
作者 | 程序員歷小冰
責編 | 林瑟
Redis 是一個開源的 key-value 存儲系統,它使用六種底層數據結構構建了包含字符串對象、列表對象、哈希對象、集合對象和有序集合對象的對象系統。?
今天我們就通過 12 張圖來全面了解一下它的數據結構和對象系統的實現原理。
01
數據結構
簡單動態字符串
Redis 使用動態字符串 SDS 來表示字符串值。下圖展示了一個值為 Redis 的 SDS結構 :
len: 表示字符串的真正長度(不包含 NULL 結束符在內)。
alloc: 表示字符串的最大容量(不包含最后多余的那個字節)。
flags: 總是占用一個字節。其中的最低 3 個 bit 用來表示 header 的類型。
buf: 字符數組
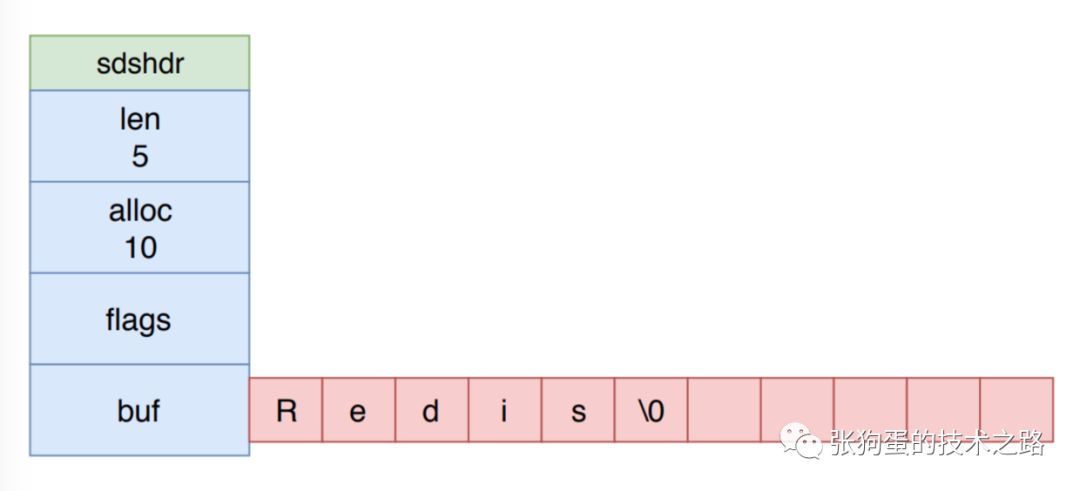
SDS 的結構可以減少修改字符串時帶來的內存重分配的次數,這依賴于內存預分配和惰性空間釋放兩大機制。
當 SDS 需要被修改,并且要對 SDS 進行空間擴展時,Redis 不僅會為 SDS 分配修改所必須要的空間,還會為 SDS 分配額外的未使用的空間。
如果修改后, SDS 的長度(也就是len屬性的值)將小于 1MB ,那么 Redis 預分配和 len 屬性相同大小的未使用空間。
如果修改后, SDS 的長度將大于 1MB ,那么 Redis 會分配 1MB 的未使用空間。
比如說,進行修改后 SDS 的 len 長度為 20 字節,小于 1MB,那么 Redis 會預先再分配 20 字節的空間, SDS 的 buf 數組的實際長度(除去最后一字節)變為 20 + 20 = 40 字節。
當 SDS 的 len 長度大于 1MB 時,則只會再多分配 1MB 的空間。
類似的,當 SDS 縮短其保存的字符串長度時,并不會立即釋放多出來的字節,而是等待之后使用。
鏈表
鏈表在 Redis 中的應用非常廣泛,比如列表對象的底層實現之一就是鏈表。除了鏈表對象外,發布和訂閱、慢查詢、監視器等功能也用到了鏈表。
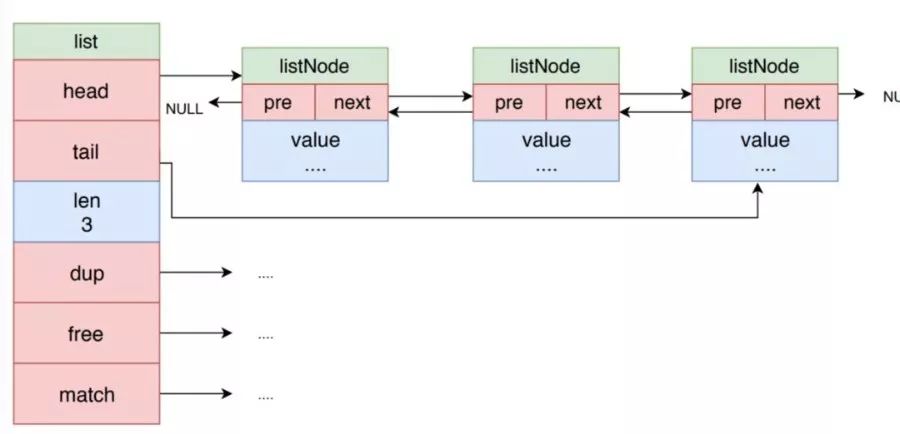
Redis 的鏈表是雙向鏈表,示意圖如上圖所示。鏈表是最為常見的數據結構,這里就不在細說。
Redis 的鏈表結構的 dup 、 free 和 match 成員屬性是用于實現多態鏈表所需的類型特定函數:
dup 函數用于復制鏈表節點所保存的值,用于深度拷貝。
free 函數用于釋放鏈表節點所保存的值。
match 函數則用于對比鏈表節點所保存的值和另一個輸入值是否相等。
字典
字典被廣泛用于實現 Redis 的各種功能,包括鍵空間和哈希對象。其示意圖如下所示。
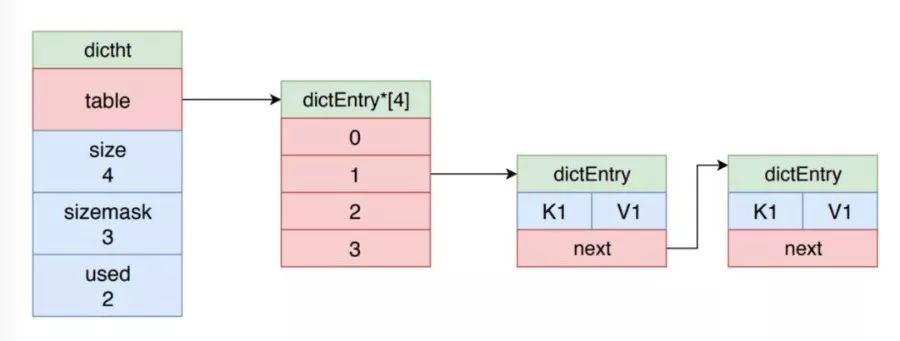
Redis 使用 MurmurHash2 算法來計算鍵的哈希值,并且使用鏈地址法來解決鍵沖突,被分配到同一個索引的多個鍵值對會連接成一個單向鏈表。
跳躍表
Redis 使用跳躍表作為有序集合對象的底層實現之一。它以有序的方式在層次化的鏈表中保存元素, 效率和平衡樹媲美 —— 查找、刪除、添加等操作都可以在對數期望時間下完成, 并且比起平衡樹來說, 跳躍表的實現要簡單直觀得多。
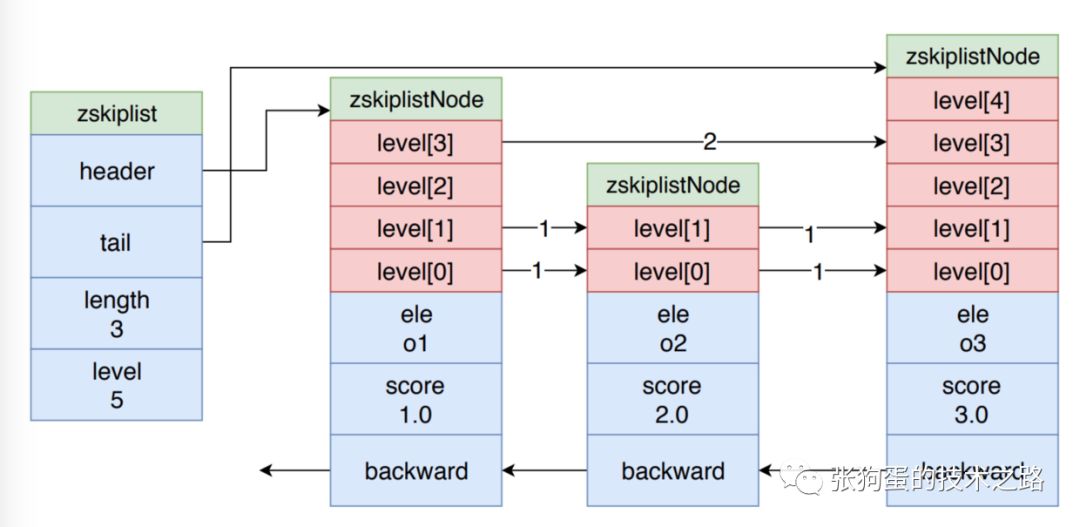
跳表的示意圖如上圖所示,這里只簡單說一下它的核心思想,并不進行詳細的解釋。
如示意圖所示,zskiplistNode 是跳躍表的節點,其 ele 是保持的元素值,score 是分值,節點按照其 score 值進行有序排列,而 level 數組就是其所謂的層次化鏈表的體現。
每個 node 的 level 數組大小都不同, level 數組中的值是指向下一個 node 的指針和 跨度值 (span),跨度值是兩個節點的 score 的差值。越高層的 level 數組值的跨度值就越大,底層的 level 數組值的跨度值越小。
level 數組就像是不同刻度的尺子。度量長度時,先用大刻度估計范圍,再不斷地用縮小刻度,進行精確逼近。
當在跳躍表中查詢一個元素值時,都先從第一個節點的最頂層的 level 開始。比如說,在上圖的跳表中查詢 o2 元素時,先從 o1 的節點開始,因為 zskiplist 的 header 指針指向它。
先從其 level[3] 開始查詢,發現其跨度是 2,o1 節點的 score 是1.0,所以加起來為 3.0,大于 o2 的 score 值2.0。所以,我們可以知道 o2 節點在 o1 和 o3 節點之間。這時,就改用小刻度的尺子了。就用level[1]的指針,順利找到 o2 節點。
整數集合
整數集合 intset 是集合對象的底層實現之一,當一個集合只包含整數值元素,并且這個集合的元素數量不多時, Redis 就會使用整數集合作為集合對象的底層實現。
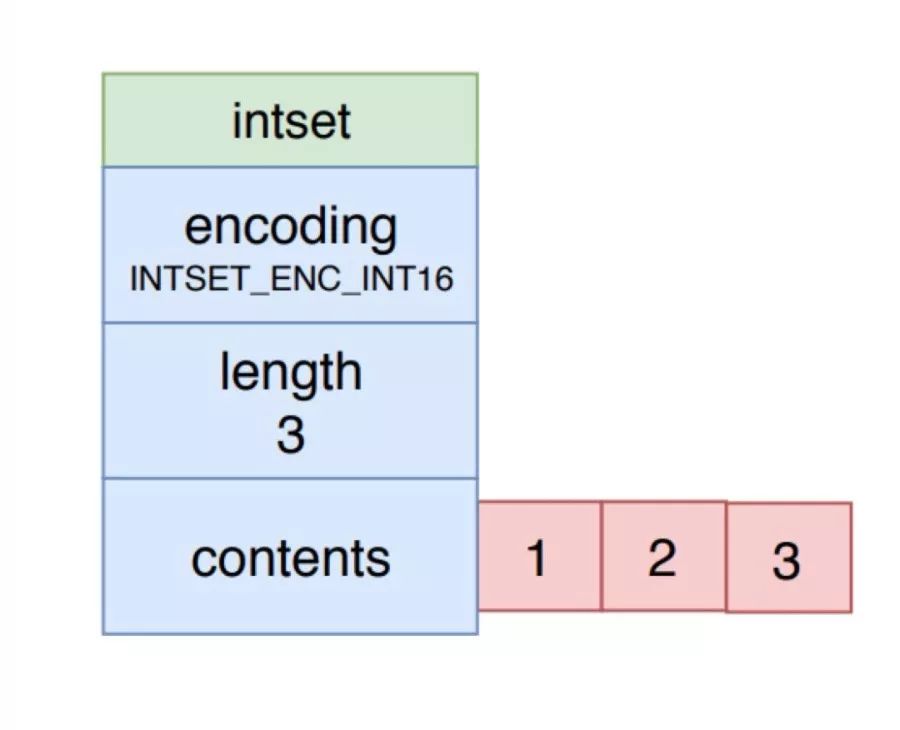
如上圖所示,整數集合的 encoding 表示它的類型,有 int16t,int32t 或者 int64_t。其每個元素都是 contents 數組的一個數組項,各個項在數組中按值的大小從小到大有序的排列,并且數組中不包含任何重復項。length 屬性就是整數集合包含的元素數量。
壓縮列表
壓縮隊列 ziplist 是列表對象和哈希對象的底層實現之一。當滿足一定條件時,列表對象和哈希對象都會以壓縮隊列為底層實現。
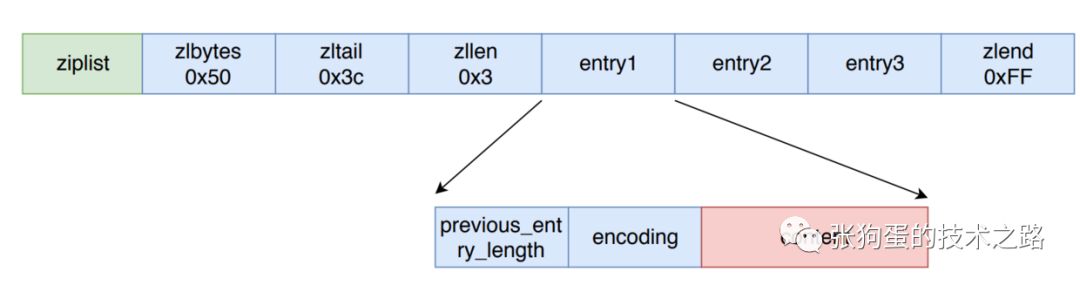
壓縮隊列是 Redis 為了節約內存而開發的,是由一系列特殊編碼的連續內存塊組成的順序型數據結構。它的屬性值有:
zlbytes : 長度為 4 字節,記錄整個壓縮數組的內存字節數。
zltail : 長度為 4 字節,記錄壓縮隊列表尾節點距離壓縮隊列的起始地址有多少字節,通過該屬性可以直接確定尾節點的地址。
zllen : 長度為 2 字節,包含的節點數。當屬性值小于 INT16_MAX時,該值就是節點總數,否則需要遍歷整個隊列才能確定總數。
zlend : 長度為 1 字節,特殊值,用于標記壓縮隊列的末端。
中間每個節點 entry 由三部分組成:
previous_entry_length : 壓縮列表中前一個節點的長度,和當前的地址進行指針運算,計算出前一個節點的起始地址。
encoding:節點保存數據的類型和長度
content :節點值,可以為一個字節數組或者整數。
02
對象系統的實現原理
上面介紹了 6 種底層數據結構,Redis 并沒有直接使用這些數據結構來實現鍵值數據庫,而是基于這些數據結構創建了一個對象系統.
這個系統包含字符串對象、列表對象、哈希對象、集合對象和有序集合這五種類型的對象,每個對象都使用到了至少一種前邊講的底層數據結構。
Redis 根據不同的使用場景和內容大小來判斷對象使用哪種數據結構,從而優化對象在不同場景下的使用效率和內存占用。
Redis 的 redisObject 結構的定義如下所示。
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; int refcount; void *ptr;} robj;
其中 type 是對象類型,包括 REDISSTRING, REDISLIST, REDISHASH, REDISSET 和 REDIS_ZSET。
encoding 是指對象使用的數據結構,全集如下。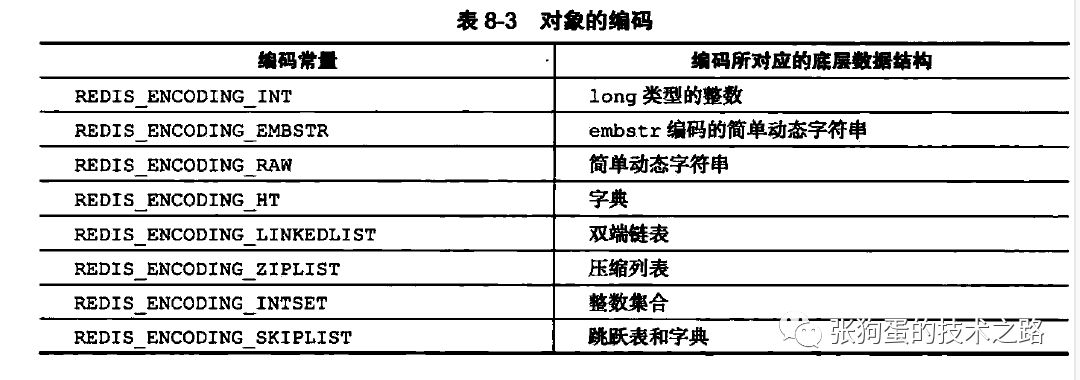
字符串對象
我們首先來看字符串對象的實現,如下圖所示。
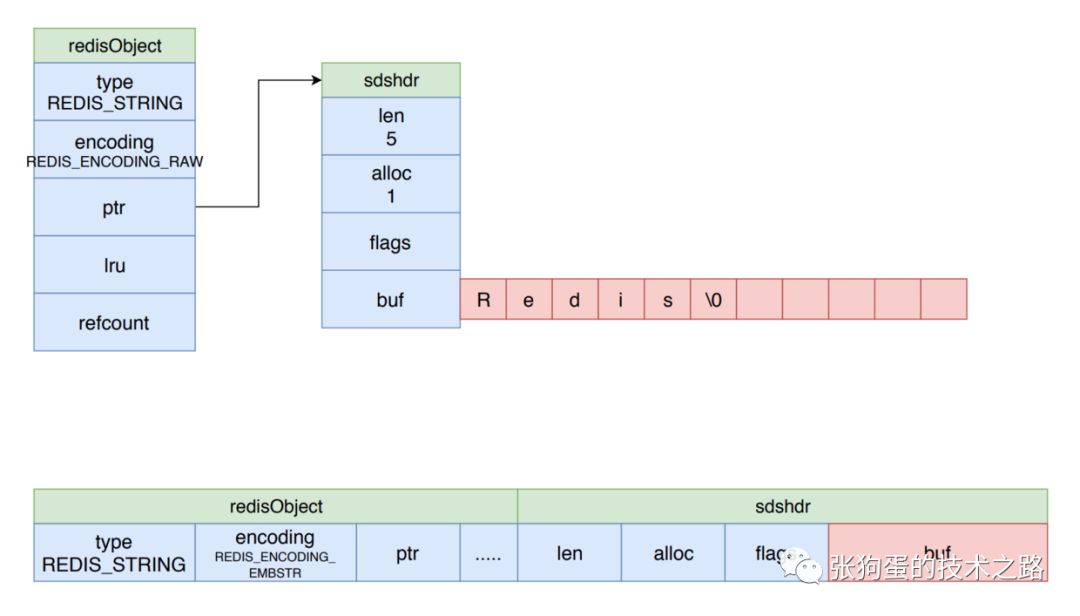
如果一個字符串對象保存的是一個字符串值,并且長度大于 32 字節,那么該字符串對象將使用 SDS 進行保存,并將對象的編碼設置為 raw,如圖的上半部分所示。
如果字符串的長度小于 32 字節,那么字符串對象將使用 embstr 編碼方式來保存。
embstr 編碼是專門用于保存短字符串的一種優化編碼方式,這個編碼的組成和 raw 編碼一致,都使用 redisObject 結構和 sdshdr 結構來保存字符串,如上圖的下半部所示。
但是 raw 編碼會調用兩次內存分配來分別創建上述兩個結構,而 embstr 則通過一次內存分配來分配一塊連續的空間,空間中一次包含兩個結構。
embstr 只需一次內存分配,而且在同一塊連續的內存中,更好的利用緩存帶來的優勢,但是 embstr 是只讀的,不能進行修改,當一個 embstr 編碼的字符串對象進行 append 操作時,redis 會現將其轉變為 raw 編碼再進行操作。
列表對象
列表對象的編碼可以是 ziplist 或 linkedlist。其示意圖如下所示。
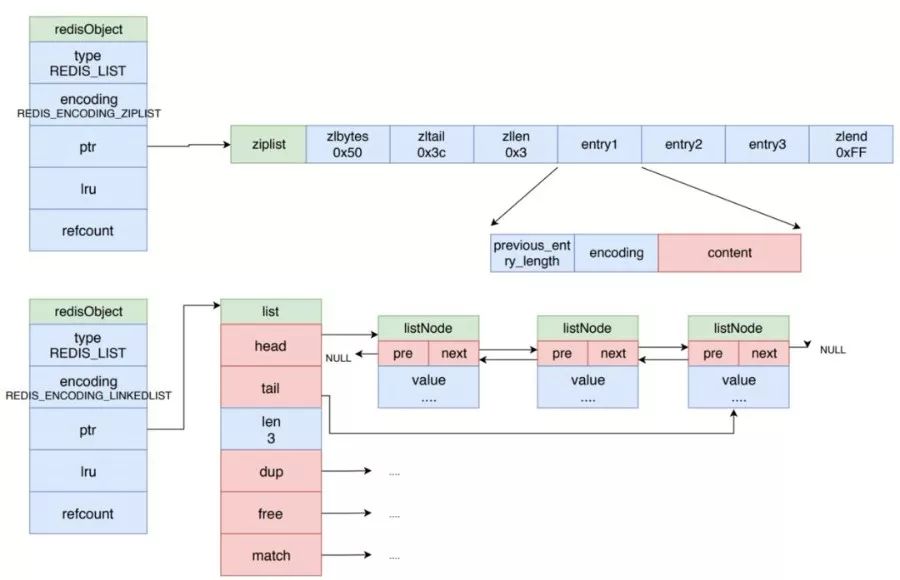
當列表對象可以同時滿足以下兩個條件時,列表對象使用 ziplist 編碼:
列表對象保存的所有字符串元素的長度都小于 64 字節。
列表對象保存的元素數量數量小于 512 個。
不能滿足這兩個條件的列表對象需要使用 linkedlist 編碼或者轉換為 linkedlist 編碼。
哈希對象
哈希對象的編碼可以使用 ziplist 或 dict。其示意圖如下所示。
當哈希對象使用壓縮隊列作為底層實現時,程序將鍵值對緊挨著插入到壓縮隊列中,保存鍵的節點在前,保存值的節點在后。如下圖的上半部分所示,該哈希有兩個鍵值對,分別是 name:Tom 和 age:25。
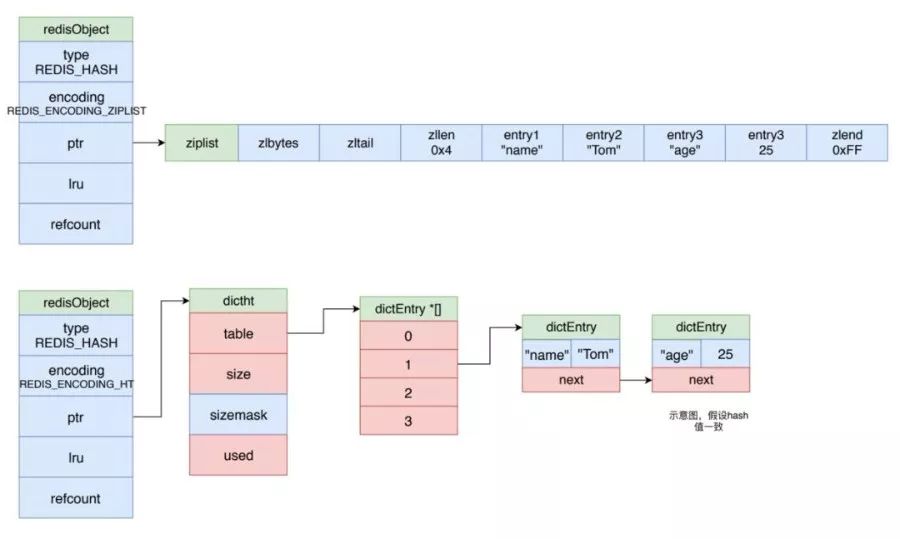
當哈希對象可以同時滿足以下兩個條件時,哈希對象使用 ziplist 編碼:
哈希對象保存的所有鍵值對的鍵和值的字符串長度都小于64字節。
哈希對象保存的鍵值對數量小于512個。
不能滿足這兩個條件的哈希對象需要使用 dict 編碼或者轉換為 dict 編碼。
集合對象
集合對象的編碼可以使用 intset 或者 dict。
intset 編碼的集合對象使用整數集合最為底層實現,所有元素都被保存在整數集合里邊。
而使用 dict 進行編碼時,字典的每一個鍵都是一個字符串對象,每個字符串對象就是一個集合元素,而字典的值全部都被設置為NULL。如下圖所示。
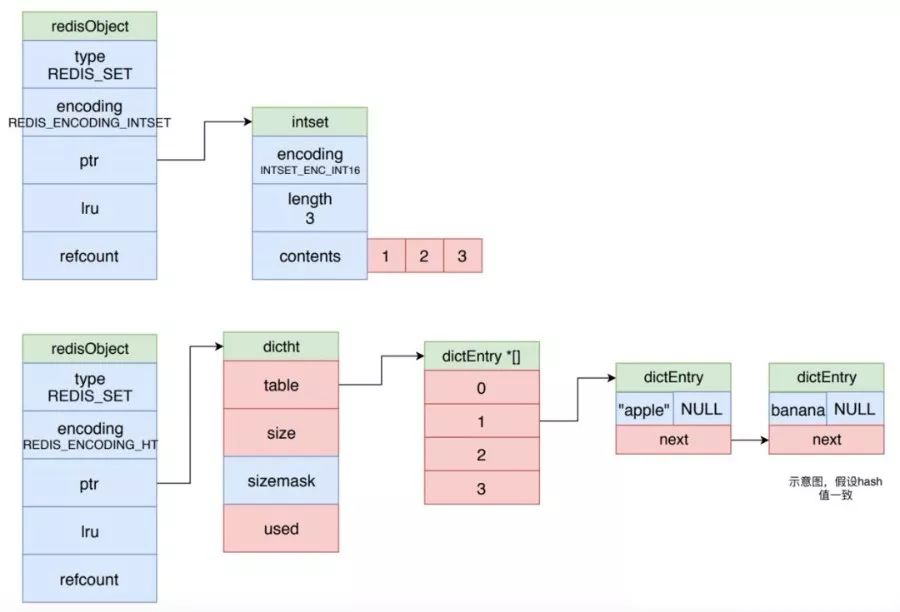
當集合對象可以同時滿足以下兩個條件時,對象使用 intset 編碼:
集合對象保存的所有元素都是整數值。
集合對象保存的元素數量不超過 512 個。
否則使用 dict 進行編碼。
有序集合對象
有序集合的編碼可以為 ziplist 或者 skiplist。
有序集合使用 ziplist 編碼時,每個集合元素使用兩個緊挨在一起的壓縮列表節點表示,前一個節點是元素的值,第二個節點是元素的分值,也就是排序比較的數值。
壓縮列表內的集合元素按照分值從小到大進行排序,如下圖上半部分所示。
有序集合使用 skiplist 編碼時使用 zset 結構作為底層實現,一個 zet 結構同時包含一個字典和一個跳躍表。
其中,跳躍表按照分值從小到大保存所有元素,每個跳躍表節點保存一個元素,其score值是元素的分值。而字典則創建一個一個從成員到分值的映射,字典的鍵是集合成員的值,字典的值是集合成員的分值。通過字典可以在O(1)復雜度查找給定成員的分值。如下圖所示。
跳躍表和字典中的集合元素值對象都是共享的,所以不會額外消耗內存。
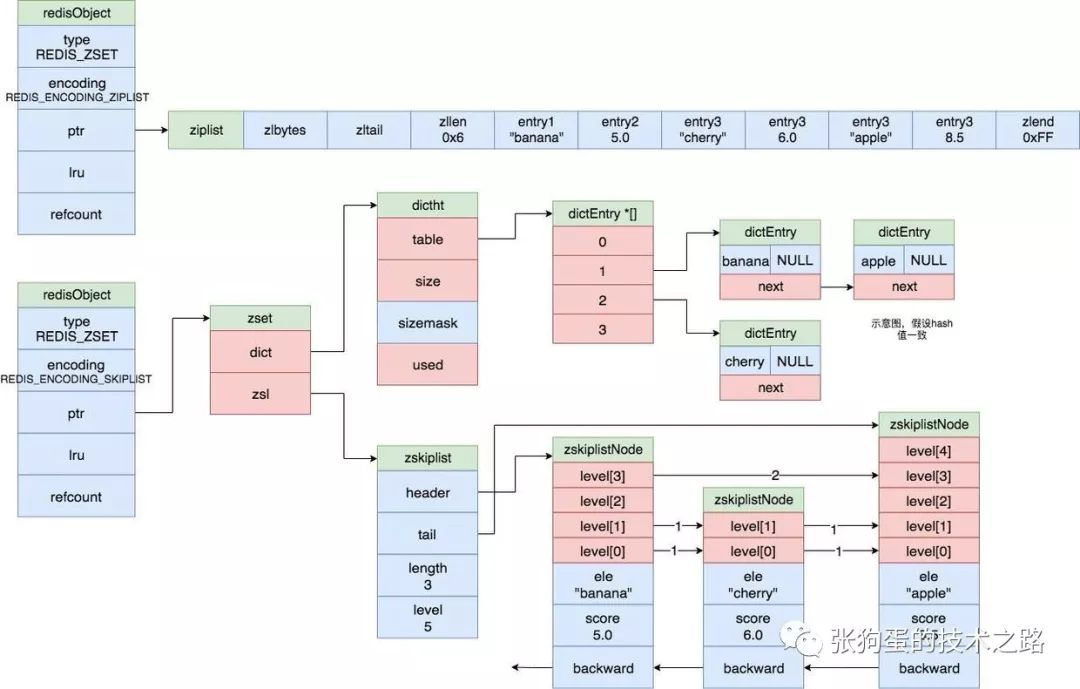
當有序集合對象可以同時滿足以下兩個條件時,對象使用 ziplist 編碼:
有序集合保存的元素數量少于128個;
有序集合保存的所有元素的長度都小于64字節。
否則使用 skiplist 編碼。
數據庫鍵空間
Redis 服務器都有多個 Redis 數據庫,每個Redis 數據都有自己獨立的鍵值空間。每個 Redis 數據庫使用 dict 保存數據庫中所有的鍵值對。
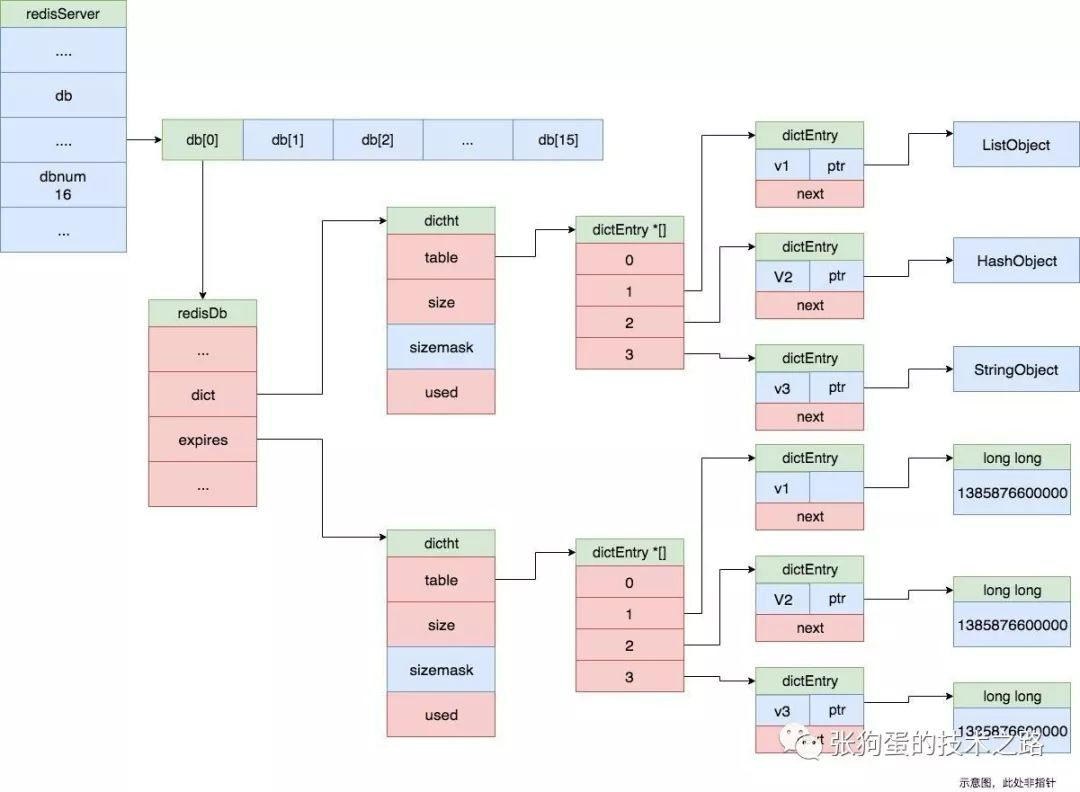
鍵空間的鍵也就是數據庫的鍵,每個鍵都是一個字符串對象,而值對象可能為字符串對象、列表對象、哈希表對象、集合對象和有序集合對象中的一種對象。
除了鍵空間,Redis 也使用 dict 結構來保存鍵的過期時間,其鍵是鍵空間中的鍵值,而值是過期時間,如上圖所示。
通過過期字典,Redis 可以直接判斷一個鍵是否過期,首先查看該鍵是否存在于過期字典,如果存在,則比較該鍵的過期時間和當前服務器時間戳,如果大于,則該鍵過期,否則未過期。
今日話題
#聊聊 Redis 的疑難雜癥#
—?完?—
程序員社群 | 連接更優秀的人







-第11篇)












