一、論文
- 研究領域: 城市級3D語義分割
- 論文:Efficient Urban-scale Point Clouds Segmentationwith BEV Projection
- 清華大學,新疆大學
- 2021.9.19
- 論文github
- 論文鏈接
二、論文概要
2.1主要思路
提出了城市級3D語義分割新的方法,將3D點云語義分割任務轉移到2D鳥瞰圖分割問題。 分為以下三步:3D到BEV投影、稀疏BEV圖像分割和BEV到3D重新映射。

注: BEV: Bird's Eye View
BEV投影是指鳥瞰視角(Bird's Eye View,簡稱BEV)的一種從上方觀看對象或場景的視角,就像鳥在空中俯視地面一樣。在自動駕駛和機器人領域,通過傳感器(如LiDAR和攝像頭)獲取的數據通常會被轉換成BEV表示,以便更好地進行物體檢測、路徑規劃等 。
2.1.1 實現步驟
- 3D到BEV投影?
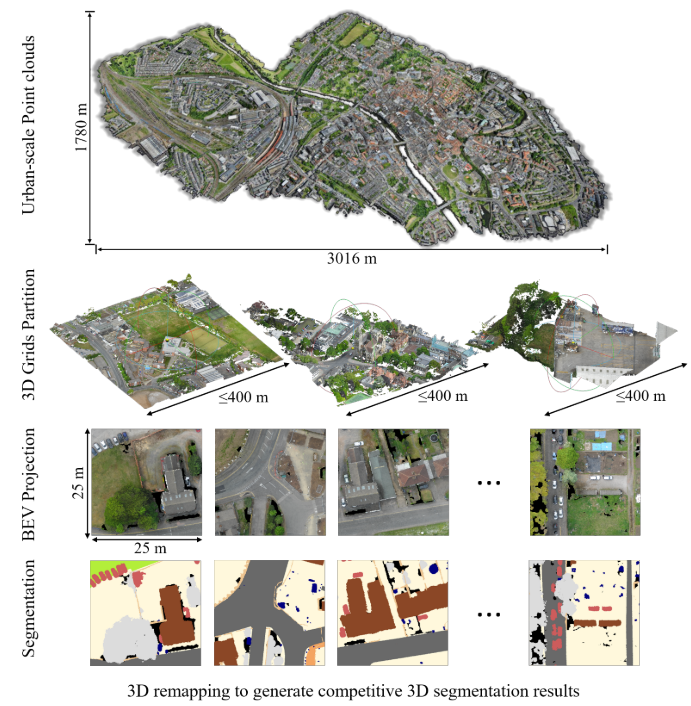
1、城市規模的點云地圖被預先劃分成邊長小于400米的網格。
2、我們進一步生成了25× 25 m2的正方形,放大倍數為20倍。
使用滑動窗口來得到BEV投影,偽代碼如下:
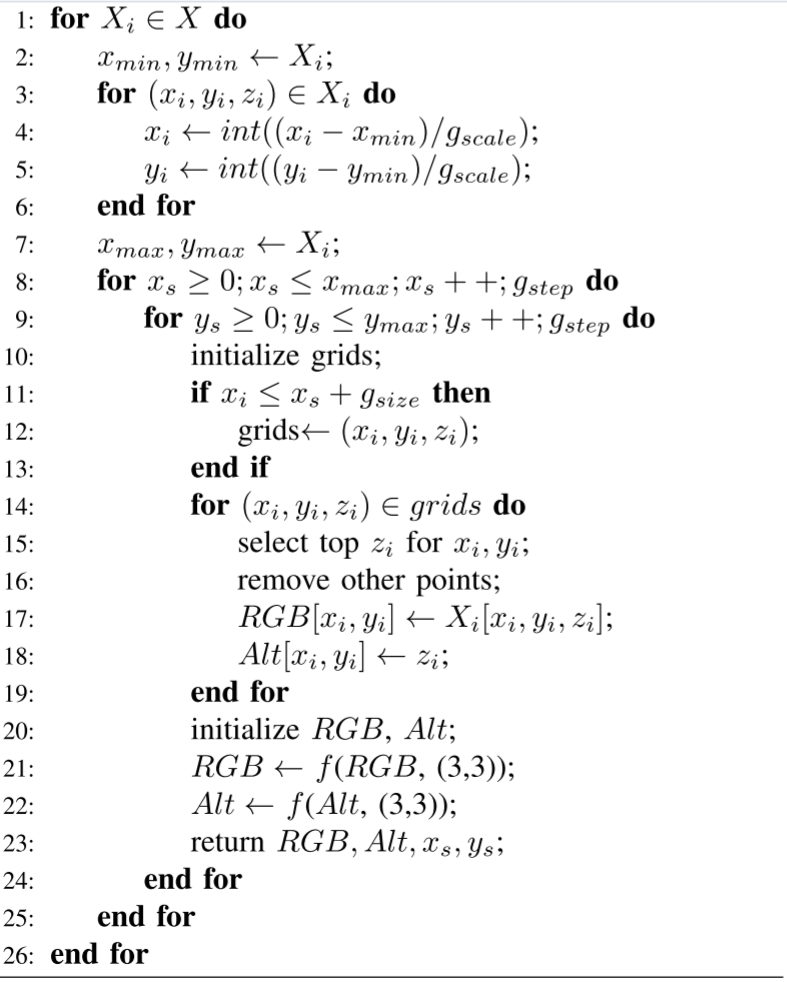
?
- 稀疏BEV圖像分割?
考慮到BEV圖像上投影點云的顯著稀疏性,這將在標記和模型學習中引入嚴重的噪聲,因此有必要對投影進行像素級完成,特別是對于不同類點周圍的內部區域和邊緣。在我們的實驗中,我們迭代地對每個圖像中的每個通道進行三次2D最大池化。標簽的漸進變化如圖4所示。

對于從左到右,我們呈現原始BEV標簽和具有一次/兩次/三次最大池化完成的標簽。
BEV投影生成的圖像,設計了一個基于注意力的多模態融合網絡,有效地融合了RGB和幾何細節。與單模態網絡相比,分割效果取得了一定的提高,進一步驗證了RGB顏色對分割的意義。?
?
- BEV到3D重新映射
對于3D重映射,我們存儲每個投影窗口的絕對x/y坐標,并使用主題查詢原始大規模點云中的提取位置以獲得2D分割輸出。對應于相同像素的點將被賦值為與像素相同的類。之后,我們能夠評估3D語義分割性能。
2.2 主要貢獻
1、針對大規模無人機點云數據稀疏、處理負擔重的問題,設計了一種大規模無人機點云數據預處理方法,即將三維點云投影到密集的鳥瞰圖上。
2、對于BEV投影生成的圖像,設計了一個基于注意力的多模態融合網絡,有效地融合了RGB和幾何細節。與單模態網絡相比,分割效果取得了一定的提高,進一步驗證了RGB顏色對分割的意義。?
提出了一種新的方法,并設計了一種新的圖像分割網絡。
?
2.3 實驗表現
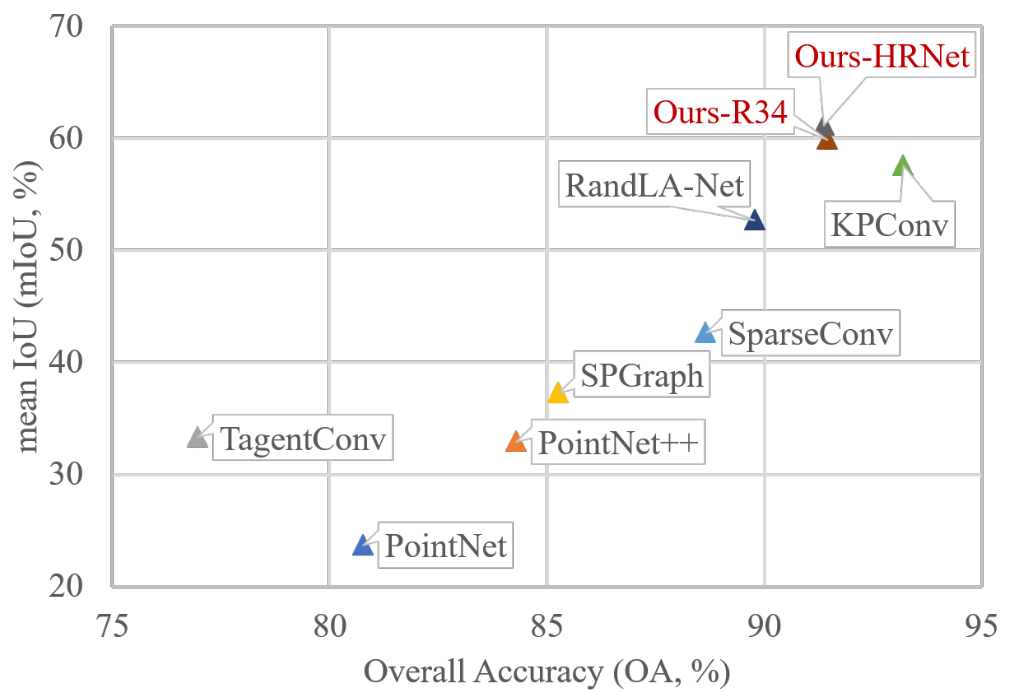
?與其他已發表方法的比較結果。我們使用ResNet-34和HRNet實現了我們的模型,這兩個模型都在SensatUrban數據集上實現了具有競爭力的平均IoU和整體準確性。
三、論文全文
基于BEV投影的城市尺度點云高效分割
摘要:近年來,點云分析已經吸引了研究人員的目光,而3D語義分割仍然是一個問題。大多數深度點云模型直接在3D點云上進行學習,這將受到城市規模數據嚴重稀疏和極端數據處理負載的影響。為了解決這一挑戰,我們建議將三維點云轉移到密集的鳥瞰圖投影。在這種情況下,由于類不平衡減少和利用各種2D分割方法的可行性,分割任務被簡化。我們進一步設計了一個基于注意力的融合網絡,可以對投影圖像進行多模態學習。最后,2D輸出被重新映射以生成3D語義分割結果。為了證明我們的方法的好處,我們在SensatUrban數據集上進行了各種實驗,其中我們的模型呈現出競爭力的評估結果(61.17% mIoU和91.37% OverallAccuracy)。我們希望我們的工作可以啟發進一步探索點云分析。
- 介紹
3D語義分割是點云學習的關鍵技術,其目的是為每個單獨的點數據分配語義標簽,已廣泛應用于自動駕駛[1],虛擬現實[2],3D重建[3]等。雖然深度學習在2D語義分割任務中表現突出,但它無法直接處理不規則,無序和非結構化的點數據[4]。因此,目前有幾種方法[5]-[11]將非結構化點轉換為某些有效的中間表示,例如體素[7],[12]和多視圖[10],[13],[14],以利用經典CNN模型處理點云。隨著對三維場景理解需求的不斷增加,提出了越來越多的三維點云數據集。從室內數據集(例如,S3DIS [15]和ScanNet [16])到道路級數據集(例如,SemanticKITTI [17]),數據集的空間大小也更大。最近的工作[3],[18]提出了城市級數據集,為大規模數據集的語義分割帶來了一些新的挑戰。
- 室內數據集(例如,S3DIS [15]和ScanNet [16])
- 道路級數據集(例如,SemanticKITTI [17]),數據集的空間大小也更大
- [3],[18]提出了城市級數據集
與基于LiDAR的數據集不同,這些城市規模的點云大多是從無人機攝影測量中獲得的,這可能導致數據集中的以下特征。首先,無人機攝影測量的掃描不均勻,掃描區域不集中,捕獲的圖像邊緣有散亂的區域。其次,重建的點云部分缺失。我們在SensatUrban [3]數據集中觀察到這種現象,一個典型的例子是,在對點云進行可視化后,屋頂下沒有對應的墻點,這使得屋頂似乎懸浮在空中。有趣的是,我們發現基于無人機的點云中垂直點的類別重疊率較低,例如,SensatUrban為2.3%,這意味著鳥瞰圖是一種合適的投影方法,它更簡單,更有效,并且能夠最大限度地保留點細節。
此外,對于投影圖像,具有更豐富標記的2D像素級數據集可以用于預訓練。因此,在本文中,我們提出了一個BEV投影分割方法來處理城市規模的三維分割問題。
我們的主要貢獻是:
1)對城市規模的點云進行點級分析;
2)提出了一種基于BEV投影算法的多模態融合分割模型;
3)我們在SensatUrban數據集上對我們的方法進行了評估,我們的競爭結果證明了我們設計的有效性。
- 相關工作
A.語義分割
通常,根據輸入網絡的點云數據的形式,現有的大多數3D語義分割方法可以分為三類:基于點、基于3D表示和基于投影。
基于點的方法直接處理原始點云,其代表方法是PointNet,計算開銷大。雖然[19],[20]對PointNet進行了一些有益的改進,但由于這些方法直接處理sprase數據,因此仍然難以加速。最近的RandLA-Net [2]引入了隨機采樣和輕型網絡架構,大大加快了模型的速度。然而,如[21]中所提到的,基于點的方法中不可忽視的問題是,由低效的隨機存儲器訪問引起的處理sprase數據的大量時間浪費(80%),這意味著實際上只有少量的時間用于提取特征。此外,大的存儲器開銷也是一個嚴重的問題。
基于3D表示的方法將原始點云數據變換成某些3D表示(例如,體素和晶格),然后利用3D卷積[5]-[8]。然而,很難平衡分辨率和內存之間的關系[21],[22]。分辨率越低,同一網格中的點融合在一起,導致點云信息丟失越嚴重。分辨率越高,計算開銷和內存使用量越大。此外,預處理和后處理步驟需要大量時間[23]。
- 分辨率越低,同一網格中的點融合在一起,導致點云信息丟失越嚴重。
- 分辨率越高,計算開銷和內存使用量越大
基于投影的方法利用成熟的2D卷積模型來處理從3D點云投影的圖像,而不是直接處理點。基于投影的方法包括幾個特定的類別,如多視圖,基于球面的方法。多視圖方法[10],[13],[14]將點云投影到多個虛擬相機視圖中。例如,[10]利用多流CNN來處理從每個視圖生成的圖像,然后融合每個點的不同圖像的預測分數,[13]定義了旋轉相機并提出了Katz投影來選擇每個相機角度中的點,[14]在不同的相機位置生成深度圖像和RGB圖像。[24]利用球面投影方法將三維點云轉換為圖像,利用SqueezeSeg網絡進行分割,并應用條件隨機場(CRF)對分割結果進行優化。[11]提出了基于SqueezeSeg的上下文聚合模塊(CAM)來擴展感受野,并且[4]引入了空間自適應卷積(SAC)來進一步提高分割精度。
基于投影的方法包括幾個特定的類別:
- 多視圖方法[10],[13],[14]將點云投影到多個虛擬相機視圖中。
- 利用球面投影方法將三維點云轉換為圖像
?B 大規模場景的語義分割
在最近的工作中,已經提出了幾個由無人機拍攝的城市尺度3D點云數據集[3],[18],[25],其中最大的是SensatUrban [3]數據集,其覆蓋面積為7.64×106 m2,具有30億個注釋點。然而,這些大而密集的數據集給語義分割帶來了新的挑戰。
城市尺度3D點云數據集:?
- 最大的是SensatUrban
首先,面對海量數據,預處理方法的選擇,例如,數據分區、下采樣等。意義重大。其次,城市規模點云存在類分布不均衡的問題。第三,基于無人機的數據集和基于激光雷達的數據集之間的一個顯著差異是,前者包含RGB特征。對于大規模數據集,是否將RGB特征納入網絡以及如何有效地利用RGB特征值得考慮。最近的工作,例如RandLA-Net [2]和BAAF-Net [23]利用RGB顏色并取得了積極的分割結果。對于BEV投影生成的圖像,我們設計了一個基于注意力的多模型融合網絡,有效地融合了RGB和幾何細節。與單模態網絡相比,分割效果取得了一定的提高,進一步驗證了RGB顏色對分割的意義。
海量數據預處理方法:
- 數據分區
- 下采樣等
近年來,已經提出了幾種針對大型數據集的語義分割算法[2],[9],[26],[27]。例如,RandLA-Net [2]引入了隨機采樣以提高計算和內存的效率,TagentConv [9]利用基于切線卷積的U型網絡進行大型和密集數據集的語義分割,SPGraph [27]提出了一種新的點云表示(SPG),能夠捕獲3D點的上下文結構。需要提出更多的大規模點云分割算法。
- 方法:
A?問題陳述
3D點云語義分割的目的是為每個單獨的點分配語義標簽,而2D分割是為每個像素分配特定的標簽。在某種程度上,這兩種類型的任務具有相似的目的和解決方案。根據我們上面的陳述,可以將3D點云語義分割任務轉移到2D鳥瞰圖分割問題。主要過程包括鳥瞰圖映射和2D多模態分割。
B?鳥瞰投影為什么合理
當我們將一個任務轉移到另一個任務時,它要求輸入數據和預期輸出的一致性。為了評估我們的想法,我們在構建模型之前進行點級分析。我們首先將3D點投影到BEV圖上(將在下文中詳細描述)并計算重疊率。在投影中以0.04m為單位進行坐標縮放時,約有25.44%的點會丟失。對于那些點密集的地方,比例將提高到50%或更多。然而,我們發現大多數重疊點屬于與頂部點相同的類別。類重疊率低于2.3%,mIoU可達93.7%。在這種情況下,可以將3D分割任務轉移到2D BEV分割。我們的目標是在BEV圖像上進行精確識別。
C?鳥瞰圖
為了優化這種大型點云的數據處理負載,我們將整個工作分為三個部分:3D到BEV投影、稀疏BEV圖像完成和BEV到3D重新映射。?前兩個部分的處理在下面的算法1中被呈現為偽代碼。
我們設置一個滑動窗口來處理點并生成BEV圖像。在投影之前,我們需要初始化參數gscale,gsize ,gstep,它控制滑動窗口的縮放,大小和移動步驟。對于每個滑動步驟,我們通過x/y坐標對點進行排序,并從當前BEV投影窗口開始/結束坐標中查詢點,之后將刪除處理過的點以減少后續數據處理量。為了獲得最佳的參數,我們測試了不同的投影尺度從0.01到0.04的空間重疊率,如圖3所示。當我們將點云的尺度設置在[0.01,0.03]時,會導致點云不同部分的重疊分布非常接近,即城市尺度點云中的點的最小間距在[0.03,0.05](m)以內。此外,根據我們的投影圖像數量估計,合適的窗口長度在[20,50](m)以內。因此,我們將參數設置為gscale = 0.05,gsize = gstep = 25。然而,我們也建議多尺度,多尺寸和多步采樣,以便在未來的工作或其他類似的任務中更好地訓練。
對于單個滑動窗口中的點,我們通過積分x/y坐標將點映射到像素。這將不可避免地帶來值量化的損失,但是,如果我們在3D重映射中進行相同的過程,它不會影響標簽檢索過程。BEV圖使用頂部的點進行更新,生成具有顏色和z坐標值的RGB和海拔(Alt)圖像。考慮到BEV圖像上投影點云的顯著稀疏性,這將在標記和模型學習中引入嚴重的噪聲,因此有必要對投影進行像素級完成,特別是對于不同類點周圍的內部區域和邊緣。在我們的實驗中,我們迭代地對每個圖像中的每個通道進行三次2D最大池化。標簽的漸進變化如圖4所示。
對于從左到右,我們呈現原始BEV標簽和具有一次/兩次/三次最大池化完成的標簽。
對于3D重映射,我們存儲每個投影窗口的絕對x/y坐標,并使用主題查詢原始大規模點云中的提取位置以獲得2D分割輸出。對應于相同像素的點將被賦值為與像素相同的類。之后,我們能夠評估3D語義分割性能。
1、初始化參數gscale,gsize ,gstep,它控制滑動窗口的縮放,大小和移動步驟
- 合適的窗口長度在[20,50](m)以內
- 參數設置為gscale = 0.05,gsize = gstep = 25
2、通過x/y坐標對點進行排序,并從當前BEV投影窗口開始/結束坐標中查詢點,之后將刪除處理過的點以減少后續數據處理量
3、單個滑動窗口中的點,我們通過積分x/y坐標將點映射到像素
3D重映射,我們存儲每個投影窗口的絕對x/y坐標,并使用主題查詢原始大規模點云中的提取位置以獲得2D分割輸出。對應于相同像素的點將被賦值為與像素相同的類
?
D.最大值多模態分割
通過BEV投影的高度和RGB圖像,我們可以利用多模態網絡從數據的不同方面進行學習。為了快速開發一個合適的模型,我們考慮一個編碼器-解碼器網絡UNet作為我們的基線,不僅因為它的流行模型架構,而且因為它在修改,訓練和推理方面的效率。它包括編碼器中的4個塊和解碼器中的5個塊,其中兩個是ResNet-34塊,最后四層使用轉置卷積,其余是卷積塊。所有卷積塊都有一個批量歸一化層和一個ReLU層,所有內核大小都是3x 3。編碼器中的每個塊都用虛線鏈接到解碼器中的相應塊,該虛線將它們的輸出連接起來以檢索低級特征。
通常,多模態融合依賴于各層中的特征通信。在此基礎上,提出了一種靈活的多級融合網絡,支持不同時間、不同地點的多管道數據融合。熔合層包括若干恒定形狀的熔合塊。每個塊接受來自兩個管道的兩個相等形狀的張量,并采用注意力層從連接的特征圖中選擇關鍵通道。以這種方式,熔合塊傾向于丟棄不相關的特征,并且熔合在隨后的層中容易被激活的那些特征。對于注意力塊,我們參考我們以前的工作??,提出了一種用于語義分割的跨通道多模態融合注意塊。之后,我們添加1x1卷積以降低維度,并針對圖像特征和融合特征、海拔特征和融合特征重復這樣的融合塊。重要的是外塊保持特征圖的恒定形狀,這意味著我們可以根據需要堆疊具有各種網絡形狀的無限塊。
- 實驗
?A setup?
數據集:SensatUrban [3]在英國3個大城市采集,包含2847M個點,覆蓋真實的世界7.64× 106m2的面積,是目前最大的3D點云數據集。在獲得無人機拍攝的區域圖像序列后,從這些圖像重建SensatUrban點云數據集。它包含13個語義類,包括地面、建筑物、交通道路等大類和自行車、鐵路、橋梁等小類。在實驗中,37個點云用于訓練,6個點云用于測試。每個點包含三維坐標、RGB顏色和語義類的特征。請注意,由于缺乏測試集標簽,我們將訓練集隨機分為4:1,使用80%的數據進行訓練,使用20%的數據進行測試。所有測試數據都不用于訓練。
度量:我們將我們的模型與幾個使用不同方法(例如,基于點的方法、基于投影的方法等)并且最近出版。選擇平均IoU(mIoU)和總體準確度(OA)作為評價指標。
實施情況:我們在訓練中使用交叉熵作為損失函數。考慮到不同類間的不平衡性,我們使用對數倒數權值來調整學習中的損失。我們將批處理大小設置為8,將輸入大小設置為投影大小500 x500。我們的模型在兩個GPU上訓練,RTX 3090具有24 G RAM和E5- 2678 v3 CPU。此外,我們使用以下軟件設置:Ubuntu 16.04 64位操作系統,Python 3.6,gcc5.4.0,PyTorch 1.7與CUDA 11.0硬件加速。
B. Results
我們使用三個主干實現了我們的模型,UNet和ResNet34,Deeplabv3和ResNet101,OCRNet和HRNet。最后兩個模型被訓練以探索在我們的BEV分割框架下的潛在性能。我們在表I中展示了分割結果(重新映射到3D點云并在3D中進行評估)。與現有的模型相比,我們的模型可以實現相當有競爭力的結果,在大多數classed和整體performancee在OA,mAcc,和mIoU。缺點是我們的BEV分割仍然無法識別一些小物體,如自行車,因為它們在投影圖像中占用的像素也非常有限。在未來的工作中,融合3D和我們的BEV模型可能會解決這個問題。可視化如圖5所示。
- CONCLUSION
針對大規模無人機點云數據稀疏、處理負擔重的問題,設計了一種大規模無人機點云數據預處理方法,即將三維點云投影到密集的鳥瞰圖上。此外,我們還提出了一種基于注意力的多模態融合網絡來分割生成的二維圖像,充分利用RGB顏色和幾何信息。我們在SensatUrban數據集上獲得了61.17%的mIoU和91.37%的OverallAccuracy測試結果。我們希望我們的工作可以啟發大規模的點云語義分割任務。








)

)

)

軟件調試---將調試工具安裝到AeDebug(11))

gramm矯正+直方圖均衡化)


)