在本教程中,我想談談Apache Lucene 。 Lucene是一個開源項目,提供基于Java的索引和搜索技術。 使用其API,很容易實現全文搜索 。 我將處理Lucene Java版本 ,但請記住,還有一個名為Lucene.NET的.NET端口,以及一些有用的子項目。
我最近閱讀了有關該項目的精彩教程 ,但沒有提供實際的代碼。 因此,我決定提供一些示例代碼來幫助您開始使用Lucene。 我們將構建的應用程序將允許您索引自己的源代碼文件并搜索特定的關鍵字。
首先,讓我們從其中一個Apache Download Mirrors下載最新的穩定版本。 我將使用的版本是3.0.1,所以我下載了lucene-3.0.1.tar.gz捆綁包(請注意,.tar.gz版本明顯小于相應的.zip版本)。 解壓縮tarball并找到lucene-core-3.0.1.jar文件,稍后將使用它。 此外,請確保在瀏覽器中打開Lucene API JavaDoc頁面(文檔也包含在壓縮包中以供離線使用)。 接下來,設置一個新的Eclipse項目,假設其名稱為“ LuceneIntroProject”,并確保在項目的類路徑中包含上述JAR。
在開始運行搜索查詢之前,我們需要構建一個索引,將針對該索引執行查詢。 這將在名為IndexWriter的類的幫助下完成,該類是創建和維護索引的類。 IndexWriter接收Document作為輸入,其中document是索引和搜索的單位。 每個Document實際上是一組Field ,每個字段都有一個名稱和一個文本值。 要創建IndexWriter,需要使用分析器 。 此類是抽象的,我們將使用的具體實現是SimpleAnalyzer 。
已經說夠了,讓我們創建一個名為“ SimpleFileIndexer”的類,并確保包含一個主要方法。 這是此類的源代碼:
package com.javacodegeeks.lucene;import java.io.File;
import java.io.FileReader;
import java.io.IOException;import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.FSDirectory;public class SimpleFileIndexer {public static void main(String[] args) throws Exception {File indexDir = new File("C:/index/");File dataDir = new File("C:/programs/eclipse/workspace/");String suffix = "java";SimpleFileIndexer indexer = new SimpleFileIndexer();int numIndex = indexer.index(indexDir, dataDir, suffix);System.out.println("Total files indexed " + numIndex);}private int index(File indexDir, File dataDir, String suffix) throws Exception {IndexWriter indexWriter = new IndexWriter(FSDirectory.open(indexDir), new SimpleAnalyzer(),true,IndexWriter.MaxFieldLength.LIMITED);indexWriter.setUseCompoundFile(false);indexDirectory(indexWriter, dataDir, suffix);int numIndexed = indexWriter.maxDoc();indexWriter.optimize();indexWriter.close();return numIndexed;}private void indexDirectory(IndexWriter indexWriter, File dataDir, String suffix) throws IOException {File[] files = dataDir.listFiles();for (int i = 0; i < files.length; i++) {File f = files[i];if (f.isDirectory()) {indexDirectory(indexWriter, f, suffix);}else {indexFileWithIndexWriter(indexWriter, f, suffix);}}}private void indexFileWithIndexWriter(IndexWriter indexWriter, File f, String suffix) throws IOException {if (f.isHidden() || f.isDirectory() || !f.canRead() || !f.exists()) {return;}if (suffix!=null && !f.getName().endsWith(suffix)) {return;}System.out.println("Indexing file " + f.getCanonicalPath());Document doc = new Document();doc.add(new Field("contents", new FileReader(f))); doc.add(new Field("filename", f.getCanonicalPath(), Field.Store.YES, Field.Index.ANALYZED));indexWriter.addDocument(doc);}} 讓我們來談談這個課程。 我們提供了索引的位置,即索引數據將保存在磁盤上的位置(“ c:/ index /”)。 然后,我們提供數據目錄,即將遞歸掃描輸入文件的目錄。 為此,我選擇了整個Eclipse工作區(“ C:/ programs / eclipse / workspace /”)。 由于我們只希望為Java源代碼文件建立索引,因此我還添加了一個后綴字段。 您顯然可以根據您的搜索需求調整這些值。 “索引”方法考慮了先前的參數,并使用IndexWriter的新實例來執行目錄索引。 “ indexDirectory”方法使用一種簡單的遞歸算法來掃描所有目錄以查找帶有.java后綴的文件。 對于每個符合條件的文件,將在“ indexFileWithIndexWriter”中創建一個新文檔,并填充相應的字段。 如果您通過Eclipse將類作為Java應用程序運行,則輸入目錄將被索引,輸出目錄將如下圖所示: 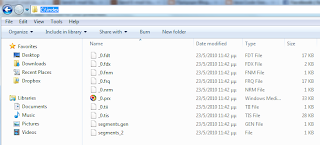 好的,我們完成了索引工作,讓我們繼續進行方程式的搜索部分。 為此,需要一個IndexSearcher類,它是實現主要搜索方法的類。 對于每次搜索,都需要一個新的Query對象(SQL可以使用SQL嗎?),可以從QueryParser實例中獲得該對象。 請注意,必須使用與創建索引相同的分析器類型來創建QueryParser,在我們的示例中,使用SimpleAnalyzer。 根據JavaDocs, Version也用作構造函數參數,并且是一個“被某些類用來在Lucene的各個發行版之間匹配版本兼容性”的類。 諸如此類的存在使我感到困惑,但是無論如何,讓我們為應用程序使用適當的版本( Lucene_30 )。 由IndexSearcher執行搜索時,將返回TopDocs對象作為執行結果。 此類僅表示搜索結果,并允許我們檢索ScoreDoc對象。 使用ScoreDocs,我們找到符合搜索條件的文檔,然后從這些文檔中檢索所需的信息。 讓我們看看所有這些都在起作用。 創建一個名為“ SimpleSearcher”的類,并確保包含一個主要方法。 此類的源代碼如下:
好的,我們完成了索引工作,讓我們繼續進行方程式的搜索部分。 為此,需要一個IndexSearcher類,它是實現主要搜索方法的類。 對于每次搜索,都需要一個新的Query對象(SQL可以使用SQL嗎?),可以從QueryParser實例中獲得該對象。 請注意,必須使用與創建索引相同的分析器類型來創建QueryParser,在我們的示例中,使用SimpleAnalyzer。 根據JavaDocs, Version也用作構造函數參數,并且是一個“被某些類用來在Lucene的各個發行版之間匹配版本兼容性”的類。 諸如此類的存在使我感到困惑,但是無論如何,讓我們為應用程序使用適當的版本( Lucene_30 )。 由IndexSearcher執行搜索時,將返回TopDocs對象作為執行結果。 此類僅表示搜索結果,并允許我們檢索ScoreDoc對象。 使用ScoreDocs,我們找到符合搜索條件的文檔,然后從這些文檔中檢索所需的信息。 讓我們看看所有這些都在起作用。 創建一個名為“ SimpleSearcher”的類,并確保包含一個主要方法。 此類的源代碼如下:
package com.javacodegeeks.lucene;import java.io.File;import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;public class SimpleSearcher {public static void main(String[] args) throws Exception {File indexDir = new File("c:/index/");String query = "lucene";int hits = 100;SimpleSearcher searcher = new SimpleSearcher();searcher.searchIndex(indexDir, query, hits);}private void searchIndex(File indexDir, String queryStr, int maxHits) throws Exception {Directory directory = FSDirectory.open(indexDir);IndexSearcher searcher = new IndexSearcher(directory);QueryParser parser = new QueryParser(Version.LUCENE_30, "contents", new SimpleAnalyzer());Query query = parser.parse(queryStr);TopDocs topDocs = searcher.search(query, maxHits);ScoreDoc[] hits = topDocs.scoreDocs;for (int i = 0; i < hits.length; i++) {int docId = hits[i].doc;Document d = searcher.doc(docId);System.out.println(d.get("filename"));}System.out.println("Found " + hits.length);}}我們提供索引目錄,搜索查詢字符串和最大匹配數,然后調用“ searchIndex”方法。 在該方法中,我們創建一個IndexSearcher,一個QueryParser和一個Query對象。 請注意,QueryParser使用我們用于使用IndexWriter創建文檔的字段的名稱(“內容”),并且再次使用相同類型的分析器(SimpleAnalyzer)。 我們執行搜索,并為找到匹配項的每個Document提取包含文件名(“ filename”)的字段的值,然后進行打印。 就是這樣,讓我們??執行實際的搜索。 作為Java應用程序運行它,您將看到包含您提供的查詢字符串的文件的名稱。
可以從此處下載本教程的Eclipse項目,包括依賴庫。
更新:您還可以使用Apache Lucene Spell-Checker查看我們后續的文章“您的意思是”功能 。
請享用!
- Apache Lucene拼寫檢查器的“您是不是要”功能
- 使用Spring AspectJ和Maven進行面向方面的編程
- 調度Java應用程序中的主體
- 依賴注入–手動方式
翻譯自: https://www.javacodegeeks.com/2010/05/introduction-to-apache-lucene-for-full.html









)
的方法代碼)

; 演練和清單)

)




)