每當您需要評估編譯時未知的表達式,或者解析奇怪的用戶輸入或文件時,這都是有用的。 當然,可以為任何這些任務創建定制的手工分析器。 但是,通常需要更多時間和精力。 對良好的解析器生成器的一點了解可能會將這些耗時的任務變成簡單而又快速的練習。
這篇文章從ANTLR有用性的一個小例子開始。 然后,我們解釋什么是ANTLR以及它如何工作。 最后,我們展示如何編譯一個簡單的“ Hello word!” 語言轉換成抽象語法樹。 文章還說明了如何添加錯誤處理以及如何測試語言。
下一篇文章展示了如何創建一種真實的表達語言。
實詞示例
ANTLR在開源單詞中似乎很流行。 其中, Apache Camel , Apache Lucene , Apache Hadoop , Groovy和Hibernate都使用它 。 他們都需要用于自定義語言的解析器。 例如,Hibernate使用ANTLR解析其查詢語言HQL。
所有這些都是大型框架,因此與小型應用程序相比,它們更可能需要特定領域的語言。 使用ANTLR的較小項目的列表可在其展示列表中找到 。 我們還找到了一個關于該主題的stackoverflow討論。
若要查看ANTLR可能在哪里有用以及如何節省時間,請嘗試估算以下要求:
- 將公式計算器添加到會計系統中。 它將計算公式的值,例如
(10 + 80)*sales_tax。 - 將擴展的搜索字段添加到配方搜索引擎中。 它將搜索匹配表達式的收據,例如
(chicken and orange) or (no meat and carrot)。
我們的安全評估需要一天半的時間,其中包括文檔,測試以及與項目的集成。 如果您面臨類似的要求并且做出了更高的估計,那么ANTLR值得一看。
總覽
ANTLR是代碼生成器。 它以所謂的語法文件作為輸入,并生成兩個類:lexer和parser。
Lexer首先運行,然后將輸入分成稱為令牌的部分。 每個令牌代表或多或少有意義的輸入。 代幣流被傳遞到解析器,解析器完成所有必要的工作。 解析器負責構建抽象語法樹,解釋代碼或將其轉換為其他形式。
語法文件包含ANTLR生成正確的詞法分析器和解析器所需的所有內容。 它是否應該生成Java或python類,解析器是否生成抽象語法樹,匯編代碼或直接解釋代碼等。 正如本教程顯示如何構建抽象語法樹一樣,在以下說明中我們將忽略其他選項。
最重要的是,語法文件描述了如何將輸入分為令牌以及如何從令牌構建樹。 換句話說,語法文件包含詞法分析器規則和解析器規則。
每個詞法分析器規則描述一個令牌:
TokenName: regular expression;解析器規則更加復雜。 最基本的版本類似于lexer規則中的版本:
ParserRuleName: regular expression;它們可能包含修飾符,這些修飾符在結果抽象語法樹中指定輸入,根和子元素上的特殊轉換,或在使用規則時執行的操作。 幾乎所有工作通常都在解析器規則內完成。
基礎設施
首先,我們展示使ANTLR開發更容易的工具。 當然,本章中所描述的內容都不是必需的。 所有示例僅適用于maven,文本編輯器和Internet連接。
ANTLR項目制作了獨立的IDE , Eclipse插件和Idea插件 。 我們沒有找到NetBeans插件。
ANTLRWorks
獨立的想法稱為ANTLRWorks 。 從項目下載頁面下載 。 ANTLRWorks是單個jar文件,請使用java -jar antlrworks-1.4.3.jar命令運行它。
IDE具有更多功能,并且比Eclipse插件更穩定。
Eclipse插件
從ANTLR 下載頁面下載并解壓縮ANTLR v3。 然后,從Eclipse Marketplace安裝ANTLR插件:

轉到“首選項”并配置ANTLR v3安裝目錄:
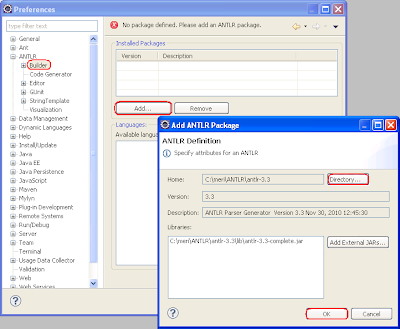
要測試配置,請下載示例語法文件并在eclipse中打開它。 它將在ANTLR編輯器中打開。 編輯器具有三個選項卡:
- 語法–具有語法突出顯示,代碼完成等功能的文本編輯器。
- 解釋器–將測試表達式編譯成語法樹,可能會產生與生成的解析器不同的結果。 它傾向于在正確的表達式上拋出失敗的謂詞異常。
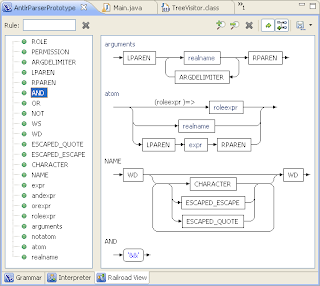
- 鐵路視圖–繪制詞法分析器和解析器規則的漂亮圖形。
空項目– Maven配置
本章說明如何將ANTLR添加到Maven項目中。 如果您使用Eclipse且尚未安裝m2eclipse插件,請從http://download.eclipse.org/technology/m2e/releases更新站點進行安裝。 這將使您的生活更加輕松。
建立專案
創建一個新的Maven項目,并在“選擇原型”屏幕上指定maven-archetype-quickstart。 如果不使用Eclipse,則命令mvn archetype:generate可以達到相同的效果。
相依性
將ANTLR依賴項添加到pom.xml中 :
org.antlrantlr3.3jarcompile注意:由于ANTLR沒有向后兼容的歷史記錄,因此最好指定所需的版本。
外掛程式
Antlr maven插件在generate-sources階段運行,并從語法(.g)文件生成lexer和parser java類。 將其添加到pom.xml中 :
org.antlrantlr3-maven-plugin3.3run antlrgenerate-sourcesantlr 創建src/main/antlr3文件夾。 該插件希望其中包含所有語法文件。
生成的文件放在target/generated-sources/antlr3目錄中。 由于此目錄不在默認的maven構建路徑中,因此我們使用build-helper-maven-plugin將其添加到該目錄中:
org.codehaus.mojobuild-helper-maven-pluginadd-sourcegenerate-sourcesadd-source${basedir}/target/generated-sources/antlr3如果使用eclipse,則必須更新項目配置:右鍵單擊項目->'maven'->'更新項目配置'。
測試一下
調用maven以測試項目配置:右鍵單擊項目->'Run As'->'Maven generate-sources'。 或者,使用mvn generate-sources命令。
構建應該成功。 控制臺輸出應包含antlr3-maven-plugin插件輸出:
[INFO] --- antlr3-maven-plugin:3.3:antlr (run antlr) @ antlr-step-by-step ---
[INFO] ANTLR: Processing source directory C:\meri\ANTLR\workspace\antlr-step-by-step\src\main\antlr3
[INFO] No grammars to process
ANTLR Parser Generator Version 3.3 Nov 30, 2010 12:46:29它之后應該是build-helper-maven-plugin插件輸出:
[INFO] --- build-helper-maven-plugin:1.7:add-source (add-source) @ antlr-step-by-step ---
[INFO] Source directory: C:\meri\ANTLR\workspace\antlr-step-by-step\target\generated-sources\antlr3 added.此階段的結果位于github上,標記為001-configured_antlr 。
你好字
我們將創建最簡單的語言解析器– hello word解析器。 它通過一個表達式構建一個小的抽象語法樹:“ Hello word!”。
我們將使用它來顯示如何創建語法文件并從中生成ANTLR類。 然后,我們將展示如何使用生成的文件并創建單元測試。
第一個語法文件
Antlr3-maven-plugin在src/main/antlr3目錄中搜索語法文件。 它使用語法為每個子目錄創建新程序包,并在其中生成解析器和詞法分析器類。 由于我們希望將類生成到org.meri.antlr_step_by_step.parsers包中,因此我們必須創建src/main/antlr3/org/meri/antlr_step_by_step/parsers目錄。
語法名稱和文件名必須相同。 文件必須帶有.g后綴。 此外,每個語法文件都以語法名稱聲明開頭。 我們的S001HelloWord語法從以下幾行開始:
grammar S001HelloWord;聲明之后始終是生成器選項。 我們正在研究Java項目,希望將表達式編譯成抽象語法樹:
options {// antlr will generate java lexer and parserlanguage = Java;// generated parser should create abstract syntax treeoutput = AST;
} Antlr不會在生成的類之上生成包聲明。 我們必須使用@parser::header和@lexer::header塊來實施它。 標頭必須遵循選項塊:
@lexer::header {package org.meri.antlr_step_by_step.parsers;
}@parser::header {package org.meri.antlr_step_by_step.parsers;
}每個語法文件必須至少具有一個詞法分析器規則。 每個詞法分析器規則必須以大寫字母開頭。 我們有兩個規則,第一個定義一個稱呼令牌,第二個定義一個endsymbol令牌。 稱呼必須為“ Hello word”,并且結尾符號必須為“!”。
SALUTATION:'Hello word';
ENDSYMBOL:'!';同樣,每個語法文件必須至少具有一個解析器規則。 每個解析器規則必須以小寫字母開頭。 我們只有一個解析器規則:我們語言中的任何表達式都必須由稱呼后跟一個結尾符號組成。
expression : SALUTATION ENDSYMBOL;注意:語法文件元素的順序是固定的。 如果更改它,則antlr插件將失敗。
生成詞法分析器和解析器
使用mvn generate-sources命令或從Eclipse從命令行生成詞法分析器和解析器:
- 右鍵單擊該項目。
- 點擊“運行方式”。
- 單擊“ Maven生成源”。
Antlr插件將創建target / generated-sources / antlr / org / meri / antlr_step_by_step / parsers文件夾,并將S001HelloWordLexer.java和S001HelloWordParser.java文件放入其中。
使用Lexer和Parser
最后,我們創建編譯器類。 它只有一種公共方法,該方法:
- 調用生成的詞法分析器將輸入拆分為令牌,
- 調用生成的解析器以根據令牌構建AST,
- 將結果AST樹打印到控制臺中,
- 返回抽象語法樹。
編譯器位于S001HelloWordCompiler類中:
public CommonTree compile(String expression) {try {//lexer splits input into tokensANTLRStringStream input = new ANTLRStringStream(expression);TokenStream tokens = new CommonTokenStream( new S001HelloWordLexer( input ) );//parser generates abstract syntax treeS001HelloWordParser parser = new S001HelloWordParser(tokens);S001HelloWordParser.expression_return ret = parser.expression();//acquire parse resultCommonTree ast = (CommonTree) ret.tree;printTree(ast);return ast;} catch (RecognitionException e) {throw new IllegalStateException("Recognition exception is never thrown, only declared.");} 注意:不必擔心在S001HelloWordParser.expression()方法上聲明的RecognitionException異常。 它永遠不會被拋出。
測試它
在本章結束時,我們將使用一個針對新編譯器的小測試用例。 創建S001HelloWordTest類:
public class S001HelloWordTest {/*** Abstract syntax tree generated from "Hello word!" should have an * unnamed root node with two children. First child corresponds to * salutation token and second child corresponds to end symbol token.* * Token type constants are defined in generated S001HelloWordParser * class.*/@Testpublic void testCorrectExpression() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Hello word!");CommonTree leftChild = ast.getChild(0);CommonTree rightChild = ast.getChild(1);//check ast structureassertEquals(S001HelloWordParser.SALUTATION, leftChild.getType());assertEquals(S001HelloWordParser.ENDSYMBOL, rightChild.getType());}}測試將成功通過。 它將抽象語法樹打印到控制臺:
0 null-- 4 Hello word-- 5 !IDE中的語法
在編輯器中打開S001HelloWord.g并進入解釋器選項卡。
- 在左上方視圖中突出顯示表達式規則。
- 寫下“你好字!” 進入右上視圖。
- 按左上角的綠色箭頭。
解釋器將生成解析樹:

復制語法
本教程中的每個新語法都基于先前的語法。 我們匯總了將舊語法復制到新語法所需的步驟列表。 使用它們將OldGrammar復制到NewGrammar:
- 將OldGrammar.g復制到同一目錄中的NewGrammar.g 。
- 將語法聲明更改為
grammar NewGrammar; - 生成解析器和詞法分析器。
- 創建類似于先前的OldGrammarCompiler類的新類NewGrammarCompiler 。
- 創建類似于先前的OldGrammarTest類的新測試類NewGrammarTest 。
沒有適當的錯誤處理,沒有任何任務真正完成。 生成的ANTLR類盡可能嘗試從錯誤中恢復。 它們的確向控制臺報告錯誤,但是沒有現成的API可以以編程方式查找語法錯誤。
如果我們只構建命令行編譯器,那可能很好。 但是,假設我們正在為我們的語言構建GUI,或將結果用作其他工具的輸入。 在這種情況下,我們需要對所有生成的錯誤進行API訪問。
在本章的開始,我們將嘗試默認錯誤處理并為其創建測試用例。 然后,我們將添加一個簡單的錯誤處理,只要發生第一個錯誤,該處理都會引發異常。 最后,我們將轉到“真實”解決方案。 它將在內部列表中收集所有錯誤并提供訪問它們的方法。
作為副產品,本章介紹了如何:
- 將自定義catch子句添加到解析器規則中 ,
- 向生成的類中添加新的方法和字段 ,
- 覆蓋生成的方法 。
默認錯誤處理
首先,我們將嘗試解析各種不正確的表達式。 目的是了解默認的ANTLR錯誤處理行為。 我們將從每個實驗中創建測試用例。 所有測試用例都位于S001HelloWordExperimentsTest類中。
表達式1 : Hello word?
結果樹與正確的樹非常相似:
0 null-- 4 Hello word-- 5 ?<missing ENDSYMBOL>控制臺輸出包含錯誤:
line 1:10 no viable alternative at character '?'
line 1:11 missing ENDSYMBOL at '<eof>'測試用例 :以下測試用例通過均沒有問題。 不會引發異常,并且抽象語法樹節點類型與正確的表達式中的相同。
@Testpublic void testSmallError() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Hello word?");//check AST structureassertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType());assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType());} 表情2 : Bye!
結果樹與正確的樹非常相似:
0 null-- 4 <missing>-- 5 !</missing>控制臺輸出包含錯誤:
line 1:0 no viable alternative at character 'B'
line 1:1 no viable alternative at character 'y'
line 1:2 no viable alternative at character 'e'
line 1:3 missing SALUTATION at '!'測試用例 :以下測試用例通過均沒有問題。 不會引發異常,并且抽象語法樹節點類型與正確的表達式中的相同。
@Testpublic void testBiggerError() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Bye!");//check AST structureassertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType());assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType());} 表達式3 : Incorrect Expression
結果樹只有根節點,沒有子節點:
0控制臺輸出包含很多錯誤:
line 1:0 no viable alternative at character 'I'
line 1:1 no viable alternative at character 'n'
line 1:2 no viable alternative at character 'c'
line 1:3 no viable alternative at character 'o'
line 1:4 no viable alternative at character 'r'
line 1:5 no viable alternative at character 'r'
line 1:6 no viable alternative at character 'e'
line 1:7 no viable alternative at character 'c'
line 1:8 no viable alternative at character 't'
line 1:9 no viable alternative at character ' '
line 1:10 no viable alternative at character 'E'
line 1:11 no viable alternative at character 'x'
line 1:12 no viable alternative at character 'p'
line 1:13 no viable alternative at character 'r'
line 1:14 no viable alternative at character 'e'
line 1:15 no viable alternative at character 's'
line 1:16 no viable alternative at character 's'
line 1:17 no viable alternative at character 'i'
line 1:18 no viable alternative at character 'o'
line 1:19 no viable alternative at character 'n'
line 1:20 mismatched input '<EOF>' expecting SALUTATION測試用例 :我們終于找到一個表達式,該表達式導致不同的樹結構。
@Testpublic void testCompletelyWrong() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Incorrect Expression");//check AST structureassertEquals(0, ast.getChildCount());}Lexer中的錯誤處理
每個詞法分析器規則“ RULE”對應于生成的詞法分析器中的“ mRULE”方法。 例如,我們的語法有兩個規則:
SALUTATION:'Hello word';
ENDSYMBOL:'!';并且生成的詞法分析器有兩種相應的方法 :
public final void mSALUTATION() throws RecognitionException {// ...
}public final void mENDSYMBOL() throws RecognitionException {// ...
} 根據拋出的異常,lexer可能會也可能不會嘗試從中恢復。 但是,每個錯誤都以reportError(RecognitionException e)方法結尾。 生成的詞法分析器繼承它:
public void reportError(RecognitionException e) {displayRecognitionError(this.getTokenNames(), e);}結果:我們必須在lexer中更改reportError或displayRecognitionError方法。
解析器中的錯誤處理
我們的語法只有一個解析器規則“表達式”:
expression SALUTATION ENDSYMBOL; 該表達式對應于生成的解析器中的expression()方法:
public final expression_return expression() throws RecognitionException {//initializationtry {//parsing}catch (RecognitionException re) {reportError(re);recover(input,re);retval.tree = (Object) adaptor.errorNode(input, retval.start, input.LT(-1), re);} finally {}//return result;
}如果發生錯誤,解析器將:
- 向控制臺報告錯誤,
- 從錯誤中恢復
- 將錯誤節點(而不是普通節點)添加到抽象語法樹。
解析器中的錯誤報告比lexer中的錯誤報告稍微復雜一些:
/** Report a recognition problem.** This method sets errorRecovery to indicate the parser is recovering* not parsing. Once in recovery mode, no errors are generated.* To get out of recovery mode, the parser must successfully match* a token (after a resync). So it will go:** 1. error occurs* 2. enter recovery mode, report error* 3. consume until token found in resynch set* 4. try to resume parsing* 5. next match() will reset errorRecovery mode** If you override, make sure to update syntaxErrors if you care about that.*/public void reportError(RecognitionException e) {// if we've already reported an error and have not matched a token// yet successfully, don't report any errors.if ( state.errorRecovery ) {return;}state.syntaxErrors++; // don't count spuriousstate.errorRecovery = true;displayRecognitionError(this.getTokenNames(), e);}這次我們有兩個可能的選擇:
- 通過自己的處理替換解析器規則方法中的catch子句,
- 覆蓋解析器方法。
Antlr提供了兩種方法來更改解析器中生成的catch子句。 我們將創建兩個新的語法,每個語法都演示一種方法。 在這兩種情況下,我們都會使解析器在第一個錯誤時退出。
首先,我們可以將rulecatch添加到新S002HelloWordWithErrorHandling語法的解析器規則中:
expression : SALUTATION ENDSYMBOL;
catch [RecognitionException e] {//Custom handling of an exception. Any java code is allowed.throw new S002HelloWordError(":(", e);
}當然,我們必須將S002HelloWordError異常的導入添加到headers塊中 :
@parser::header {package org.meri.antlr_step_by_step.parsers;//add imports (see full line on Github)import ... .S002HelloWordWithErrorHandlingCompiler.S002HelloWordError;
}編譯器類與以前幾乎相同。 它聲明了新的異常:
public class S002HelloWordWithErrorHandlingCompiler extends AbstractCompiler {public CommonTree compile(String expression) {// no change here}@SuppressWarnings("serial")public static class S002HelloWordError extends RuntimeException {public S002HelloWordError(String arg0, Throwable arg1) {super(arg0, arg1);}}
}然后,ANTLR將用我們自己的處理方式替換表達式規則方法中的默認catch子句:
public final expression_return expression() throws RecognitionException {//initializationtry {//parsing}catch (RecognitionException re) {//Custom handling of an exception. Any java code is allowed.throw new S002HelloWordError(":(", e); } finally {}//return result;
}通常, 語法 , 編譯器類和測試類在Github上都可用。
或者,我們可以將rulecatch規則放在標題塊和第一個lexer規則之間。 S003HelloWordWithErrorHandling語法演示了此方法:
//change error handling in all parser rules
@rulecatch {catch (RecognitionException e) {//Custom handling of an exception. Any java code is allowed.throw new S003HelloWordError(":(", e);}
}我們必須將S003HelloWordError異常的導入添加到標頭塊中:
@parser::header {package org.meri.antlr_step_by_step.parsers;//add imports (see full line on Github)import ... .S003HelloWordWithErrorHandlingCompiler.S003HelloWordError;
}編譯器類與前面的情況完全相同。 ANTLR將替換所有解析器規則中的默認catch子句:
public final expression_return expression() throws RecognitionException {//initializationtry {//parsing}catch (RecognitionException re) {//Custom handling of an exception. Any java code is allowed.throw new S003HelloWordError(":(", e); } finally {}//return result;
}同樣,Github提供了語法 , 編譯器類和測試類 。
不幸的是,這種方法有兩個缺點。 首先,它僅在解析器中不適用于lexer。 其次,默認報告和恢復功能以合理的方式工作。 它嘗試從錯誤中恢復。 一旦開始恢復,就不會產生新的錯誤。 僅當解析器未處于錯誤恢復模式時,才會生成錯誤消息。
我們喜歡此功能,因此我們決定僅更改錯誤報告的默認實現。
我們會將所有詞法分析器/解析器錯誤存儲在私有列表中。 此外,我們將在生成的類中添加兩個方法:
- hasErrors –如果發生至少一個錯誤,則返回true,
- getErrors –返回所有生成的錯誤。
在@members塊內添加了新的字段和方法:
@lexer::members {//everything you need to add to the lexer
}@parser::members {//everything you need to add to the parser
}成員塊必須放在標題塊和第一個詞法分析器規則之間。 該示例的語法為S004HelloWordWithErrorHandling :
//add new members to generated lexer
@lexer::members {//add new fieldprivate List<RecognitionException> errors = new ArrayList <RecognitionException> ();//add new methodpublic List<RecognitionException> getAllErrors() {return new ArrayList<RecognitionException>(errors);}//add new methodpublic boolean hasErrors() {return !errors.isEmpty();}
}//add new members to generated parser
@parser::members {//add new fieldprivate List<RecognitionException> errors = new ArrayList <RecognitionException> ();//add new methodpublic List<RecognitionException> getAllErrors() {return new ArrayList<RecognitionException>(errors);}//add new methodpublic boolean hasErrors() {return !errors.isEmpty();}
}生成的詞法分析器和生成的解析器都包含用member塊編寫的所有字段和方法。
要覆蓋生成的方法,請執行與要添加新方法相同的操作,例如,將其添加到@members塊中:
//override generated method in lexer
@lexer::members {//override methodpublic void reportError(RecognitionException e) {errors.add(e);displayRecognitionError(this.getTokenNames(), e);}
}//override generated method in parser
@parser::members {//override methodpublic void reportError(RecognitionException e) {errors.add(e);displayRecognitionError(this.getTokenNames(), e);}
}現在,reportError方法將覆蓋lexer和parser中的默認行為。
收集編譯器中的錯誤
最后,我們必須更改編譯器類。 新版本將在輸入解析階段之后收集所有錯誤:
private List<RecognitionException> errors = new ArrayList<RecognitionException>();public CommonTree compile(String expression) {try {... init lexer ...... init parser ...ret = parser.expression();//collect all errorsif (lexer.hasErrors())errors.addAll(lexer.getAllErrors());if (parser.hasErrors())errors.addAll(parser.getAllErrors());//acquire parse result... as usually ...} catch (RecognitionException e) {...}
}/**
* @return all errors found during last run
*/
public List<RecognitionException> getAllErrors() {return errors;
}解析器完成工作后,我們必須收集詞法分析器錯誤。 從它調用詞法分析器,之前沒有任何錯誤。 像往常一樣,我們將語法 , 編譯器類和測試類放在Github上。
下載antlr分步項目的標記003-S002-to-S004HelloWordWithErrorHandling ,以查找同一java項目中的所有三種錯誤處理方法。
參考: ANTLR教程–我們的JCG合作伙伴 Maria Jurcovicova在This is Stuff博客上的問候語。
翻譯自: https://www.javacodegeeks.com/2012/04/antlr-tutorial-hello-word.html















java策略模式)
)


