論文地址:https://arxiv.org/abs/2307.08621
目錄
?Abstract
一.Introduction
二.Retentive Networks
2.1Retention?
2.2Gated Multi-Scale Retention
2.3Overall Architecture of Retention Networks
2.4Relation to and Differences from Previous Methods
三.Experiments
3.1Setup
3.2Comparisons with Transformer
3.3Training Cost
3.4Inference Cost
3.5Comparison with Transformer Variants
3.6Ablation Studies
四.Conclusion
五.Innovation Point

?Abstract
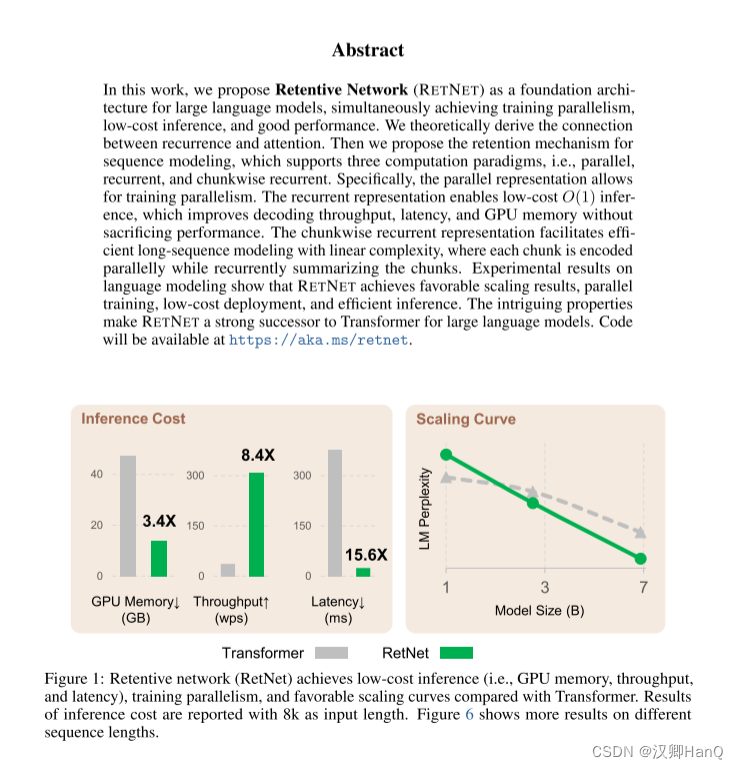
- 翻譯
????????在這項工作中,我們提出了保留網絡(RETNET)作為大型語言模型的基礎架構,同時實現訓練并行性、低成本推理和良好性能。我們從理論上推導了循環和注意力之間的關系。然后,我們為序列建模提出了保留機制,支持三種計算范式,即并行、遞歸和分塊遞歸。具體而言,并行表示允許進行訓練并行性。遞歸表示使得低成本的O(1)推理成為可能,這提高了解碼吞吐量、延遲和GPU內存,而不犧牲性能。分塊遞歸表示有助于使用線性復雜性進行高效的長序列建模,其中每個分塊在并行編碼的同時遞歸地總結這些分塊。在語言建模的實驗結果表明,RETNET取得了有利的擴展結果,實現了并行訓練、低成本部署和高效推理。這些引人注目的特性使RETNET成為大型語言模型的Transformer的強有力的繼任者。
- 精讀?
? ? ? ? RetNet彌補神經網絡中并行性差,推理成本高和性能較差的缺點,通過推導NN中的循環與Attention之間的關系提出保留機制,以支持
? ? ? ? 1.并行:允許訓練并行進行
? ? ? ? 2.遞歸:interface成本為o(1),在不犧牲性能的前提下,提高decoder吞吐量,延遲和降低GPU內存
? ? ? ? 3.分塊遞歸:有助于使用線性復雜性口模型高效的長建模
????????三種計算范式
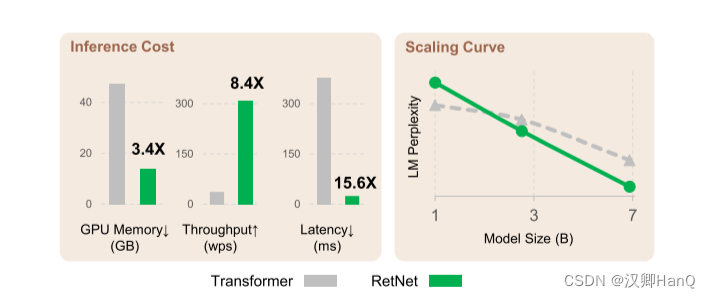
? ? ? ? 通過上述改進,RetNet較Transformer相比,在8k的輸入序列長度,其顯存下降3.4倍,吞吐量提高了8.4倍,延遲下降了15.6倍。當隨著數據下降,模型LM Perplexity比Transformer更低
求通俗解釋NLP里的perplexity是什么? - 知乎
一.Introduction

- 翻譯
????????Transformer已成為大型語言模型的事實標準架構,最初是為了克服遞歸模型的序列訓練問題而提出的。然而,Transformer的訓練并行性是以低效的推理為代價的,這是因為每個步驟的O(N)復雜度和受內存限制的鍵值緩存,這使得Transformer在部署方面不太友好。不斷增長的序列長度會增加GPU內存消耗,同時也會增加延遲,降低推理速度。
????????下一代架構的開發仍在繼續,旨在保持訓練并行性和transformer 的競爭性能,同時有高效的 O(1)推理。同時實現上述目標具有挑戰性,即圖 2 所示的所謂的“不可能的三角形”。
? ? ? ??有三個主要的研究方向。首先,線性化注意力近似標準注意力分數exp(q · k)與核?(q) · ?(k),以便將自回歸推理重寫為循環形式。然而,這種模型的建模能力和性能都不及Transformer,從而阻礙了該方法的普及。第二個方向回歸到遞歸模型以實現高效推理,但會犧牲訓練并行性。作為補救,使用元素級操作符進行加速,但這會損害表示能力和性能。第三個研究方向探索將注意力替換為其他機制,如S4以及其變體。然而,之前的研究都無法突破不可能的三角形,因此與Transformer相比沒有明確的勝者。
????????在這項工作中,我們提出了保留網絡(RetNet),同時實現了低成本推理、高效的長序列建模、與Transformer相媲美的性能以及并行模型訓練。具體而言,我們引入了多尺度的保留機制來替代多頭注意力,該機制具有并行、遞歸和分塊遞歸表示三種計算范式。首先,通過并行表示,我們實現了充分利用GPU設備的訓練并行性。其次,遞歸表示使得在內存和計算方面都能實現高效的O(1)推理。部署成本和延遲得以顯著降低,此外,實現過程大大簡化,無需使用鍵值緩存技巧。第三,分塊遞歸表示能夠進行高效的長序列建模。我們通過并行編碼每個局部塊來提高計算速度,同時通過遞歸編碼全局塊來節省GPU內存。
????????我們進行了大量實驗,將RetNet與Transformer及其變體進行了比較。在語言建模的實驗結果中,RetNet在規模曲線和上下文學習方面始終具有競爭力。此外,RetNet的推理成本與序列長度無關。對于一個7B模型和8k序列長度,RetNet的解碼速度比使用鍵值緩存的Transformer快8.4倍,并節省了70%的內存。在訓練過程中,RetNet的內存節省和加速效果也比標準Transformer以及高度優化的FlashAttention [DFE+22]都要好,分別達到25-50%和7倍。此外,RetNet的推理延遲不受批量大小的影響,可以實現巨大的吞吐量。這些引人注目的特性使得RetNet成為大型語言模型的Transformer的有力繼任者。
- 精讀?
????????????????????????????????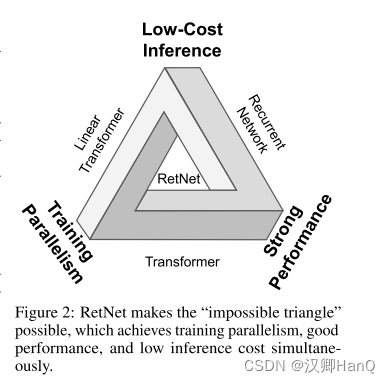
? ? ? ? 在神經網絡上,有一個不可能三角,即低成本推理,并行性和強大的擴展能力,以往的模型架構只能滿足三者中的其二。例如Transformer其并行處理機制是以低效推理為代價的,每個步驟的復雜度為O(N);Transformer是內存密集型模型,序列越長,占用的內存越多。
? ? ? ? 然而,RetNet打破了這個不可能三角
? ? ? ? RetNet引入多尺度保留Retentive代替自注意力機制,通過Retentive中三種計算范式來實現不可能三角:
? ? ? ? 1.并行:賦予訓練并行性以充分利用GPU設備。
? ? ? ? 2.循環:在內存和計算方面實現interface O(1) 在沒有鍵值緩沖下,顯著降低部署成本和延遲。
? ? ? ? 3.分塊遞歸:對每個局部模塊并行編碼提高計算速度,同時對全局進行遞歸編碼以節省GPU內存
二.Retentive Networks

- 翻譯
????????Retentive network (RetNet)由 L 個相同的塊堆疊而成,其布局與 Transformer [VSP+17]類似(即剩余連接和 pre-LayerNorm)。每個RetNet 塊包含兩個模塊:多尺度保持(MSR)模塊和前饋網絡(FFN)模塊。我們將在下面的章節中介紹MSR模塊。給定一個輸入序列x = x1···x|x|,RetNet 以自回歸的方式對序列進行編碼。輸入向量{xi}i=1 |x|首先被打包成X0 = [x1,···,x|x|]∈R|x×dmodel,其中dmodel 為隱維。然后我們計算上下文化的向量表示
2.1Retention?


- 翻譯
????????在本節中,我們介紹了一種具有遞歸和并行性雙重形式的保留機制。因此,我們可以以并行方式訓練模型,同時進行遞歸地推理。給定輸入X ∈ R|x|×dmodel,我們將其投影到一維函數v(n) = Xn · wV。考慮一個序列建模問題,通過狀態sn將v(n)映射到o(n)。為簡單起見,記vn和on分別表示v(n)和o(n)。我們以遞歸方式表達這種映射:
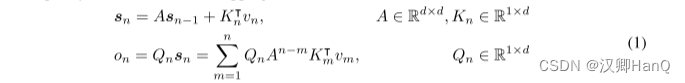
我們在這里映射vn對狀態向量sn,然后實現線性變換,對序列信息進行遞歸編碼。
接下來,我們做投影Qn, kn 內容感知:

?我們對矩陣A進行對角化,得到A = Λ(γeiθ)Λ?1,其中γ,θ ∈ Rd。然后我們得到An?m = Λ(γeiθ)n?mΛ?1。通過將Λ吸收到WQ和WK中,我們可以將方程(1)重新寫成:
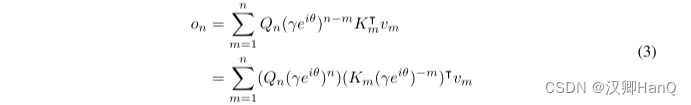
?其中,Qn, Km稱為xPos [SDP+22],即為Transformer 提出的相對位置嵌入。進一步將γ化簡為標量,式(3)為:

?其中?為共軛轉置,該公式很容易在訓練中并行化。
綜上所述,我們從(1)循環建模開始,直至推導(4)的并行表達式.我們將原始映射v(n)->o(n)視為向量,得到retention機制如下:
?
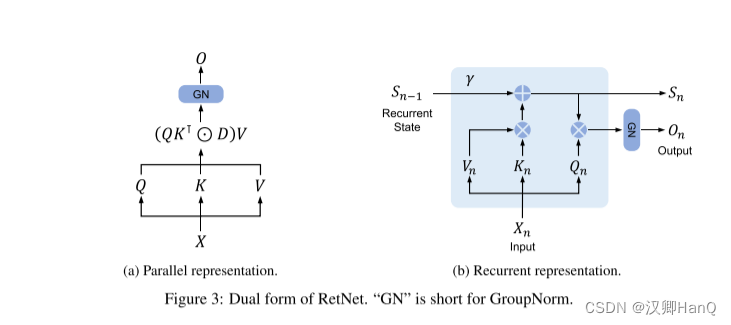
retention的并行表示 如圖3a所示,保留層被定義為:
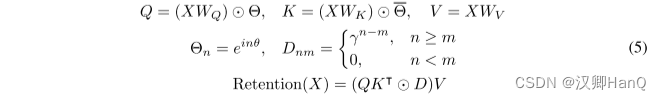
其中,θ^-是θ的共軛復數,D ∈ R|x|×|x| 將因果屏蔽和相對距離的指數衰減結合為一個矩陣。類似于自注意力,這種并行表示使我們能夠有效地使用GPU訓練模型。
?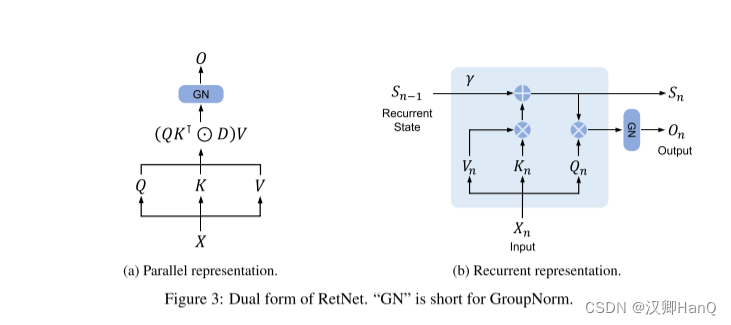
如圖3b所示,所提出的機制也可以寫成遞歸神經網絡(rnn),這有利于推理。對于第n次時間步,我們遞歸地得到輸出為:
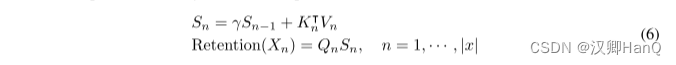
式中,Q、K、V、γ與式(5)相同。
并行表示和循環表示的混合形式可以加速訓練,特別是對長序列的訓練。我們把輸入序列分成塊。在每個 chunk內,我們按照并行表示(式(5))進行計算。而跨塊信息則按照循環表示進行傳遞(式(6))。具體來說,設 B表示塊長度。我們通過以下方法計算第 i 塊的保留輸出:
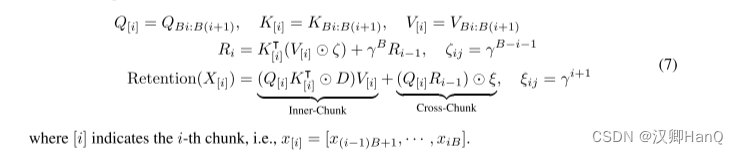
- 精讀
2.2Gated Multi-Scale Retention

- 翻譯
????????在每個層中,我們使用h = dmodel/d 的保留頭(retention heads),其中d是頭的維度。這些頭使用不同的參數矩陣WQ、WK、WV ∈ Rd×d。此外,多尺度保留(MSR)為每個頭分配不同的γ。為簡單起見,我們在不同層之間設置相同的γ,并保持其不變。此外,我們添加了一個swish門(swish gate)[HG16,RZL17]以增加保留層的非線性。形式上,給定輸入X,我們將層定義為:
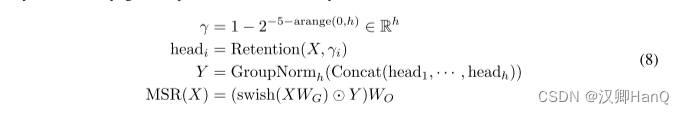
?????????其中WG, WO∈Rdmodel×dmodel 是可學習參數,GroupNorm [WH18]對每個頭的輸出進行歸一化,遵循在[SPP+19]。注意,頭部使用多個γ 尺度,這導致不同的方差統計。所以我們分別歸一化頭部的輸出。
????????我們利用 GroupNorm的尺度不變性質來提高保留層的數值精度。具體而言,在GroupNorm中乘以一個標量值不會影響輸出和反向梯度,即GroupNorm(α ? headi) = GroupNorm(headi)。我們在公式(5)中實現了三個歸一化因子。首先,我們將QK?歸一化為QK?/ √ d。其次,我們用D?nm = Dnm / √Pn i=1 Dni代替D。第三,設R表示保留分數,即R = QK? ⊙ D,我們將其歸一化為R?nm = Rnm /max(| Pn i=1 Rni|,1)。然后保留輸出變為Retention(X) = ?RV。上述技巧不會影響最終結果,同時穩定了前向和后向傳遞的數值流動,這是由于尺度不變特性。
- 精讀
2.3Overall Architecture of Retention Networks
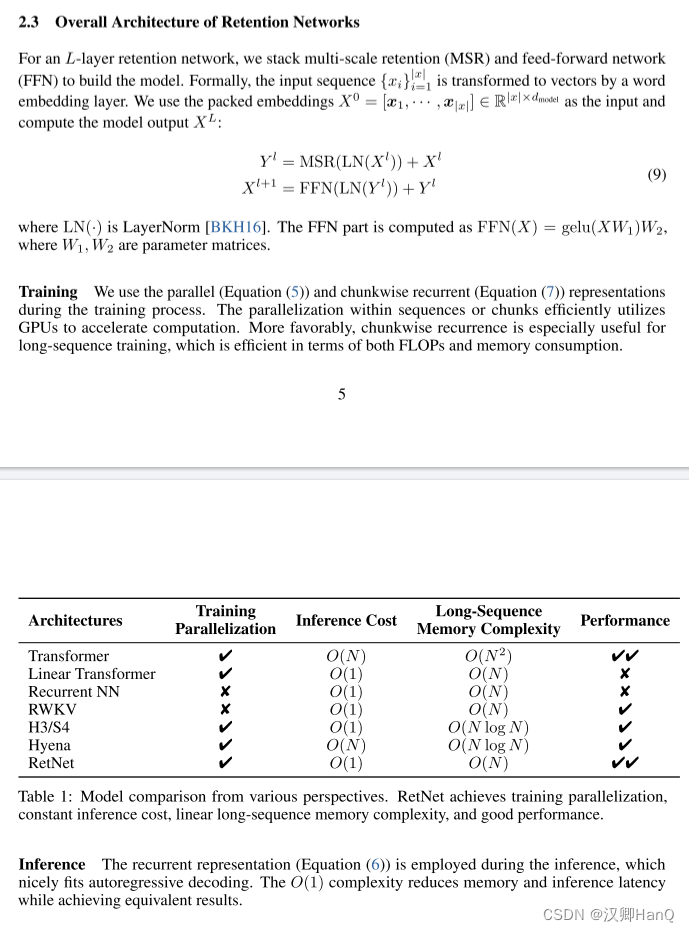
- 翻譯
????????對于一個L層的保留網絡,我們堆疊多尺度保留(MSR)和前饋網絡(FFN)來構建模型。形式上,輸入序列{xi}|x| i=1通過一個詞嵌入層轉化為向量。我們使用打包的嵌入X0 = [x1, · · · , x|x|] ∈ R|x|×dmodel 計算模型輸出XL:
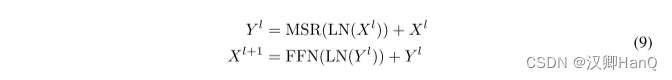
????????其中,LN為LayerNorm,FNN計算公式為FFN(X) = gelu(XW1) w2,其中W1, w2 是參數矩陣。
????????訓練過程中我們使用并行表示(公式(5))和分塊遞歸表示(公式(7))。在序列或分塊內部進行的并行計算充分利用了GPU來加速計算。而且,分塊遞歸特別適用于長序列的訓練,這在FLOP和內存消耗方面都是高效的。
????????推理過程中我們使用遞歸表示(公式(6)),這非常適用于自回歸解碼。O(1)的復雜度降低了內存占用和推理延遲,同時實現了等效的結果。
- 精讀
2.4Relation to and Differences from Previous Methods


- 翻譯
????????表1從各個角度比較了RetNet與以前的方法。比較結果呼應了圖2中呈現的“不可能三角形”。此外,由于分塊遞歸表示,RetNet對于長序列具有線性的內存復雜度。我們還總結了與具體方法的比較如下:
? ? ? ? Transformer:The parallel representation of retention與Transformers [VSP+17]有著相似的思想。最相關的Transformer變體是Lex Transformer [SDP+22],它實現了xPos作為位置嵌入。如公式(3)所述,保留的推導與xPos是相符的。與注意力相比,保留去除了softmax,并啟用了遞歸公式,這在推理方面有著顯著的優勢。
? ? ? ? S4:與公式(2)不同,如果Qn和Kn不考慮內容,該公式可以退化為S4。
? ? ? ? Linear Attention:這些變體通常使用各種核函數
?????????????????????????????????????????????????????
?????來替代softmax函數。然而,線性注意力在有效編碼位置信息方面存在困難,使模型的性能較差。此外,我們重新審視了序列建模,而不是旨在近似softmax。
? ? ? ? AFT/RWKV:無注意力Transformer(AFT)將點積注意力簡化為逐元素操作,并將softmax移到鍵向量中。RWKV使用指數衰減替換了AFT的位置嵌入,并在訓練和推理過程中遞歸運行模型。相比之下,保留保留了高維狀態以編碼序列信息,這有助于表達能力和更好的性能。
? ? ? ? xPos/RoPE:與為Transformers提出的相對位置嵌入方法相比,公式(3)呈現了與xPos [SDP+22]和RoPE [SLP+21]類似的公式。
? ? ? ? Sub-LayerNorm:如公式(8)所示,保留層使用Sub-LayerNorm [WMH+22]來對輸出進行歸一化。由于多尺度建模導致頭部之間的方差不同,我們用GroupNorm替換了原始的LayerNorm。
- 精讀
三.Experiments

????????我們進行語言建模實驗來評估RetNet。我們對提議進行評估具有各種基準的體系結構,例如,語言建模性能,以及零/少命中率學習下游的任務。此外,在訓練和推理方面,我們比較速度和記憶力消耗和延遲。
3.1Setup

 ?
?
- 翻譯
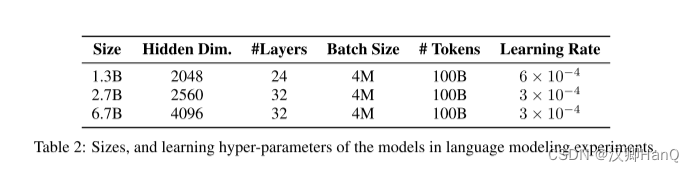
????????參數分配:我們重新分配了MSR和FFN中的參數,以進行公平比較。在這里,我們用d來表示dmodel。在Transformers中,自注意力層中大約有4d2個參數,其中WQ、WK、WV、WO ∈ Rd×d,以及FFN層中有8d2個參數,其中中間維度為4d。相比之下,RetNet在保留層中有8d2個參數,其中WQ、WK ∈ Rd×d,WG、WV ∈ Rd×2d,WO ∈ R2d×d。請注意,V的頭維度是Q和K的兩倍。擴展的維度通過WO投影回d。為了保持與Transformer相同的參數數量,RetNet中的FFN中間維度為2d。同時,我們在實驗中將頭維度設置為256,即查詢和鍵為256,值為512。為了公平比較,我們在不同的模型尺寸中保持γ相同,其中γ = 1 ? elinspace(log 1/32,log 1/512,h) ∈ Rh,而不是公式(8)中的默認值。
????????語言模型訓練:如表2所示,我們從頭開始訓練不同規模的語言模型(即1.3B、2.7B和6.7B)。訓練語料庫是The Pile [GBB+20]、C4 [DMI+21]和The Stack [KLBA+22]的精選匯編。我們在序列的開頭添加了<bos>標記以表示序列的開始。訓練的批次大小為4M個標記,最大長度為2048。我們用100B個標記(即25k步)來訓練模型。我們使用AdamW [LH19]優化器,其中β1 = 0.9,β2 = 0.98,并且權重衰減設置為0.05。預熱步數為375,采用線性學習率衰減。參數的初始化遵循DeepNet [WMD+22]以確保訓練穩定。實現基于TorchScale [MWH+22]。我們使用512個AMD MI200 GPU來訓練模型。
- 精讀
3.2Comparisons with Transformer

 ?
?
 ?
?
- 翻譯
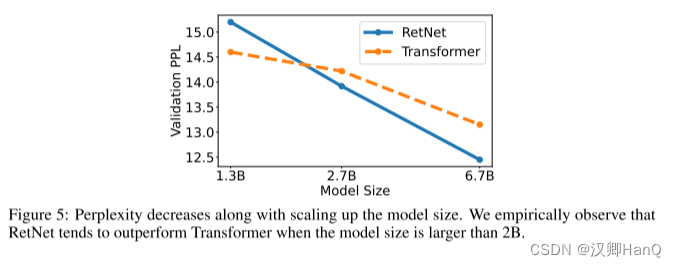
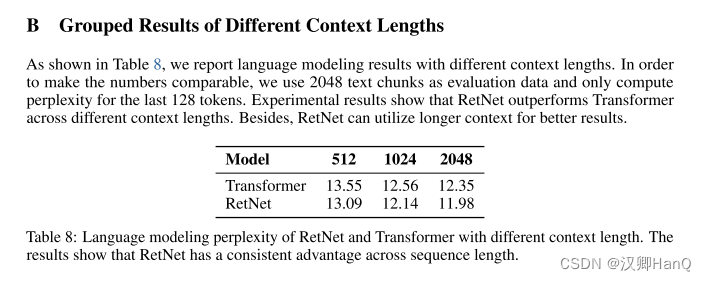
????????語言模型:如圖5所示,我們在驗證集上報告了基于Transformer和RetNet的語言模型的困惑度。我們展示了三個模型大小的規模曲線,即1.3B、2.7B和6.7B。RetNet在與Transformer相當的結果上取得了可比的效果。更重要的是,結果表明RetNet在規模擴展方面更有優勢。除了性能外,我們的實驗中RetNet的訓練非常穩定。實驗結果表明,對于大型語言模型,RetNet是Transformer的有力競爭者。經驗證實,當模型大小大于2B時,RetNet開始勝過Transformer。我們還在附錄B中總結了不同上下文長度的語言建模結果。?
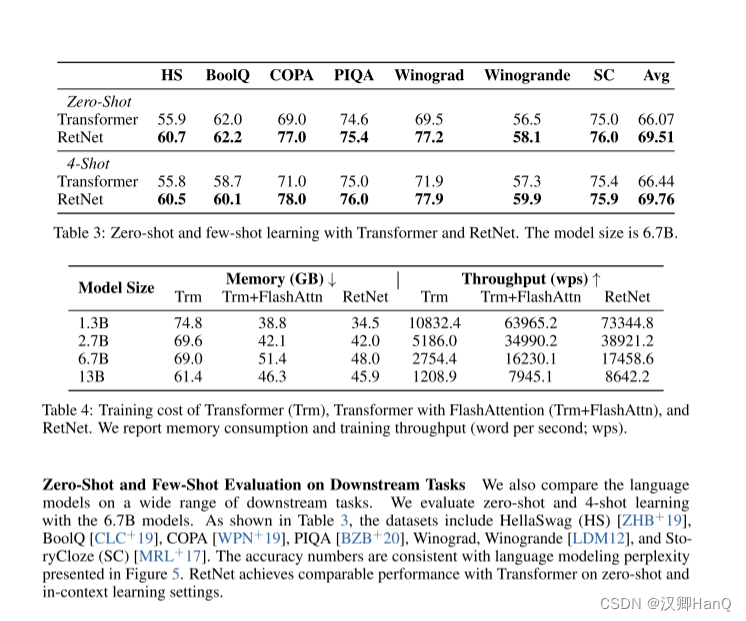
? ? ? ? 各種下游任務的語言模型:我們還在廣泛的下游任務上比較了語言模型。我們使用6.7B模型進行零射和4射學習的評估。如表3所示,數據集包括HellaSwag(HS)[ZHB+19]、BoolQ [CLC+19]、COPA [WPN+19]、PIQA [BZB+20]、Winograd、Winogrande [LDM12]和StoryCloze(SC)[MRL+17]。準確度數字與圖5中的語言建模困惑度保持一致。在零射和上下文學習設置中,RetNet在性能上與Transformer達到了可比的水平。
- 精讀
3.3Training Cost

- 翻譯
????????如表4所示,我們比較了Transformer和RetNet的訓練速度和內存消耗,其中訓練序列長度為8192。我們還與FlashAttention [DFE+22]進行了比較,后者通過重新計算和內核融合來提高速度并減少GPU內存IO。相比之下,我們使用原始的PyTorch代碼來實現RetNet,并將內核融合或類似FlashAttention的加速留給未來的工作。我們使用公式(7)中的分塊遞歸保留表示。分塊大小設置為512。我們使用八個Nvidia A100-80GB GPU進行評估,因為FlashAttention在A100上進行了高度優化。6.7B和13B模型啟用了張量并行。
????????實驗結果顯示,與Transformer相比,RetNet在訓練過程中具有更高的內存效率和吞吐量。即使與FlashAttention相比,RetNet在速度和內存成本方面仍然具有競爭力。此外,由于不依賴特定的內核,可以在其他平臺上高效地訓練RetNet。例如,我們在一個AMD MI200集群上訓練了RetNet模型,具有不錯的吞吐量。值得注意的是,RetNet有潛力通過先進的實現,比如內核融合,進一步降低成本。
- 精讀
3.4Inference Cost

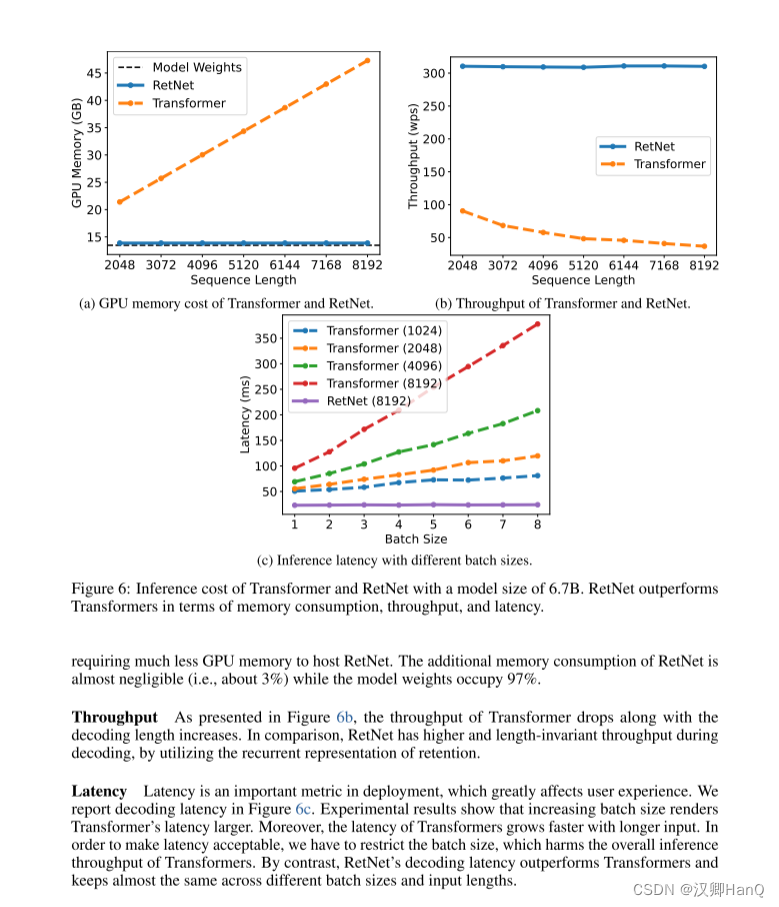
- 翻譯
????????如圖6所示,我們在推理過程中比較Transformer 和RetNet 的內存成本、吞吐量和延遲。變壓器重用以前解碼令牌的KV緩存。RetNet 使用如式(6)所示的循環表示。我們在實驗中對 A100-80GB? GPU 上的 6.7B 模型進行了評估。圖 6 顯示RetNet 在推理成本方面優于Transformer。
? ? ? ? 顯存:如圖6a所示,由于KV緩存,Transformer的內存成本呈線性增加。相比之下,RetNet的內存消耗即使在長序列情況下也保持一致,因此,托管RetNet所需的GPU內存要少得多。RetNet的額外內存消耗幾乎可以忽略不計(即約為3%),而模型權重占據了97%。
? ? ? ? 吞吐量:如圖6b所示,隨著解碼長度的增加,Transformer的吞吐量下降。相比之下,通過利用保留的遞歸表示,RetNet在解碼過程中具有更高且長度不變的吞吐量。
? ? ? ? 延遲部署:延遲是部署中的一個重要指標,它極大地影響用戶體驗。我們在圖6c中報告了解碼延遲。實驗結果顯示,增加批次大小會使Transformer的延遲變大。此外,Transformer的延遲在輸入更長的情況下增長得更快。為了使延遲可接受,我們不得不限制批次大小這會損害Transformer的整體推理吞吐量。相比之下,RetNet的解碼延遲優于Transformer,并且在不同的批次大小和輸入長度之間基本保持一致。
- 精讀
3.5Comparison with Transformer Variants

 ?
?
- 翻譯
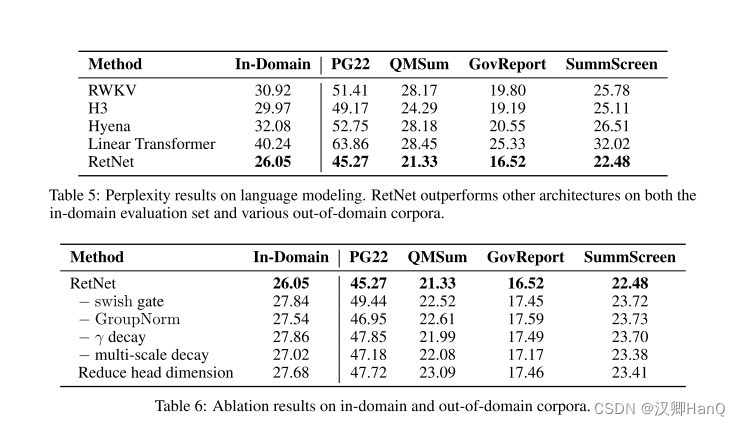
????????除了Transformer,我們還將RetNet與各種高效的Transformer變體進行了比較,包括Linear Transformer [KVPF20]、RWKV [PAA+23]、H3 [DFS+22]和Hyena [PMN+23]。所有模型都有200M個參數,具有16層和1024的隱藏維度。對于H3,我們將頭維度設置為8。對于RWKV,我們使用TimeMix模塊來替代自注意力層,同時保持FFN層與其他模型保持一致,以進行公平比較。我們以0.5M個標記的批次大小進行了10k步的訓練。大多數超參數和訓練語料庫與第3.1節保持一致。
????????表5報告了在領域內驗證集和其他領域外語料庫(例如,Project Gutenberg 2019-2022(PG22)[SDP+22]、QMSum [ZYY+21]、GovReport [HCP+21]、SummScreen [CCWG21,SSI+22])上的困惑度數字。總體而言,RetNet在不同的數據集上表現優于先前的方法。RetNet不僅在領域內語料庫上獲得更好的評估結果,還在一些領域外的數據集上獲得更低的困惑度。這種有利的表現使得RetNet成為Transformer的強有力繼任者,除了顯著降低成本的好處(第3.3和3.4節)。
????????此外,我們還討論了所比較方法的訓練和推理效率。令d表示隱藏維度,n表示序列長度。對于訓練,RWKV的令牌混合復雜度為O(dn),而Hyena的復雜度為O(dn log n),并通過快速傅里葉變換進行加速。上述兩種方法通過使用逐元素運算符來降低建模容量以換取訓練FLOPS。與此相比,基于塊的遞歸表示為O(dn(b + h)),其中b是塊大小,h是頭維度,通常設置b = 512,h = 256。對于大模型大小(即更大的d)或序列長度,額外的b + h對性能影響微乎其微。因此,RetNet的訓練非常高效,而不會犧牲建模性能。對于推理,在比較的高效架構中,Hyena的復雜度(即每步O(n))與Transformer相同,而其他架構可以實現O(1)解碼。
- 精讀
3.6Ablation Studies

?
- 翻譯
????????我們去掉了RetNet 的各種設計選擇,并在表6中報告了語言建模結果。評估設置和指標與章節3.5相同。
????????Architecture:我們分析了方程(8)中的Swish門和GroupNorm。表6顯示,上述兩個組件可以提高最終的性能。首先,門控模塊對于增強非線性和提高模型能力至關重要。需要注意的是,我們在去除門控后使用與Transformer相同的參數分配。其次,保留在保留層中的分組歸一化可以平衡多頭輸出的方差,從而提高訓練穩定性和語言建模結果。
????????Multi-Scale Decay:方程(8)顯示,我們使用不同的γ作為保留頭部的衰減率。在消融研究中,我們研究了去除γ衰減(即“-γ衰減”)和在所有頭部應用相同的衰減率(即“-多尺度衰減”)。具體來說,去除γ衰減等同于γ = 1。在第二種情況下,我們將所有頭部的γ設置為127/128。表6表明,無論是衰減機制還是使用多個衰減率,都可以提高語言建模性能。
????????Head Dimension:從方程(1)的遞歸角度來看,頭部維度暗示了隱藏狀態的內存容量。在消融研究中,我們將默認的頭部維度從256降低到64,即查詢和鍵使用64,值使用128。我們保持隱藏維度dmodel不變,因此頭部數目增加。表6中的實驗結果顯示,較大的頭部維度可以獲得更好的性能。
- 精讀
四.Conclusion

????????在本研究中,我們提出了用于序列建模的保留網絡(RetNet),它能夠實現各種表示,即并行、遞歸和分塊遞歸。相比于Transformer,RetNet在推理效率(內存、速度和延遲方面)、有利的訓練并行化以及競爭性能方面表現出色。上述優勢使得RetNet成為大型語言模型的理想繼任者,特別是考慮到O(1)推理復雜度帶來的部署優勢。在未來,我們計劃在模型大小[CDH+22]和訓練步驟方面擴展RetNet。此外,保留可以通過壓縮長期記憶有效地與結構化提示[HSD+22b]配合使用。我們還將使用RetNet作為骨干架構來訓練多模態大型語言模型[HSD+22a,HDW+23,PWD+23]。此外,我們有興趣在各種邊緣設備上部署RetNet模型,如手機等。?
(VP))





】)



(2)——Enet(彈性網絡))

)






