簡介:?
Prometheus是一個開源的系統監控和告警系統,由Google的BorgMon監控系統發展而來。它主要用于監控和度量各種時間序列數據,比如系統性能、網絡延遲、應用程序錯誤等。Prometheus通過采集監控數據并存儲在時間序列數據庫中,然后使用PromQL查詢語言進行數據分析和可視化。
以下是Prometheus基本使用的一些技術:
- 安裝和配置:了解如何安裝和配置Prometheus,包括Prometheus Server、Exporters和Pushgateway等組件。
- 數據采集:學習如何使用Prometheus采集各種監控數據,包括系統性能、網絡延遲、應用程序錯誤等。
- 數據存儲:了解Prometheus如何將采集的監控數據存儲在時間序列數據庫中,以及如何使用本地磁盤、遠程存儲等不同的存儲后端。
- 數據查詢和分析:學習如何使用PromQL查詢語言對監控數據進行查詢和分析,以及如何通過可視化工具進行數據展示。
- 告警規則:學習如何創建和管理告警規則,以及如何將告警發送給不同的接收器,比如電子郵件、Slack、PagerDuty等。
- 數據可視化:了解如何使用Prometheus提供的儀表盤界面展示監控數據和告警狀態,以及如何通過拖放和自定義配置來創建自己的儀表盤。
- 服務發現:學習如何使用各種服務發現機制,比如Kubernetes、EC2、GCE等,以自動發現和監控服務的運行狀態。
- 安全和權限控制:了解Prometheus如何提供安全和權限控制的機制,如身份驗證、授權等,以確保數據的訪問安全。
基本使用以及認識配置:
安裝和配置:了解如何安裝和配置Prometheus,包括Prometheus Server、Exporters和Pushgateway等組件。
Prometheus Server
????????Prometheus Server是Prometheus組件中的核心部分,負責實現對監控數據的獲取、存儲以及查詢。
????????首先,Prometheus Server可以通過靜態配置管理監控目標,也可以配合使用Service Discovery的方式動態管理監控目標,并從這些監控目標中獲取數據。這意味著Prometheus Server可以根據預設的規則發現并監控各種服務和目標,無論是靜態配置的目標還是動態發現的目標。
????????其次,Prometheus Server需要對采集到的數據進行存儲。Prometheus Server本身就是一個時序數據庫,它將采集到的監控數據按照時間序列的方式存儲在本地磁盤當中。這種存儲方式使得Prometheus Server可以有效地保存大量的時間序列數據,并且可以在后續進行快速的數據查詢和分析。
????????最后,Prometheus Server提供了自定義的PromQL語言,用戶可以使用PromQL實現對數據的查詢以及分析。同時,Prometheus Server還提供了HTTP API,用戶可以使用這些API通過編程方式查詢數據。另外,Prometheus Server的聯邦集群能力可以使其從其他的Prometheus Server實例中獲取數據,從而實現監控數據的共享和統一管理。
????????總之,Prometheus Server是Prometheus生態圈中的核心組件,它負責采集、存儲和查詢監控數據,為用戶提供了一個全面和實時的監控解決方案
Exporters
????????Exporters是Prometheus中的一個組件,負責將特定應用程序或服務的監控數據暴露給Prometheus。Exporters可以將應用程序的監控數據轉換為Prometheus能夠識別的格式,并通過HTTP或其他方式將數據發送給Prometheus。
????????Exporters的主要作用是擴展Prometheus的監控能力,使其能夠監控到更多類型的應用程序和服務。由于不同類型的應用程序和服務的監控數據格式可能不同,因此需要不同的Exporters來實現對它們的監控。
????????Prometheus的生態系統提供了許多常見的Exporters,比如Node Exporter用于監控系統性能,Redis Exporter用于監控Redis數據庫,MySQL Exporter用于監控MySQL數據庫等。用戶可以根據需要選擇合適的Exporters來擴展Prometheus的監控能力。
????????除了使用現有的Exporters,用戶還可以根據需要自定義自己的Exporters。自定義的Exporters可以根據應用程序的特定需求來實現對監控數據的采集和轉換。
????????總之,Exporters是Prometheus中非常重要的組件,它們擴展了Prometheus的監控能力,使其能夠監控更多類型的應用程序和服務。用戶可以根據需要選擇使用現有的Exporters,或者自定義自己的Exporters來實現對特定應用程序的監控。
? ? ? ? 本專欄中會更新部署Exporters的方式方法。
Pushgateway
????????Pushgateway是Prometheus的一種組件,用于接收來自短期作業的指標數據。
????????由于Prometheus主要通過pull模式獲取監控數據,但是某些短時作業可能不支持輪詢,或者因為網絡原因無法被Prometheus直接拉取數據,這時就可以使用Pushgateway。用戶可以通過編寫自定義的腳本將需要監控的數據發送給Pushgateway,然后Pushgateway再將數據推送給對應的Prometheus服務。
????????Pushgateway可以單獨運行在任何節點上,不需要運行在被監控的客戶端。它可以將接收到的監控數據存儲在本地磁盤中,并且支持自定義的時間序列存儲方式。同時,Pushgateway還提供了HTTP API,用戶可以使用這些API通過編程方式將數據推送到Pushgateway中。
????????總之,Pushgateway是Prometheus中一個重要的組件,它主要用于接收來自短期作業的指標數據,解決了Prometheus無法直接獲取這些數據的問題。
了解配置文件書寫:
要根據我們現實的配置文件來進行定制化的書寫
要注意的是在docker中使用這些配置的時候,最好還是掛載數據卷的形式來掛載出來。
Prometheus的配置文件通常包含以下幾種類型:
rule_files:規則文件,用于配置告警規則和數據聚合配置。scrape_configs:采集配置,用于指定要采集的目標列表和采集規則。static_configs:靜態配置,用于指定要采集的目標列表。global:全局配置,包含全局默認配置,如抓取監控數據的間隔、抓取業務數據接口的超時時間、告警規則執行周期等。alerting:告警配置,用于配置告警發送到的Alertmanager的地址。remote_write?和?remote_read:遠程寫入和讀取配置,用于將數據投遞到遠程地址或者從遠程地址讀取數據。
上述的配置文件都是在prometheus.yml中去進行書寫的。
下面分別介紹一下這些配置文件的作用:
rule_files:該配置文件用于指定告警規則文件的位置。告警規則文件包含用于觸發告警的條件和操作。這些規則文件可以基于聚合的數據進行定義,以便進行更復雜的告警邏輯。scrape_configs:該配置文件用于指定要采集的目標列表和采集規則。它包含每個目標的服務地址、端口、請求超時等信息,以及如何從目標中抓取數據和數據處理規則等。static_configs:該配置文件是靜態配置,用于手動指定要采集的目標列表。與scrape_configs不同,這里的配置不能動態添加或刪除目標,因此適用于穩定的環境。global:該配置文件包含全局默認配置,如抓取監控數據的間隔、抓取業務數據接口的超時時間、告警規則執行周期等。這些配置會影響整個Prometheus系統的運行方式。alerting:該配置文件用于指定告警發送到的Alertmanager的地址。Alertmanager是一個獨立的組件,用于處理和發送告警信息。通過配置該文件,Prometheus可以將告警信息發送給Alertmanager進行處理。remote_write?和?remote_read:這兩個配置文件用于將數據投遞到遠程地址或者從遠程地址讀取數據。這使得Prometheus可以與其他系統進行集成,實現更強大的數據分析和處理能力。例如,可以將采集到的監控數據遠程寫入到其他的存儲系統,或者從遠程地址讀取數據進行進一步的分析和處理。
需要注意的是,Prometheus的配置文件通常需要在使用前進行適當的修改和調整,以滿足特定環境和需求的要求。
配置文件基本案例
rule_files:
rule_files用于指定告警規則文件的位置。這些規則文件包含用于觸發告警的條件和操作。例如,可以基于聚合的數據進行定義,以便進行更復雜的告警邏輯。
rule_files:- "first_rules.yml"- "second_rules.yml"
上述配置指定了兩個規則文件,分別是"first_rules.yml"和"second_rules.yml"。Prometheus會加載這些規則文件并應用其中的告警規則。
具體案例:
當提到?rule_files?時,是指在使用某個特定系統或應用程序時,用于定義告警規則的文件。這些文件通常使用特定的格式和語法,以便根據條件觸發告警。
以下是一個示例?first_rules.yml?文件的內容,其中包含一個告警規則的示例:
# first_rules.ymlrules:- name: "Example Rule"conditions:- metric: "CPU Usage"operator: "<"threshold: 80actions:- email: "example@example.com"subject: "High CPU Usage Alert"message: "The CPU usage has exceeded the threshold of 80%."
在上述示例中,規則文件包含一個名為 "Example Rule" 的規則。該規則定義了一個條件,該條件監視 "CPU Usage" 指標,并使用 "<" 運算符檢查是否小于閾值 80。如果條件滿足,則執行相應的操作。在此示例中,操作包括發送電子郵件給指定的電子郵件地址,主題為 "High CPU Usage Alert",消息包含有關告警的詳細信息。
請注意,具體的規則文件格式和語法可能因使用的系統或應用程序而有所不同。上述示例僅用于說明目的,并可能需要根據所使用的特定工具進行調整。
scrape_configs:
方式1使用配置書寫配置文件的方式來發現服務等:
scrape_configs用于指定要采集的目標列表和采集規則。它包含每個目標的服務地址、端口、請求超時等信息,以及如何從目標中抓取數據和數據處理規則等。
scrape_configs:- job_name: 'example_app'scrape_interval: 5sstatic_configs:- targets: ['app1.example.com:8080', 'app2.example.com:8080']
上述配置定義了一個名為"example_app"的采集任務,使用靜態配置指定了兩個目標服務地址,分別為"app1.example.com:8080"和"app2.example.com:8080"。同時,設置了抓取間隔為5秒。
方式2使用額外的配置文件來發現服務:
scrape_configs:- job_name: "服務發現"file_sd_configs:- files:- /prometheus/ClientAll/*.json # 用json格式文件方式發現服務,下面的是用yaml格式文件方式,都可以refresh_interval: 10m- files:- /prometheus/ClientAll/*.yaml # 用yaml格式文件方式發現服務refresh_interval: 10m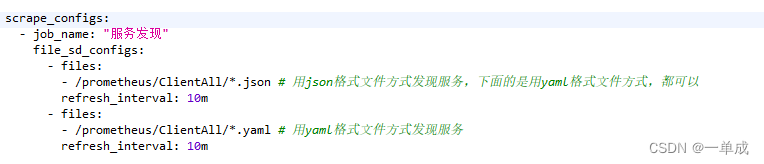
?配置文件解讀:
這個配置文件是一個Prometheus的配置文件片段,用于配置服務發現(Service Discovery)。服務發現是一種自動檢測和跟蹤系統中的服務及其關系的方法,這樣Prometheus就可以自動發現并監控這些服務。
在配置文件中,scrape_configs是一個數組,其中包含一個或多個配置項。每個配置項都是一個字典,包含了一些鍵值對來定義一個特定的服務發現配置。
在這個例子中,有兩個配置項:
job_name: "服務發現"?- 這個配置項定義了監控任務的名稱為"服務發現"。file_sd_configs?- 這個鍵對應的值是一個數組,其中包含兩個字典,每個字典都定義了一種不同的服務發現方式。
a. 第一個字典:
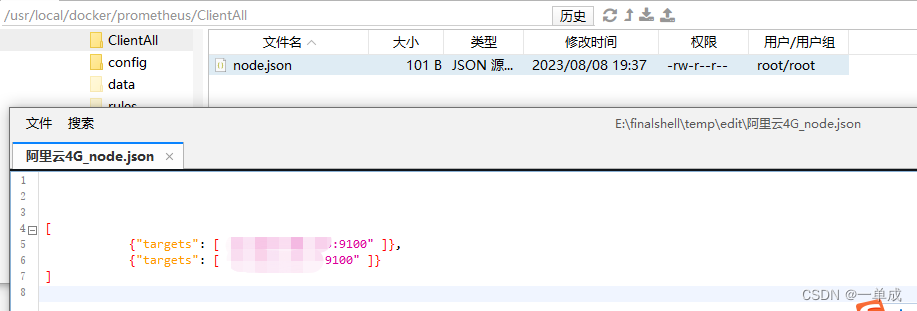
* `files` - 這個鍵對應的值是一個列表,其中包含一個文件路徑`/prometheus/ClientAll/*.json`。這表示Prometheus將從該路徑下查找所有滿足正則表達式`*.json`的JSON文件。這些文件通常包含了關于服務的元數據和配置信息。
* `refresh_interval` - 這個鍵對應的值是一個字符串`10m`,表示每隔10分鐘刷新一次服務發現配置。
* 總的來說,這個配置告訴Prometheus從指定的路徑下讀取JSON文件,然后根據這些文件的內容來自動發現并監控服務,并且每隔10分鐘刷新一次服務發現配置。
b. 第二個字典:
* `files` - 這個鍵對應的值是一個列表,其中包含一個文件路徑`/prometheus/ClientAll/*.yaml`。這表示Prometheus將從該路徑下查找所有滿足正則表達式`*.yaml`的YAML文件。這些文件通常也包含了關于服務的元數據和配置信息。
* `refresh_interval` - 這個鍵對應的值也是`10m`,表示每隔10分鐘刷新一次服務發現配置。
* 總的來說,這個配置告訴Prometheus從指定的路徑下讀取YAML文件,然后根據這些文件的內容來自動發現并監控服務,并且每隔10分鐘刷新一次服務發現配置。
通過這樣的配置,Prometheus可以根據不同的文件格式(JSON或YAML)和服務描述信息自動發現并監控服務。這對于動態環境或需要自動擴展的服務非常有用,因為當服務發生變化時,Prometheus可以自動更新其監控配置并開始監控新的服務
static_configs:
static_configs是靜態配置,用于手動指定要采集的目標列表。與scrape_configs不同,這里的配置不能動態添加或刪除目標,因此適用于穩定的環境。
static_configs:- targets: ['target1.example.com:8080']
上述配置手動指定了一個目標服務地址為"target1.example.com:8080",不能動態添加或刪除目標。
global:
global包含全局默認配置,如抓取監控數據的間隔、抓取業務數據接口的超時時間、告警規則執行周期等。這些配置會影響整個Prometheus系統的運行方式。
global:scrape_interval: 10sevaluation_interval: 10s
上述配置設置了全局的抓取間隔為10秒,告警規則執行周期也為10秒。
alerting:
在使用這個的時候要提前準備好并安裝好?alertmanager這個組件
假裝有連接
alerting用于指定告警發送到的Alertmanager的地址。Alertmanager是一個獨立的組件,用于處理和發送告警信息。通過配置該文件,Prometheus可以將告警信息發送給Alertmanager進行處理。
alerting:alertmanagers:- static_configs:- targets: ['alertmanager1.example.com:9093']
上述配置指定了告警發送到的Alertmanager地址為"alertmanager1.example.com:9093"。
看到這里有同志會出現疑惑了?
我使用的是Prometheus+Grafana那么到底我使用誰來給我發送告警呢?
我解讀一下子
在這兩個組合中的Grafana是一個可視化平臺,是沒有發送預警的能力的所以,發送告警的只能是Prometheus。
Alertmanager是一個獨立的組件,用于處理和發送告警信息。在Prometheus中,Alertmanager被用于接收Prometheus發送的告警信息,然后對這些信息進行處理,例如將告警信息路由到不同的接收者、對告警進行靜默或抑制等操作,最后將告警信息發送給接收者。
在配置文件中,alerting部分用于指定告警發送到的Alertmanager的地址。上述配置中的alerting: alertmanagers: - static_configs: - targets: ['alertmanager1.example.com:9093']指定了告警發送到的Alertmanager地址為"alertmanager1.example.com:9093"。
在這個配置中,alertmanagers是一個列表,其中每個元素都包含了一個static_configs部分。static_configs是一個字典,其中的targets鍵對應的值是一個列表,包含了Alertmanager的地址。在這個例子中,只有一個地址'alertmanager1.example.com:9093'。
通過這樣的配置,Prometheus可以將告警信息發送給指定的Alertmanager進行處理。
一個使用Alertmanager這個獨立組件進行發送郵件和釘釘的告警案例
Alertmanager提供了一種方式來配置接收告警信息的通知接收器(receiver)。通知接收器定義了一組與告警相關的操作,例如發送電子郵件、發送短信、將告警信息存儲到某個系統等。通過配置通知接收器,您可以指定在Prometheus觸發告警時應該執行的操作。
以下是一個示例Alertmanager配置文件的一部分,用于配置一個發送電子郵件的通知接收器:
global:smtp_smarthost: 'smtp.example.com:587'smtp_from: 'alertmanager@example.com'smtp_auth_username: 'alertmanager'smtp_auth_password: 'password'smtp_require_tls: falsereceivers:
- name: 'email'email_configs:- to: 'alerts@example.com'from: 'alertmanager@example.com'subject: '[Alertmanager] Alerts for {{ .接收器的名字 }}'smtp_auth:username: 'alertmanager'password: 'password'smtp_smarthost: 'smtp.example.com:587'require_tls: false
在這個配置中,我們定義了一個名為"email"的通知接收器,并指定了一個發送電子郵件的配置。您可以根據您的需求修改這個配置,例如修改郵件的接收者、發件人、主題等。
然后,您需要在Alertmanager的配置文件中指定這個通知接收器。以下是一個示例Alertmanager配置文件的一部分:
route:receiver: 'email'
在這個配置中,我們指定了當Alertmanager接收到告警信息時,應該將它們發送到名為"email"的通知接收器。
最后,您需要將Alertmanager的配置文件部署到Alertmanager所在的服務器上,并確保Alertmanager可以讀取和加載這個配置文件。然后,當Prometheus觸發告警時,Alertmanager將根據配置發送相應的郵件通知。
Alertmanager和rule_files之間存在關聯
Alertmanager是一個用于管理和發送告警信息的組件,而rule_files是配置告警規則的文件。
在Prometheus中,告警規則是基于Prometheus表達式語言的表達式進行定義的,用于檢測特定情況并觸發告警。這些規則被存儲在rule_files中。Alertmanager通過讀取rule_files中的規則,對Prometheus發送的告警信息進行匹配和后續處理。
Alertmanager的配置文件可以指定多個rule_files,每個文件包含一組告警規則。通過將這些規則文件與Alertmanager的配置文件進行關聯,可以實現對告警信息的處理和通知。
以下是一個示例Alertmanager配置文件中的相關部分,用于指定rule_files的路徑:
global:# rule_files字段指定了告警規則文件的路徑rule_files:- 'rules/basic_rules.yml'- 'rules/complex_rules.yml'
在這個配置中,我們指定了兩個規則文件:basic_rules.yml和complex_rules.yml。Alertmanager將讀取這兩個文件中的告警規則,并根據這些規則對接收到的告警信息進行匹配和后續處理。
通過配置rule_files,可以根據您的需求定義和管理告警規則,并將這些規則與Alertmanager的配置文件進行關聯,以便在Prometheus觸發告警時執行相應的操作。
在這些告警中怎么去指定我要使用哪一個 rule_files
在Alertmanager的配置文件中,可以通過指定rule_files字段來選擇要使用的告警規則文件。rule_files字段接受一個字符串列表,每個字符串表示一個規則文件的路徑。可以在配置文件中添加或修改rule_files字段來指定要使用的規則文件。
以下是一個示例Alertmanager配置文件的部分內容,展示了如何指定要使用的規則文件:
global:# rule_files字段指定了告警規則文件的路徑rule_files:- 'path/to/rule_file_1.yml'- 'path/to/rule_file_2.yml'route:# route字段指定了告警處理和通知的路由規則receiver: 'ReceiverName'
在這個示例中,我們指定了兩個規則文件:'path/to/rule_file_1.yml'和'path/to/rule_file_2.yml'。Alertmanager將按照在rule_files中定義的順序讀取這些規則文件。可以根據需要修改或添加更多的規則文件,只需將它們的路徑添加到rule_files列表中即可。
請確保在修改Alertmanager的配置文件后,將其部署到Alertmanager所在的服務器上,并確保Alertmanager可以讀取和加載這個配置文件。這樣,當Prometheus觸發告警時,Alertmanager將根據指定的規則文件進行匹配和處理。
告警的使用Alertmanager的案例
????????當使用Alertmanager發送告警時,可以通過配置rule_files來實現針對特定情況的告警規則。下面是一個示例,展示了如何使用Alertmanager和rule_files來發送告警,包括將告警信息發送到釘釘和郵件中。
????????首先,確保已經安裝并配置了Alertmanager和Prometheus,并已經創建了用于發送釘釘和郵件的接收者。
創建規則文件:
創建一個名為rules/alerting_rules.yml的規則文件,其中包含以下內容:
groups:
- name: alerting_rulesinterval: 1mrules:- alert: AlertNameexpr: some_metric > 100for: 1mlabels:severity: highannotations:summary: High value detecteddescription: An alert has been triggered for the 'some_metric' metric exceeding 100.
在這個規則文件中,我們定義了一個名為AlertName的告警規則,使用了表達式some_metric > 100來檢測超過100的值。告警會在指標超過100持續1分鐘的情況下觸發。我們為告警設置了標簽severity: high和注釋信息summary和description。
配置Alertmanager的接收者:
根據您的需求,配置Alertmanager的接收者以接收并處理告警信息。例如,如果您使用了釘釘作為接收者,請按照釘釘接收者的配置進行設置。如果您使用了電子郵件作為接收者,請按照電子郵件接收者的配置進行設置。確保接收者的配置正確并已啟用。
以下是一個示例Alertmanager配置文件(alertmanager.yml)中的相關部分,用于指定釘釘接收者:
global:# 其他配置項...receivers:
- name: 'DingTalkReceiver'dingtalk_config:webhook_url: 'https://oapi.dingtalk.com/robot/send?access_token=your_access_token'send_resolved: trueroute:receiver: 'DingTalkReceiver'
在這個示例中,我們創建了一個名為DingTalkReceiver的接收者,并配置了釘釘的相關信息,包括webhook URL和發送已解決的告警。我們還將該接收者指定為默認的接收者(receiver: 'DingTalkReceiver')。
配置Prometheus的告警規則:
在Prometheus中,您需要將規則文件中的告警規則導入到Prometheus中。使用以下命令將規則文件導入到Prometheus:
kubectl apply -f rules/alerting_rules.yml
-
啟動Alertmanager和Prometheus:
啟動Alertmanager和Prometheus服務,確保它們正在運行。您可以使用以下命令啟動Alertmanager:
kubectl apply -f alertmanager.yml
-
觸發告警:
為了觸發告警,您可以手動觸發滿足告警規則的條件。在Prometheus中,您可以使用pushgateway來模擬數據并觸發告警規則。例如,使用以下命令將模擬數據推送到pushgateway:
curl -X POST -H "Content-Type: application/json" --data '{"some_metric": 200}' http://<pushgateway_address>:<pushgateway_port>/metrics/job/alerting_rules/instance/prometheus-k8s-01/prometheus-k8s-01/default/alerting_rules/DingTalkReceiver/alertname/AlertName/severity/high/summary/High value detected/description/An alert has been triggered for the 'some_metric' metric exceeding 100. --header "Content-Type: application/json"
-
查看告警信息:
一旦滿足告警規則的條件,P·1·1·1·1·1rometheus將發送告警信息給Alertmanager。Alertmanager將根據配置的接收者發送告警信息。在本例中,我們將通過釘釘接收告警信息。您可以在釘釘中查看收到的告警信息。
以上是一個簡單的示例,展示了如何使用Alertmanager和rule_files發送告警信息到釘釘和郵件中。您可以根據實際需求進行相應的調整和配置。
本專欄中會專門出關于組件Alertmanager的講解文章。
remote_write 和 remote_read:
remote_write和remote_read用于將數據投遞到遠程地址或者從遠程地址讀取數據。這使得Prometheus可以與其他系統進行集成,實現更強大的數據分析和處理能力。例如,可以將采集到的監控數據遠程寫入到其他的存儲系統,或者從遠程地址讀取數據進行進一步的分析和處理。
remote_write:- url: "http://remote-write-url"write_relabel_configs:- source_labels: ['__address__']regex: '^localhost:(.*)$'target_label: '__address__'replacement: '${1}'- url: "https://another-remote-write-url"...
remote_read:- url: "http://remote-read-url"params: {'match[]': 'some_metric'}- url: "https://another-remote-read-url"...
上述配置使用remote_write將采集到的監控數據遠程寫入到兩個不同的地址,使用write_relabel_configs對目標地址進行重寫。同時,使用remote_read從兩個不同的遠程地址讀取數據,并指定了匹配的指標名。
個人案例:
案例總結:
? ? ? ? 在使用的時候需要指定配置文件的路徑
global:scrape_interval: 15s # 設置抓取間隔為每15秒。evaluation_interval: 15s # 每隔15秒評估規則。rule_files:- /prometheus/rules/*.yml # 這里匹配指定目錄下所有的.rules文件scrape_configs:- job_name: "阿丹服務器" #使用配置來發現服務static_configs:- targets: ['ip:9090']labels:instance: prometheus- job_name: "服務發現"file_sd_configs:- files:- /prometheus/ClientAll/*.json # 用json格式文件方式發現服務,下面的是用yaml格式文件方式,都可以refresh_interval: 10m- files:- /prometheus/ClientAll/*.yaml # 用yaml格式文件方式發現服務refresh_interval: 10m


)

)

)

軟件調試---將調試工具安裝到AeDebug(11))

gramm矯正+直方圖均衡化)


)




