98中的一個例子
如果想要對一個數據集合中的元素進行排序,可以使用std::sort方法
#include <algorithm>
#include <functional>
int main()
{int array[] = {4,1,8,5,3,7,0,9,2,6};// 默認按照小于比較,排出來結果是升序std::sort(array, array+sizeof(array)/sizeof(array[0]));// 如果需要降序,需要改變元素的比較規則std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());return 0;
}
排序一個單鏈表
如果待排序元素為自定義類型,需要用戶定義排序時的比較規則:
struct Goods
{string _name;double _price;
};
struct Compare
{bool operator()(const Goods& gl, const Goods& gr){return gl._price <= gr._price;}
};
int main()
{Goods gds[] = { { "蘋果", 2.1 }, { "相交", 3 }, { "橙子", 2.2 }, { "菠蘿", 1.5 } };sort(gds, gds + sizeof(gds) / sizeof(gds[0]), Compare());return 0;
}
每次為了實現一個algorithm算法, 都要重新去寫一個類,如果每次比較的邏輯不一樣,還要去實現多個類,特別是相同類的命名,這些都給編程者帶來了極大的不便
lambda表達式
函數中聲明函數
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods&left, const Goods& right){return left._price < right._price; });
lambda表達式語法
lambda表達式書寫格式:
- [capture-list] (parameters) mutable -> return-type { statement }
- lambda表達式各部分說明
[capture-list]: 捕捉列表,該列表總是出現在lambda函數的開始位置,編譯器根據[]來判斷接下來的代碼是否為lambda函數,捕捉列表能夠捕捉上下文中的變量供lambda函數使用。(parameters):參數列表。與普通函數的參數列表一致,如果不需要參數傳遞,則可以連同()一起省略mutable:默認情況下,lambda函數總是一個const函數,mutable可以取消其常量性。使用該修飾符時,參數列表不可省略(即使參數為空)。->return-type:返回值類型。用追蹤返回類型形式聲明函數的返回值類型,沒有返回值時此部分可省略。返回值類型明確情況下,也可省略,由編譯器對返回類型進行推導。{statement}:函數體。在該函數體內,除了可以使用其參數外,還可以使用所有捕獲到的變量。
[捕捉列表](參數列表)mutable->返回值類型{//函數體};
[]{}; //最簡單的lambda表達式
- 捕獲列表說明
捕捉列表描述了上下文中那些數據可以被lambda使用,以及使用的方式傳值還是傳引用。- [var]:表示值傳遞方式捕捉變量var
- [=]:表示值傳遞方式捕獲所有父作用域中的變量(包括this)
- [&var]:表示引用傳遞捕捉變量var
- [&]:表示引用傳遞捕捉所有父作用域中的變量(包括this)
- [this]:表示值傳遞方式捕捉當前的this指針
注意:
- 父作用域指包含lambda函數的語句塊
- 語法上捕捉列表可由多個捕捉項組成,并以逗號分割。
比如:[=, &a, &b]:以引用傳遞的方式捕捉變量a和b,值傳遞方式捕捉其他所有變量 [&,a, this]:值傳遞方式捕捉變量a和this,引用方式捕捉其他變量 c. 捕捉列表不允許變量重復傳遞,否則就會導致編譯錯誤。 比如:[=, a]:=已經以值傳遞方式捕捉了所有變量,捕捉a重復 - 在塊作用域以外的lambda函數捕捉列表必須為空。
- 在塊作用域中的lambda函數僅能捕捉父作用域中局部變量,捕捉任何非此作用域或者非局部變量都會導致編譯報錯。(主函數只能捕獲主函數聲明得變量)
int a = 3, b = 4;
[=,&g_a]{return a + 3; }; //驗證4
- lambda表達式之間不能相互賦值,即使看起來類型相同,找不到operator=()。
auto f1 = []{cout << "hello world" << endl; };
auto f2 = []{cout << "hello world" << endl; };
//f1 = f2; // 編譯失敗--->提示找不到operator=()
// 允許使用一個lambda表達式拷貝構造一個新的副本
auto f3(f2);
f3();
// 可以將lambda表達式賦值給相同類型的函數指針
PF = f2;
PF();//執行相應得表達式
// 最簡單的lambda表達式, 該lambda表達式沒有任何意義[]{};// 省略參數列表和返回值類型,返回值類型由編譯器推導為intint a = 3, b = 4;[=]{return a + 3; }; //想要在a的基礎上+3返回。//但是這個lambda表達式沒有用//因為沒有取名字// 省略了返回值類型,無返回值類型//不知道lambda表達式的類型就用auto//[&]以引用的方式捕獲當前主函數的變量 a=3;b=13;//[=]以值得方式進行捕獲 a=3;b=4;auto fun1 = [=](int c)mutable{b = a + c; };fun1(10);cout << a << " " << b << endl;// 各部分都很完善的lambda函數// [=] 以值的方式捕獲所有的變量// [&] 以引用的方式捕獲所有的變量// [=,&b] 對于b變量以引用得方式捕獲,對于其它變量用值的方式auto fun2 = [=, &b](int c)->int{return b += a + c; };cout << fun2(10) << endl;// 復制捕捉x// 以值得方式捕獲x,函數內修改不會影響外部int x = 10;auto add_x = [x](int a) mutable { x *= 2; return a + x; };cout << add_x(10) << endl;return 0;
仿函數與lambda表達式的聯系
函數對象,又稱為仿函數,即可以想函數一樣使用的對象,就是在類中重載了operator()運算符的類對象
class Rate
{
public:Rate(double rate) : _rate(rate){}double operator()(double money, int year){return money * _rate * year;}
private:double _rate;
};
int main()
{// 函數對象double rate = 0.49;Rate r1(rate); //定義一個對象將利率傳進去r1(10000, 2); //對象調用自身的方法,跟函數調用比較像都是 名字()// 仿函數//=捕獲rateauto r2 = [=](double monty, int year)->double{return monty*rate*year; };r2(10000, 2);return 0;
}
函數對象將rate作為其成員變量,在定義對象時給出初始值即可,lambda表達式通過捕獲列表可以直接將該變量捕獲到。
實際在底層編譯器對于lambda表達式的處理方式,完全就是按照函數對象的方式處理的,即:如果定義了一個lambda表達式,編譯器會自動生成一個類,在該類中重載operator()。
lambda表達式的應用
int array[] = { 1, 2, 3, 4, 5 };
for_each(array, array + 5, [](int&c){c *= 2; });
for_each(array, array + 5, [](int c){cout << c<<" "; });
線程庫
#include<thread>
void ThreadFunc(int a)
{cout << "Thread1" << a << endl;
}
class TF
{
public:void operator()(){cout << "Thread3" << endl;}
};int main()
{TF tf;//線程函數尾函數指針thread t1(ThreadFunc, 10);//線程函數為lambda表達式thread t2([]{cout << "Thread2" << endl; });//線程函數為函數對象thread t3(tf);t1.join();t2.join();t3.join();cout << "Main thread!" << endl;system("pause");return 0;
}
線程之間不能互相賦值,也不能拷貝
線程的啟動
C++線程庫通過構造一個線程對象來啟動一個線程,該線程對象中就包含了線程運行時的上下文環境,比如:線程函數、線程棧、線程起始狀態等以及線程ID等,所有操作全部封裝在一起,最后在底層統一傳遞給_beginthreadex() 創建線程函數來實現 (注意_beginthreadex是windows中創建線程的底層c函數)。std::thread()創建一個新的線程可以接受任意的可調對象類型(帶參數或者不帶參數),包括lambda表達式(帶變量捕獲或者不帶),函數,函數對象,以及函數指針。
#include<thread>
void ThreadFunc1(int& x)
{cout << &x << " " << x << endl;x += 10;
}void ThreadFunc2(int*x)
{*x += 10;
}int main()
{int a = 10;//在線程函數中對a修改,不會影響外部實參,因為:線程函數雖然是引用方式,但其實際引用的是線程棧中的拷貝thread t1(ThreadFunc1, a);t1.join();cout << &a <<" "<< a << endl;//地址的拷貝thread t3(ThreadFunc2, &a);t3.join();cout << a << endl;system("pause");return 0;
}
線程的結束
1. join()方式
join():會主動地等待線程的終止。在調用進程中join(),當新的線程終止時,join()會清理相關的資源,然后返回,調用線程再繼續向下執行。由于join()清理了線程的相關資源,thread對象與已銷毀的線程就沒有關系了,因此一個線程的對象每次你只能使用一次join(),當你調用的join()之后joinable()就將返回false了。主線程會阻塞
2. detach()
detach:會從調用線程中分理出新的線程,之后不能再與新線程交互。就像是你和你女朋友分手,那之后你們就不會再有聯系(交互)了,而她的之后消費的各種資源也就不需要你去埋單了(清理資源)。此時調用joinable()必然是返回false。分離的線程會在后臺運行,其所有權和控制權將會交給c++運行庫。同時,C++運行庫保證,當線程退出時,其相關資源的能夠正確的回收
原子性操作
多線程最主要的問題是共享數據帶來的問題(即線程安全)。如果共享數據都是只讀的,那么沒問題,因為只讀操作不會影響到數據,更不會涉及對數據的修改,所以所有線程都會獲得同樣的數據。但是,當一個或多個線程要修改共享數據時,就會產生很多潛在的麻煩。比如:
#include <iostream>
using namespace std;
#include <thread>
unsigned long sum = 0L;
void fun(size_t num)
{for (size_t i = 0; i < num; ++i)sum++;
}
int main()
{cout << "Before joining,sum = " << sum << std::endl;thread t1(fun, 10000000);thread t2(fun, 10000000);//兩個線程每個每回都循環10000000次,每次加1//如果沒問題應該是20000000t1.join();t2.join();cout << "After joining,sum = " << sum << std::endl;system("pause");return 0;
}

通過加鎖保證線程安全
#include <iostream>
using namespace std;
#include <thread>
#include<mutex>
unsigned long sum = 0L;mutex m;
void fun(size_t num)
{for (size_t i = 0; i < num; ++i){m.lock();sum++;m.unlock();}
}
int main()
{size_t begin = clock();cout << "Before joining,sum = " << sum << std::endl;thread t1(fun, 10000000);thread t2(fun, 10000000);//兩個線程每個每回都循環10000000次,每次加1//如果沒問題應該是20000000t1.join();t2.join();cout << "After joining,sum = " << sum << std::endl;size_t end = clock();cout << end - begin << endl; //計算時間system("pause");return 0;
}
加鎖后,能夠保證線程安全,但是耗費的時間就比較多,而且有可能導致死鎖

原子操作
原子操作:一但開始,不能被打斷
對于內置類型
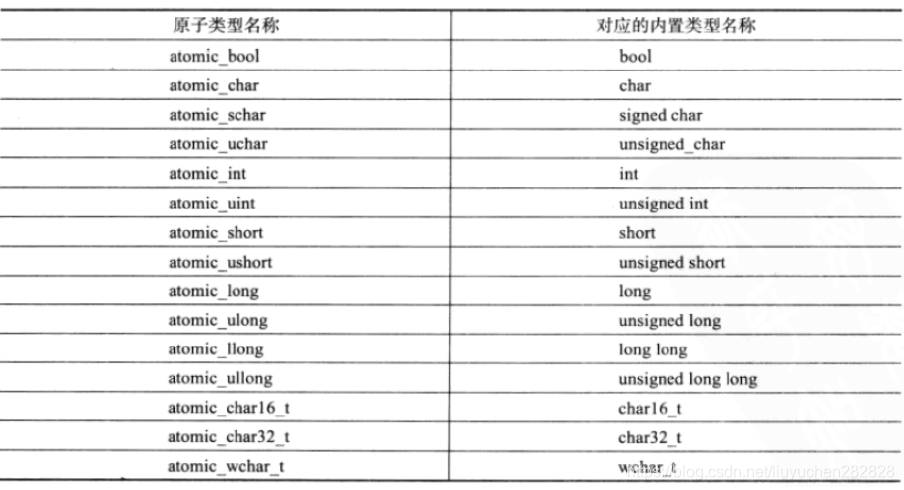
對于自定義類型
使用atomic模板,定義出需要的任意原子類型
atomic<T> t;
注意事項
原子類型通常屬于“資源型”數據,多個線程只能訪問單個原子類型的拷貝,因此在c++11中原子類型只能從其模板參數中進行構造,不允許原子類型進行拷貝構造,移動構造以及operator=等,于是,標準庫已經將atmoic模板類中的拷貝構造,移動構造,賦值運算符的重載默認刪除了
#include <iostream>
using namespace std;
#include <thread>
#include<atomic>//unsigned long sum = 0L;
atomic_long sum{0}; //定義原子類型變量void fun(size_t num)
{for (size_t i = 0; i < num; ++i){sum++;}
}
int main()
{size_t begin = clock();cout << "Before joining,sum = " << sum << std::endl;thread t1(fun, 10000000);thread t2(fun, 10000000);//兩個線程每個每回都循環10000000次,每次加1//如果沒問題應該是20000000t1.join();t2.join();cout << "After joining,sum = " << sum << std::endl;size_t end = clock();cout << end - begin << endl; //計算時間system("pause");return 0;
}

時間更短,也能保證線程安全
)
)

















