科學、技術、工程、應用
- 科學:是什么、為什么
- 技術:怎么做
- 工程:怎樣做的多快好省
- 應用:怎么使用
定義
機器學習:利用經驗改善系統自身的性能。

研究
智能數據分析(數據分析+算法)
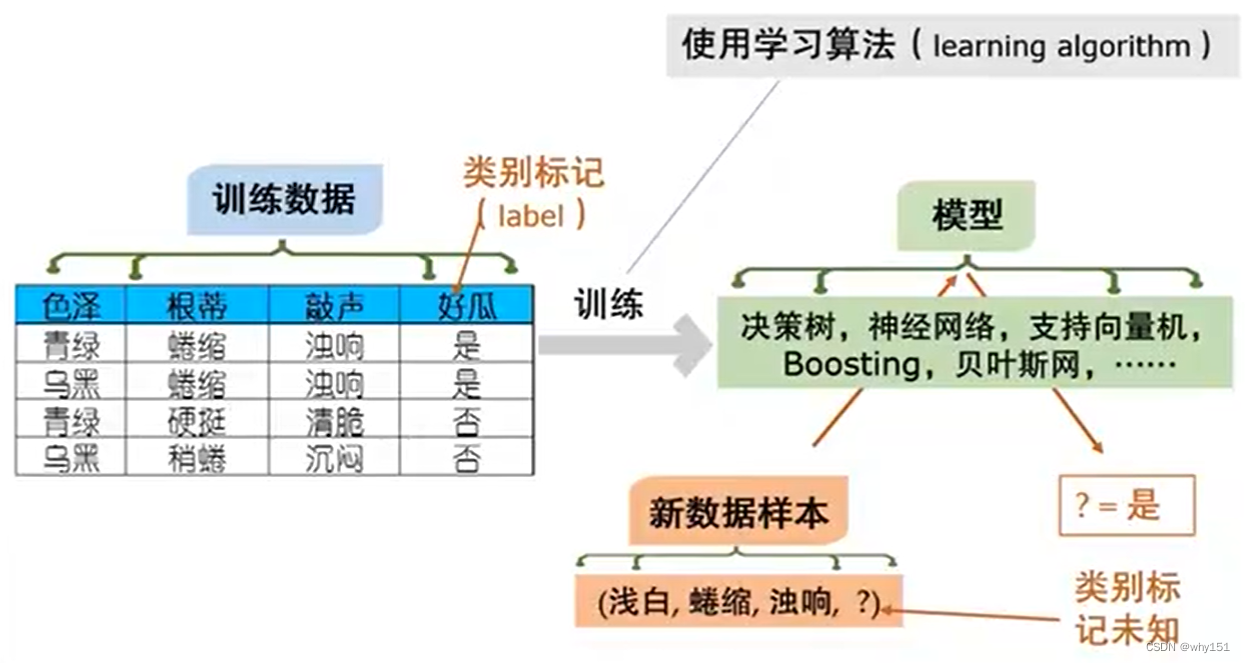
典型的機器學習過程
利用訓練數據,按照某種學習算法訓練出模型,利用模型預測新的樣本數據的標簽。
計算學習理論

- 為什么不追求誤差為0?
- 為什么要使用概率P而不是一個絕對的結果?
機器學習一般用于解決不確定規則的問題,從數據中總結出一定的規則,具有很強的不確定性。
P問題:在多項式時間內找到問題的解。
NP問題:給定n個解,在多項式時間內判斷是不是問題的解。
千禧難題:P=NP?
我們怎么樣在多項式時間內給出最佳結果?或者如何判斷某個解是不是最優的?
如果我們去誤差為0和絕對,那么要求我們每一次都能得到確定的最佳答案。
歸納和演繹
歸納就是從個別到一般,是從多個個別的事物中獲得普遍的規則,例如:黑馬、白馬,可以歸納為馬;
演繹則是從一般到個別,是從普遍性規則推導出個別性規則,例如:基于一組公理和推理規則推導出與之相洽的定理。
假設空間和版本空間

或者西瓜數據集:
假設空間:所有有可能的西瓜屬性值的西瓜樣本。
版本空間:與訓練集一致的假設集合。
基本術語
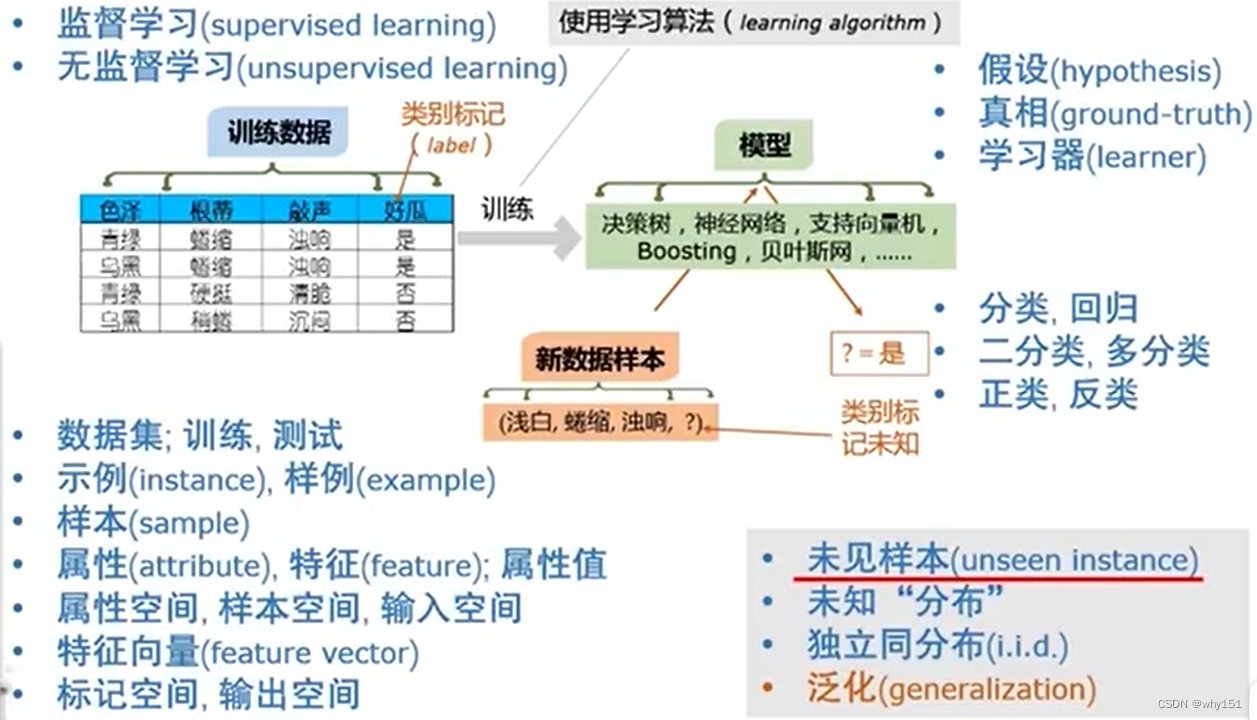
- 假設:學得模型對應了關于數據的某種潛在規則。
- 屬性、樣本、輸入空間:屬性張成的空間。
- 標記空間:標記的集合。
- 泛化能力:學得模型適用于新樣本的能力。
歸納偏好
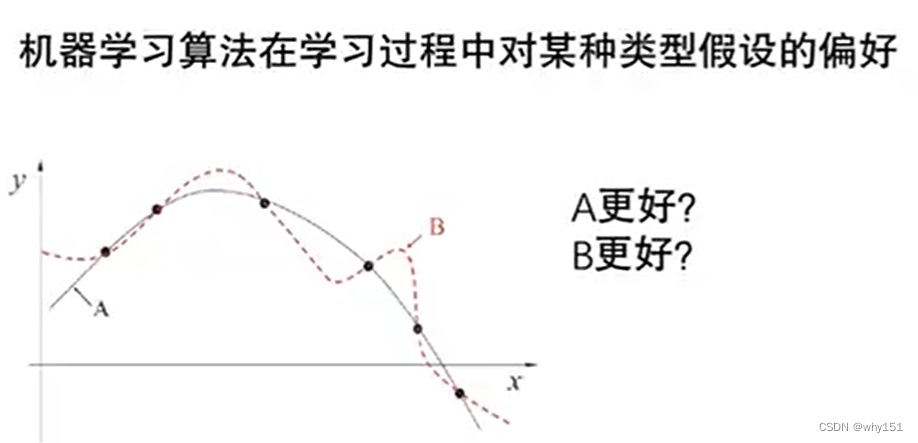
奧卡姆剃刀原則:若非必要,勿增實體。(選最簡單的,更平滑的)
若有多個假設與觀察一致,則選最簡單的那個。
NFL
沒有免費的午餐



泛化能力

思考
機器學習和深度學習的區別?
個人認為:
深度學習是機器學習的一個子集,都是利用現有數據總結經驗的過程。機器學習一般泛指支持向量機、決策樹等不需要利用神經網絡的模型,而深度學習一般是CNN、RNN等含有深層神經網絡的模型。
查找資料:




總結:
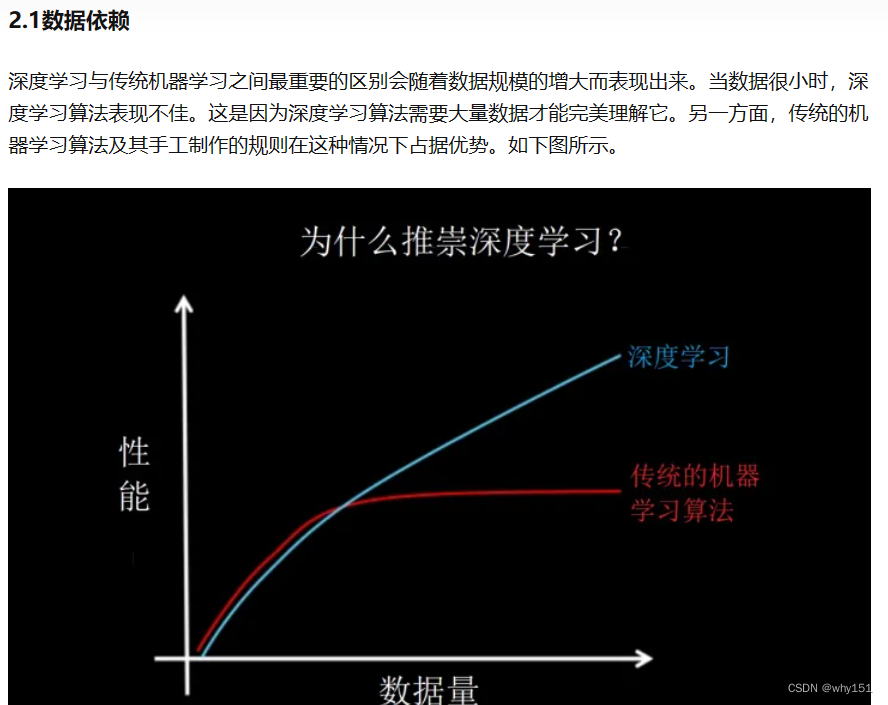
深度學習是機器學習的一個子集,但是一般而言,機器學習一般指支持向量機、決策樹等算法模型,深度學習一般是指CNN、RNN等模型。
兩個的區別主要在于:
1.數據量(深度學習往往需要大量數據,機器學習不是)
2.硬件依賴性(深度學習需要使用GPU進行大量的矩陣運算)
3.特征工程,機器學習的屬性類別往往需要人工編碼,而深度學習可以挖掘出數據的深層特征。例如,對于貓狗分類任務而言,機器學習需要人工總結一些屬性,例如是否有胡須、是否有耳朵等,而深度學習對復雜概念進行連續層次識別,最終找到答案,無需人工尋找屬性。











(基于c語言的補充))
)






