0 前言
上一篇文章:進程調度(3):RR(輪轉) 算法 原理與實踐
1 前提鋪墊
與上一篇同。
2 引入I/O操作
之前我們一直提及的是計算密集型程序,現在我們的程序可以進行I/O交互了,它會發起I/O請求,比如向磁盤發起請求獲取數據。
這個時候,我們之前的算法會發生怎樣的變化呢?我們來探索一下!
2.1 進程的三狀態模型
- Ready:就緒態
- Running:運行態
- Waiting:阻塞態 / 等待
最后還有一個DONE,代表執行完成,我們看一下其定義:
RUNNING - the process is using the CPU right now
READY - the process could be using the CPU right nowbut (alas) some other process is
WAITING - the process is waiting on I/O(e.g., it issued a request to a disk)
DONE - the process is finished executing
之前我們的計算密集型程序,僅僅使用CPU,沒有Waiting狀態,不過現在有了!
2.2 傻等:糟糕的資源利用方式
我們看一看一個向磁盤發起IO請求的程序,將會如何執行。
我們先假定其采用FIFO策略順序執行吧!
- A:每在CPU執行10s,就發起IO請求,IO耗時10s,之后再在CPU執行10s,發起IO,共循環3次。
- B:運行時間30s,100%使用CPU,不發起IO請求。
假定A比B先到達一點點。
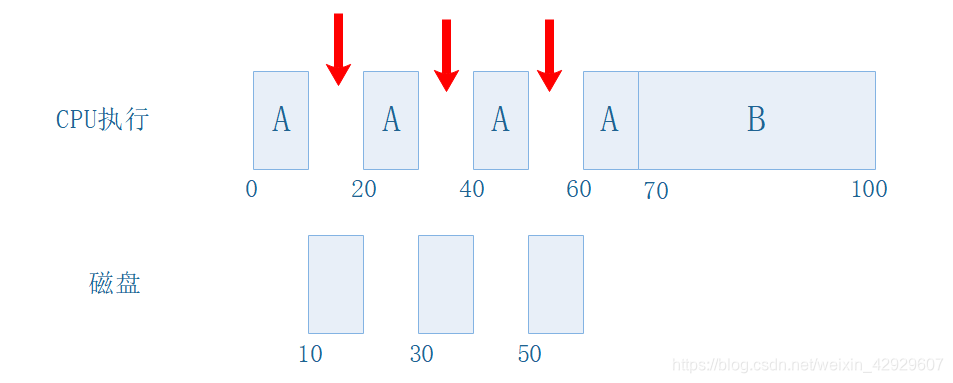
它的執行就成了這樣,注意紅色箭頭部分,CPU是空閑的!OMG!CPU空閑了30s!如此昂貴的CPU空閑30s……這真是太糟糕了。
2.3 重疊:高效利用資源
既然B執行30s,為什么不在空閑的時候執行B呢?反正我們擁有上下文切換機制!
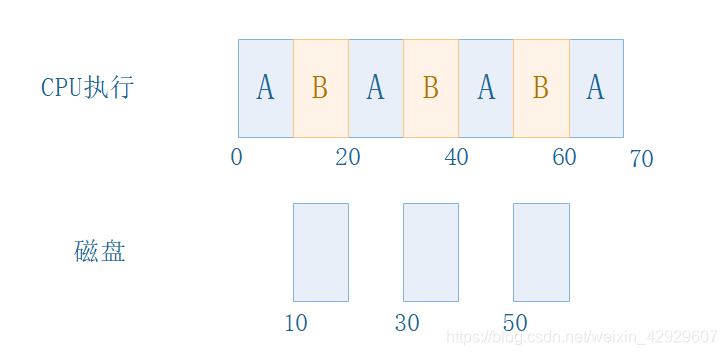
這看起來棒多了,A和B重疊了起來!CPU沒有被浪費,系統的整體性能也提高了,之前100s做的現在70s完成了!
3 不可預測的運行時間
3.1 無法預知的未來
之前我們的假設是任務運行時間已知,但是這怎么可能?我們不可能在程序運行前,就知道它將會運行多久……這很荒謬不是嗎?那怎么辦?
3.2 以史為鑒:預測時間
我們將會使用以史為鑒的方式,估計運行時間,也就是基于該程序之前運行時間的歷史情況,估算一下,這聽起來還有點靠譜了!具體實現先不談,之后再說。
3.3 思想貫通:CPU流水線的分支預測
CPU流水線,是硬件,也有類似的技術,就是分支預測,更著名的是動態分支預測,這這很棒!我想之后軟硬件的預測思想可以結合起來理解,達到融會貫通。
4 預告:進程調度(5)MLFQ(多級反饋隊列)算法 原理與實踐
之前我們的算法,無法同時兼顧周轉時間和響應時間,那么,何不將二者的優點結合? 這也就是接下來我們做的事情。
5 模擬軟件鏈接
點擊此處,在Linux可以運行模擬軟件,請閱讀README.md文檔,然后進行軟件的使用。
此模擬軟件可以充分體會多進程運行時候的轉換,體會IO引入程序之后帶來的重疊使用方式。



)
03,04)

)
(資源消耗))
(數據通路設計思想))
數據通路構建:取指部件分析)

數據通路構建:第一類R型指令分析(1))
)



并行接口8255A(1):全局觀)


并行接口8255A(2):控制字概述)