非類型模板參數
模板參數分類類型形參與非類型形參。
類型形參:出現在模板參數列表中,跟在class或者typename之類的參數類型名稱。
非類型形參,就是用一個常量作為類(函數)模板的一個參數,在類(函數)模板中可將該參數當成常量來使用。
namespace bite
{template<class T, size_t N>class array{public:void push_back(constT& data){//N=10;_array[_size++] = data;}T& operator[](size_t){assert(index < _size)return _array[index];}bool empty()const{return 0 == _size;}size_t size()const{return _size;}private:T _array[N];size_t _size;};
}
注意事項
- 浮點數、類對象以及字符串是不允許作為非類型模板參數的。
- 非類型的模板參數必須在編譯期就能確認結果。
模板的特化
模板特化的概念
通常情況下,使用模板可以實現一些與類型無關的代碼,但對于一些特殊類型的可能會得到一些錯誤的結果,比如
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){}bool operator>(const Date&d)const{return _day > d._day;}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "/" << d._month << "/" << d._day << endl;return _cout;}
private:int _year;int _month;int _day;
};
template<class T>
T& Max(T& left, T& right)
{return left > right ? left : right;
}char *p1 = "world";char *p2 = "hello";cout << Max(p1, p2) << endl;cout << Max(p2, p1) << endl;
這個代碼他就無法比較字符串類型的變量的大小
此時,就需要對模板進行特化。即:在原模板類的基礎上,針對特殊類型所進行特殊化的實現方式
函數模板特化
如果不需要通過形參改變外部實參加上const
例如
template<class T>
const T& Max(const T& left, const T& right)
{return left > right ? left : right;
}
//函數模板的特化
template<>
char *& Max<char*>(char*& left, char*& right)
{//>0大于 =0等于 <0小于if (strcmp(left, right) > 0){return left;}return right;
}
注意事項
- 必須要先有一個基礎的函數模板
- 關鍵字template后面接一對空的尖括號<>
- 函數名后跟一對尖括號,尖括號中指定需要特化的類型
- 函數形參表: 必須要和模板函數的基礎參數類型完全相同,如果不同編譯器可能會報一些奇怪的錯誤。
一般函數模板沒必要特化,直接把相應類型的函數給出就行
char* Max(char *left, char* right)
{if (strcmp(left, right) > 0){return left;}return right;
}
類模板的特化
全特化
//全特化-----對所有類型參數進行特化
template<class T1, class T2>
class Data
{
public:Data() { cout << "Data<T1, T2>" << endl; }
private:T1 _d1;T2 _d2;
};template<>
class Data<int, int>
{
public:Data() { cout << "Data<int, int>" << endl; }
private:int _d1;int _d2;
};int main()
{Data<int, double>d1;Data<int, int>d2;return 0;
}
偏特化
部分特化
//偏特化,將模板參數列表中的參數部分參數類型化
template<class T1>
class Data<T1,int>
{
public:Data() { cout << "Data<T1, int>" << endl; }
private:T1 _d1;int _d2;
};int main()
{Data<int, double>d1;Data<int, int>d2;Data<double, int>d3;system("pause");return 0;
}
參數更進一步的限制
//偏特化:讓模板參數列表中的類型限制更加的嚴格
template<class T1,class T2>
class Data<T1*, T2*>
{
public:Data() { cout << "Data<T1*, T2*>" << endl; }
private:T1* _d1;T2* _d2;
};int main()
{Data<int*, int>d1;Data<int, int*>d2;Data<int*, int*>d3;//特化Data<int*, double*>d4;//特化system("pause");return 0;
}
模板特化的作用之類型萃取
編寫一個通用類型的拷貝函數
template<class T>
void Copy(T* dst, T* src, size_t size)
{memcpy(dst, src, sizeof(T)*size);
}
上述代碼雖然對于任意類型的空間都可以進行拷貝,但是如果拷貝自定義類型對象就可能會出錯,因為自定義類型對象有可能會涉及到深拷貝(比如string),而memcpy屬于淺拷貝。如果對象中涉及到資源管理,就只能用賦值。
class String
{
public:String(const char* str = ""){if (str == nullptr)str = "";this->_str = new char[strlen(str) + 1];strcpy(this->_str, str);}String(const String& s):_str ( new char[strlen(s._str)+1]){strcpy(this->_str, s._str);}String& operator=(const String &s){if (this != &s){char *str = new char[strlen(s._str) + 1];strcpy(str, s._str);delete[]_str; _str = s._str;}}~String(){delete[]_str;}private:char* _str;
};//寫一個通用的拷貝函數,要求:效率盡量高
template<class T>
void Copy(T* dst, T* src, size_t size)
{memcpy(dst, src, sizeof(T)*size);
}void TestCopy()
{int array1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };int array2[10];Copy(array2, array1, 10);String s1[3] = { "111", "222", "333" };String s2[3];Copy(s2, s1, 3);
}
如果是自定義類型用memcpy,那么會存在
- 淺拷貝----導致代碼崩潰
- 內存泄露—S2數組中每個String類型對象原來的空間丟失了
增加一個拷貝函數處理淺拷貝
template<class T>
void Copy2(T* dst, T*src, size_t size)
{for (size_t i = 0; i < size; ++i){dst[i] = src[i];}
}
- 優點:一定不會出錯
- 缺陷:效率比較低,讓用戶做選擇,還需要判斷調用哪個函數
讓函數自動去識別所拷貝類型是內置類型或者自定義類型
bool IsPODType(const char* strType)
{//此處將所有的內置類型枚舉出來const char * strTypes[] = { "char", "short", "int", "long", "long long", "float", "double" };for (auto e : strTypes){if (strcmp(strType, e) == 0)return true;}return false;
}template<class T>
void Copy(T* dst, T*src, size_t size)
{//通過typeid可以將T的實際類型按照字符串的方式返回if (IsPODType(typeid(T).name()){//T的類型:內置類型memcpy(dst, src, sizeof(T)*size);}else{//T的類型:自定義類型----原因:自定義類型種可能會存在淺拷貝for (size_t i = 0; i < size; ++i){dst[i] = src[i];}}
}
在編譯期間就確定類型—類型萃取
如果把一個成員函數的聲明和定義放在類里面,編譯器可能會把這個方法當成內聯函數來處理
class String
{
public:String(const char* str = ""){if (str == nullptr)str = "";this->_str = new char[strlen(str) + 1];strcpy(this->_str, str);}String(const String& s):_str(new char[strlen(s._str) + 1]){strcpy(this->_str, s._str);}String& operator=(const String& s){if (this != &s){char* str = new char[strlen(s._str) + 1];strcpy(str, s._str);delete[] _str;_str = str;}return *this;}~String(){delete[]_str;}private:char* _str;
};//確認T到底是否是內置類型
//是
//不是
//對應內置類型
struct TrueType
{static bool Get(){return true;}
};//對應自定義類型
struct FalseType
{static bool Get(){return true;}
};template<class T>
struct TypeTraits
{typedef FalseType PODTYPE;};template<>
struct TypeTraits<char>
{typedef TrueType PODTYPE;
};template<>
struct TypeTraits<short>
{typedef TrueType PODTYPE;
};
template<>
struct TypeTraits<int>
{typedef TrueType PODTYPE;
};//........還有很多內置類型template<class T>
void Copy(T* dst, T* src, size_t size)
{// 通過typeid可以將T的實際類型按照字符串的方式返回if (TypeTraits<T>::PODTYPE::Get()){// T的類型:內置類型memcpy(dst, src, sizeof(T)*size);}else{// T的類型:自定義類型---原因:自定義類型中可能會存在淺拷貝for (size_t i = 0; i < size; ++i)dst[i] = src[i];}
}
STL中的類型萃取
// 代表內置類型
struct __true_type {};
// 代表自定義類型
struct __false_type {};template <class type>
struct __type_traits
{typedef __false_type is_POD_type;
};// 對所有內置類型進行特化
template<>
struct __type_traits<char>
{typedef __true_type is_POD_type;
};
template<>
struct __type_traits<signed char>
{typedef __true_type is_POD_type;
};
template<>
struct __type_traits<unsigned char>
{typedef __true_type is_POD_type;
};
template<>
struct __type_traits<int>
{typedef __true_type is_POD_type;
};
template<>
struct __type_traits<float>
{typedef __true_type is_POD_type;
};
template<>
struct __type_traits<double>
{typedef __true_type is_POD_type;
};
// 注意:在重載內置類型時,所有的內置類型都必須重載出來,包括有符號和無符號,比如:對于int類型,必
須特化三個,int -- signed int -- unsigned int
// 在需要區分內置類型與自定義類型的位置,標準庫通常都是通過__true_type與__false_type給出一對重載
的
// 函數,然后用一個通用函數對其進行封裝
// 注意:第三個參數可以不提供名字,該參數最主要的作用就是讓兩個_copy函數形成重載
template<class T>
void _copy(T* dst, T* src, size_t n, __true_type)
{memcpy(dst, src, n*sizeof(T));
}
template<class T>
void _copy(T* dst, T* src, size_t n, __false_type)
{for (size_t i = 0; i < n; ++i)dst[i] = src[i];
}
template<class T>
void Copy(T* dst, T* src, size_t n)
{_copy(dst, src, n, __type_traits<T>::is_POD_type());
}
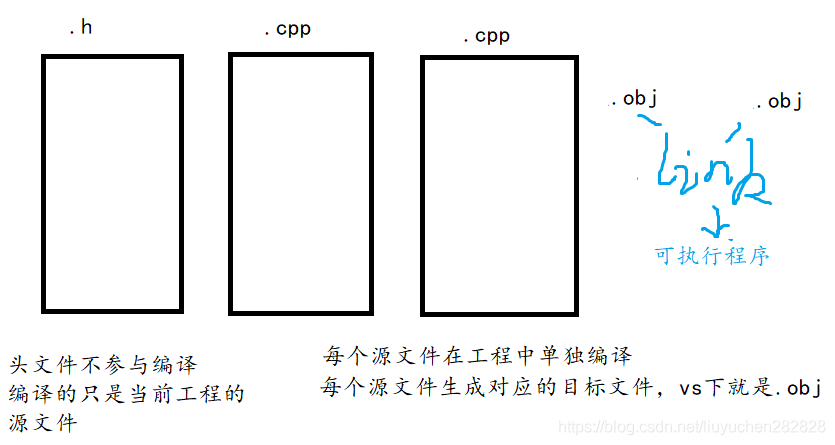
分離編譯
預處理----->編譯---->匯編----->鏈接
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right)
{return left + right;
}
// main.cpp
#include"a.h"
int main()
{Add(1, 2);Add(1.0, 2.0);return 0;
}
沒有模板的函數,沒有問題
有模板的函數,編譯可以過,但是鏈接會出錯
函數模板編譯:
- 實例化之前:編譯器只做一些簡答的語法檢測,不會生成處理具體類型的代碼。并不會確認函數的入口地址
- 實例化期間:編譯器會推演形參類型來確保模板參數列表中T的實際類型,在生成具體類型的代碼
- 不支持分離編譯
解決分離編譯
- 將聲明和定義放到一個文件 “xxx.hpp” 里面或者xxx.h其實是可以的。
- 模板定義的位置顯式實例化。
模板總結
優點
- 模板復用了代碼,節省資源,更快的迭代開發,C++的標準模板庫(STL)因此而產生
- 增強了代碼的靈活性
缺點
- 模板會導致代碼膨脹問題,也會導致編譯時間變長
- 出現模板編譯錯誤時,錯誤信息非常凌亂,不易定位錯誤
更加深入學習參考這個鏈接




)







)
)





