InnoDB總體結構
首先我們來看官網的一張圖(圖片來源于MySQL官網):
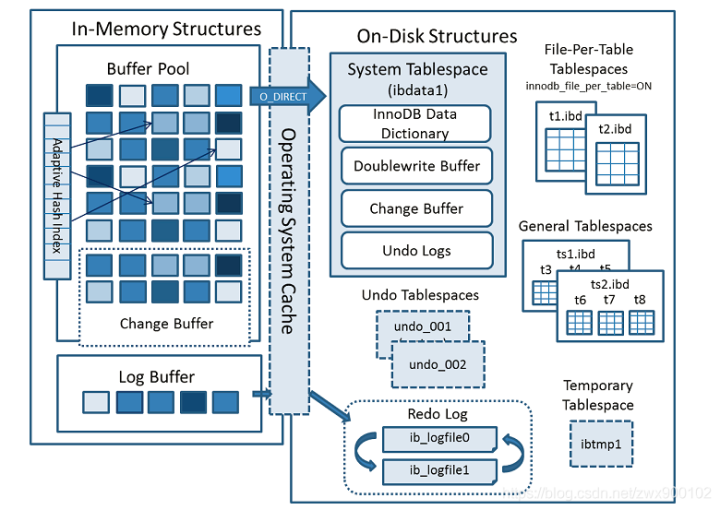
從上圖中可以看出其主要分為兩部分結構,一部分為內存中的結構(上圖左邊),一部分為磁盤中的結構(上圖右邊)
內存結構
InnoDB內存中的結構主要分為:Buffer Pool,Change Buffer和Log Buffer三部分。
Buffer Pool
Buffer Pool是InnoDB緩存表和索引的一塊主內存區域,Buffer Pool允許直接從內存中處理經常使用的數據,從而加快處理速度,帶來一定的性能提升。 但是緩存總有放滿的時候,當緩存滿了新來的數據怎么處理呢?Bufer Pool中采用的是LRU(least recently used,最近最少使用)算法,LRU列表中最前面存的是高頻使用頁,尾部放的是最少使用的頁。當有新數據過來而緩存滿了就會覆蓋尾部數據。
假如我們有一條查詢語句非常大,返回的結果集直接就超過了Buffer Pool的大小,而這種語句使用場景又是極少的,可能查詢這一次之后很久不會查詢,而這一次就將緩存占滿了,將一些熱點數據全部覆蓋了。為了避免這種情況發生,InnoDB對傳統的LRU算法又做了改進,將LRU列表分拆分為2個,如下圖(圖片來源于MySQL官網):
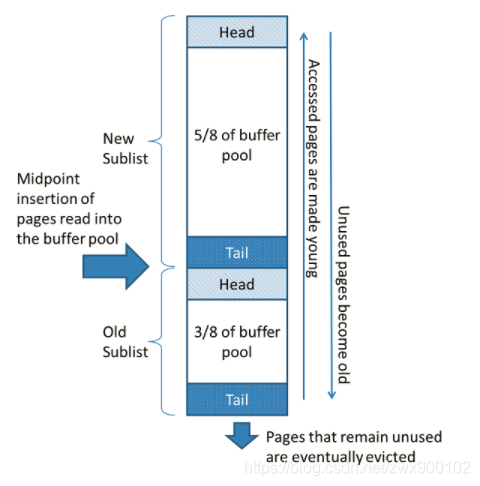
該算法在new子列表中保留大量頁面(5/8),old子列表包含較少使用的頁面(3/8);old子列表中數據可能會被覆蓋,該算法具體操作如下:
-
3/8的Buffer Pool空間用于old子列表
-
列表的中點是new子列表的尾部與old子列表的頭部之間的邊界
-
當InnoDB將一個頁面讀入緩沖池時,它首先將它插入到中間點(old子列表的頭)。讀取的頁面是由用戶發起的操作(比如SQL查詢)或InnoDB自動執行的預讀操作
-
訪問old子列表中的頁面使其“young”,并將其移動到new子列表的頭部。如果讀取的頁是由用戶發起的操作,那么就會立即進行第一次訪問,并使頁面處于young狀態;如果讀取的頁是由預讀發起的操作,那么第一次訪問不會立即發生,而且可能直到覆蓋都不會發生。
-
操作數據時,Buffer Pool中未被訪問的頁會逐漸移到尾部,最終會被覆蓋。
默認情況下,查詢讀取的頁面會立即移動到新的子列表中,這意味著它們在緩沖池中停留的時間更長。
Change Buffer
Change Buffer是一種特殊的緩存結構,用來緩存不在Buffer Pool中的輔助索引頁, 支持insert, update,delete(DML)操作的緩存(注意,這個在MySQL5.5之前叫做Insert Buffer,僅支持insert操作的緩存)。當這些數據頁被其他查詢加載到Buffer Pool后,則會將數據進行merge到索引數據葉中。
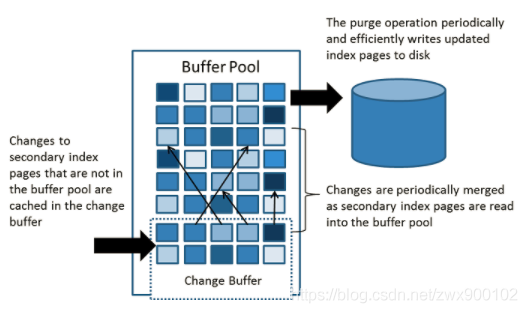
InnoDB在進行DML操作非聚集非唯一索引時,會先判斷要操作的數據頁是不是在Buffer Pool中,如果不在就會先放到Change Buffer進行操作,然后再以一定的頻率將數據和輔助索引數據頁進行merge。這時候通常都能將多個操作合并到一次操作,減少了IO操作,尤其是輔助索引的操作大部分都是IO操作,可以大大提高DML性能。
如果Change Buffer中存儲了大量的數據,那么可能merge操作會需要消耗大量時間。
為什么Change Buffer只能針對非聚集非唯一索引
因為如果是主鍵索引或者唯一索引,需要判斷數據是否唯一,這時候就需要去索引頁中加載數據判斷而不能僅僅只操作緩存。
Change Buffer什么時候會merge
總體來說,Change Buffer的merge操作發生在以下三種情況:
-
輔助索引頁被讀取到Buffer Pool時。 當執行一條select語句時,會去檢查當前數據頁是否在Change Buffer中,如果在,就會把數據merge到索引頁
-
該輔助索引頁沒有可用空間時。 InnoDB內部會檢測輔助索引頁是否還有可用空間(至少有1/32頁),如果檢測到當前操作之后,當前索引頁剩余空間不足1/32時,會進行一次強制merge操作
-
后臺線程Master Thread定時merge。 Master Thread是一個非常核心的后臺線程,主要負責將緩沖池中的數據異步刷新到磁盤,保證數據的一致性。
Adaptive Hash Index
Adaptive Hash Index,自適應哈希索引。InnoDB引擎會監控對索引頁的查詢,如果發現建立哈希索引可以帶來性能上的提升,就會建立哈希索引,這種稱之為自適應哈希索引,InnoDB引擎不支持手動創建哈希索引。
Log Buffer
日志緩沖區是存儲要寫入磁盤日志文件的一塊數據內存區域,大小由變量innodb_log_buffer_size 控制,默認大小為16MB(5.6版本是8MB):
SHOW VARIABLES LIKE 'innodb_log_buffer_size';-- global級別,無session級別
上文講述update語句更新流程一文中,我們只提到了Buffer Pool用來代替緩存區,通過本文對內存結構的分析,實際上Buffer Pool中嚴格來說還有Change Buffer,Log Buffer和Adaptive Hash Index三個部分,DML操作會緩存在Change Buffer區域,而寫redo log之前會先寫入Log Buffer,所以Log Buffer又可以稱之為redo Log Buffer。
Log Buffer什么時候寫入redo log
一個大的Log Buffer空間大允許運行大型事務,而無需在事務提交之前將redo log數據寫入磁盤。Log Buffer中的數據會定期刷新到磁盤,那么Log Buffer的數據又是如何寫入磁盤的呢?Log Buffer數據flush到磁盤有三種方式,通過變量innodb_flush_log_at_trx_commit 控制,默認為1。 |value|描述|

-
當設置為0時,由于數據還在內存,所以崩潰后數據基本會被丟失
-
當設置為2時,由于數據已經實時寫到redo log了,如果磁盤文件沒有被損壞,還是可以恢復的
另外,Mast Thread默認1s進行一次刷盤操作,這個可以通過變量innodb_flush_log_at_timeout控制,默認1s。
SHOW VARIABLES LIKE 'innodb_flush_log_at_timeout';-- global級別,無session級別磁盤結構
InnoDB引擎的磁盤結構,從大的方面來說可以分為Tablespace和redo log兩部分
Tablespace
Tablespace可以分為4大類,分別是:System Tablespace,File-Per-Table Tablespaces,General Tablespaces,Undo Tablespaces
System Tablespace
系統表空間中包括了 InnoDB data dictionary,doublewrite buffer, change buffer, undo logs 4個部分,默認情況下InnoDB存儲引擎有一個共享表空間ibdata1,如果我們創建表沒有指定表空間,則表和索引數據也會存儲在這個文件當中,可以通過一個變量控制(后面會介紹)。
ibdata1文件默認大小為12MB,可以通過變量innodb_data_file_path來控制,改變其大小的最好方式就是設置為自動擴展。
innodb_data_file_path=ibdata1:12M:autoextend上面表示默認表空間ibdata1大小為12MB,支持自動擴展大小。
當我們的文件達到一定的大小之后,比如達到了998MB,我們就可以另外開啟一個表空間文件:
innodb_data_home_dir=
innodb_data_file_path=/ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend關于上面的設置有3點需要注意:
-
innodb_data_home_dir如果不設置的話,那么就默認所有的表空間文件都在datadir目錄下,而我們上面指定了2個不同路徑,所以需要把innodb_data_home_dir設為空
-
autoextend這個屬性,只能放在最后一個文件
-
指定新的表空間文件名的時候,不能和現有表空間文件名一致,否則啟動MySQL時會報錯
當然,表空間可以增大,自然也可以減少,但是一般我們都不會去設置減少,而且減少表空間也相對麻煩,在這里就不展開敘述了。
InnoDB Data Dictionary
InnoDB數據字典由內部系統表組成,其中包含用于跟蹤對象(如表、索引和表列)的元數據。元數據在物理上位于InnoDB系統表空間中。由于歷史原因,數據字典元數據在某種程度上與存儲在InnoDB表元數據文件(.frm文件)中的信息重疊。
Doublewrite Buffer
Doublewrite Buffer,雙寫緩沖區,這個是InnoDB為了實現double write而設置的一塊緩沖區,double write和上面的change buffer一個確保了可靠性,一個確保了性能的提升,是InnoDB中非常重要的兩大特性。
我們先來看下面一張圖:
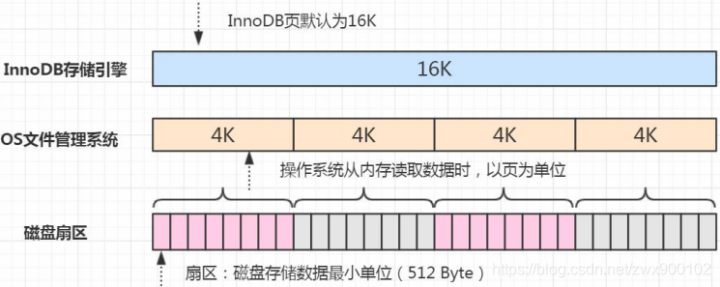
InnoDB默認頁的大小是16KB,而操作系統是4KB,如果存儲引擎正在寫入頁的數據到磁盤時發生了宕機,可能出現頁只寫了一部分的情況,比如只寫了 4K,這種情況叫做部分寫失效(partial page write),可能會導致數據丟失。
可能有人會說,可以通過redo log來恢復,但是注意,redo log恢復數據有一個前提,那就是頁沒有損壞,如果頁本身已經被損壞了,那么是沒辦法恢復的,所以為了確保萬無一失,我們需要先保存一個頁的副本,如果出現了上面的極端情況,可以用頁的副本結合redo log來恢復數據,這就是double write技術。
double write也是由兩部分組成,一部分是內存中的double write buffer,大小為2MB,另一部分是物理磁盤上的共享表空間中的連續128個頁,大小也是2MB,寫入流程如下圖(圖片來源于《MySQL技術內幕 InnoDB存儲引擎》):
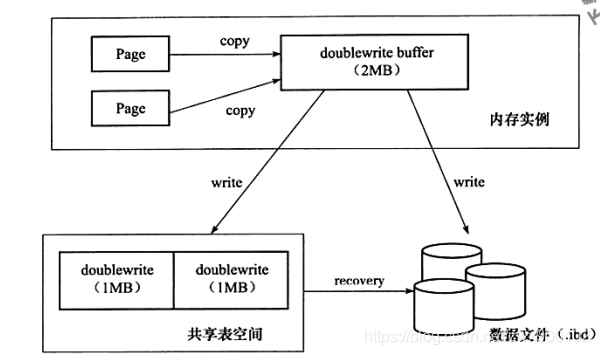
double write機制會使得數據寫入兩次磁盤,但是其并不需要兩倍的I/O開銷或兩倍的I/O操作。通過對操作系統的單個fsync()調用,數據以一個大的順序塊的形式寫入到雙寫入緩沖區。
在大多數情況下默認啟用了doublewrite緩沖區。要禁用doublewrite緩沖區,可通過將變量innodb_doublewrite設置為0即可。
面試資料整理匯總

這些面試題是我朋友進阿里前狂刷七遍以上的面試資料,由于面試文檔很多,內容更多,沒有辦法一一為大家展示出來,所以只好為大家節選出來了一部分供大家參考,需要全部文檔的,關注小編后,點擊這里即可免費領取。
面試的本質不是考試,而是告訴面試官你會做什么,所以,這些面試資料中提到的技術也是要學會的,不然稍微改動一下你就涼涼了
多,沒有辦法一一為大家展示出來,所以只好為大家節選出來了一部分供大家參考,需要全部文檔的,關注小編后,點擊這里即可免費領取。
面試的本質不是考試,而是告訴面試官你會做什么,所以,這些面試資料中提到的技術也是要學會的,不然稍微改動一下你就涼涼了
在這里祝大家能夠拿到心儀的offer!










)








