作為在后端開發,是不是經常聽到過,mysql 單表最好不要超過 2000w,單表超過 2000w 就要考慮數據遷移了,表數據都要到 2000w ,查詢速度變得賊慢。
1、建表操作
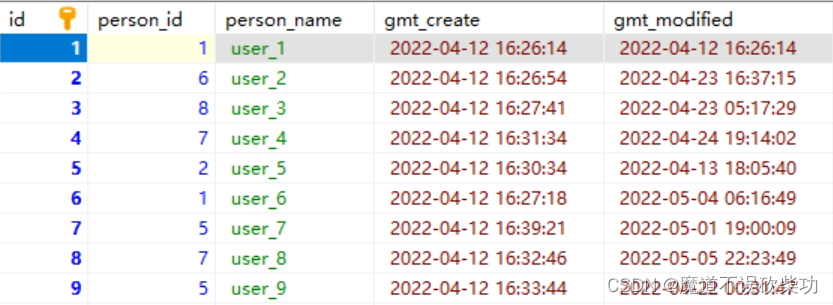
建一張表
CREATE TABLE person(
id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '主鍵',
person_id tinyint not null comment '用戶id',
person_name VARCHAR(200) comment '用戶名稱',
gmt_create datetime comment '創建時間',
gmt_modified datetime comment '修改時間'
) comment '人員信息表';
插入一條數據
insert into person values(1,1,'user_1', NOW(), now());
利用 mysql 偽列 rownum 設置偽列起始點為 1
select (@i:=@i+1) as rownum, person_name from person, (select @i:=100) as init;
set @i=1;
運行下面的 sql,連續執行 20 次,就是 2 的 20 次方約等于 100w 的數據;執行 23 次就是 2 的 23 次方約等于 800w , 如此下去即可實現千萬測試數據的插入,如果不想翻倍翻倍的增加數據,而是想少量,少量的增加,有個技巧,就是在 SQL 的后面增加 where 條件,如 id > 某一個值去控制增加的數據量即可。
insert into person(id, person_id, person_name, gmt_create, gmt_modified)
select @i:=@i+1,
left(rand()*10,10) as person_id,
concat('user_',@i%2048),
date_add(gmt_create,interval + @i*cast(rand()*100 as signed) SECOND),
date_add(date_add(gmt_modified,interval +@i*cast(rand()*100 as signed) SECOND), interval + cast(rand()*1000000 as signed) SECOND)
from person;
此處需要注意的是,也許你在執行到近 800w 或者 1000w 數據的時候,會報錯:The total number of locks exceeds the lock table size,這是由于你的臨時表內存設置的不夠大,只需要擴大一下設置參數即可。
SET GLOBAL tmp_table_size =512*1024*1024; (512M)
SET global innodb_buffer_pool_size= 1*1024*1024*1024 (1G);
先來看一組測試數據,這組數據是在 mysql8.0 的版本,并且是在我本機上,由于本機還跑著 idea , 瀏覽器等各種工具,所以并不是機器配置就是用于數據庫配置,所以測試數據只限于參考。

看到這組數據似乎好像真的和標題對應,當數據達到 2000w 以后,查詢時長急劇上升。
2、單表數量限是多少呢?
首先我們先想想數據庫單表行數最大多大?
CREATE TABLE person(
id int(10) NOT NULL AUTO_INCREMENT PRIMARY KEY comment '主鍵',
person_id tinyint not null comment '用戶id',
person_name VARCHAR(200) comment '用戶名稱',
gmt_create datetime comment '創建時間',
gmt_modified datetime comment '修改時間'
) comment '人員信息表';
看看上面的建表 sql,id 是主鍵,本身就是唯一的,也就是說主鍵的大小可以限制表的上限,如果主鍵聲明 int 大小,也就是 32 位,那么支持 2^32-1 ~~21 億;如果是 bigint,那就是 2^62-1 ?(36893488147419103232),難以想象這個的多大了,一般還沒有到這個限制之前,可能數據庫已經爆滿了!!
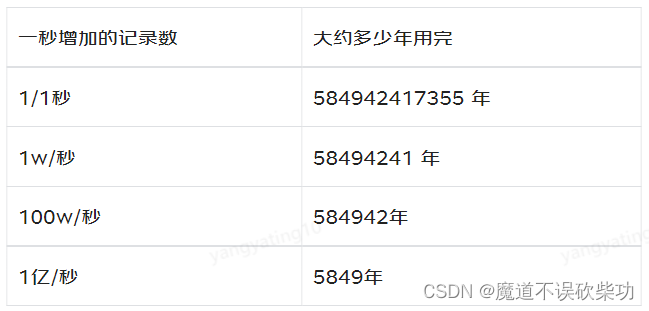
有人統計過,如果建表的時候,自增字段選擇無符號的 bigint , 那么自增長最大值是 18446744073709551615,按照一秒新增一條記錄的速度,大約什么時候能用完?
3、表空間
下面我們再來看看索引的結構,對了,我們下面講內容都是基于 Innodb 引擎的,大家都知道 Innodb 的索引內部用的是 B+ 樹
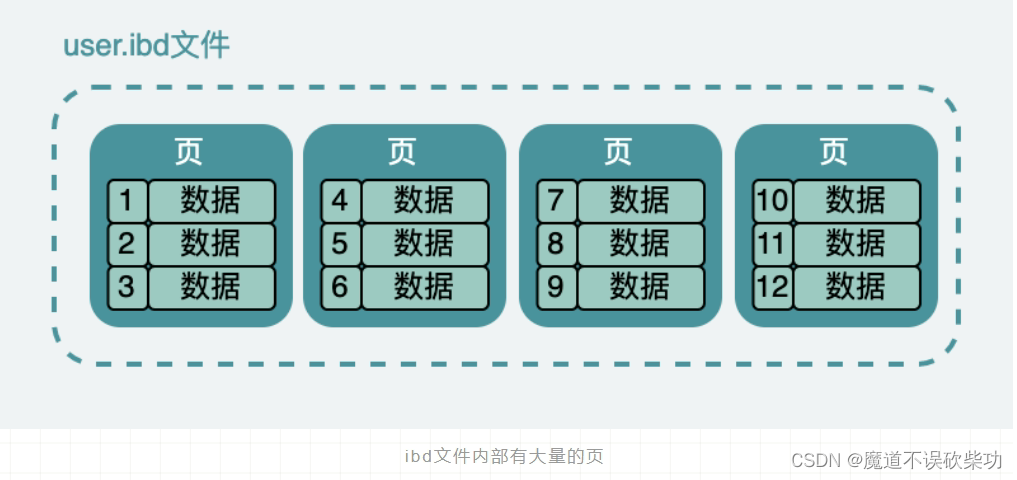
這張表數據,在硬盤上存儲也是類似如此的,它實際是放在一個叫 person.ibd (innodb data)的文件中,也叫做表空間;雖然數據表中,他們看起來是一條連著一條,但是實際上在文件中它被分成很多小份的數據頁,而且每一份都是 16K。
大概就像下面這樣,當然這只是我們抽象出來的,在表空間中還有段、區、組等很多概念,但是我們需要跳出來看。對于什么事 B+樹,可以參考另一篇文章即可。
4、總結
- MySQL 的表數據是以頁的形式存放的,頁在磁盤中不一定是連續的。
- 頁的空間是 16K, 并不是所有的空間都是用來存放數據的,會有一些固定的信息,如,頁頭,頁尾,頁碼,校驗碼等等。
- 在 B+ 樹中,葉子節點和非葉子節點的數據結構是一樣的,區別在于,葉子節點存放的是實際的行數據,而非葉子節點存放的是主鍵和頁號。
- 索引結構不會影響單表最大行數,2kw 也只是推薦值,超過了這個值可能會導致 B + 樹層級更高,影響查詢性能。


![[excel]vlookup函數對相同的ip進行關聯](http://pic.xiahunao.cn/[excel]vlookup函數對相同的ip進行關聯)


)
)




![用友-NC-Cloud遠程代碼執行漏洞[2023-HW]](http://pic.xiahunao.cn/用友-NC-Cloud遠程代碼執行漏洞[2023-HW])






:張量并行版Embedding層及交叉熵的實現及測試)
