操作系統IO模型與實現原理
阻塞IO 模型

應用程序調用一個IO函數,導致應用程序阻塞,等待數據準備好。如果數據沒有準備好,一直等待….數據準備好了,從內核拷貝到用戶空間,IO函數返回成功指示。
當調用recv()函數時,系統首先查是否有準備好的數據。如果數據沒有準備好,那么系統就處于等待狀態。當數據準備好后,將數據從系統緩沖區復制到用戶空間,然后該函數返回。在套接應用程序中,當調用recv()函數時,未必用戶空間就已經存在數據,那么此時recv()函數就會處于等待狀態。
非阻塞IO模型
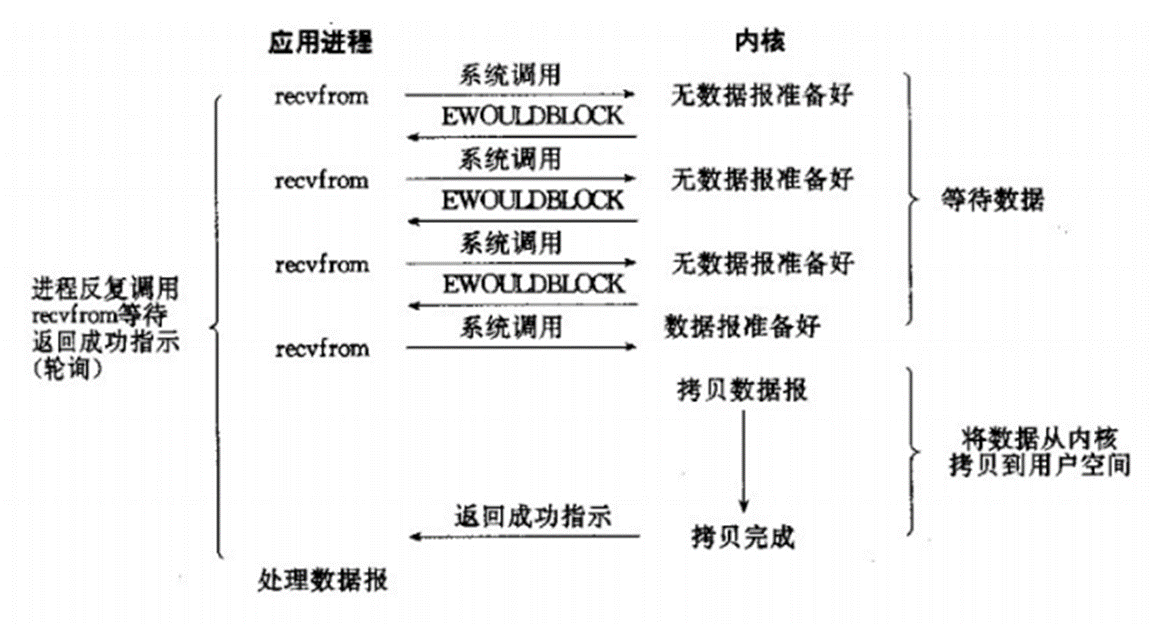
我們把一個SOCKET接口設置為非阻塞就是告訴內核,當所請求的I/O操作無法完成時,不要將進程睡眠,而是返回一個錯誤。這樣我們的I/O操作函數將不斷的測試數據是否已經準備好,如果沒有準備好,繼續測試,直到數據準備好為止。在這個不斷測試的過程中,會大量的占用CPU的時間。上述模型絕不被推薦。
把SOCKET設置為非阻塞模式,即通知系統內核:在調用Windows Sockets API時,不要讓線程睡眠,而應該讓函數立即返回。在返回時,該函數返回一個錯誤代碼。圖所示,一個非阻塞模式套接字多次調用recv()函數的過程。前三次調用recv()函數時,內核數據還沒有準備好。因此,該函數立即返回WSAEWOULDBLOCK錯誤代碼。第四次調用recv()函數時,數據已經準備好,被復制到應用程序的緩沖區中,recv()函數返回成功指示,應用程序開始處理數據。
IO復用模型
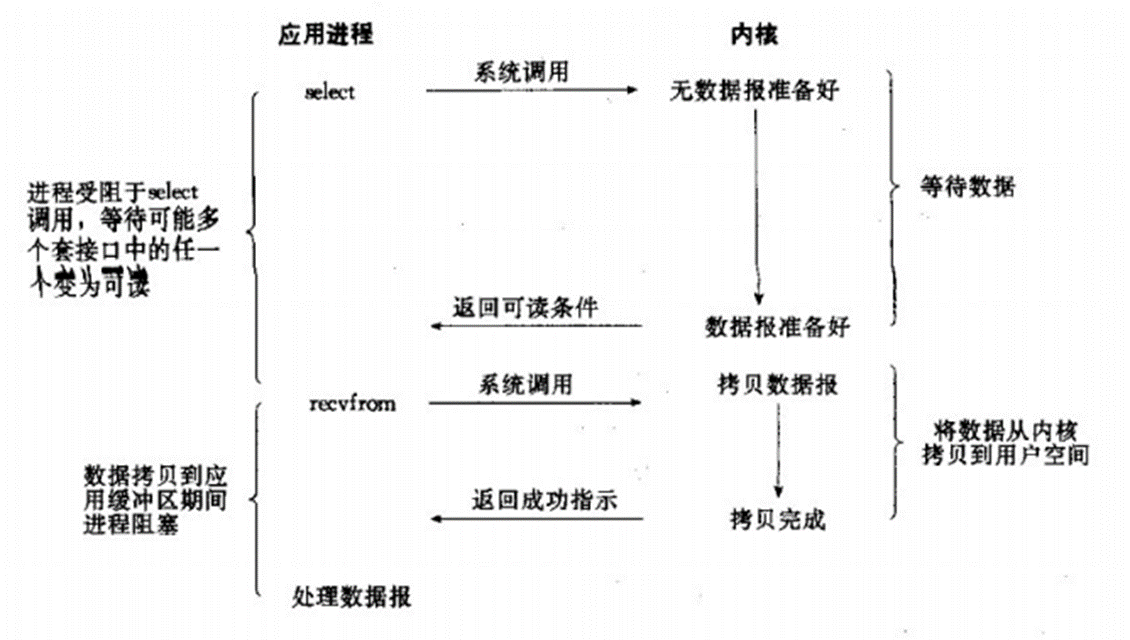
主要是通過select和epoll;對一個IO端口,兩次調用,兩次返回,比阻塞IO并沒有什么優越性;關鍵是能實現同時對多個IO端口進行監聽;
I/O復用模型會用到select、poll、epoll函數,這幾個函數也會使進程阻塞,但是和阻塞I/O所不同的的,這兩個函數可以同時阻塞多個I/O操作。而且可以同時對多個讀操作,多個寫操作的I/O函數進行檢測,直到有數據可讀或可寫時,才真正調用I/O操作函數。
當用戶進程調用了select,那么整個進程會被block;而同時,kernel會“監視”所有select負責的socket;當任何一個socket中的數據準備好了,select就會返回。這個時候,用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。
這個圖和blocking IO的圖其實并沒有太大的不同,事實上還更差一些。因為這里需要使用兩個系統調用(select和recvfrom),而blocking IO只調用了一個系統調用(recvfrom)。但是,用select的優勢在于它可以同時處理多個connection。(select/epoll的優勢并不是對于單個連接能處理得更快,而是在于能處理更多的連接。
信號驅動IO模型

兩次調用,兩次返回;
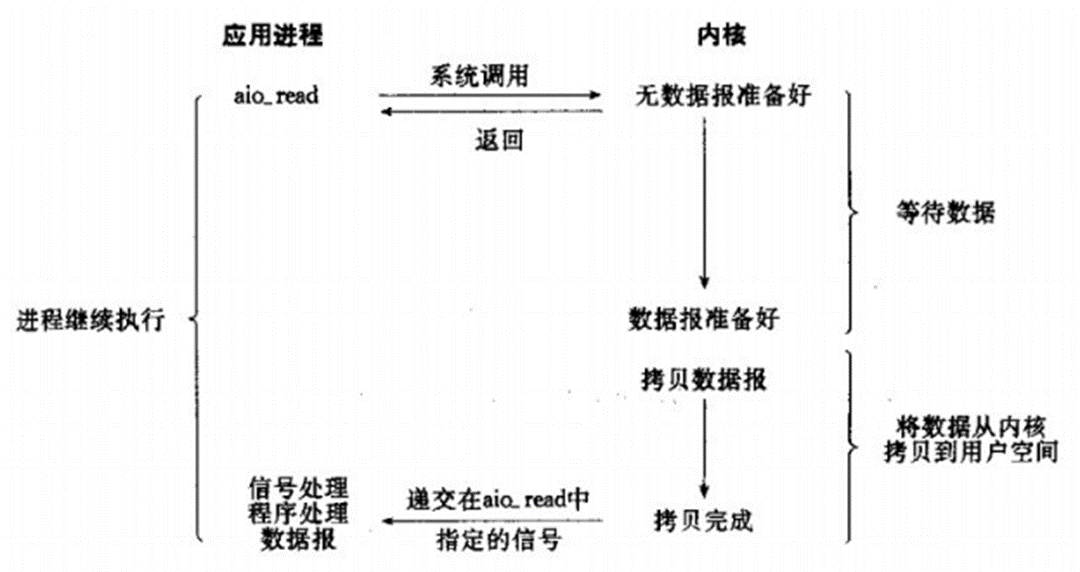
允許套接口進行信號驅動I/O,并安裝一個信號處理函數,進程繼續運行并不阻塞。當數據準備好時,進程會收到一個SIGIO信號,可以在信號處理函數中調用I/O操作函數處理數據。
異步IO模型
簡單進程/線程模型
這是一種非常簡單的模式,服務器啟動后監聽端口,阻塞在accept上,當新網絡連接建立后,accept返回新連接,服務器啟動一個新的進程/線程專門負責這個連接。從性能和伸縮性來說,這種模式是非常糟糕的,原因在于
- 進程/線程創建和銷毀的時間,操作系統創建一個進程/線程顯然需要時間,在一個繁忙的服務器上,如果每秒都有大量的連接建立和斷開,采用每個進程/線程處理一個客戶連接的模式,每個新連接都要創建創建一個進程/線程,當連接斷開時,銷毀對應的線程/進程。創建和銷毀進程/線程的操作消耗了大量的CPU資源。使用鏈接池和線程池可以緩解這個問題。
- 內存占用,主要包含兩方面;一個是內核數據結構所占用的內存空間,另外一個是Stack所占用的內存。有些應用的調用棧很深,比如Java應用,經常能看到幾十上百層的調用棧。
- 上下文切換的開銷;上下文切換時,操作系統的調度器中斷當前線程,選擇另外一個可運行的線程在CPU上繼續運行。調度器需要保存當前線程的現場信息,然后選擇一個可運行的線程,再將新線程的狀態恢復到寄存器中。保存和恢復現場所需要的時間和CPU型號有關,選擇一個可運行的線程則完全是軟件操作,Linux 2.6才開始使用常量時間的調度算法。 以上是上下文切換的直接開銷。除此之外還有一些間接開銷,比如上下文切換導致相關的緩存失效影響程序的性能,但是此類的很多間接開銷很難衡量。
有意思的是,這種模式雖然性能極差,但卻依然是我們今天最常見到的模式,很多Web程序都是這樣的方式在運行。
select/poll
另外一種方式是使用select/poll,在一個線程內處理多個客戶連接。select和poll能夠監控多個socket文件描述符,當某個文件描述符就緒,select/soll從阻塞狀態返回,通知應用程序可以處理用戶連接了。使用這種方式,我們只需要一個線程就可以處理大量的連接,避免了多進程/線程的開銷。之所以把select和poll放在一起說,原因在于兩者非常相似,性能上基本沒有區別,唯一的區別在于poll突破了select 1024個文件描述符的限制,然而當文件描述符數量增加時,poll性能急劇下降,因此所謂突破1024個文件描述符實際上毫無意義。select/poll并不完美,依然存在很多問題:
- 每次調用select/poll,都要把文件描述符的集合從用戶地址空間復制到內核地址空間
- select/poll返回后,調用方必須遍歷所有的文件描述符,逐一判斷文件描述符是否可讀/可寫。
這兩個限制讓select/poll完全失去了伸縮性。連接數越多,文件描述符就越多,文件描述符越多,每次調用select/poll所帶來的用戶空間到內核空間的復制開銷越大。最嚴重的是當報文達到,select/poll返回之后,必須遍歷所有的文件描述符。假設現在有1萬個連接,其中只一個連接發送了請求,但是select/poll就要把1萬個連接全部檢查一遍。
epoll
epoll是如何提供一個高性能可伸縮的IO多路復用機制呢?首先,epoll引入了epoll instance這個概念,epoll instance在內核中關聯了一組要監聽的文件描述符配置:interest list,這樣的好處在于,每次要增加一個要監聽的文件描述符,不需要把所有的文件描述符都配置一次,然后從用戶地址空間復制到內核地址空間,只需要把單個文件描述符復制到內核地址空間,復制開銷從O(n)降到了O(1)。
注冊完文件描述符后,調用epoll_wait開始等待文件描述符事件。epoll_wait可以只返回已經ready的文件描述符,因此,在epoll_wait返回之后,程序只需要處理真正需要處理的文件描述符,而不用把所有的文件描述符全部遍歷一遍。假設在全部N個文件描述符中,只有一個文件描述符Ready,select/poll要執行N次循環,epoll只需要一次。
epoll出現之后,Linux上才真正有了一個可伸縮的IO多路復用機制。基于epoll,能夠支撐的網絡連接數取決于硬件資源的配置,而不再受限于內核的實現機制。CPU越強,內存越大,能支撐的連接數越多。
select、poll、epoll的區別
1、支持一個進程所能打開的最大連接數
| select | 單個進程所能打開的最大連接數有FD_SETSIZE宏定義,其大小是32個整數的大小(在32位的機器上,大小就是32*32,同理64位機器上FD_SETSIZE為32*64),可以對進行修改,然后重新編譯內核,但是性能可能會受到影響。 |
| poll | poll本質上和select沒有區別,但是它沒有最大連接數的限制,原因是它是基于鏈表來存儲的 |
| epoll | 連接數有上限,但是很大,1G內存的機器上可以打開10萬左右的連接,2G內存的機器可以打開20萬左右的連接 |
2、FD劇增后帶來的IO效率問題
| select | 因為每次調用時都會對連接進行線性遍歷,所以隨著FD的增加會造成遍歷速度慢的“線性下降性能問題”。 |
| poll | 同上 |
| epoll | 因為epoll內核中實現是根據每個fd上的callback函數來實現的,只有活躍的socket才會主動調用callback,所以在活躍socket較少的情況下,使用epoll沒有前面兩者的線性下降的性能問題,但是所有socket都很活躍的情況下,可能會有性能問題。 |
3、消息傳遞方式
| select | 內核需要將消息傳遞到用戶空間,都需要內核拷貝動作 |
| poll | 同上 |
| epoll | epoll通過內核和用戶空間共享一塊內存來實現的。 |
什么是TCP粘包半包?
假設場景:使用程序,用客戶端發送100遍消息
假設客戶端分別發送了兩個數據包D1和D2給服務端,由于服務端一次讀取到的字節數是不確定的,故可能存在以下4種情況。
(1)服務端分兩次讀取到了兩個獨立的數據包,分別是D1和D2,沒有粘包和拆包;
(2)服務端一次接收到了兩個數據包,D1和D2粘合在一起,被稱為TCP粘包;
(3)服務端分兩次讀取到了兩個數據包,第一次讀取到了完整的D1包和D2包的部分內容,第二次讀取到了D2包的剩余內容,這被稱為TCP拆包;
(4)服務端分兩次讀取到了兩個數據包,第一次讀取到了D1包的部分內容D1_1,第二次讀取到了D1包的剩余內容D1_2和D2包的整包。
如果此時服務端TCP接收滑窗非常小,而數據包D1和D2比較大,很有可能會發生第五種可能,即服務端分多次才能將D1和D2包接收完全,期間發生多次拆包。
TCP粘包/半包發生的原因
由于TCP協議本身的機制(面向連接的可靠地協議-三次握手機制)客戶端與服務器會維持一個連接(Channel),數據在連接不斷開的情況下,可以持續不斷地將多個數據包發往服務器,但是如果發送的網絡數據包太小,那么他本身會啟用Nagle算法(可配置是否啟用)對較小的數據包進行合并(基于此,TCP的網絡延遲要UDP的高些)然后再發送(超時或者包大小足夠)。那么這樣的話,服務器在接收到消息(數據流)的時候就無法區分哪些數據包是客戶端自己分開發送的,這樣產生了粘包;服務器在接收到數據庫后,放到緩沖區中,如果消息沒有被及時從緩存區取走,下次在取數據的時候可能就會出現一次取出多個數據包的情況,造成粘包現象
UDP:本身作為無連接的不可靠的傳輸協議(適合頻繁發送較小的數據包),他不會對數據包進行合并發送(也就沒有Nagle算法之說了),他直接是一端發送什么數據,直接就發出去了,既然他不會對數據合并,每一個數據包都是完整的(數據+UDP頭+IP頭等等發一次數據封裝一次)也就沒有粘包一說了。
分包產生的原因就簡單的多:可能是IP分片傳輸導致的,也可能是傳輸過程中丟失部分包導致出現的半包,還有可能就是一個包可能被分成了兩次傳輸,在取數據的時候,先取到了一部分(還可能與接收的緩沖區大小有關系),總之就是一個數據包被分成了多次接收。
更具體的原因有三個,分別如下。
1. 應用程序寫入數據的字節大小大于套接字發送緩沖區的大小
2. 進行MSS大小的TCP分段。MSS是最大報文段長度的縮寫。MSS是TCP報文段中的數據字段的最大長度。數據字段加上TCP首部才等于整個的TCP報文段。所以MSS并不是TCP報文段的最大長度,而是:MSS=TCP報文段長度-TCP首部長度
3. 以太網的payload大于MTU進行IP分片。MTU指:一種通信協議的某一層上面所能通過的最大數據包大小。如果IP層有一個數據包要傳,而且數據的長度比鏈路層的MTU大,那么IP層就會進行分片,把數據包分成托干片,讓每一片都不超過MTU。注意,IP分片可以發生在原始發送端主機上,也可以發生在中間路由器上。
解決粘包半包問題
由于底層的TCP無法理解上層的業務數據,所以在底層是無法保證數據包不被拆分和重組的,這個問題只能通過上層的應用協議棧設計來解決,根據業界的主流協議的解決方案,可以歸納如下。
(1)在包尾增加分割符,比如回車換行符進行分割,例如FTP協議;linebase包和delimiter包下,分別使用LineBasedFrameDecoder和DelimiterBasedFrameDecoder
(2)消息定長,例如每個報文的大小為固定長度200字節,如果不夠,空位補空格;fixed包下,使用FixedLengthFrameDecoder
(3)將消息分為消息頭和消息體,消息頭中包含表示消息總長度(或者消息體長度)的字段,通常設計思路為消息頭的第一個字段使用int32來表示消息的總長度,LengthFieldBasedFrameDecoder;。



)


)












