棧回溯和符號解析是使用 perf 的兩大阻力,本文以應用程序 fio 的觀測為例子,提供一些處理它們的經驗法則,希望幫助大家無痛使用 perf。
前言
系統級性能優化通常包括兩個階段:性能剖析和代碼優化:
-
性能剖析的目標是尋找性能瓶頸,查找引發性能問題的原因及熱點代碼;
-
代碼優化的目標是針對具體性能問題而優化代碼或調整編譯選項,以改善軟件性能。
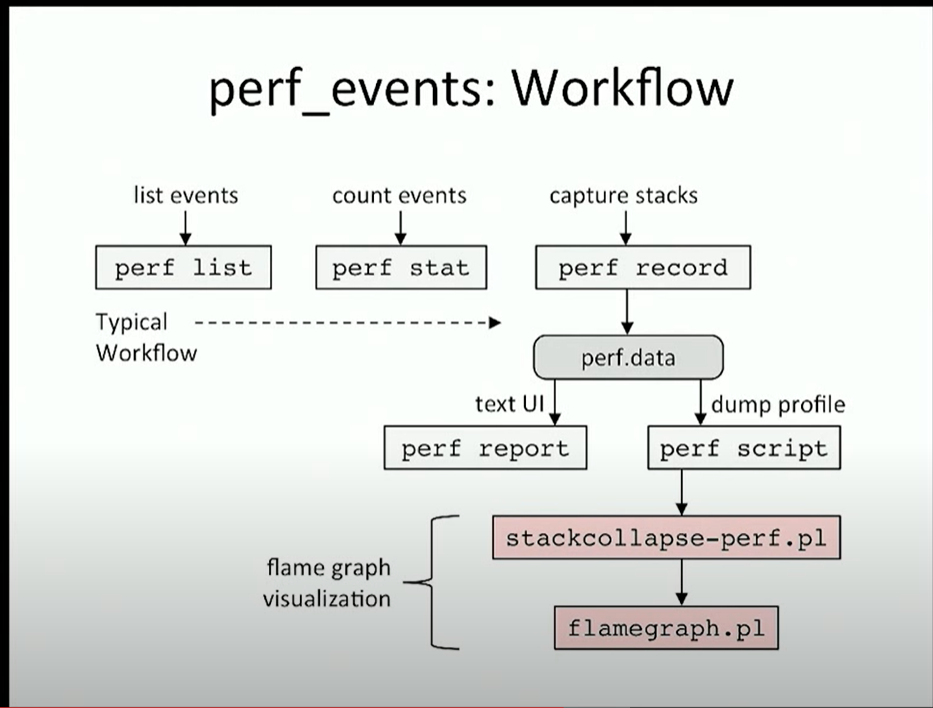
在步驟一性能剖析階段,最常用的工具就是 perf。perf 是 linux 官方提供的性能分析工具,被包含在 Linux 內核源碼樹中。它是一個龐大的工具集合,功能相當繁雜。但在工作中,通常我們只會使用到 perf 其中相當小的一個子集,主要包含以下四個步驟:
-
perf record: 采集數據,采的時間越長越心安;
-
perf report: 查看采集數據,因為采集太長時間,解析數據會卡很久,我們試圖理解數據,通常無法理解;
-
perf script: 嘗試查看原始采樣點,通常無法理解;
-
生成火焰圖: 色彩豐富,通常發給領導理解。
綜上,后三個步驟是我們無法控制的,本文主要聊聊如何在步驟一盡量生成可信的采樣數據。
workflow of perf
雖然聽起來調侃,但上述步驟確實是標準的分析流程,畢竟有火焰圖發明人 Brandon 的背書:
@Brandon
可以看到,它們被包含在 perf 工作流第三列的 capture stacks 中,簡單回顧一下這四個步驟:
-
perf record: 通過指定 -g 選項可以收集系統整體的函數調用棧(包含用戶態和內核態),默認以 4000HZ 的頻率收集,大約每秒生成 4000 個采樣點,被保存在 perf.data 文件中;
$?perf?record?-g?-C?0?--?sleep?1
[?perf?record:?Captured?and?wrote?0.906?MB?perf.data?(4001?samples)?]
-
perf report: 通過解析 perf.data,生成熱點函數占用 CPU 的比例。例如以下輸出中,CPU0 大部分時間(99.73%)停留在內核代碼的 idle 函數中,即 CPU0 大部分時間處于空閑狀態:
$?perf?report?--no-child?--stdio
99.73%??swapper??????????[kernel.kallsyms]??[k]?native_safe_halt|---native_safe_haltacpi_idle_do_entryacpi_idle_entercpuidle_enter_statecpuidle_enterdo_idlecpu_startup_entrystart_kernelsecondary_startup_64_no_verify
-
perf script: 查看每個采樣樣本(棧),例如以下棧樣本表明:
cpu-clock:pppH:事件于時間45399.463561發生,在 CPU0 觸發了中斷,中斷打斷的任務是進程號為 0 的內核線程swapper,棧從下往上看,被打斷時 CPU 正在執行 native_safe_halt 偏移 0xe 處的指令:
$?perf?script
swapper?????0?[000]?45399。463561:?????250000?cpu-clock:pppH:?ffffffffa234c45e?native_safe_halt+0xe?([kernel.kallsyms])ffffffffa234c806?acpi_idle_do_entry+0x46?([kernel.kallsyms])ffffffffa1f4bafb?acpi_idle_enter+0x9b?([kernel.kallsyms])ffffffffa211efb7?cpuidle_enter_state+0x87?([kernel.kallsyms])ffffffffa211f33c?cpuidle_enter+0x2c?([kernel.kallsyms])ffffffffa1b16ff4?do_idle+0x234?([kernel.kallsyms])ffffffffa1b171ef?cpu_startup_entry+0x6f?([kernel.kallsyms])ffffffffa3601262?start_kernel+0x518?([kernel.kallsyms])ffffffffa1a00107?secondary_startup_64_no_verify+0xc2?([kernel.kallsyms])
-
使用腳本生成火焰圖,以下是官網例圖:
可以發現,后續的分析步驟都基于步驟一采集得到的 perf.data。顯然,只有獲取到足夠精準的調用棧信息,后續才能準確定位到性能瓶頸。可惜的是,獲取函數調用棧并沒有一個通用解,導致我們需要額外了解一些小知識。
choose your unwinder
獲取函數調用棧過程又稱棧回溯(unwind),棧回溯的方法被稱為 unwinder,常見的 unwinder 有:
-
fp:perf 默認選項,ARM 和 X86 都支持,消耗低;
-
dwarf:通過
--call-graph=dwarf指定,ARM 和 X86 都支持,對CPU和磁盤消耗高; -
lbr:通過
--call-graph=lbr指定,僅 Intel 新型號支持,消耗低,但可回溯的棧深度有限; -
orc:內核 unwinder,無需指定。 在 perf record 中,若不通過
--call-graph指定 unwinder,默認使用 fp 作為用戶態棧的 unwinder;至于內核態的 unwinder,不由 perf 參數指定,由內核編譯選項控制,低版本內核使用 fp,高版本內核使用 orc。
因此問題轉化為:用戶態使用哪個 unwinder 是更合適的?結論先行,以下是可供參考的方案:
-
Intel CPU:優先使用 lbr,lbr 的好處是硬件實現,精準可靠,大部分情況下深度夠用;
-
ARM 架構:優先使用 fp,因為 ARM 架構寄存器比較多,保留了寄存器記錄棧基址;
- X86 上沒有 lbr 時:優先使用 dwarf,雖然 X86 架構也把棧基址保存在 %rbp,但只要編譯優化大于等于
-O1,%rbp 寄存器基本作為通用寄存器使用,使得在 X86 上用 fp 獲取用戶態棧大部分時候不可靠。有以下注意點:-
在 linux 5.19 版本以下,dwarf 可能采樣不到動態鏈接庫的棧(參考提交 perf unwind: Fix egbase for ld.lld linked objects);
-
dwarf 需要復制保存每一個采樣點的用戶棧,因此采樣期間 CPU 消耗較高,生成的采樣數據也遠大于其它 unwinder;
-
如果 dwarf 無法滿足需求,可以 gcc 編譯時添加選項
-fno-omit-frame-pointer放棄復用 %rbp 寄存器的編譯優化,重新編譯應用后使用 fp。雖然該選項無法百分百保證 %rbp 一定可靠,但總體可信。
-
讓我們通過在 X86 架構上觀測應用程序 fio,對這些 unwinder 有個初步的了解:
$?perf?record?-a?--user-callchains?--call-graph=dwarf?-p?`pidof?fio`?-o?perf.data.dwarf?--?sleep?2
$?perf?report?--no-ch?--stdio?-i?perf.data.dwarf10.69%??fio??????[kernel.kallsyms]??[k]?iowrite16|---syscallio_submit0x55a0a986682e?#?<-?我們會在下下節解決符號問題td_io_committd_io_queue0x55a0a985945a?<-0x55a0a985b7d0?<-?start_thread__GI___clone?(inlined)
$?perf?record?-a?--user-callchains?--call-graph=fp?-p?`pidof?fio`?-o?perf.data.fp?--?sleep?2
$?perf?report?--no-ch?--stdio?-i?perf.data.fp8.27%??fio??????[kernel.kallsyms]??[k]?iowrite16|---syscall|--0.75%--0x70700000707|--0.75%--0x62d0000062d|--0.75%--0x5e1000005e1|--0.75%--0x55b0000055a|--0.75%--0x54800000548|--0.75%--0x52f0000052f|--0.75%--0x51000000510|--0.75%--0x44f0000044f|--0.75%--0x3cb000003cb|--0.75%--0x39800000398--0.75%--0x37c0000037b
以上采集數據的命令中使用 --user-callchains 選項指定了 perf 采樣時只采集用戶棧,排除掉我們暫時不關心的內核棧。輸出中可以看到雖然 dwarf 采集得到的棧沒有被完全翻譯,但正確地回溯到了進程剛誕生的函數 __GI___clone,這表明 dwarf 采樣得到了完整的棧;反觀 fp,只得到了些奇怪的地址。我們的方案三是有效的!
what do dwarf do
為敘述完整,該節補充一點 dwarf 棧回溯原理,不影響 perf 使用,不涉及的朋友可以跳轉下一節解決符號問題。
在編譯過程中 gcc 無論是否指定 -g 選項, 默認都會生成 .eh_frame 和 .eh_frame_hdr 段. gcc 在翻譯代碼為匯編代碼時, 會幫忙插上一些 CFI 偽指令, 如
$?gcc?-S?test.c???????????#?c語言生成匯編代碼
$?vim?test.s??????????????#?查看匯編代碼
$?cat?test.s.cfi_startproc?#?剛進函數,?當前我們處于?callee?棧幀的起始處,?更新?CFA?=?rsp?+?8pushq?%rbp#?每次?push?寄存器到棧上,?需要將?CFA?+=?8,?因為相比上一狀態需要多往前走一個單位才是?caller?的棧幀.cfi_def_cfa_offset?16.cfi_offset?6,?-16?#?并且更新該寄存器關于?CFA?的偏移,?使回溯過程可以恢復該寄存器的值#?...movq?%rsp?%rbp?#?將?rsp?寄存器賦值給?rbp.cfi_def_cfa_register?6?#?將寄存器?6?(rbp)?定義為?CFA?寄存器,?之后?CFA?的計算都基于?rbp#?...leave.cfi_def_cfa?7,?8?#?leave?中將?rbp?寄存器的值賦值給?rsp,?即?rsp?此時指向?callee?棧幀開始處,?此時?CFA?=?rsp?+?8.cfi_endproc
$?readelf?-wF?test.o?#?查看對應的?.eh_frame?印證
0000000000000661?rsp+8????u?????c-8???
0000000000000662?rsp+16???c-16??c-8???
0000000000000665?rbp+16???c-16??c-8???
00000000000006a6?rsp+8????c-16??c-8?
其中 CFA (Canonical Frame Address, which is the address of %rsp in the caller frame) 指上一級調用者的堆棧指針.
如上所示, 匯編器會將這些 CFI 偽指令收集到可執行文件中的 .eh_frame 段. 典型形式如下:
$?readelf?-wF?a.out?
Contents?of?the?.eh_frame?section:00000000?0000000000000014?00000000?CIE?"zR"?cf=1?df=-8?ra=16LOC???????????CFA??????ra????
0000000000000000?rsp+8????u?????...000000c8?0000000000000044?0000009c?FDE?cie=00000030?pc=00000000000006b0..0000000000000715LOC???????????CFA??????rbx???rbp???r12???r13???r14???r15???ra????
00000000000006b0?rsp+8????u?????u?????u?????u?????u?????u?????c-8???
00000000000006b2?rsp+16???u?????u?????u?????u?????u?????c-16??c-8???
00000000000006b4?rsp+24???u?????u?????u?????u?????c-24??c-16??c-8???
00000000000006b9?rsp+32???u?????u?????u?????c-32??c-24??c-16??c-8???
00000000000006bb?rsp+40???u?????u?????c-40??c-32??c-24??c-16??c-8???
00000000000006c3?rsp+48???u?????c-48??c-40??c-32??c-24??c-16??c-8???
00000000000006cb?rsp+56???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
00000000000006d8?rsp+64???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
000000000000070a?rsp+56???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
000000000000070b?rsp+48???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
000000000000070c?rsp+40???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
000000000000070e?rsp+32???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
0000000000000710?rsp+24???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
0000000000000712?rsp+16???c-56??c-48??c-40??c-32??c-24??c-16??c-8???
0000000000000714?rsp+8????c-56??c-48??c-40??c-32??c-24??c-16??c-8??
可以看到 .eh_frame 總體架構由 CIE 和 FDE 組成。通常一個 CIE 代表一個文件, 一個 FDE 代表一個函數. 其中核心的是 FDE 的組織:

利用 .eh_frame 進行棧 unwind 時候, 遵循以下步驟:
-
根據當前的PC在
.eh_frame中找到對應的條目,根據條目提供的各種偏移計算其他信息。 -
首先根據
CFA = rsp+4,把當前rsp+4得到CFA的值。再根據CFA的值計算出通用寄存器和返回地址在堆棧中的位置。 -
通用寄存器棧位置計算。例如:rbx = CFA-56。
-
返回地址ra的棧位置計算。ra = CFA-8。
-
根據ra的值,重復步驟1到4,就形成了完整的棧回溯。
handle missing symbols
函數調用棧本質是一串地址,perf 會盡量將地址翻譯人類可讀的符號。在以下樣本點中,可以看到 IP 寄存器保存的地址屬于 libc 庫,它被正確翻譯為 syscall+0x1d,但再往下回溯,我們只知道 syscall 函數是由 libaio 庫某不知名函數調用的。這里出現 [unknown] 通常由于可執行程序的符號被裁剪所致,裁剪符號是有效減小可執行程序體積的做法。
$?perf?script?-D?-i?perf.data.dwarf
259594741631398?0x2d840?[0x20f8]:?PERF_RECORD_SAMPLE(IP,?0x1):?273245/273258:?0xffffffff89d1869d?period:?250000?addr:?0
...?FP?chain:?nr:0
[...]
....?IP????0x00007f3afb87f52d
...?ustack:?size?8192,?offset?0xe0
[...]
fio?273258?259594.741631:?????250000?cpu-clock:pppH:?7f3afb87f52d?syscall+0x1d?(/usr/lib64/libc-2.28.so)7f3afc50ab7d?[unknown]?(/usr/lib64/libaio.so.1.0.1)55a0a9866a95?[unknown]?(/usr/bin/fio)55a0a98197a5?td_io_getevents+0x75?(/usr/bin/fio)55a0a983b216?io_u_queued_complete+0x66?(/usr/bin/fio)55a0a98577d4?[unknown]?(/usr/bin/fio)55a0a98591fa?[unknown]?(/usr/bin/fio)55a0a985b7d0?[unknown]?(/usr/bin/fio)7f3afc0db179?start_thread+0xe9?(/usr/lib64/libpthread-2.28.so)7f3afb884dc2?__GI___clone+0x42?
那怎么將符號補全呢?我們可以通過安裝 -debuginfo 或 -dbgsym 包解決,例如對于 fio:
#?centos?上,先使能?yum?的?debuginfo?源,再安裝對應應用的?-debuginfo?包即可
$?cat?/etc/yum.repos.d/CentOS-Linux-Debuginfo.repo?
[debuginfo]
name=CentOS?Linux?$releasever?-?Debuginfo
baseurl=http://debuginfo.centos.org/$releasever/$basearch/
gpgcheck=0
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
$?yum?clean?all?&&?yum?makecache
$?yum?-y?install?fio-debuginfo.x86_64#?ubuntu?上,先導入調試符號簽名密鑰,再安裝對應應用的?-dbgsym?包即可
$?apt?install?ubuntu-dbgsym-keyring
$?apt?install?fio-dbgsym
補全后的棧如下所示:
$?perf?script?-i?perf.data.dwarf
fio??2469??2823.211391:?????250000?cpu-clock:pppH:?7f03631a89bd?syscall+0x1d?(/usr/lib64/libc-2.28.so)7f0363ef1c14?io_submit+0x34?(/usr/lib64/libaio.so.1.0.1)555976f418ce?fio_libaio_commit+0xde?(/usr/bin/fio)555976ef4a98?td_io_commit+0x58?(/usr/bin/fio)555976ef4fb5?td_io_queue+0x3f5?(/usr/bin/fio)555976f344ea?do_io+0x71a?(/usr/bin/fio)555976f36880?thread_main+0x18b0?(/usr/bin/fio)555976f38561?run_threads+0xcb1?(/usr/bin/fio)
后記
當你面對一個性能問題,如果選擇使用 perf 觀測,那么問題就變成了三個,另外兩個是在解決性能問題前,必須先解決棧回溯和符號解析,前者影響觀測準確性,后者影響觀測可讀性。perf 大部分時候都幫忙做好了,但如果遇到了些小困難,希望本文能有幸幫上一點忙。







)
——ET模式實現分析)



)


)


)

)