什么是壓縮
想辦法讓源文件變得更小并能還原。
為什么要進行文件壓縮
- 文件太大,節省空間
- 提高數據再網絡上傳輸的效率
- 對數據有保護作用—加密
文件壓縮的分類
- 無損壓縮
- 源文件被壓縮后,通過解壓縮能夠還原成和源文件完全相同的格式
- 有損壓縮
- 解壓縮之后不能將其還原成與源文件完全相同的格式–解壓縮之后的文件再識別其內容時基本沒有影響
GZIP壓縮
LZ77變形:
原理將重復出現得語句用盡可能短得標記來替換
字符串的壓縮
LZ77可以消除文件中重復出現的語句,但還存在字節方面的重復
基于Huffman編碼得壓縮
基于字節的壓縮
1個字節—>8個bit位,如果對于每個字節如果能夠找到一個更短的編碼,來重新改寫原3數據,可以起到壓縮的目的
Huffman樹的概念
從二叉樹的根結點到二叉樹中所有葉結點的路徑長度與相應權值的乘積之和為該二叉樹的帶權路徑長度WPL。
把帶權路徑最小的二叉樹稱為Huffman樹
Huffman樹的概念
用戶提供一組權值信息
- 以每個權值為結點創建N棵二叉樹的森林
- 如果二叉樹森林中有超過兩個樹,進行以下操作
- 從二叉樹森林中取出根結點權值最小的兩棵二叉樹
- 以該兩棵二叉樹作為某個結點的左右子樹創建一顆新的二叉樹,新二叉樹中的權值為其左右子樹權值之和
- 將新創建的二叉樹插入到森林中
創建好之后的二叉樹森林中的每棵樹可以采用堆(priority_queue)保存
Huffman樹的創建
Huffman樹的結點定義
struct HuffManTreeNode
{HuffManTreeNode(const W& weight = W()):_pLeft(nullptr), _pRight(nullptr), _pParent(nullptr), _weight(weight){}HuffManTreeNode<W>* _pLeft;HuffManTreeNode<W>* _pRight;HuffManTreeNode<W>* _pParent;//加上雙親指針域W _weight; //結點的權值
};
Huffman樹的類
template<class W>
class HuffManTree
{typedef HuffManTreeNode<W> Node;
public:HuffManTree():_pRoot(nullptr){}HuffManTree(const vector<W>& vWeight, const W& invaild){//進行建樹操作CreatHuffManTree(vWeight,invaild);}~HuffManTree(){_DestroyTree(_pRoot);}Node* GetRoot(){return _pRoot;}void CreatHuffManTree(const vector<W>& vWeight,const W& invaild){//1.構建森林//底層為優先級隊列priority_queue<Node*,vector<Node*>,Less<W>> q;for (auto e : vWeight){//默認插入的數據沒有重復if (e == invaild)//如果是無效的權值,就不放了continue;q.push(new Node(e));//創建新的結點,樹就有了}//2.看森林里面有沒有超過兩個樹while (q.size() > 1){//取根結點權值最小的兩顆樹Node* pLeft = q.top();q.pop();Node* pRight = q.top();q.pop();// 以該兩棵二叉樹作為某個結點的左右子樹創建一顆新的二叉樹,//新二叉樹中的權值為其左右子樹權值之和Node* pParent = new Node(pLeft->_weight + pRight->_weight);pParent->_pLeft = pLeft;pParent->_pRight = pRight;//將新數插入到Huffman樹中pLeft->_pParent = pParent; //更新雙親pRight->_pParent = pParent;q.push(pParent);}//3.森林里只有一棵樹了,就是哈夫曼樹_pRoot = q.top();}private://銷毀二叉樹,只能用后序遍歷的方式進行銷毀void _DestroyTree(Node*& pRoot){if (pRoot){_DestroyTree(pRoot->_pLeft);_DestroyTree(pRoot->_pRight);delete pRoot;//要改指針本身,要么傳二級指針,要么一級指針的引用pRoot = nullptr;}}
private:Node * _pRoot;
};
基于Huffman編碼的壓縮和解壓縮
壓縮
- 統計源文件中每個字節出現的次數
- 用統計的結果創建Huffman樹
- 什么是Huffman樹:帶權路徑長度最短的一顆二叉樹----權值越大,越靠近根結點
- Huffman樹創建規則:
- 用所有的權值創建只有根結點的二叉樹森林
- 從二叉樹森林中取出根結點權值最小的兩棵二叉樹
- 以該兩棵二叉樹作為某個結點的左右子樹創建一顆新的二叉樹,新二叉樹中的權值為其左右子樹權值之和
- 將新創建的二叉樹插入到森林中
- 取權值最小,用優先級隊列也就是堆
- 從Huffman樹種獲取字節的編碼
void GenerateHuffmanCode(pRoot)
{if(nullptr == pRoot )return ;GenerateHuffmanCode(pRoot->left);GenerateHuffmanCode(pRoot->right);//是葉子結點獲取編碼if(nullptr == pRoot->left&& nullptr == pRoot->right){Node* pParent =pRoot->parent;Node* pCur = pRoot;while(pParent){if(pCur == pParent->left)str+='0';elsestr+='1';}}
}
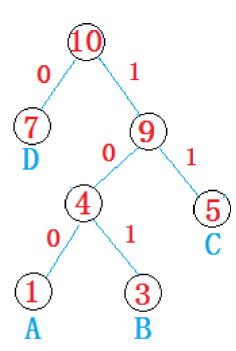
壓縮文件實現
我們將文件中出現的字符信息保存在一個大小為256的數組中
//構造函數
FileCompressHuff::FileCompressHuff()
{_fileInfo.resize(256);for (int i = 0; i < 256; ++i){_fileInfo[i]._ch = i;_fileInfo[i]._count = 0;}
}
每一個數組的元素都是一個結構體類型,里面要保存該字符的信息,如:編碼,出現的次數
而且要支持字符之間的一些運算
struct CharInfo
{unsigned char _ch; //具體的字符size_t _count; //字符出現的次數std::string _strCode;//字符編碼CharInfo(size_t count = 0):_count(count){}CharInfo operator+(const CharInfo& c){//返回對象,無名對象return CharInfo(_count + c._count);}bool operator>(const CharInfo& c){return _count > c._count;}//比較次數bool operator==(const CharInfo& c){return _count == c._count;}
};
最后再按照上面的四步來完成壓縮的任務
void FileCompressHuff::CompressFile(const string& path)
{//1.統計源文件中每個字符出現的次數FILE* fIn = fopen(path.c_str(),"rb");if (nullptr == fIn){assert(false);return;}unsigned char * pReadBuff = new unsigned char[1024];int rdSize = 0;while (true){//讀文件rdSize = fread(pReadBuff, 1, 1024, fIn); if (0 == rdSize)break;//統計for (int i = 0; i < rdSize; ++i){_fileInfo[pReadBuff[i]]._count++;}}//2.以這些出現的次數為權值創建哈夫曼樹HuffManTree<CharInfo> t(_fileInfo,CharInfo());//3.獲取每個字符的編碼GenerateHuffManCode(t.GetRoot());//4.獲取到的字符編碼重新改寫FILE* fOut = fopen("2.txt", "wb"); //打開一個文件保存壓縮后的結果if (nullptr == fOut){assert(false);return;}//將來要保存文件的后綴,所以壓縮時要讀取壓縮格式文件頭部信息WriteHead(fOut, path);fseek(fIn,0,SEEK_SET); //把文件指針再次放到文件的起始位置char ch = 0; //存放字符編碼int bitcount = 0; //計算放了多少個比特位while (true){rdSize = fread(pReadBuff, 1, 1024,fIn);if (0 == rdSize) //文件讀取結束break;//根據字節的編碼對讀取到的內容進行重寫for (size_t i = 0; i < rdSize; ++i){//拿到編碼string strCode = _fileInfo [pReadBuff[i]]._strCode;//A "100"for (size_t j = 0; j < strCode.size(); ++j){ch <<= 1; //每放一個往左一位,把下一個編碼往里放//存放的時候,一個一個比特位來放if ('1' == strCode[j])ch |= 1;bitcount++;if (8 == bitcount) //說明ch滿了,把這個字節寫到文件中去{//fputc 寫單個字節的函數fputc(ch, fOut);//寫完后,都清零bitcount = 0;ch = 0;}}}}//最后一次ch中可能不夠8個比特位if (bitcount < 8){ch <<= 8 - bitcount; //左移剩余的位數//不夠的位肯定要寫到文件中fputc(ch, fOut);}delete[]pReadBuff;fclose(fIn);fclose(fOut);
}
獲取字符編碼
//計算字符編碼
void FileCompressHuff::GenerateHuffManCode(HuffManTreeNode<CharInfo>* pRoot)
{if (nullptr == pRoot)return;GenerateHuffManCode(pRoot->_pLeft);GenerateHuffManCode(pRoot->_pRight);//找到葉子結點if (nullptr == pRoot->_pLeft&&pRoot->_pRight == nullptr){string& strCode = _fileInfo[pRoot->_weight._ch]._strCode;HuffManTreeNode<CharInfo>* pCur = pRoot;HuffManTreeNode<CharInfo>* pParent = pCur->_pParent;while (pParent){if (pCur == pParent->_pLeft) //左為0{strCode += '0';}else //右為1{strCode += '1';}pCur = pParent;pParent = pCur->_pParent;}//字符編碼從葉子結點開始獲取是個反的//我們需要把它翻轉一下reverse(strCode.begin(), strCode.end());//_fileInfo[pRoot->_weight._ch]._strCode = strCode;}
}
獲取文件后綴
//獲取文件的后綴
//2.txt
//F:\123\2.txt
string FileCompressHuff:: GetFilePostFix(const string& filename)
{//substr截取文件,第二個參數沒有給的話默認截取到末尾return filename.substr(filename.rfind('.'));
}
壓縮文件的格式
壓縮文件中只保存壓縮之后的數據可以嗎?
答案是不行的,因為在解壓縮時,沒有辦法進行解壓縮。比如:10111011 00101001 11000111 01011,只有壓縮數據是沒辦法進行解壓縮的,因此壓縮文件中除了要保存壓縮數據,還必須保存解壓縮需要用到的信息:
- 源文件的后綴
- 字符次數對的總行數
- 字符以及字符出現次數(為簡單期間,每個字符放置一行
- 壓縮數據
//壓縮文件格式
void FileCompressHuff::WriteHead(FILE* fOut, const string& filename)
{assert(fOut);//寫文件的后綴string strHead;strHead += GetFilePostFix(filename);strHead += '\n'; //后綴與后面的內容之間用\n隔開//寫行數size_t lineCount = 0;string strChCount;char szValue[32] = { 0 }; //緩沖區放入字符次數for (int i = 0; i < 256; ++i){CharInfo& charInfo = _fileInfo[i];if (charInfo._count){lineCount++; //行數strChCount += charInfo._ch; //字符strChCount += ':'; //字符與字符次數之間用冒號隔開_itoa(charInfo._count, szValue, 10);strChCount += szValue; //字符次數strChCount += '\n'; //末尾加\n}}_itoa(lineCount, szValue, 10);//接受字符的行數strHead += szValue; //字符的行樹strHead += '\n'; //換行隔開信息strHead += strChCount; //字符的種類個數//寫信息fwrite(strHead.c_str(),1,strHead.size(),fOut);
}
解壓縮
- 從壓縮文件中獲取源文件的后綴
- 從壓縮文件中獲取字符次數的總行數
- 獲取每個字符出現的次數
- 重建huffman樹
- 依靠Huffman樹解壓縮解壓縮
要解壓縮文件我們先要讀取壓縮文件的格式信息
//讀取壓縮文件的信息
void FileCompressHuff::ReadLine(FILE* fIn, string& strInfo)
{assert(fIn);//讀取一行的字符while (!feof(fIn)) //只要文件指針沒有到文件末尾就讀取{//讀取一個字符char ch = fgetc(fIn);if (ch == '\n')break;//有效的字符就拼接上去strInfo += ch;}
}
按照上面的步驟完成解壓縮
void FileCompressHuff::UNComPressFile(const std::string& path)
{FILE* fIn = fopen(path.c_str(), "rb");if (nullptr == fIn){assert(false);return;}//讀取文件的后綴string strFilePostFix;ReadLine(fIn,strFilePostFix);//讀取字符信息的總行數string strCount;ReadLine(fIn, strCount);int lineCount = atoi(strCount.c_str()); //總的行數//讀取字符的信息for (int i = 0; i < lineCount; ++i){string strchCount;ReadLine(fIn, strchCount); //讀每一行的字符信息//如果讀取到的是\nif (strchCount.empty()){strchCount += '\n'; //將\n寫入讀取ReadLine(fIn, strchCount); //多讀一行,將\n的次數和冒號讀取}//A:100_fileInfo[(unsigned char)strchCount[0]]._count = atoi(strchCount.c_str() + 2);//跳過前兩個字符,因為前兩個是A:}//還原Huffman樹HuffManTree<CharInfo> t; //創建Huffamn樹的對象t.CreatHuffManTree(_fileInfo, CharInfo(0)); //還原Huffman樹FILE* fOut = fopen("3.txt","wb");assert(fOut);//解壓縮char* pReadBuff = new char[1024]; //創建緩沖區char ch = 0;HuffManTreeNode<CharInfo>* pCur = t.GetRoot();size_t fileSize = pCur->_weight._count; //文件總的大小就是根結點的權值的次數size_t uncount = 0;//表示解壓縮了多少個while (true){size_t rdSize = fread(pReadBuff,1,1024,fIn); //讀數據if (0 == rdSize)break;//一個個字節進行解壓縮for (size_t i = 0; i < rdSize; ++i){//只需要將一個字節中的8個比特位單獨處理ch = pReadBuff[i];for (int pos = 0; pos < 8; ++pos){//增加一次判斷if (nullptr == pCur->_pLeft && nullptr == pCur->_pRight){//uncount++; //每次解壓縮一個,就++一下fputc(pCur->_weight._ch, fOut);if (uncount == fileSize)break;//葉子結點,解壓出一個字符,寫入文件 pCur = t.GetRoot(); //把pCur放到樹根的位置上繼續}if (ch & 0x80)//如果該位上的數字為1pCur = pCur->_pRight;elsepCur = pCur->_pLeft;ch <<= 1; //與完后往左移動一位if (nullptr == pCur->_pLeft && nullptr == pCur->_pRight){uncount++; //每次解壓縮一個,就++一下fputc(pCur->_weight._ch, fOut);if (uncount == fileSize)break;//葉子結點,解壓出一個字符,寫入文件 pCur = t.GetRoot(); //把pCur放到樹根的位置上繼續}}//for循環完后再讀取下一個字節}}delete[]pReadBuff;fclose(fIn);fclose(fOut);
}
出現的問題
1. 加中文
問題1
壓縮時統計源文件中每個字符出現的次數時,出現崩潰,因為數組越界,因為char[-128.127];
修改:將char改成unsigned char;
問題2
獲取編碼時崩潰,將CharInfo結構體中的char改為unsigned char
問題3
解壓縮函數讀取字符信息時崩潰,strchCount要作為數組下標必須為整數,將其強轉為unsigned char
2.多行信息
問題1
解壓縮函數中的解壓縮時崩潰,因為pCur為空了,因為讀取文件時,讀取空格就直接什么都沒有讀到,所以遇到空格時應該多讀一行,在解壓縮讀取文件時處理\n
問題2
文件量增大時,只能解壓縮一部分,將所有的文件打開和寫入方式轉變為以二進制形式打開和寫入,并在解壓縮時再增加一次判斷
完整代碼:
要改進的方面
- 保證壓縮的正確性
- 壓縮比率
- 是不是每次壓縮之后變小?有沒有可能壓縮變大?
- 文本文件,視頻,音頻,圖片,都可以壓縮?
- 其它改進的方式
)


















