
目錄
- Kafka的基本介紹
- Kafka的設計原理分析
- Kafka數據傳輸的事務特點
- Kafka消息存儲格式
- 副本(replication)策略
- Kafka消息分組,消息消費原理
- Kafak順序寫入與數據讀取
- 消費者(讀取數據)
Kafka的基本介紹
Kafka是最初由Linkedin公司開發,是一個分布式、分區的、多副本的、多訂閱者,基于zookeeper協調的分布式日志系統(也可以當做MQ系統),常見可以用于web/nginx日志、訪問日志,消息服務等等,Linkedin于2010年貢獻給了Apache基金會并成為頂級開源項目。
主要應用場景是:日志收集系統和消息系統。
Kafka主要設計目標如下:
- 以時間復雜度為O(1)的方式提供消息持久化能力,即使對TB級以上數據也能保證常數時間的訪問性能。
- 高吞吐率。即使在非常廉價的商用機器上也能做到單機支持每秒100K條消息的傳輸。
- 支持Kafka Server間的消息分區,及分布式消費,同時保證每個partition內的消息順序傳輸。
- 同時支持離線數據處理和實時數據處理。
Kafka的設計原理分析
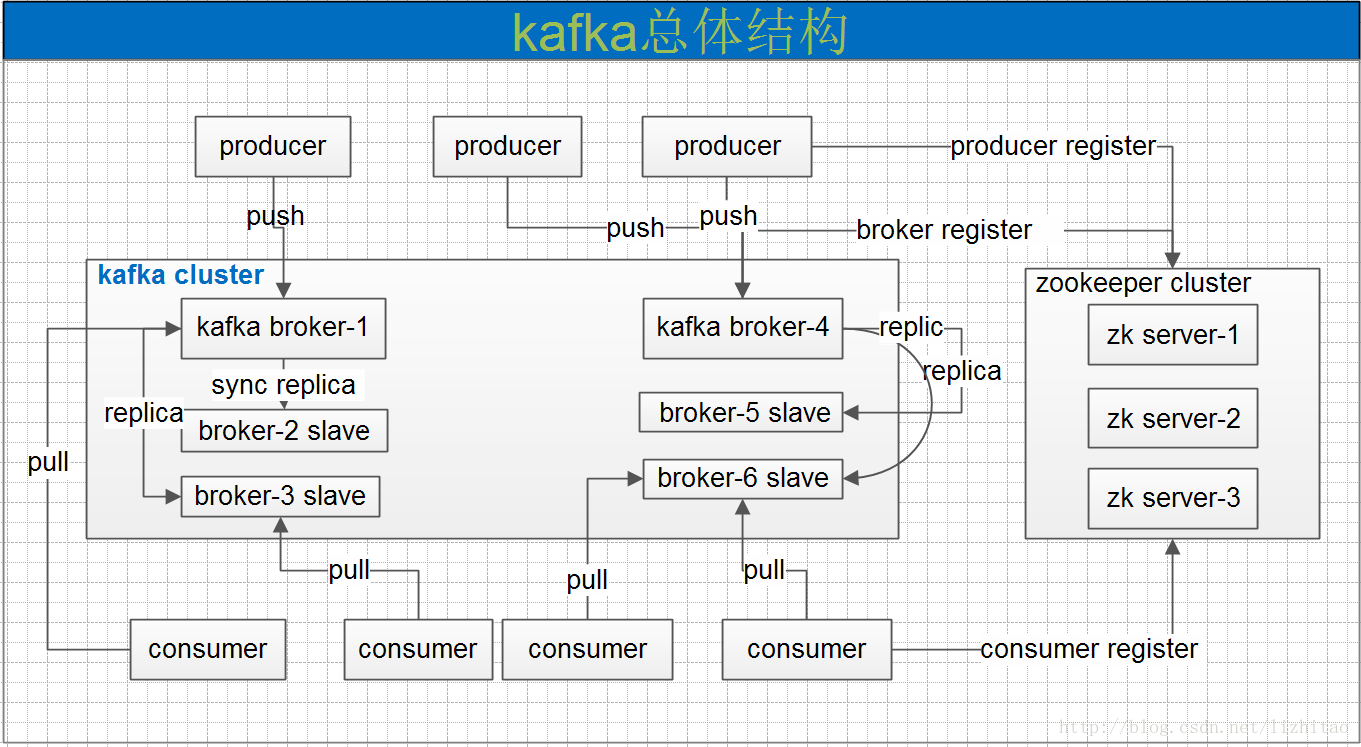
一個典型的kafka集群中包含若干producer,若干broker,若干consumer,以及一個Zookeeper集群。Kafka通過Zookeeper管理集群配置,選舉leader,以及在consumer group發生變化時進行rebalance。producer使用push模式將消息發布到broker,consumer使用pull模式從broker訂閱并消費消息。
Kafka專用術語:
- Broker:消息中間件處理結點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka集群。
- Topic:一類消息,Kafka集群能夠同時負責多個topic的分發。
- Partition:topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的隊列。
- Segment:partition物理上由多個segment組成。
- offset:每個partition都由一系列有序的、不可變的消息組成,這些消息被連續的追加到partition中。partition中的每個消息都有一個連續的序列號叫做offset,用于partition唯一標識一條消息。
- Producer:負責發布消息到Kafka broker。
- Consumer:消息消費者,向Kafka broker讀取消息的客戶端。
- Consumer Group:每個Consumer屬于一個特定的Consumer Group。
Kafka數據傳輸的事務特點
- at most once:最多一次,這個和JMS中"非持久化"消息類似,發送一次,無論成敗,將不會重發。消費者fetch消息,然后保存offset,然后處理消息;當client保存offset之后,但是在消息處理過程中出現了異常,導致部分消息未能繼續處理。那么此后"未處理"的消息將不能被fetch到,這就是"at most once"。
- at least once:消息至少發送一次,如果消息未能接受成功,可能會重發,直到接收成功。消費者fetch消息,然后處理消息,然后保存offset。如果消息處理成功之后,但是在保存offset階段zookeeper異常導致保存操作未能執行成功,這就導致接下來再次fetch時可能獲得上次已經處理過的消息,這就是"at least once",原因offset沒有及時的提交給zookeeper,zookeeper恢復正常還是之前offset狀態。
- exactly once:消息只會發送一次。kafka中并沒有嚴格的去實現(基于2階段提交),我們認為這種策略在kafka中是沒有必要的。
通常情況下"at-least-once"是我們首選。
Kafka消息存儲格式
Topic & Partition
一個topic可以認為一個一類消息,每個topic將被分成多個partition,每個partition在存儲層面是append log文件。
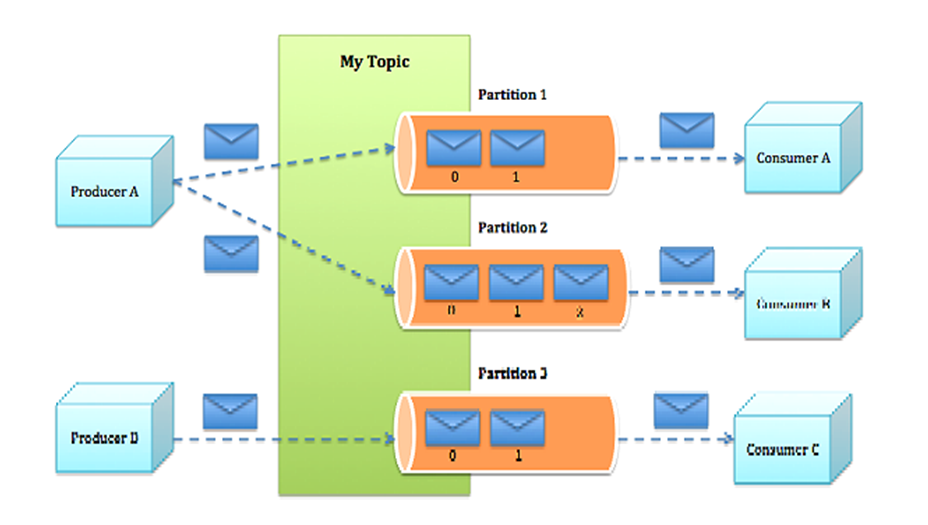
在Kafka文件存儲中,同一個topic下有多個不同partition,每個partition為一個目錄,partiton命名規則為topic名稱+有序序號,第一個partiton序號從0開始,序號最大值為partitions數量減1。
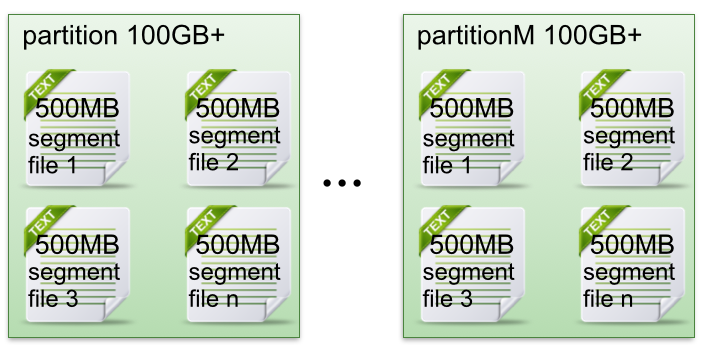
- 每個partion(目錄)相當于一個巨型文件被平均分配到多個大小相等segment(段)數據文件中。但每個段segment file消息數量不一定相等,這種特性方便old segment file快速被刪除。
- 每個partiton只需要支持順序讀寫就行了,segment文件生命周期由服務端配置參數決定。
這樣做的好處就是能快速刪除無用文件,有效提高磁盤利用率。
- segment file組成:由2大部分組成,分別為index file和data file,此2個文件一一對應,成對出現,后綴".index"和“.log”分別表示為segment索引文件、數據文件.
- segment文件命名規則:partion全局的第一個segment從0開始,后續每個segment文件名為上一個segment文件最后一條消息的offset值。數值最大為64位long大小,19位數字字符長度,沒有數字用0填充。
最后分享一波我的面試寶典——一線互聯網大廠Java核心面試題庫
以下是我個人的一些做法,希望可以給各位提供一些幫助:
點擊《一線互聯網大廠Java核心面試題庫》即可免費領取,整理了很長一段時間,拿來復習面試刷題非常合適,其中包括了Java基礎、異常、集合、并發編程、JVM、Spring全家桶、MyBatis、Redis、數據庫、中間件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且還會持續的更新…可star一下!
283頁的Java進階核心pdf文檔
Java部分:Java基礎,集合,并發,多線程,JVM,設計模式
數據結構算法:Java算法,數據結構
開源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架構設計,Redis緩存,Zookeeper,kafka,RabbitMQ,負載均衡等
微服務部分:SpringBoot,SpringCloud,Dubbo,Docker
還有源碼相關的閱讀學習
…(img-PWPB8R6G-1626257210895)]
還有源碼相關的閱讀學習
[外鏈圖片轉存中…(img-OvpzyqGf-1626257210896)]

)
















)
