0 前言
接上一篇文章:進程調度(2b):STCF(最短完成時間優先) 算法 原理與實踐
1 前提鋪墊
除了與上一篇相同的,這里介紹新的基礎知識。
1.1 三種類型的程序
- 計算密集型(CPU導向)
- 輸入輸出密集型(I/O導向)
- 中間型
所謂計算密集型程序,就是大量時間都在占用CPU做運算,例如科學計算。而輸入輸出密集型程序,則大量時間都在進行輸入輸出,你很熟悉它,例如人機交互,我們每時每刻都在用計算機干這個事情。中間型就是二者都有,占比差不多。
那么介紹這個有什么用?
當我們的目標不同的時候,性能指標的評價標準也不同,對于計算密集型程序,我們可能更關注它的Turnaround Time,而對于(交互型的)輸入輸出密集型程序,我們可能更關注它的Response Time。后續我們會對算法進行性能評價,設計目標很重要不是嗎?
1.2 響應時間(Response Time)
這是一個新的性能指標。
Response Time: the time a job spends waiting after arrival before first running.
所謂響應時間,就是從任務到達后,到第一次被執行的等待時間。這個概念在分時操作系統誕生后變得尤為重要,用戶是“獨占”計算機的,并且是交互式界面,所以對用戶來說,響應時間非常重要,用戶必須等待很短的時間就能看到一部分結果。
試想一個場景,你敲擊了鍵盤的字母Z,然后在10s之后,才看見屏幕顯示了Z……這真的令人抓狂不是嗎?
我們需要做的,就是讓用戶快速看到自己的成果,此時,并不需要將程序執行完成,將程序運行一點點先給用戶顯示出來,這對于用戶來說是很棒的!
那么應該如何做到這一點?答案就是充分使用上下文切換。還記得上一篇我們的搶占式調度嗎?它第一次打破了進程順序執行,實現了簡易的進程(上下文)切換,現在,我們要充分利用上下文切換,來讓用戶因為快速響應而得到滿足了!
但是要警惕!沒有必要太快!上下文切換也是需要系統開銷的,它的占比應該盡可能小,我們后續會深入談。現在,你只需要知道,響應時間是1s還是0.1s,對用戶來說是沒有什么區別的,因此我們選擇1s即可,這樣將上下文切換的數量降低了10倍。
1.3 上下文切換(Context Switch)
好吧……上面說了這么多上下文切換,它到底是個啥?第一篇我提到了底層機制 + 上層策略,當時只是提了一句,現在,我們再進一步說一說。
- 底層機制:上下文切換
- 上層策略:FIFO,SJF,STCF,RR……
在解釋這個之前,我們先來談談刀吧。對的,就是刀!
你知道的,刀可以削水果,可以切菜,也可以雕刻……但是歸根結底,都是在刀足夠鋒利的前提下,這些事情才能完成,我們分析一下:
- 底層機制:刀足夠鋒利
- 上層策略:削水果,切菜,雕刻……
也就是說,在刀鋒利這個底層機制滿足的前提下,我們才能切菜削水果。
好吧現在我們回來,對于進程調度算法而言,也是一樣的,我們在能夠實現上下文切換(進程切換)的前提下,才能使用各種各樣的方法進行進程調度。
你要問我Context Switch是什么樣的?我來畫張圖。
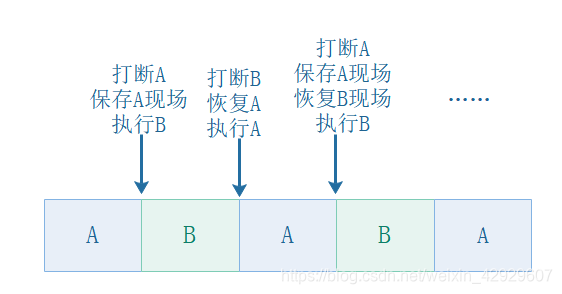
我想你明白了,只是切換而已。如果說更關鍵的,可能是
- 保存現場和恢復現場是如何實現的?
- 上下文切換的系統開銷是多少?
我們先不回答這個問題,你只需要知道,每次上下文切換的時間 / 每個時間片的時間 這個比例應該小一點!(時間片下面就會談)
2 RR原理
RR(Round - Robin)輪轉,輪轉算法下,多個進程不再是順序執行,而是切換式執行,這樣對于交互式程序來說,用戶就能快速感受到自己執行的操作得到了響應,響應時間短。
2.1 算法
舉個例子
- A:20s
- B:20s
- C:20s
在順序執行下,上述3個進程按照A、B、C的順序依次執行,如下圖:

這樣一來,響應時間分別是
- A:0s
- B:20s
- C:40s
對于執行C程序的用戶來說,他可能會非常崩潰……響應太慢總是讓人發瘋的,不是嗎?
如果我們采用輪轉算法,假定一個時間片為10s,結果就不一樣了,所謂時間片,就是指某進程在CPU執行10s,就要被中斷,然后讓其他進程執行(也就是每隔10s就進行上下文切換)。
我們看看會發生什么:

這樣一來,響應時間分別為
- A:0s
- B:10s
- C:20s
響應時間縮短很多了,但是好像還是慢,如果時間片設置為1s呢?響應時間就是0s,1s和2s,這就很棒了!
2.1.1 思考1:時間片可以無限小下去嗎?
我們的用戶當然想要更快獲得響應,但是對于用戶來說,1s和0.1s可能沒什么差別,所以我們完全可以選擇1s,那么,選擇更大值的理由是什么?不選0.1s的理由是什么?
答案就是切換上下文需要系統開銷,切換上下文的時候,要保存當前程序的狀態,我們切換越頻繁,系統的額外開銷就越多,要之前,順序執行的時候我們根本不需要這樣做,所以,切換上下文帶來的開銷應該盡可能小一點。
例如,時間片是10ms,切換上下文需要1ms,那么我們需要浪費10%的時間去切換上下文,如果時間片是100ms,就占1%,這還可以接受,物極必反的道理就在于此了。
- 擴展:可以思考下奔騰4的失敗,CPU的流水線深度越深性能就越好嗎?奔騰4使用了31級流水線,性能反而下降了,現代CPU的流水線也不過十幾級,例如i7是14級。
- 推薦閱讀:面向流水線的指令設計:奔騰4是怎么失敗的?
所以說,時間片是不能無限小下去,它的占比應該小一點,小到什么程度那就與具體需求和實現有關了。
假設切換上下文1s,時間片10s,上面的例子就成了這樣:

相關分析請讀者自行完成。
2.1.2 思考2:時間片的設置可以是任意的嗎?
對于上下文切換這個底層機制的實現,是由軟硬件協同完成的,這里有一個重要的概念時鐘中斷,時鐘每隔一段時間,就會中斷程序,把控制權從正在執行的程序交還給OS。
因此說,我們的時間片應該是時鐘中斷周期的整倍數,這樣,我們就能保證每個時間片在執行的時候不會被時鐘中斷所打斷(被程序本身的系統調用打斷就是另一回事了……)
2.2 缺點:大鍋飯式分配 & 增長的周轉時間
RR算法下,對所有就緒進程都是一視同仁的,不管你是誰,都會被執行,切斷,切換,恢復,再執行,就像大鍋飯一樣,不管你干活多少,吃的飯都一樣。
但是我們知道,不同的程序,重要程度和緊急程度是不一樣的,但是RR全忽略了,這顯然不合理。
另外,響應時間確實是改進了,但是此時程序周轉時間表現不佳,這是顯而易見的。
因此我們的算法仍需要進一步改進。
3 RR實踐
我們來進行幾個模擬,體會上一小節的幾個觀點吧。
我們先試一下SJF,3個進程都是100s,同時到達
./scheduler.py -p SJF -l 100,100,100 -c
得到的結果是
Average -- Response: 100.00 Turnaround 200.00 Wait 100.00
再試試RR,3進程都是100s,時間片是1s,忽略上下文切換時間
./scheduler.py -p RR -q 1 -l 100,100,100 -c
得到的結果是
Average -- Response: 1.00 Turnaround 299.00 Wait 199.00
你可以充分體會到,SJF的響應時間是RR是100倍,RR的周轉時間是SJF是1.5倍,而在更極端的情況下,差距可能會更大。
4 核心思想
目前我們接觸到的都是計算密集型程序,而且是100%占用CPU,我們關注了兩大性能指標,周轉時間和響應時間。
- 關注周轉時間的算法:FIFO,SJF和STCF
- 關注響應時間的算法:RR
目前來說,我們還
- 沒有同時兼顧周轉時間和響應時間的算法
- 沒有考慮包含輸入輸出的程序的算法
這也是接下來我們要改進的。
5 預告:進程調度(4):I/O、不可預測的運行時間
接下來,我們初步為程序引入I/O,并且談談最初的一個假設運行時間已知是否現實。
鏈接:進程調度(4):I/O、不可預測的運行時間
:I/O、不可預測的運行時間)



)
03,04)

)
(資源消耗))
(數據通路設計思想))
數據通路構建:取指部件分析)

數據通路構建:第一類R型指令分析(1))
)



并行接口8255A(1):全局觀)

