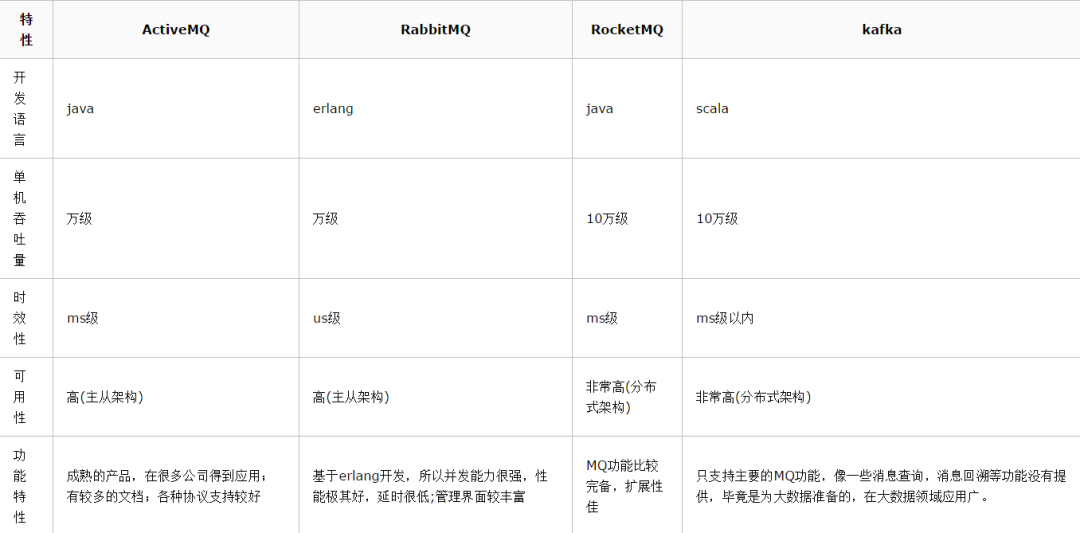
綜合上面的材料得出以下兩點:
(1)中小型軟件公司,建議選RabbitMQ.
一方面,erlang語言天生具備高并發的特性,而且他的管理界面用起來十分方便。
正所謂,成也蕭何,敗也蕭何!他的弊端也在這里,雖然RabbitMQ是開源的,然而國內有幾個能定制化開發erlang的程序員呢?
所幸,RabbitMQ的社區十分活躍,可以解決開發過程中遇到的bug,這點對于中小型公司來說十分重要。
不考慮rocketmq和kafka的原因是,一方面中小型軟件公司不如互聯網公司,數據量沒那么大,選消息中間件,應首選功能比較完備的,所以kafka排除。
不考慮rocketmq的原因是,rocketmq是阿里出品,如果阿里放棄維護rocketmq,中小型公司一般抽不出人來進行rocketmq的定制化開發,因此不推薦。
(2)大型軟件公司,根據具體使用在rocketMq和kafka之間二選一
一方面,大型軟件公司,具備足夠的資金搭建分布式環境,也具備足夠大的數據量。
針對rocketMQ,大型軟件公司也可以抽出人手對rocketMQ進行定制化開發,畢竟國內有能力改JAVA源碼的人,還是相當多的。
至于kafka,根據業務場景選擇,如果有日志采集功能,肯定是首選kafka了。具體該選哪個,看使用場景。
4、如何保證消息隊列是高可用的?
分析:在第二點說過了,引入消息隊列后,系統的可用性下降。在生產中,沒人使用單機模式的消息隊列。
因此,作為一個合格的程序員,應該對消息隊列的高可用有很深刻的了解。
如果面試的時候,面試官問,你們的消息中間件如何保證高可用的?
如果你的回答只是表明自己只會訂閱和發布消息,面試官就會懷疑你是不是只是自己搭著玩,壓根沒在生產用過。
因此,請做一個愛思考,會思考,懂思考的程序員。
回答:這問題,其實要對消息隊列的集群模式要有深刻了解,才好回答。
以rcoketMQ為例,他的集群就有多master 模式、多master多slave異步復制模式、多 master多slave同步雙寫模式。
多master多slave模式部署架構圖(網上找的,偷個懶,懶得畫):

其實博主第一眼看到這個圖,就覺得和kafka好像,只是NameServer集群,在kafka中是用zookeeper代替,都是用來保存和發現master和slave用的。
通信過程如下:
Producer 與 NameServer集群中的其中一個節點(隨機選擇)建立長連接,定期從 NameServer 獲取 Topic 路由信息,并向提供 Topic 服務的 Broker Master 建立長連接,且定時向 Broker 發送心跳。
Producer 只能將消息發送到 Broker master,但是 Consumer 則不一樣,它同時和提供 Topic 服務的 Master 和 Slave建立長連接,既可以從 Broker Master 訂閱消息,也可以從 Broker Slave 訂閱消息。
那么kafka呢,為了對比說明直接上kafka的拓補架構圖(也是找的,懶得畫)
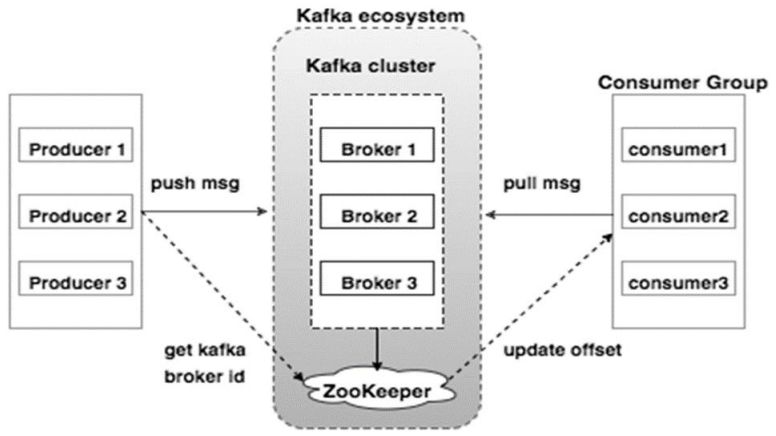
如上圖所示,一個典型的Kafka集群中包含若干Producer(可以是web前端產生的Page View,或者是服務器日志,系統CPU、Memory等),若干broker(Kafka支持水平擴展,一般broker數量越多,集群吞吐率越高),若干Consumer Group,以及一個Zookeeper集群。
Kafka通過Zookeeper管理集群配置,選舉leader,以及在Consumer Group發生變化時進行rebalance。
Producer使用push模式將消息發布到broker,Consumer使用pull模式從broker訂閱并消費消息。
至于rabbitMQ,也有普通集群和鏡像集群模式,自行去了解,比較簡單,兩小時即懂。
要求,在回答高可用的問題時,應該能邏輯清晰的畫出自己的MQ集群架構或清晰的敘述出來。
5、如何保證消息不被重復消費?
分析:這個問題其實換一種問法就是,如何保證消息隊列的冪等性?
這個問題可以認為是消息隊列領域的基本問題。換句話來說,是在考察你的設計能力,這個問題的回答可以根據具體的業務場景來答,沒有固定的答案。
回答:先來說一下為什么會造成重復消費?
其實無論是那種消息隊列,造成重復消費原因其實都是類似的。
正常情況下,消費者在消費消息時候,消費完畢后,會發送一個確認信息給消息隊列,消息隊列就知道該消息被消費了,就會將該消息從消息隊列中刪除。只是不同的消息隊列發送的確認信息形式不同
例如RabbitMQ是發送一個ACK確認消息,RocketMQ是返回一個CONSUME_SUCCESS成功標志,kafka實際上有個offset的概念
簡單說一下(如果還不懂,出門找一個kafka入門到精通教程),就是每一個消息都有一個offset,kafka消費過消息后,需要提交offset,讓消息隊列知道自己已經消費過了。
那造成重復消費的原因?
就是因為網絡傳輸等等故障,確認信息沒有傳送到消息隊列,導致消息隊列不知道自己已經消費過該消息了,再次將該消息分發給其他的消費者。
如何解決?這個問題針對業務場景來答分以下幾點
(1)比如,你拿到這個消息做數據庫的insert操作。
那就容易了,給這個消息做一個唯一主鍵,那么就算出現重復消費的情況,就會導致主鍵沖突,避免數據庫出現臟數據。
(2)再比如,你拿到這個消息做redis的set的操作
那就容易了,不用解決。因為你無論set幾次結果都是一樣的,set操作本來就算冪等操作。
(3)如果上面兩種情況還不行,上大招。
準備一個第三方介質,來做消費記錄。以redis為例,給消息分配一個全局id,只要消費過該消息,將以K-V形式寫入redis。那消費者開始消費前,先去redis中查詢有沒消費記錄即可。
6、如何保證消費的可靠性傳輸?
分析:我們在使用消息隊列的過程中,應該做到消息不能多消費,也不能少消費。如果無法做到可靠性傳輸,可能給公司帶來千萬級別的財產損失。
同樣的,如果可靠性傳輸在使用過程中,沒有考慮到,這不是給公司挖坑么,你可以拍拍屁股走了,公司損失的錢,誰承擔。
還是那句話,認真對待每一個項目,不要給公司挖坑
回答:其實這個可靠性傳輸,每種MQ都要從三個角度來分析:生產者弄丟數據、消息隊列弄丟數據、消費者弄丟數據
RabbitMQ
(1)生產者丟數據
從生產者弄丟數據這個角度來看,RabbitMQ提供transaction和confirm模式來確保生產者不丟消息。
transaction機制就是說,發送消息前,開啟事物(channel.txSelect()),然后發送消息,如果發送過程中出現什么異常,事物就會回滾(channel.txRollback()),如果發送成功則提交事物(channel.txCommit())。
然而缺點就是吞吐量下降了。因此,按照博主的經驗,生產上用confirm模式的居多。
一旦channel進入confirm模式,所有在該信道上面發布的消息都將會被指派一個唯一的ID(從1開始)
一旦消息被投遞到所有匹配的隊列之后,rabbitMQ就會發送一個Ack給生產者(包含消息的唯一ID)
這就使得生產者知道消息已經正確到達目的隊列了.如果rabiitMQ沒能處理該消息,則會發送一個Nack消息給你,你可以進行重試操作。
處理Ack和Nack的代碼如下所示(說好不上代碼的,偷偷上了):
channel.addConfirmListener(new ConfirmListener() {@Overridepublic void handleNack(long deliveryTag, boolean multiple) throws IOException {System.out.println("nack: deliveryTag = "+deliveryTag+" multiple: "+multiple);}@Overridepublic void handleAck(long deliveryTag, boolean multiple) throws IOException {System.out.println("ack: deliveryTag = "+deliveryTag+" multiple: "+multiple);}
});
(2)消息隊列丟數據
處理消息隊列丟數據的情況,一般是開啟持久化磁盤的配置。
這個持久化配置可以和confirm機制配合使用,你可以在消息持久化磁盤后,再給生產者發送一個Ack信號。
這樣,如果消息持久化磁盤之前,rabbitMQ陣亡了,那么生產者收不到Ack信號,生產者會自動重發。
那么如何持久化呢,這里順便說一下吧,其實也很容易,就下面兩步
1、將queue的持久化標識durable設置為true,則代表是一個持久的隊列
2、發送消息的時候將deliveryMode=2
這樣設置以后,rabbitMQ就算掛了,重啟后也能恢復數據
(3)消費者丟數據
消費者丟數據一般是因為采用了自動確認消息模式。
這種模式下,消費者會自動確認收到信息。這時rahbitMQ會立即將消息刪除,這種情況下如果消費者出現異常而沒能處理該消息,就會丟失該消息。
至于解決方案,采用手動確認消息即可。
kafka
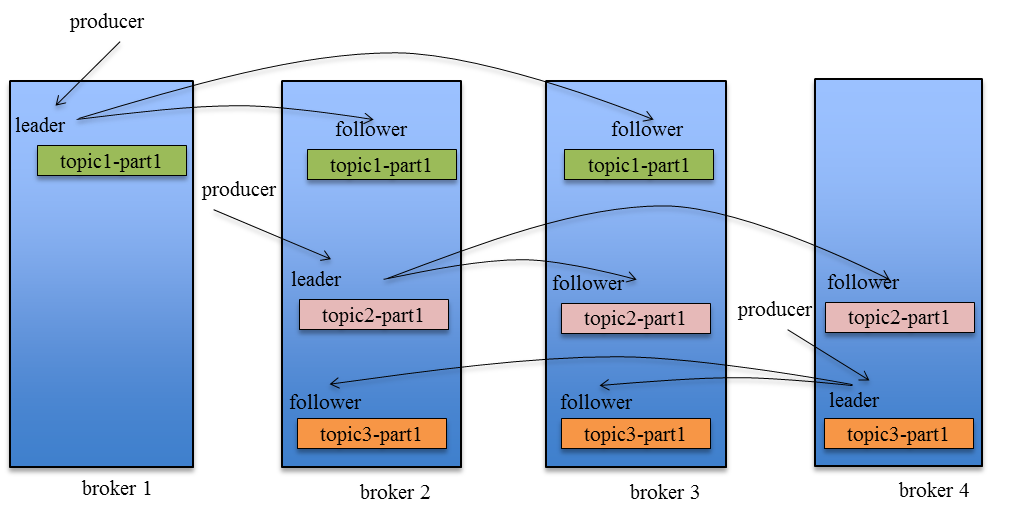
Producer在發布消息到某個Partition時,先通過ZooKeeper找到該Partition的Leader
然后無論該Topic的Replication Factor為多少(也即該Partition有多少個Replica),Producer只將該消息發送到該Partition的Leader。
Leader會將該消息寫入其本地Log。每個Follower都從Leader中pull數據。
針對上述情況,得出如下分析
(1)生產者丟數據
在kafka生產中,基本都有一個leader和多個follwer。follwer會去同步leader的信息。
因此,為了避免生產者丟數據,做如下兩點配置
-
第一個配置要在producer端設置acks=all。這個配置保證了,follwer同步完成后,才認為消息發送成功。
-
在producer端設置retries=MAX,一旦寫入失敗,這無限重試
(2)消息隊列丟數據
針對消息隊列丟數據的情況,無外乎就是,數據還沒同步,leader就掛了,這時zookpeer會將其他的follwer切換為leader,那數據就丟失了。
針對這種情況,應該做兩個配置。
-
replication.factor參數,這個值必須大于1,即要求每個partition必須有至少2個副本
-
min.insync.replicas參數,這個值必須大于1,這個是要求一個leader至少感知到有至少一個follower還跟自己保持聯系
這兩個配置加上上面生產者的配置聯合起來用,基本可確保kafka不丟數據
(3)消費者丟數據
這種情況一般是自動提交了offset,然后你處理程序過程中掛了。kafka以為你處理好了。
再強調一次offset是干嘛的
offset:指的是kafka的topic中的每個消費組消費的下標。
簡單的來說就是一條消息對應一個offset下標,每次消費數據的時候如果提交offset,那么下次消費就會從提交的offset加一那里開始消費。
比如一個topic中有100條數據,我消費了50條并且提交了,那么此時的kafka服務端記錄提交的offset就是49(offset從0開始),那么下次消費的時候offset就從50開始消費。
解決方案也很簡單,改成手動提交即可。
ActiveMQ和RocketMQ
大家自行查閱吧
7、如何保證消息的順序性?
分析:其實并非所有的公司都有這種業務需求,但是還是對這個問題要有所復習。
回答:針對這個問題,通過某種算法,將需要保持先后順序的消息放到同一個消息隊列中(kafka中就是partition,rabbitMq中就是queue)。然后只用一個消費者去消費該隊列。
有的人會問:那如果為了吞吐量,有多個消費者去消費怎么辦?
這個問題,沒有固定回答的套路。比如我們有一個微博的操作,發微博、寫評論、刪除微博,這三個異步操作。如果是這樣一個業務場景,那只要重試就行。
比如你一個消費者先執行了寫評論的操作,但是這時候,微博都還沒發,寫評論一定是失敗的,等一段時間。等另一個消費者,先執行寫評論的操作后,再執行,就可以成功。
總之,針對這個問題,我的觀點是保證入隊有序就行,出隊以后的順序交給消費者自己去保證,沒有固定套路。
最后
小編利用空余時間整理了一份《MySQL性能調優手冊》,初衷也很簡單,就是希望能夠幫助到大家,減輕大家的負擔和節省時間。
關于這個,給大家看一份學習大綱(PDF)文件,每一個分支里面會有詳細的介紹。
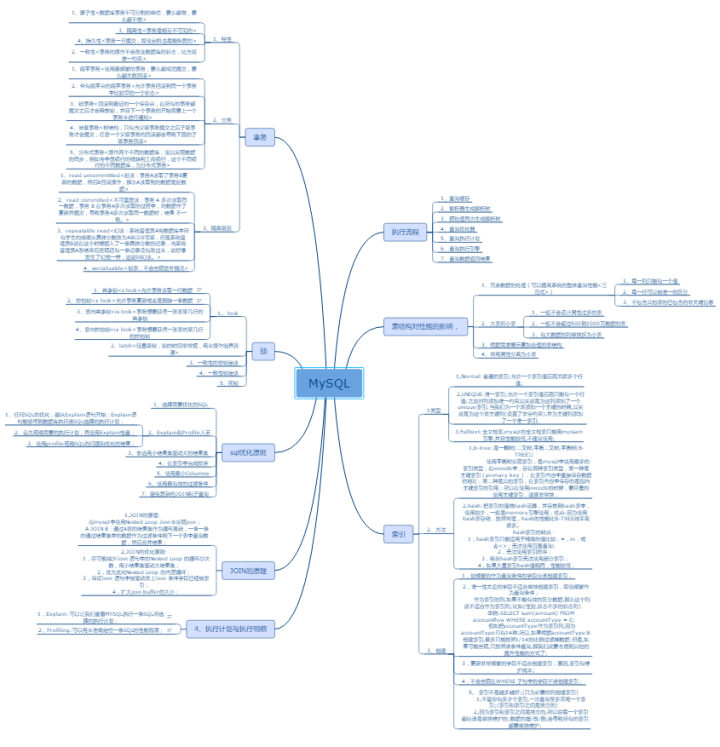
這里都是以圖片形式展示介紹,如要下載原文件以及更多的性能調優筆記(MySQL+Tomcat+JVM)可以直接【點擊 “性能調優”】免費下載!
就可以成功。
總之,針對這個問題,我的觀點是保證入隊有序就行,出隊以后的順序交給消費者自己去保證,沒有固定套路。
最后
小編利用空余時間整理了一份《MySQL性能調優手冊》,初衷也很簡單,就是希望能夠幫助到大家,減輕大家的負擔和節省時間。
關于這個,給大家看一份學習大綱(PDF)文件,每一個分支里面會有詳細的介紹。
[外鏈圖片轉存中…(img-4JyE6rxr-1623850686005)]
這里都是以圖片形式展示介紹,如要下載原文件以及更多的性能調優筆記(MySQL+Tomcat+JVM)可以直接【點擊 “性能調優”】免費下載!


)





)










