哈希切割
給一個超過100G大小的log file, log中存著IP地址, 設計算法找到出現次數最多的IP地址? 與上題條件相同,如何找到top K的IP?如何直接用Linux系統命令實現
解決思路
找到出現次數最多的IP地址
要找到前TopK的IP地址,就是要統計每個IP地址出現多少次
分割大文件:如果能將相同IP地址放到同一個文件中
哈希分割: 從源文件中獲取一個IP地址---->IP%文件份數
- 每拿到一個IP地址后,用函數把IP地址轉化為整型數據,再%上文件分數,就知道把IP地址放到哪個文件中去
- 這樣,就可以統計每個IP地址出現多少次
//構建鍵值對
<IP地址的整型數據,次數>
- 統計哪個IP地址出現的次數比較多,用unordered_map,m[ip]++;每拿到一個IP地址的++。每個IP地址出現的次數,已經在unordered_map中保存起來
- 按類似的方法,統計每個文件中的IP地址的次數,最后用一個for()---->找出出現最多的IP地址
top K的IP
堆---->最多前K個IP地址—><次數,IP地址>
位圖
給40億個不重復的無符號整數,沒排過序。給一個無符號整數,如何快速判斷一個數是否在這40億個數中。
- 遍歷,時間復雜度O(N)
- 排序(O(NlogN)),利用二分查找: logN
位圖解決
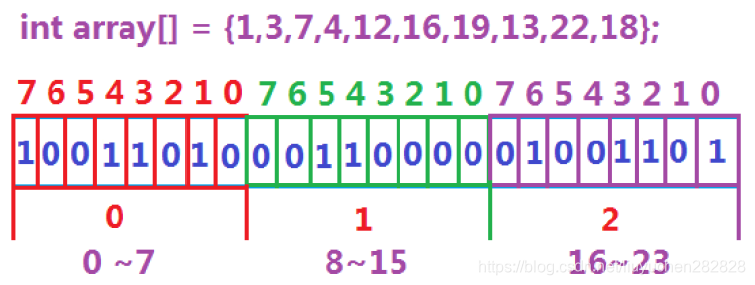
數據是否在給定的整形數據中,結果是在或者不在,剛好是兩種狀態,那么可以使用一個二進制比
特位來代表數據是否存在的信息,如果二進制比特位為1,代表存在,為0代表不存在。比如:
40億的整型數據大概是16G的數據
用位圖來映射的話 大概就是232-23=512M
解決
C++中提供了位圖的類,bitset
位圖的實現
#pragma once
#include<vector>
#include<iostream>
using namespace std;
namespace LXY
{class bitset{public:bitset(size_t bitCount):_set(bitCount/8 + 1), _bitCount(bitCount){}//置1操作void set(size_t which){//如果位集合給出100個比特位,那么你給100,就表示不了,范圍為0~99if(which >= _bitCount)return;//計算對應的字節size_t index = (which >> 3);//除以8size_t pos = which % 8;//先將1移到對應的比特位上,再或上對應位上的數字_set[index] |= (1 << pos);}//置0操作void reset(size_t which){if (which >= _bitCount)return;//計算對應的字節size_t index = (which >> 3);//除以8size_t pos = which % 8;//先將1的取反0移到對應的比特位上,再與上對應位上的數字_set[index] &= ~(1 << pos);}//檢測which比特位是否為1bool test(size_t which){if (which >= _bitCount)return false;//計算對應的字節size_t index = (which >> 3);//除以8size_t pos = which % 8;//與上1不等于0就代表存在return 0 != (_set[index] & (1 << pos));}//返回比特位總的個數size_t size(){return _bitCount;}//返回為1的比特位的總數size_t count(){//查表int bitCnttable[256] = {0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2, 3, 3, 4, 2,3, 3, 4, 3, 4, 4, 5, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3,3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3,4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4,3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5,6, 6, 7, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4,4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5,6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 3,4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 4, 5, 5, 6, 5, 6, 6, 7, 5, 6,6, 7, 6, 7, 7, 8 };size_t szcount = 0;for (size_t i = 0; i < _set.size(); ++i)szcount += bitCnttable[_set[i]];return szcount;}public:std::vector<unsigned char> _set;size_t _bitCount;};
}void TestBitSet()
{LXY::bitset bt(100);bt.set(10);bt.set(20);bt.set(30);bt.set(40);bt.set(41);cout << bt.size() << endl;cout << bt.count() << endl;if (bt.test(40))cout << "40bite is 1" << endl;elsecout << "40bite is not 1" << endl;bt.reset(40);cout << bt.count() << endl;if (bt.test(40))cout << "40bite is 1" << endl;elsecout << "40bite is not 1" << endl;
}int main()
{TestBitSet();system("pause");return 0;
}
位圖的應用
- 快速查找某個數據是否在一個集合中
- 排序 (數據不能有重復)
- 求兩個集合的交集、并集等
- 操作系統中磁盤塊標記
位圖的題
- 給定100億個整數,設計算法找到只出現一次的整數?
用兩個比特位表示一個數據,8/2=4;那么位圖中一個字節只能表示4個數據,232/22=1G。
取一個數據:哪個字節 哪兩個比特位
if(00) //出現過0次01else if(01) //出現過多次10
- 位圖應用變形:1個文件有100億個int,1G內存,設計算法找到出現次數不超過2次的所有整數
布隆過濾器
位圖+哈希函數
特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”,它是用多個哈希函數,將一個數據映射到位圖結構中。此種方式不僅可以提升查詢效率,也可以節省大量的內存空間。多個比特位代表數據的狀態信息
布隆過濾器插入
如果向布隆過濾器中插入baidu,我們用三個哈希函數將三個位置置為1
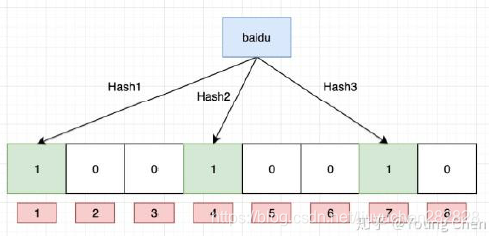
“baidu”---->1 4 7
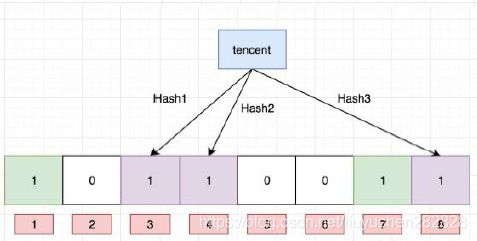
“tecent”---->3 4 8
hash1,hash2,hash3----->三個位置
檢測三個位置的狀態
如果三個位置只要有一個為0,說明數據一定不存在
布隆過濾器的查找
布隆過濾器的思想是將一個元素用多個哈希函數映射到一個位圖中,因此被映射到的位置的比特位一定為1。所以可以按照以下方式進行查找:分別計算每個哈希值對應的比特位置存儲的是否為零,只要有一個為零,代表該元素一定不在哈希表中,否則可能在哈希表中
布隆過濾器如果告訴你數據不存在,那么一定不存在,如果告訴你存在,則有可能存在。
布隆過濾器的插入和查找的實現
#pragma once
#include"biteset.hpp"
#include<iostream>
#include"Common.hpp"
using namespace std;//BloomFilter:位圖+多個哈希
template<class T,class HF1 = Str2INT ,class HF2 = Str2INT2,class HF3 = Str2INT3,class HF4 =Str2INT4,class HF5 = Str2INT5>
//哈希函數給的越多,將來產生誤報的概率就也就越小
class BloomFilter
{
public:BloomFilter(size_t size = 10):_bt(10 * size), _size(0){}bool Insert(const T& data){//HF1()(data)可能回越界,要%上位圖的比特位數size_t index1 = HF1()(data) % _bt.size();size_t index2 = HF2()(data) % _bt.size();size_t index3 = HF3()(data) % _bt.size();size_t index4 = HF4()(data) % _bt.size();size_t index5 = HF5()(data) % _bt.size();_bt.set(index1);_bt.set(index2);_bt.set(index3);_bt.set(index4);_bt.set(index5);_size++;return true;}//檢測是否存在,每個哈希函數都得檢測bool IsIn(const T&data){size_t index = HF1()(data) % _bt.size();if (!_bt.test(index))return false;index = HF2()(data) % _bt.size();if (!_bt.test(index))return false;index = HF3()(data) % _bt.size();if (!_bt.test(index))return false;index = HF4()(data) % _bt.size();if (!_bt.test(index))return false;index = HF5()(data) % _bt.size();if (!_bt.test(index))return false;//元素可能存在return true;}//存儲多少個元素size_t count()const{return _size;}
private:LXY::bitset _bt;size_t _size;
};
布隆過濾器的刪除
布隆過濾器不能直接支持刪除工作,因為在刪除一個元素時,可能會影響其他元素
一種支持刪除的方法:將布隆過濾器中的每個比特位擴展成一個小的計數器(整型數組),插入元素時給k個計數器(k個哈希函數計算出的哈希地址)加一,刪除元素時,給k個計數器減一,通過多占用幾倍存儲空間的代價來增加刪除操作。
缺陷:
- 無法確認元素是否真正在布隆過濾器中
- 存在計數回繞
布隆過濾器優點
- 增加和查詢元素的時間復雜度為:O(K), (K為哈希函數的個數,一般比較小),與數據量大小無關
- 哈希函數相互之間沒有關系,方便硬件并行運算
- 布隆過濾器不需要存儲元素本身,在某些對保密要求比較嚴格的場合有很大優勢
- 在能夠承受一定的誤判時,布隆過濾器比其他數據結構有這很大的空間優勢
- 數據量很大時,布隆過濾器可以表示全集,其他數據結構不能
- 使用同一組散列函數的布隆過濾器可以進行交、并、差運算
布隆過濾器缺陷
- 有誤判率,即存在假陽性(False Position),即不能準確判斷元素是否在集合中(補救方法:再建立一個白名單,存儲可能會誤判的數據)
- 不能獲取元素本身
- 一般情況下不能從布隆過濾器中刪除元素
- 如果采用計數方式刪除,可能會存在計數回繞問題
布隆過濾器
- 給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?分別給出精確算法和近似算法
答:給一個布隆過濾器,將一個文件的數據映射里面去。如果整體映射不完,先映射一部分。從另外一個文件拿一個數據在布隆過濾器里面找,如果有,數據存在就算是兩個文件的交集。
倒排索引
給上千個文件,每個文件大小為1K—100M。給n個詞,設計算法對每個詞找到所有包含它的文件,你只有100K內存



)
)














