大家好,我是微學AI,今天給大家介紹一下人工智能任務1-【NLP系列】句子嵌入的應用與多模型實現方式。句子嵌入是將句子映射到一個固定維度的向量表示形式,它在自然語言處理(NLP)中有著廣泛的應用。通過將句子轉化為向量表示,可以使得計算機能夠更好地理解和處理文本數據。
本文采用多模型實現方式詞嵌入,包括:Word2Vec 、Doc2Vec、BERT模型,將其應用于句子嵌入任務。這些預訓練模型通過大規模的無監督學習從海量文本數據中學習到了豐富的語義信息,并能夠產生高質量的句子嵌入。
目錄
- 引言
- 項目背景與意義
- 句子嵌入基礎
- 實現方式
- Word2Vec
- Doc2Vec
- BERT
- 項目實踐與代碼
- 數據預處理
- 句子嵌入實現
- 總結
- 參考資料
引言
隨著人工智能和大數據的發展,自然語言處理(NLP)在許多領域得到了廣泛應用,如搜索引擎,推薦系統,自動翻譯等。其中,句子嵌入是NLP的關鍵技術之一,它可以將自然語言的句子轉化為計算機可以理解的向量,從而使機器可以處理和理解自然語言。本文將詳細介紹句子嵌入在NLP中的應用項目,以及幾種常見的中文文本句子嵌入的實現方式。
項目背景與意義
在自然語言處理中,將句子轉化為向量的過程稱為句子嵌入。這是因為計算機不能直接理解自然語言,而是通過處理數值數據(例如向量)來實現。句子嵌入可以捕捉句子的語義信息,幫助機器理解和處理自然語言。
句子嵌入的應用項目廣泛,如情感分析,文本分類,語義搜索,機器翻譯等。例如,在情感分析中,句子嵌入可以將文本轉化為向量,然后通過機器學習模型來預測文本的情感。在機器翻譯中,句子嵌入可以幫助機器理解源語言的句子,并將其轉化為目標語言的句子。
句子嵌入的應用主要包括以下幾個方面:
文本分類/情感分析:句子嵌入可以用于文本分類任務,如將電影評論分為正面和負面情感。基于句子嵌入的模型能夠學習到句子的語義信息,并將其應用于情感分類。
語義相似度:通過計算句子嵌入之間的相似度,可以衡量句子之間的語義相似性。這在問答系統、推薦系統等任務中非常有用,可以幫助找到與輸入句子最相關的其他句子。
機器翻譯:句子嵌入可以用于機器翻譯任務中的句子對齊和翻譯建模。通過將源語言句子和目標語言句子編碼成嵌入向量,可以捕捉句子之間的對應關系和語義信息,從而提高翻譯質量。
句子生成:利用預訓練的語言模型和句子嵌入,可以生成連貫、語義正確的句子。句子嵌入可以作為生成任務的輸入,保證生成的句子與輸入的上下文相關。
信息檢索/相似句子查找:通過將句子轉換為嵌入向量,可以建立索引并進行快速的相似句子查找。這在搜索引擎、知識圖譜等領域具有重要應用價值。
句子嵌入基礎
句子嵌入是一種將自然語言句子轉化為固定長度的實數向量的技術。這個向量能夠捕獲句子的語義信息,例如句子的主題,情感,語氣等。句子嵌入通常是通過神經網絡模型學習得到的。這些模型可以是無監督的,如Word2Vec,Doc2Vec,或者是有監督的,如BERT。
實現方式
接下來,我們將介紹三種常見的中文文本句子嵌入的實現方式。
方法一:Word2Vec
Word2Vec是一種常見的詞嵌入方法,它可以將詞語轉化為向量。這種方法的思想是,將一個句子中的所有詞向量取平均,得到句子的向量。
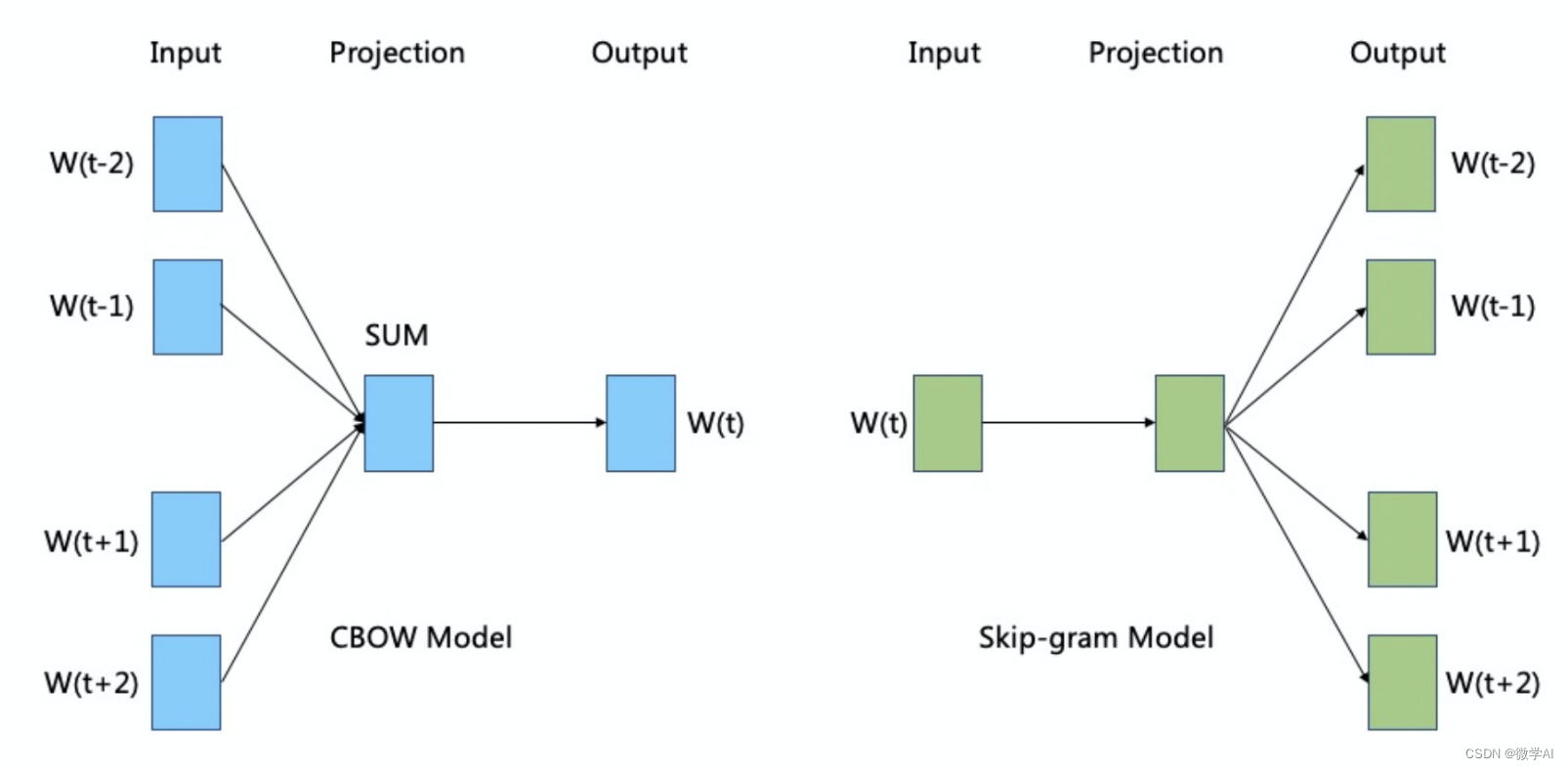
Word2Vec 有兩種實現方式:CBOW(Continuous Bag-of-Words)和Skip-gram。
CBOW 模型旨在根據上下文預測中心詞,而 Skip-gram 模型則是根據中心詞預測上下文。以下是這兩種模型的基本數學原理:
CBOW 模型:
假設我們有一個中心詞 w t w_t wt?,并且上下文窗口大小為 m m m,則上下文詞可以表示為 w t ? m , w t ? m + 1 , . . . , w t ? 1 , w t + 1 , . . . , w t + m w_{t-m}, w_{t-m+1}, ..., w_{t-1}, w_{t+1}, ..., w_{t+m} wt?m?,wt?m+1?,...,wt?1?,wt+1?,...,wt+m?。
CBOW 模型試圖根據上下文詞來預測中心詞,其目標是最大化給定上下文條件下中心詞的條件概率。
具體而言,CBOW 模型通過將上下文詞的詞向量進行平均或求和,得到上下文表示 v = 1 2 m ∑ i = 1 2 m v w t i \mathbf{v} = \frac{1}{2m} \sum_{i=1}^{2m} \mathbf{v}_{w_{t_i}} v=2m1?∑i=12m?vwti???。然后,將上下文表示 v \mathbf{v} v 輸入到一個隱藏層中,并通過一個非線性函數(通常是 sigmoid 函數)得到隱藏層的輸出 h = σ ( W v + b ) \mathbf{h} = \sigma(\mathbf{W}\mathbf{v} + \mathbf{b}) h=σ(Wv+b)。最后,將隱藏層的輸出與中心詞 w t w_t wt? 相關的 one-hot 編碼表示進行比較,并使用 softmax 函數得到每個詞的概率分布 y ^ \hat{\mathbf{y}} y^?。模型的目標是最大化實際中心詞的對數概率: max ? log ? P ( w t ∣ w t ? m , . . . , w t ? 1 , w t + 1 , . . . , w t + m ) \max \log P(w_t | w_{t-m}, ..., w_{t-1}, w_{t+1}, ..., w_{t+m}) maxlogP(wt?∣wt?m?,...,wt?1?,wt+1?,...,wt+m?)。
Skip-gram 模型:
Skip-gram 模型與 CBOW 模型相反,它試圖根據中心詞預測上下文詞。
具體而言,Skip-gram 模型將中心詞 w t w_t wt? 的詞向量 v w t \mathbf{v}_{w_t} vwt?? 輸入到隱藏層,并通過一個非線性函數得到隱藏層的輸出 h = σ ( W v w t + b ) \mathbf{h} = \sigma(\mathbf{W}\mathbf{v}_{w_t} + \mathbf{b}) h=σ(Wvwt??+b)。然后,將隱藏層的輸出與上下文詞 w t ? m , w t ? m + 1 , . . . , w t ? 1 , w t + 1 , . . . , w t + m w_{t-m}, w_{t-m+1}, ..., w_{t-1}, w_{t+1}, ..., w_{t+m} wt?m?,wt?m+1?,...,wt?1?,wt+1?,...,wt+m? 相關的 one-hot 編碼表示依次比較,并使用 softmax 函數得到每個詞的概率分布 y ^ \hat{\mathbf{y}} y^?。模型的目標是最大化實際上下文詞的對數概率: max ? ∑ i = 1 2 m log ? P ( w t i ∣ w t ) \max \sum_{i=1}^{2m} \log P(w_{t_i} | w_{t}) max∑i=12m?logP(wti??∣wt?)。
在實際訓練過程中,Word2Vec 使用負采樣(negative sampling)來近似 softmax 函數的計算,加快模型的訓練速度,并取得更好的性能。
希望上述使用 LaTeX 輸出的數學表示對您有所幫助!
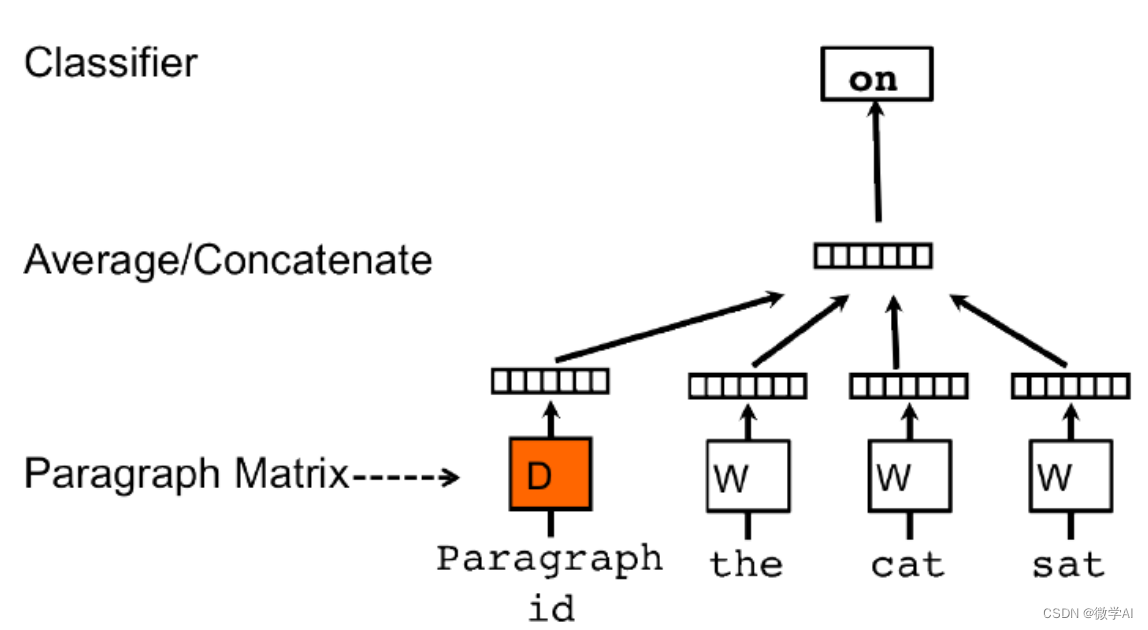
方法二:Doc2Vec
Doc2Vec是一種直接獲取句子向量的方法,它是Word2Vec的擴展。Doc2Vec不僅考慮詞語的上下文關系,還考慮了文檔的全局信息。
假設我們有一個包含N個文檔的語料庫,每個文檔由一系列單詞組成。Doc2Vec的目標是為每個文檔生成一個固定長度的向量表示。
Doc2Vec使用了兩種不同的模型來實現這一目標:分別是PV-DM和PV-DBOW。
對于PV-DM模型,在訓練過程中,每個文檔被映射到一個唯一的向量(paragraph vector),同時也將每個單詞映射到一個向量。在預測階段,模型輸入一部分文本(可能是一個或多個單詞)并嘗試預測缺失部分文本(通常是一個單詞)。模型的損失函數基于預測和真實值之間的差異進行計算,然后通過反向傳播來更新文檔和單詞的向量表示。
對于PV-DBOW模型,它忽略了文檔內單詞的順序,只關注文檔的整體表示。在該模型中,一個文檔被映射到一個向量,并且模型的目標是通過上下文單詞的信息預測該文檔。同樣地,模型使用損失函數和反向傳播來更新文檔和單詞的向量表示。
總體而言,Doc2Vec通過將每個文檔表示為固定長度的向量來捕捉文檔的語義信息。這些向量可以用于度量文檔之間的相似性、聚類文檔或作為其他任務的輸入。
使用數學符號描述Doc2Vec的具體細節,可以參考以下公式:
PV-DM模型:
- 輸入:一個文檔d,由單詞序列 ( w 1 , w 2 , . . . , w n ) (w_1, w_2, ..., w_n) (w1?,w2?,...,wn?)組成,其中 n n n是文檔中的單詞數。
- 文檔向量: p v dm ( d ) pv_{\text{dm}}(d) pvdm?(d),表示文檔d的向量表示。
- 單詞向量:每個單詞 w i w_i wi?都有一個對應的向量表示 w i w_i wi?。
- 預測:給定輸入部分文本 ( w 1 , w 2 , . . . , w k ) (w_1, w_2, ..., w_k) (w1?,w2?,...,wk?),模型嘗試預測缺失文本 w k + 1 w_{k+1} wk+1?。
- 損失函數:使用交叉熵或其他適當的損失函數計算預測值與真實值之間的差異。
- 訓練:通過反向傳播和梯度下降算法更新文檔向量和單詞向量。
PV-DBOW模型:
- 輸入:一個文檔d,由單詞序列 ( w 1 , w 2 , . . . , w n ) (w_1, w_2, ..., w_n) (w1?,w2?,...,wn?)組成,其中 n n n是文檔中的單詞數。
- 文檔向量: p v dbow ( d ) pv_{\text{dbow}}(d) pvdbow?(d),表示文檔d的向量表示。
- 單詞向量:每個單詞 w i w_i wi?都有一個對應的向量表示 w i w_i wi?。
- 預測:給定一個文檔d,模型嘗試預測與該文檔相關的上下文單詞。
- 損失函數:使用交叉熵或其他適當的損失函數計算預測值與真實值之間的差異。
- 訓練:通過反向傳播和梯度下降算法更新文檔向量和單詞向量。
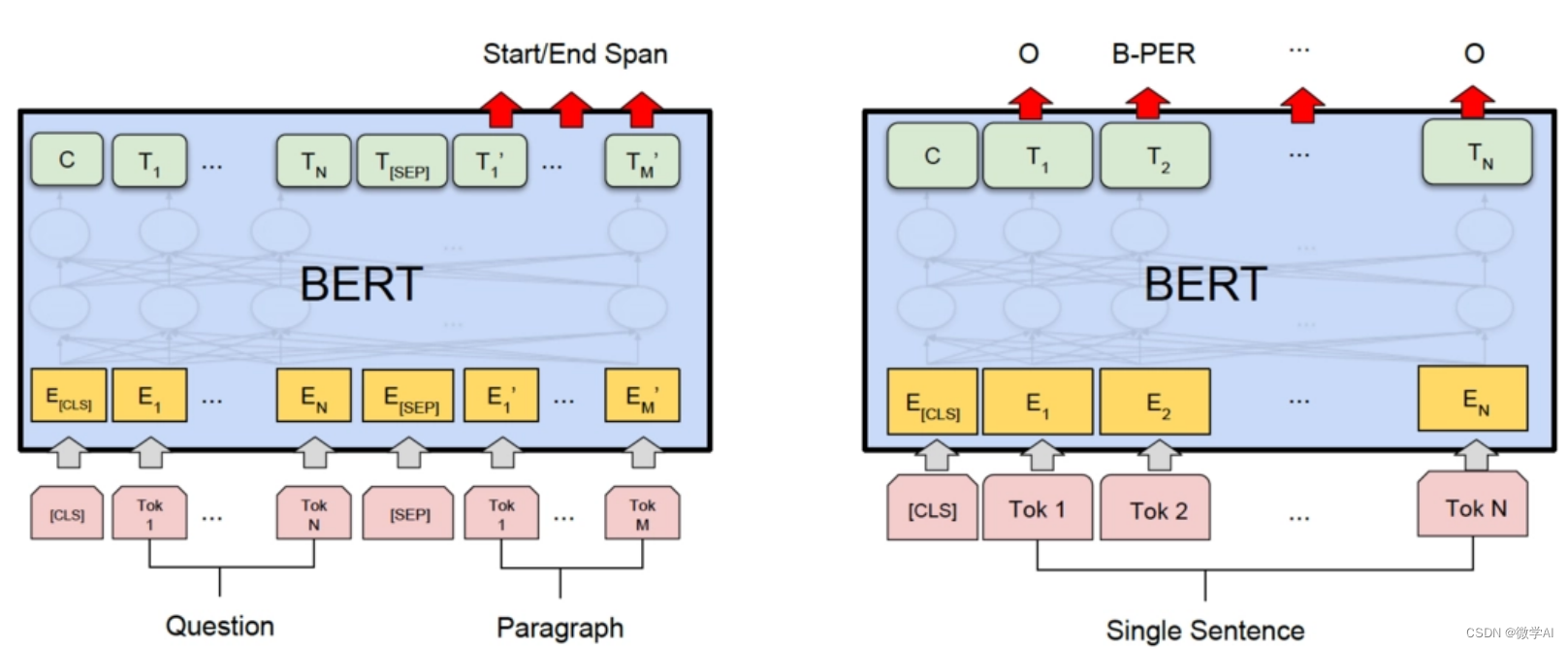
方法三:BERT
BERT是一種基于Transformer的深度學習模型,它可以獲取到句子的深層次語義信息。
BERT模型的數學原理基于兩個關鍵概念:MLM和NSP。
首先,我們將輸入文本序列表示為一系列的詞向量,并且為每個詞向量添加相對位置編碼。然后,通過多次堆疊的Transformer層來進行特征抽取。
在MLM階段,BERT會對輸入序列中的一部分詞進行隨機掩碼操作,即將這些詞的嵌入向量替換為一個特殊的標記 “[MASK]”。然后,模型通過上下文上下文預測這些被掩碼的詞。
在NSP階段,BERT會將兩個句子作為輸入,并判斷它們是否是原始文本中的連續句子。這個任務旨在幫助模型學習到句子級別的語義信息。
具體而言,BERT模型的數學原理包括以下幾個步驟:
- 輸入嵌入層:輸入是一系列的詞語索引,將其映射為詞向量表示。
- 位置編碼:為每個輸入添加相對位置編碼,以便模型能夠理解詞語之間的順序關系。
- Transformer層:通過多次堆疊的Transformer層進行特征抽取,每層由多頭自注意力機制和前饋神經網絡組成。
- Masked Language Model(MLM):對輸入序列中的一部分詞進行掩碼,并通過上下文預測這些被掩碼的詞。
- Next Sentence Prediction(NSP):將兩個句子作為輸入,判斷它們是否是原始文本中的連續句子。
項目實踐與代碼
接下來,我們將通過一個例子來展示如何實現中文文本的句子嵌入。我們將使用Python語言和相關的NLP庫(如gensim,torch,transformers等)來完成。
數據預處理
首先,我們需要對數據進行預處理,包括分詞,去除停用詞等。以下是一個簡單的數據預處理代碼示例:
import jiebadef preprocess_text(text):# 使用jieba進行分詞words = jieba.cut(text)# 去除停用詞stop_words = set(line.strip() for line in open('stop_words.txt', 'r', encoding='utf-8'))words = [word for word in words if word not in stop_words]return words
句子嵌入實現
接下來,我們將展示如何使用上述的三種方法來實現句子嵌入。
方法一:Word2Vec + 文本向量平均
from gensim.models import Word2Vecdef sentence_embedding_word2vec(sentences, size=100, window=5, min_count=5):# 訓練Word2Vec模型model = Word2Vec(sentences, size=size, window=window, min_count=min_count)# 對每個句子的詞向量進行平均sentence_vectors = []for sentence in sentences:vectors = [model.wv[word] for word in sentence if word in model.wv]sentence_vectors.append(np.mean(vectors, axis=0))return sentence_vectors
方法二:Doc2Vec
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedDocumentdef sentence_embedding_doc2vec(sentences, vector_size=100, window=5, min_count=5):# 將句子轉化為TaggedDocument對象documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(sentences)]# 訓練Doc2Vec模型model = Doc2Vec(documents, vector_size=vector_size, window=window, min_count=min_count)# 獲取句子向量sentence_vectors = [model.docvecs[i] for i in range(len(sentences))]return sentence_vectors
方法三:BERT
import torch
from transformers import BertTokenizer, BertModel# 加載預訓練的BERT模型和分詞器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')# 輸入待轉換的句子
sentence = "這是一個示例句子。"# 使用分詞器將句子分成tokens
tokens = tokenizer.tokenize(sentence)# 添加特殊標記 [CLS] 和 [SEP]
tokens = ['[CLS]'] + tokens + ['[SEP]']# 將tokens轉換為對應的id
input_ids = tokenizer.convert_tokens_to_ids(tokens)# 創建輸入tensor
input_tensor = torch.tensor([input_ids])# 使用BERT模型獲取句子的嵌入向量
with torch.no_grad():outputs = model(input_tensor)sentence_embedding = outputs[0][0][0] # 取第一個句子的第一個token的輸出作為句子的嵌入向量# 輸出句子的嵌入向量
print(sentence_embedding)
print(sentence_embedding.shape)
總結
本文詳細介紹了句子嵌入在NLP中的應用項目,以及幾種常見的中文文本句子嵌入的實現方式。我們通過實踐和代碼示例展示了如何使用Word2Vec + 文本向量平均,Doc2Vec,和BERT來實現句子嵌入。希望本文能夠幫助讀者更好地理解句子嵌入,并在實際項目中應用句子嵌入技術。

GPIO控制)

:全面總結delegate、Func委托的寫法演變)


RedisAutoConfiguration自動配置類)


![P8642 [藍橋杯 2016 國 AC] 路徑之謎](http://pic.xiahunao.cn/P8642 [藍橋杯 2016 國 AC] 路徑之謎)




)




