grep + awk
- 1.grep命令
- 1.1 基本格式
- 1.2 常用選項
- 2.awk命令
- 2.1 awk工作原理
- 2.2 awk命令格式
- 2.3 awk常用內置變量
1.grep命令
1.1 基本格式
grep [選項]… 查找條件 目標文件
1.2 常用選項
| 選項 | 功能 |
|---|---|
| -m [ x ] | 匹配x次 后停止,x為具體數字 |
| -v | 取反 |
| -i | 忽略字符大小寫 |
| -n | 顯示匹配的 行號 |
| -c | 統計匹配的行數 |
| -o | 僅顯示匹配到的字符串 |
| -q | 靜默模式,不輸出任何信息 |
| -A x after | 匹配內容的后x行 |
| -B x before | 前x行 |
| -C x context | 前后各x行 |
| -e | 實現多個選項間的邏輯or關系 |
| -w | 匹配 整個單詞 |
| -E | 使用擴展正則表達式,相當于egrep |
| -F | 不支持正則表達式,相當于fgrep |
| -r | 遞歸目錄,但不處理軟鏈接 |
| -R | 遞歸目錄,但處理軟鏈接 |
| -f file | file 根據模式文件,處理兩個文件相同內容 把第一個文件作為匹配條件 |
| -color=auto | 對匹配到的文本著色顯示 |
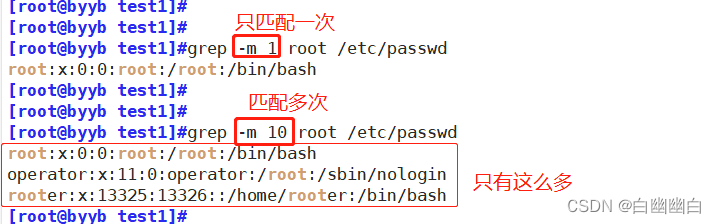
-m 匹配#次后停止grep -m 1 root /etc/passwd #多個匹配只取第一個
-v 取反grep -Ev '^[[:space:]]*#|^$' /etc/fstab#非空行

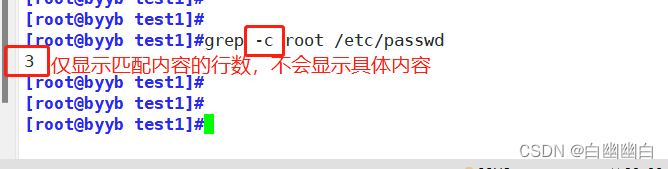
-c 統計匹配的行數grep -c root /etc/passwd #統計匹配到的行數
-A x after 匹配內容的后x行 grep -A3 root /etc/passwd #匹配到的行后3行業顯示出來

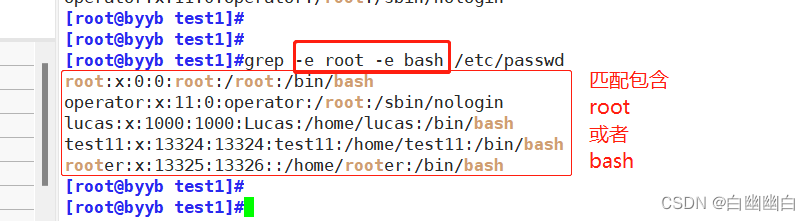
-e 實現多個選項間的邏輯or關系grep -e root -e bash /etc/passwd #包含root或者包含bash 的行grep -E root|bash /etc/passwd #使用擴展正則表達式的寫法
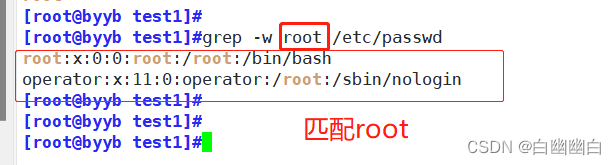
-w 匹配整個單詞grep -w root /etc/passwd
2.awk命令
2.1 awk工作原理
+-----------------+
| 輸入文件 |
| 或標準輸入 |
+-----------------+|v
+-----------------+
| 分割輸入行 |
+-----------------+|v
+-----------------+
| 匹配模式 |
+-----------------+|v
+-----------------+
| 執行動作 |
+-----------------+|v
+-----------------+
| 處理下一行 |
+-----------------+|v循環結束
-
讀取輸入:AWK首先讀取輸入文件或從標準輸入接收輸入;
-
分割輸入:AWK默認將輸入行分割成字段,并使用空格或制表符作為字段分隔符;
-
匹配模式:AWK使用模式匹配來確定需要處理的行,可以使用正則表達式或其他條件來指定匹配的行。如果沒有指定模式,AWK將默認匹配所有行;
-
執行動作:當輸入行與模式匹配時,AWK執行相應的動作;
-
處理下一行:一旦完成當前行的處理,AWK繼續處理下一行,重復上述步驟。
2.2 awk命令格式
awk默認使用正則表達式 所以不需要\
#命令格式#
awk [選項] '[模式匹配條件]{操作 }' 文件1 文件2..
#選項##一般只有-F常用
-F 指定分隔符,默認的分隔符是若干個連續空白符,默認的時候可不寫
-v 自定義變量
-f 腳本awk '/匹配條件/{ print $x }'#匹配條件可以不寫 x為任意數字
#模式匹配條件格式#/ 匹配條件 /
# 起始 結束
#/ / 一定要加
#操作#
#常用的 只有 print awk '{ print $1 }'awk '{ print $1 $2 $3 .... }'#awk會自動壓縮空格,不需要再寫tr -s ' '
2.3 awk常用內置變量
| 內置變量 | 功能 |
|---|---|
| FS | 指定每行文本的字段分隔符,缺省為空格或制表符(tab)。與 “-F”作用相同 -v “FS=:” |
| OFS | 輸出時的分隔符 |
| NF | 當前處理的行的字段個數 |
| NR | 當前處理的行的行號(序數) |
| $0 | 當前處理的行的整行內容 |
| $n | 當前處理行的第n個字段(第n列) |
| FILENAME | 被處理的文件名 |
| RS | 行分隔符。awk從文件上讀取資料時,將根據RS的定義就把資料切割成許多條記錄,而awk一次僅讀入一條記錄進行處理。預設值是\n |
########### FS #################
[root@localhost ky15]#awk -v FS=':' '{print $1FS$3}' /etc/passwd
#此處FS 相當于于變量 -v 變量賦值 相當于 指定: 為分隔符
[root@localhost ky15]#awk -F: '{print $1":"$3}' /etc/passwdshell中的變量
[root@localhost ky15]#fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd
#定義變量傳給FS######### 支持變量 ##################
[root@localhost ky15]#fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd
#輸出分隔符-F -FS一起使用 -F 的優先級高############ OFS ##########
[root@localhost ~]#awk -v FS=':' -v OFS='==' '{print $1,$3}' /etc/passwd
root==0
bin==1
daemon==2
adm==3
lp==4
sync==5######## RS #######
默認是已 /n (換行符)為一條記錄的分隔符
不動他
[root@localhost ~]#echo $PATH | awk -v RS=':' '{print $0}'
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin################## NF ###################
代表字段的個數
[root@localhost ky15]#awk -F: '{print NF}' /etc/passwd[root@localhost ky15]#awk -F: '{print $NF}' /etc/passwd
#$NF最后一個字段[root@localhost ky15]#df|awk -F: '{print $(NF-1)}'
#倒數第二行
[root@localhost ky15]#df|awk -F "[ %]+" '{print $(NF-1)}'################ NR ######################
行號
[root@localhost ky15]#awk '{print $1,NR}' /etc/passwd
##行號
[root@localhost ky15]#awk 'NR==2{print $1}' /etc/passwd
#只取第二行的第一個字段
[root@localhost ky15]#awk 'NR==1,NR==3{print}' passwd
#打印出1到3 行
[root@localhost ky15]#awk 'NR==1||NR==3{print}' passwd
#打印出1和3行
[root@localhost ky15]#awk '(NR%2)==0{print NR}' passwd
#打印出函數取余數為0行
[root@localhost ky15]#awk '(NR%2)==1{print NR}' passwd
#打印出函數取余數為1的行
[root@localhost ky15]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd[root@localhost ky15]#seq 10|awk 'NR>5 && NR<10'
#取 行間
6
7
8
9
[root@localhost ky15]#awk '$3>1000{print}' /etc/passwd
#注意分隔符
#打印出普通用戶 第三列 大于1000 的行################ FNR ############
[root@localhost data]#cat /etc/issue |wc -l
3
[root@localhost data]#cat /etc/os-release |wc -l
16
[root@localhost data]#awk '{print FNR}' /etc/issue /etc/os-release
1
2
3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16################ FILENAME ############
[root@localhost ~]#awk -F: 'NR==2{print FILENAME}' /etc/passwd
/etc/passwd


















