
"探索MongoDB的無邊之境:沉浸式數據庫之旅"
歡迎來到MongoDB的精彩世界!在這個博客中,我們將帶您進入一個充滿創新和無限潛力的數據庫領域。無論您是開發者、數據工程師還是技術愛好者,MongoDB都將為您帶來一場令人心動的沉浸式體驗。
從一開始,我們將揭開MongoDB的神秘面紗,告訴您為什么它成為當今數據庫領域的明星。您將發現MongoDB的靈活性和可擴展性如何顛覆傳統數據庫的概念,讓您擺脫約束,以自由自在的方式處理數據。
在這個博客中,我們將帶您深入了解MongoDB的架構和設計原理。您將探索文檔型數據模型的魅力,學習如何利用無模式設計存儲和查詢各種類型的數據。我們還會分享一系列最佳實踐、技巧和性能優化策略,讓您的MongoDB應用發揮出最大的潛力。
不僅如此,我們將通過實際案例和故事,向您展示MongoDB如何在真實世界中發揮作用。您將了解到它如何助力起步公司快速迭代和擴展業務,如何幫助大型企業應對海量數據的挑戰,以及如何在物聯網和人工智能領域掀起革命性的變革。
無論您是MongoDB的新手還是有經驗的專家,這個博客都將成為您掌握MongoDB的絕佳資源。加入我們,追尋MongoDB的無邊之境,開啟一段令人興奮的數據庫之旅吧!
基礎知識
概述
MongoDB
簡介
MongoDB是免費開源的跨平臺NoSQL數據庫,以BSON格式存儲
BSON
BSON是一種類似于JSON的二進制形式的存儲格式,簡稱Binary JSON
它和JSON一樣,支持內嵌的文檔對象和數組對象,但是BSON有JSON沒有的一些數據類型,如Date和BinData類型
BSON有三個特點:輕量性、可遍歷性、高效性
應用場景
適用場景
網站數據:Mongo 非常適合實時的插入,更新與查詢,并具備網站實時數據存儲所需的復制及高度伸縮性
緩存:由于性能很高,Mongo 也適合作為信息基礎設施的緩存層。在系統重啟之后,由Mongo搭建的持久化緩存層可以避免下層的數據源過載
大尺寸、低價值的數據:使用傳統的關系型數據庫存儲一些大尺寸低價值數據時會比較浪費,在此之前,很多時候程序員往往會選擇傳統的文件進行存儲
高伸縮性的場景:Mongo 非常適合由數十或數百臺服務器組成的數據庫,Mongo 的路線圖中已經包含對MapReduce 引擎的內置支持以及集群高可用的解決方案
用于對象及JSON數據的存儲:Mongo的BSON數據格式非常適合文檔化格式的存儲及查詢
具體應用
游戲場景:使用MongoDB存儲游戲用戶信息,用戶的裝備、積分等直接以內嵌文檔的形式存儲,方便查詢、更新
物流場景:使用MongoDB存儲訂單信息,訂單狀態在運送過程中會不斷更新,以MongoDB內嵌數組的形式來存儲,一次查詢就能將訂單所有的變更讀取出來
社交場景:使用MongoDB存儲存儲用戶信息,以及用戶發表的朋友圈信息,通過地理位置索引實現附近的人、地點等功能
物聯網場景:使用MongoDB存儲所有接入的智能設備信息,以及設備匯報的日志信息,并對這些信息進行多維度的分析
直播:使用MongoDB存儲用戶信息、禮物信息等
邏輯結構
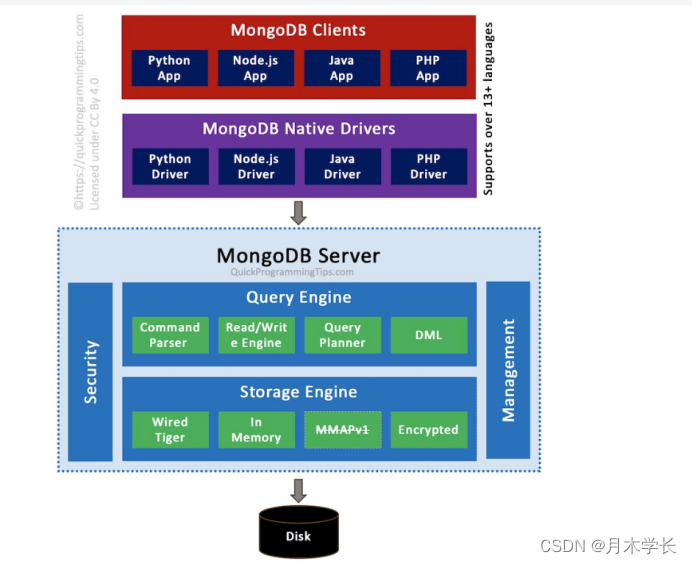
簡介
MongoDB與MySQL中的架構相差不多,底層都使用了可插拔的存儲引擎以滿足用戶的不同需要,用戶可以根據程序的數據特征選擇不同的存儲引擎
在存儲引擎上層的就是MongoDB的數據模型和查詢語言
數據模型
簡介
與SQL數據庫不同,在SQL數據庫中,在插入數據之前必須確定和聲明表的架構
默認情況下,MongoDB的集合不要求其文檔具有相同的架構
結構靈活
單個集合中的文檔不需要具有相同的字段集合,并且集合中的文檔之間的字段數據類型可能不同;
可靈活更改集合中文檔的結構,如添加新字段、刪除現有字段或將字段值更改為新類型,將文檔更新為新結構。
文檔結構【內嵌】
內嵌的方式指的是把相關聯的數據保存在同一個文檔結構之中
MongoDB的文檔結構允許一個字段或者一個數組內的值作為一個嵌套的文檔
文檔結構【引用】
引用方式通過存儲數據引用信息來實現兩個不同文檔之間的關聯,應用程序可以通過解析這些數據引用來訪問相關數據
WiredTiger存儲引擎
簡介
從MongoDB 3.2開始默認的存儲引擎是WiredTiger,3.2版本之前的默認存儲引擎是MMAPv1,MongoDB 4.x版本不再支持MMAPv1存儲引擎
WiredTiger提供了不同粒度的并發控制和壓縮機制,能夠為不同種類的應用提供了最好的性能和存儲率
支持document級別并發操作
WiredTiger對寫入操作使用document級并發控制。因此,多個客戶端可以同時修改集合的不同文檔
對于大多數讀寫操作,WiredTiger使用樂觀并發控制。WiredTiger僅在全局、數據庫和集合級別使用意向鎖
當存儲引擎檢測到兩個操作之間的沖突時,其中一個操作將引發寫入沖突,MongoDB會對用戶透明地重試該操作
快照和檢查點
WiredTiger使用多版本并發控制(MVCC)
在操作開始時,WiredTiger會向操作提供數據的point-in-time快照,快照顯示了數據在內存中的一致性視圖
從3.6版開始,MongoDB將WiredTiger配置為每隔60秒創建檢查點(即將快照數據寫入磁盤)
在早期版本中,MongoDB將檢查點設置為在WiredTiger中每隔60秒或寫入2 GB日志數據時(以先發生的為準)對用戶數據進行檢查
日志
WiredTiger將日志與檢查點結合使用,以確保數據的持久性
WiredTiger日志將保留檢查點之間的所有數據修改
如果MongoDB在兩個檢查點之間退出,它將使用日志重播自上一個檢查點以來修改的所有數據
壓縮
使用WiredTiger存儲引擎,MongoDB會對所有集合和索引進行壓縮,壓縮以犧牲額外的CPU為代價,最大限度地減少了磁盤的使用
默認情況下,WiredTiger對所有集合使用block compression,并對索引使用prefix compression
內存使用
對于WiredTiger,MongoDB利用WiredTiger內部緩存和文件系統緩存
從MongoDB 3.4開始,默認WiredTiger內部緩存大小為以下兩者中的較大值:
50% of (RAM - 1 GB)
256 MB
??????????
In-memory存儲引擎
簡介
從MongoDB 企業版3.2.6版開始,In-Memory存儲引擎是64位版本中廣泛使用(general availability GA)的一部分
除某些元數據和診斷數據外,In-Memory存儲引擎不維護任何磁盤上的數據,包括配置數據,索引,用戶憑據等
In-Memory存儲引擎設置
配置--storageEngine選項值為inMemory;如果使用配置文件,則配置storage.engine
配置--dbpath,如果使用配置文件則配置storage.dbPath。盡管In-Memory存儲引擎不會將數據寫入文件系統,
但它會在--dbpath中維護小型元數據文件和診斷數據以及用于構建大型索引的臨時文件
mongod --storageEngine inMemory --dbpath
并發
In-Memory存儲引擎對于寫入操作使用了document級并發控制
多個客戶端可以同時修改集合的不同文檔
內存使用
默認情況下,In-Memory存儲引擎使用50%的物理RAM減去1GB
如果寫操作的數據超過了指定的內存大小,則MongoDB返回錯誤:
"WT_CACHE_FULL: operation would overflow cache"
要指定新大小,可使用YAML格式配置文件的
事務
從MongoDB 4.2開始,復制集和分片集群上支持事務,其中:
主成員節點使用WiredTiger存儲引擎,同時,輔助成員使用WiredTiger存儲引擎或In-Memory存儲引擎
在MongoDB 4.0中,只有使用WiredTiger存儲引擎的復制集才支持事務
??????????
安裝
yum安裝
安裝
進入/etc/yum.repos.d目錄,創建文件mongodb-org-5.0.repo
cd /etc/yum.repos.dvim mongodb-org-5.0.repo[mongodb-org]
name=MongoDB Repository
baseurl=http://mirrors.aliyun.com/mongodb/yum/redhat/7Server/mongodb-org/5.0/x86_64/
gpgcheck=0
enabled=1
更新yum
yum update
安裝
yum -y install mongodb-org
修改配置文件
查看mongo的安裝位置
whereis mongod
修改配置文件
vim /etc/mongod.conf
bindIp: 172.0.0.1 改為 bindIp: 0.0.0.0
mongdb的使用
查看
systemctl status mongod.service
啟動
systemctl start mongod.service
停止
systemctl stop mongod.service
重啟
systemctl restart mongod.service查看
systemctl status mongod.service
設置開機自啟動
systemctl enable mongod.service
mongo shelld的使用
啟動
cd /usr/bin./mongo
啟動【指定主機和端口】
cd /usr/bin./mongo--host=主機IP --port=端口
??????????
docker安裝
安裝
拉取鏡像
docker pull mongo:4.4.14-focal
創建容器
docker run -itd --name mongo -p 8036:27017 ?mongo:4.4.14-focal --auth
配置管理員
進入容器
docker exec -it mongo bash
進入終端
mongo
進入admin數據庫
use admin
創建管理員賬戶
db.createUser({ user: "root", pwd: "Jiakewei521", roles: [{ role: "root", db: "admin" }] })
驗證用戶添加是否成功
db.auth("root", "Jiakewei521");
如果返回1,則表示成功
進入終端
進入容器
docker exec -it mongo bash
進入終端
mongo
以管理員身份登錄
use adminswitched to db admindb.auth("root","Jiakewei521")安全認證
MongoDB安全認證
簡介
MongoDB 默認是沒有賬號的,可以直接連接,無須身份驗證,但實際項目中肯定是要權限驗證的,否則后果不堪設想
認證相關操作
docker以auth方式創建MongoDB容器
docker run -itd --name mongo5 -p 27017:27017 mongo:xxx --auth
備份數據
mongodump -h 127.0.0.1:27017 -d mydb -o /usr/local
恢復數據(在用戶認證之后)
mongorestore -h localhost -u root -p 123456 --db mydb /dump/mydb --authenticationDatabase admin
????????
基于角色的訪問控制相關知識
用戶命令
修改密碼
db.changeUserPassword( '賬號' , '密碼' );
添加角色
db.grantRolesToUser('用戶名',[{ role:'角色名', db:'數據庫名'}])
刪除用戶
db.dropUser("用戶名")
驗證用戶【返回 1 說明認證成功】
db.auth("賬號","密碼")
內置角色
root ???超級賬號,超級權限
read ???允許用戶讀取指定數據庫
readwrite ???允許用戶讀寫指定數據庫
dbAdmin ???可以讀取任何數據庫并對庫進行清理、修改、壓縮,獲取統計信息、執行檢查等操作
userAdmin ???可以在指定數據庫里創建、刪除和管理用戶
readAnyDatabase ???可以讀取任何數據庫中的數據,除了數據庫config和local之外
readwriteAnyDatabase ???可以讀寫任何數據庫中的數據,除了數據庫config和local之外
userAdminAnyDatabase ???可以在指定的數據庫中創建和修改用戶,除了數據庫config和local之外
dbAdminAnyDatabase ???可以讀取任何數據庫并對庫進行清理、修改、壓縮,獲取統計信息、執行檢查等操作,除了數據庫config和local之外
backup ???備份數據權限
restore ???從備份中恢復數據的權限
mongdb中用戶默認對應的角色
數據庫用戶 ???read、readwrite
數據庫管理角色 ???dbAdmin、userAdmin
所有數據庫角色 ???readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、 dbAdminAnyDatabase
備份恢復角色 ???backup、restore
超級用戶角色 ???root
?????????
管理員
創建管理員
MongoDB 服務端開啟安全檢查之前,至少需要有一個管理員賬號,admin 數據庫中的用戶都被視為管理員
如果 admin 庫沒有任何用戶的話,即使在其他數據庫中創建了用戶,啟用身份驗證,
默認的連接方式依然會有超級權限,即仍然可以不驗證賬號密碼照樣能進行 CRUD,安全認證相當于無效
進入容器
docker exec -it mongo bash
進入終端
mongo
進入admin數據庫
use admin
創建管理員賬戶
db.createUser({ user: "root", pwd: "Jiakewei521", roles: [{ role: "root", db: "admin" }] })
驗證用戶添加是否成功
db.auth("root", "Jiakewei521");
如果返回1,則表示成功
管理員登錄
客戶端管理員以root用戶登錄,安全認證通過后,擁有對所有數據庫的所有權限
進入容器
docker exec -it mongo bash
進入終端
mongo
以管理員身份登錄
use admin
switched to db admin
db.auth("root","Jiakewei521")
????????
普通用戶
創建普通用戶
創建mydb數據庫并創建兩個用戶,zhangsan 擁有讀寫權限,lisi 擁有只讀權限測試這兩個賬戶的權限。以超級管理員登錄測試權限
> use mydb
switched to db mydb
> ?db.c1.insert({name:"testdb1"})
WriteResult({ "nInserted" : 1 })
> db.c2.insert({name:"testdb1"})
WriteResult({ "nInserted" : 1 })
> show tables
c1
c2
> db.c1.find()
{ "_id" : ObjectId("62a00e5c1eb2c6ab85dd5eec"), "name" : "testdb1" }
> db.c1.find({})
{ "_id" : ObjectId("62a00e5c1eb2c6ab85dd5eec"), "name" : "testdb1" }
> show dbs
admin ??0.000GB
config ??0.000GB
local ??0.000GB
mydb ???0.001GB
>
普通用戶登錄
普通用戶現在仍然像以前一樣進行登錄,如下所示直接登錄進入 mydb數據庫中,登錄是成功的,只是登錄后日志少了很多東西,
而且執行 show dbs 命令,以及 show tables 等命令都是失敗的,即使沒有被安全認證的數據庫,用戶同樣操作不了,
這都是因為權限不足,一句話:用戶只能在自己權限范圍內的數據庫中進行操作
> db.auth("zhangsan","123456")
1
> show dbs
mydb 0.001GB
> show tables
c1
c2 ???????
????????
常用命令
數據庫命令
查看數據庫
show dbs;
切換數據庫 如果沒有對應的數據庫則創建
use 數據庫名;
創建集合
db.createCollection("集合名")
查看集合
showtables;
show collections;
刪除集合
db.集合名.drop();
刪除當前數據庫
db.dropDatabase();
????????
添加文檔
注意
添加單個文檔,如果集合不存在,會創建一個集合
如果不指定id, MongoDB會使用ObjectId的value作為id
添加單個文檔
db.inventory.insertOne(
{ item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } })
添加多個文檔
db.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], size: { h: 14, w: 21, uom: "cm" } },
{ item: "mat", qty: 85, tags: ["gray"], size: { h: 27.9, w: 35.5, uom: "cm" } },
{ item: "mousepad", qty: 25, tags: ["gel", "blue"], size: { h: 19, w: 22.85, uom: "cm" }}]) ???更新文檔
測試數據
db.inventory.insertMany( [
{ item: "canvas", qty: 100, size: { h: 28, w: 35.5, uom: "cm" }, status: "A" },
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "mat", qty: 85, size: { h: 27.9, w: 35.5, uom: "cm" }, status: "A" },
{ item: "mousepad", qty: 25, size: { h: 19, w: 22.85, uom: "cm" }, status: "P" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "P" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" },
{ item: "sketchbook", qty: 80, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "sketch pad", qty: 95, size: { h: 22.85, w: 30.5, uom: "cm" }, status: "A" }] );
操作1
更新item值為“paper”的第一個文檔 將它的size.uom設置為“cm”,status值設置為"P"
并且把lastModified字段更新為當前時間,如果該字段不存在,則生成一個
db.inventory.updateOne(
{ item: "paper" },
{$set: { "size.uom": "cm", status: "P" },
$currentDate: { lastModified: true }}
)
操作2
更新qty屬性值小于50的文檔 將它的size.uom設置為“in”,status值設置為"P"
并且把lastModified字段更新為當前時間,如果該字段不存在,則生成一個
把item屬性為“paper”的文檔替換成下面的內容
db.inventory.replaceOne(
{ item: "paper" },{ item: "paper", instock: [ { warehouse: "A", qty: 60 }, { warehouse: "B", qty: 40 } ] })刪除文檔
刪除集合所有文檔
db.inventory.deleteMany({})
刪除指定條件的文檔
db.inventory.deleteMany({ status : "A" })
最多刪除1個指定條件的文檔
db.inventory.deleteOne( { status: "D" } )查詢文檔
測試數據
db.inventory.insertMany( [
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);
查詢集合所有文檔
db.inventory.find({})
查詢指定內容的文檔【size內容順序要匹配】
db.inventory.find( { size: { h: 14, w: 21, uom: "cm" } } )
匹配size中uom屬性為“in”的文檔
db.inventory.find( { "size.uom": "in" } )
匹配size中h屬性值小于15的文檔
db.inventory.find( { "size.h": { $lt: 15 } } )
匹配h屬性小于15并且uom屬性為“in”,并且“status”屬性為"D"的文檔
db.inventory.find( { "size.h": { $lt: 15 }, "size.uom": "in", status: "D" } )聚合命令
聚合操作
聚合操作
通過聚合操作可以處理多個文檔,并返回計算后的結果:對多個文檔進行分組/對分組的文檔執行操作并返回單個結果/分析數據變化
聚合管道
分別由多個階段來處理文檔,每個階段的輸出是下個階段的輸入,返回的是一組文檔的處理結果
例如,total、average、maxmium、minimium
測試數據
db.orders.insertMany([
{ _id: 0, name: "Pepperoni", size: "small", price: 19,quantity: 10, date: ISODate( "2030-03-13T08:14:30Z" ) },
{ _id: 1, name: "Pepperoni", size: "medium", price: 20,quantity: 20, date : ISODate( "2030-03-13T09:13:24Z" ) },
{ _id: 2, name: "Pepperoni", size: "large", price: 21,quantity: 30, date : ISODate( "2030-03-17T09:22:12Z" ) },
{ _id: 3, name: "Cheese", size: "small", price: 12,quantity: 15, date : ISODate( "2030-03-13T11:21:39.736Z" ) },
{ _id: 4, name: "Cheese", size: "medium", price: 13,quantity:50, date : ISODate( "2031-01-12T21:23:13.331Z" ) },
{ _id: 5, name: "Cheese", size: "large", price: 14,quantity: 10, date : ISODate( "2031-01-12T05:08:13Z" ) },
{ _id: 6, name: "Vegan", size: "small", price: 17,quantity: 10, date : ISODate( "2030-01-13T05:08:13Z" ) },
{ _id: 7, name: "Vegan", size: "medium", price: 18,quantity: 10, date : ISODate( "2030-01-13T05:10:13Z" ) }
])
示例1
計算尺寸為medium的訂單中,每種類型的訂單數量
db.orders.aggregate( [
// Stage 1: 匹配size:"medium"的文檔
{
$match: { size: "medium" }
},
// Stage 2: 根據name統計過濾后的文檔,并把"quantity"值相加
{
$group: { _id: "$name", totalQuantity: { $sum: "$quantity" } }
}
] )
示例2
更復雜的例子
db.orders.aggregate( [
// Stage 1: 根據日期范圍過濾
{
$match:
{
"date": { $gte: new ISODate( "2030-01-01" ), $lt: new ISODate( "2030-01-30" ) }
}
},
// Stage 2: 對過濾后文檔以日期為條件進行分組并計算
{
$group:
{
_id: { $dateToString: { format: "%Y-%m-%d", date: "$date" } },
totalOrderValue: { $sum: { $multiply: [ "$price", "$quantity" ] } },
averageOrderQuantity: { $avg: "$quantity" }
}
},
// Stage 3: 按照訂單價值倒序排列文檔
{
$sort: { totalOrderValue: -1 }
}
] ) ?
??????????
聚合管道順序優化
聚合管道順序優化
聚合管道在執行的過程中有一個優化的階段,以提高性能
優化前
$addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: {
name: "Joe Schmoe",
maxTime: { $lt: 20 },
minTime: { $gt: 5 },
avgTime: { $gt: 7 }
} }
優化后
優化思路:優化器把$match階段分成了4個獨立的過濾器,盡可能把過濾器放在$project操作前面,優化后的聚合管道如下
{ $match: { name: "Joe Schmoe" } },
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: { avgTime: { $gt: 7 } } }
????????????
索引命令
索引
簡介
索引是一種單獨的、物理的對數據庫表中一列或多列的值進行排序的一種存儲結構
索引是某個表中一列或若干列值的集合和相應的指向表中物理標識這些值的數據頁的邏輯指針清單
作用
相當于圖書的目錄,可以根據目錄中的頁碼快速找到所需的內容
提高數據庫的查詢效率,沒有索引的話,查詢會進行全表掃描,數據量大時嚴重降低了查詢效率
??????????
索引管理
獲取索引
db.collection.getIndexes()
獲取索引數量
db.collection.totalIndexSize()
重建索引
db.collection.reIndex()
刪除索引
注意: _id 對應的索引是刪除不了的
db.collection.dropIndex("INDEX-NAME")db.collection.dropIndexes() ???????????單鍵索引
簡介
MongoDB默認所有的集合在_id字段上有一個索引
創建索引
注意:1代表升序,-1代表降序
創建索引:db.test.createIndex( { key字段: 1 } )
創建索引【有內嵌字段】:db.test.createIndex( { "key字段.子key字段": 1 } )
創建復合索引:db.test.createIndex( { "key字段.子key字段": 1 ,"key字段.子key字段": 1...} )
創建復合
示例
示例數據
db.test.inseartOne({
"_id": 123,
"score": 356,
"location": { province: "Hebei", city: "Tangshan" }
})
創建索引
db.test.createIndex( { score: 1 } )
創建內嵌字段的索引
db.test.createIndex( { "location.province": 1 } )
創建復合索引
db.test.createIndex( {score: 1, "location.province": 1 } )多鍵索引
簡介
多鍵索引用于為數組中的元素創建索引
示例
測試數據
[{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] },
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] },
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] },
{ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] },
{ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ] }]
創建多鍵索引
db.inventory.createIndex( { ratings: 1 } )
原理解釋:
MongoDB使用多鍵索引查找在“ratings”數組中有“5”的文檔,
然后,MongoDB檢索這些文檔并篩選“ratings”數組等于查詢數組“[5,9]”的文檔
地理空間索引
地理空間索引
針對地理空間坐標數據創建索引。2dsphere索引用于存儲和查找球面上的點,2d索引用于存儲和查找平面上的點
db.company.insert(
{
loc : { type: "Point", coordinates: [ 116.502451, 40.014176 ] },
name: "軍博地鐵",
category : "Parks"
}
)
?
db.company.createIndex( { loc : "2dsphere" } )
?
db.company.find({
"loc" : {
"$geoWithin" : {
"$center":[[116.482451,39.914176],0.05]
}
}
})
?
db.places.insert({"name":"aa","addr":[32,32]})
db.places.insert({"name":"bb","addr":[30,22]})
db.places.insert({"name":"cc","addr":[28,21]})
db.places.insert({"name":"dd","addr":[34,26]})
db.places.insert({"name":"ee","addr":[34,27]})
db.places.insert({"name":"ff","addr":[39,28]})
?
db.places.find({})
db.places.createIndex({"addr":"2d"})
db.places.find({"addr":{"$within":{"$box":[[0,0],[30,30]]}}})全文索引
全文索引
MongoDB提供了針對string內容的文本查詢,Text Index支持任意屬性值為string或string數組元素的索引查詢
注意:一個集合僅支持最多一個Text Index,中文分詞不理想推薦ES
?
db.fullText.insert({name:"aa",description:"no pains,no gains"})
db.fullText.insert({name:"ab",description:"pay pains,get gains"})
db.fullText.insert({name:"ac",description:"a friend in need,a friend in deed"})
創建索引并指定語言
db.fullText.createIndex(
{ description : "text" },
{ default_language: "english" }
)db.fullText.find({"$text": {"$search": "pains"}})
全文索引名稱
db.collection.createIndex(
{
content: "text",
"users.comments": "text",
"users.profiles": "text"
}
)
生成的默認索引名:content_text_users.comments_text_users.profiles_text
指定名稱
db.collection.createIndex(
{
content: "text",
"users.comments": "text",
"users.profiles": "text"
},
{
name: "MyTextIndex"
}
)
使用指定名稱刪除索引
db.collection.dropIndex("MyTextIndex")
??????????
哈希索引
哈希索引
針對屬性的哈希值進行索引查詢,當要使用Hashed index時,MongoDB能夠自動的計算hash值,
無需程序計算hash值。注:hash index僅支持等于查詢,不支持范圍查詢
?
db.collection.createIndex({"field": "hashed"})
創建復合hash索引,4.4以后的版本
db.collection.createIndex( { "fieldA" : 1, "fieldB" : "hashed", "fieldC" : -1 } )



)





(VP))





】)


