前文分別介紹了滴滴自研的ES強一致性多活是如何實現的、以及如何提升ES的性能潛力。由于滴滴ES日志場景每天寫入量在5PB-10PB量級,寫入壓力和業務成本壓力大,為了提升ES的寫入性能,我們讓ES支持ZSTD壓縮算法,本篇文章詳細展開滴滴在落地ZSTD壓縮算法上的思考和實踐。
//?背 景?//
ES通過索引(Index)對外提供數據檢索能力,索引是用于組織和存儲數據的邏輯單元。每個索引由若干個分片(shard)組成,每個分片就是一個Lucene索引,可以在不同的節點上進行分布式存儲和并行處理,提高性能和可伸縮性。每個分片由一組段文件(segment)組成,段是分片中更小的存儲和搜索單元,是一組物理文件,包含了檢索需要的倒排索引(詞項和文檔ID的映射關系)和文檔存儲(字段值和其他元數據),如下圖:
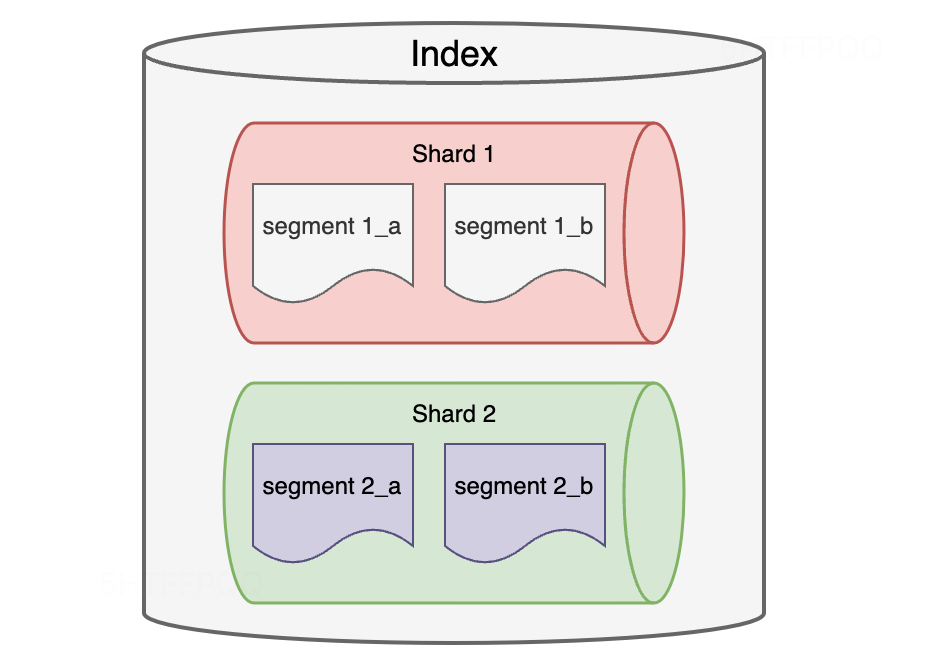
ES數據模型
Lucene作為ES的底層索引引擎,提供了靈活的數據檢索能力,同時也導致CPU、存儲占用較為嚴重。為實現降本增效,23年上半年,ES團隊開啟了Lucene壓縮編碼優化專項,通過改進存儲層壓縮算法,從而降低單位Document所占用的資源。本文概述了ES的底層索引文件,并介紹了Lucene存儲壓縮編碼的優化。
//?Lucene索引文件介紹?//
ES的壓縮編碼優化專項涉及到Lucene底層的文件存儲,Lucene索引由一組Segment構成,每個Segment包含了一系列文件,重點文件類型如下圖:
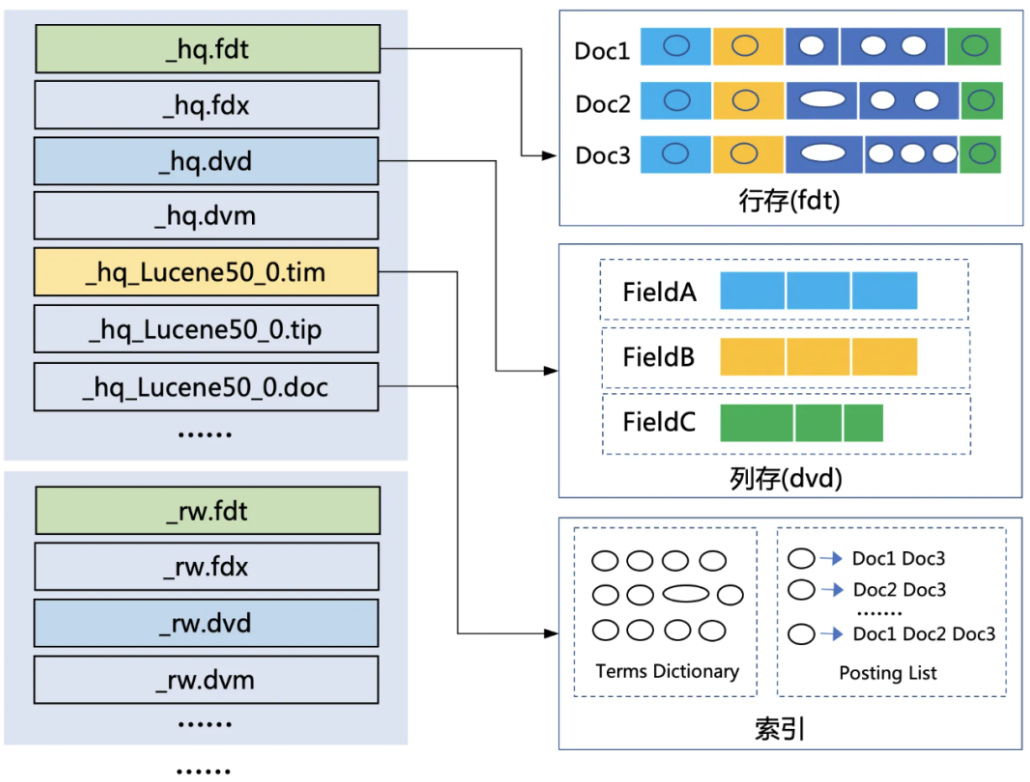
行存文件:包括原文存儲文件和原文索引文件。原文存儲文件,即.fdt文件。用戶寫入的原始數據都被存儲于該文件中,因其占比大,為節約存儲,Lucene在原文存儲上支持LZ4壓縮和ZIP壓縮;原文索引文件,即.fdx文件,它存儲了原文數據在原文存儲文件中的位置信息,建立起了doc id和原文之間的聯系,以支持快速訪問和定位。
列存文件:即.dvd文件,常被應用于一些OLAP分析引擎中。列存文件按列組織數據,不同Document中的同一列數據(Field),相鄰存放在一起,這樣可以加速該列聚合分析性查詢。同時,相鄰每列類型相同,在存儲的時候可以進行統一性的編碼優化,提高壓縮率,減少存儲磁盤空間的占用。
索引相關文件:ES依靠分詞產生倒排索引,使其具備強大的全文檢索能力。索引相關文件中,重點文件包含:字典數據文件&倒排索引文件。字典數據文件,即.tim文件,通過用戶配置的索引分詞器,能夠從用戶數據中提取分詞信息并存儲在.tim文件中。同一列的分詞信息,相鄰存放,按塊組織;倒排索引文件,即.doc文件,也被稱為"倒排拉鏈表",它記錄了每一個分詞所關聯的文檔列表,能夠實現快速的單詞到文檔的倒排查找。
//?ZSTD壓縮算法調研與分析?//
ES線上集群中資源比較緊張的主要是日志集群,集群寫多讀少,高峰期CPU使用率在85%左右,寫入性能是它的主要瓶頸。通過調研可以發現原文存儲文件的占比最大,基本都超過了30%,有些索引甚至超過了70%。由此,我們明確了索引文件壓縮編碼優化的重心。
目前滴滴ES線上采用的是7.6.0版本,對應的Lucene版本是8.4.0,該版本支持兩種壓縮策略:
BEST_SPEED,是ES索引默認的壓縮算法,使用了LZ4壓縮。壓縮與解壓速度快,CPU占用低,但壓縮效果弱。? ??
BEST_COMPRESSION,使用了ZIP壓縮。壓縮與解壓速度慢,CPU占用高,但壓縮效果好。
Lucene的壓縮算法僅針對占比最大的行存文件生效,其他文件通過自定義編碼優化來降低存儲。目前滴滴ES日志集群采用BEST_COMPRESSION壓縮算法,通過ES壓縮比測試發現,日志場景下,同一個索引采用ZIP比LZ4低20% ~ 40%的磁盤存儲占用空間。但通過分析日志集群的CPU使用情況可以發現,ES壓縮模塊的CPU占比較高,一些日志集群甚至超過30%,如下圖:
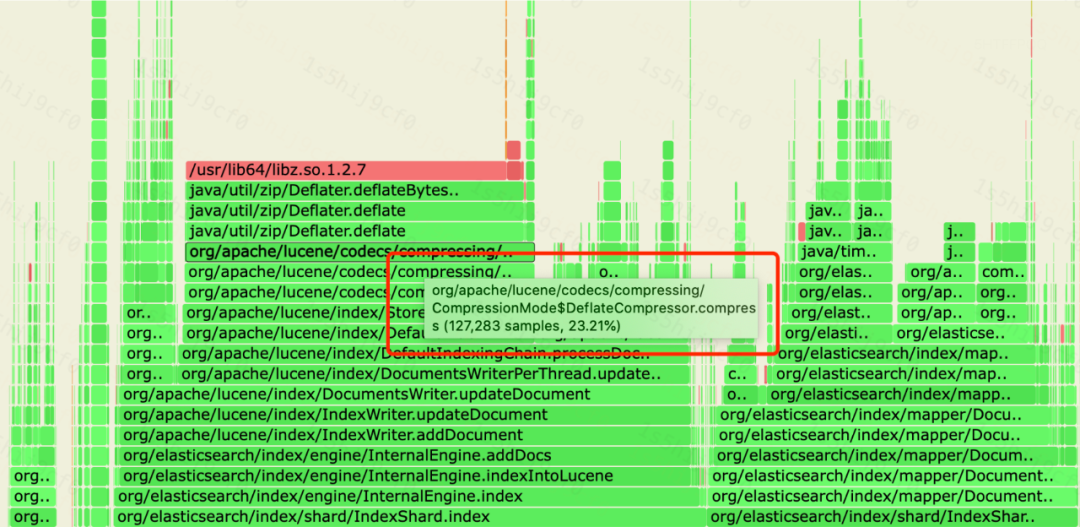
CPU損耗占比
在上述背景下,我們調研了ZSTD壓縮算法,ZSTD(Zstandard)底層基于FSE編碼實現,具有出色的壓縮和解壓速度。ZSTD算法的實現經過了高度優化,通過SIMD等指令集能夠充分利用硬件并行性,同時編碼過程大量依賴位移運算來完成狀態的切換,以此提高處理速度。ZSTD采用字典壓縮算法,通過引用字典中的匹配項,能夠大大減少重復數據的存儲空間,提高壓縮比。與此同時,ZSTD采用多級壓縮策略,在不同的壓縮級別中應用不同的壓縮算法,能夠在不同的應用場景中靈活地平衡速度和壓縮比。
為了驗證它的性能,采用bamai線上1GB的日志文件做壓縮性能測試,測試發現,ZSTD的壓縮速度是ZIP的4.5倍,解壓縮速度是ZIP的1.5倍,壓縮比幾乎持平,如下圖所示,ZSTD壓縮算法兼顧了LZ4壓縮的"快"及ZIP壓縮的"效果好"。
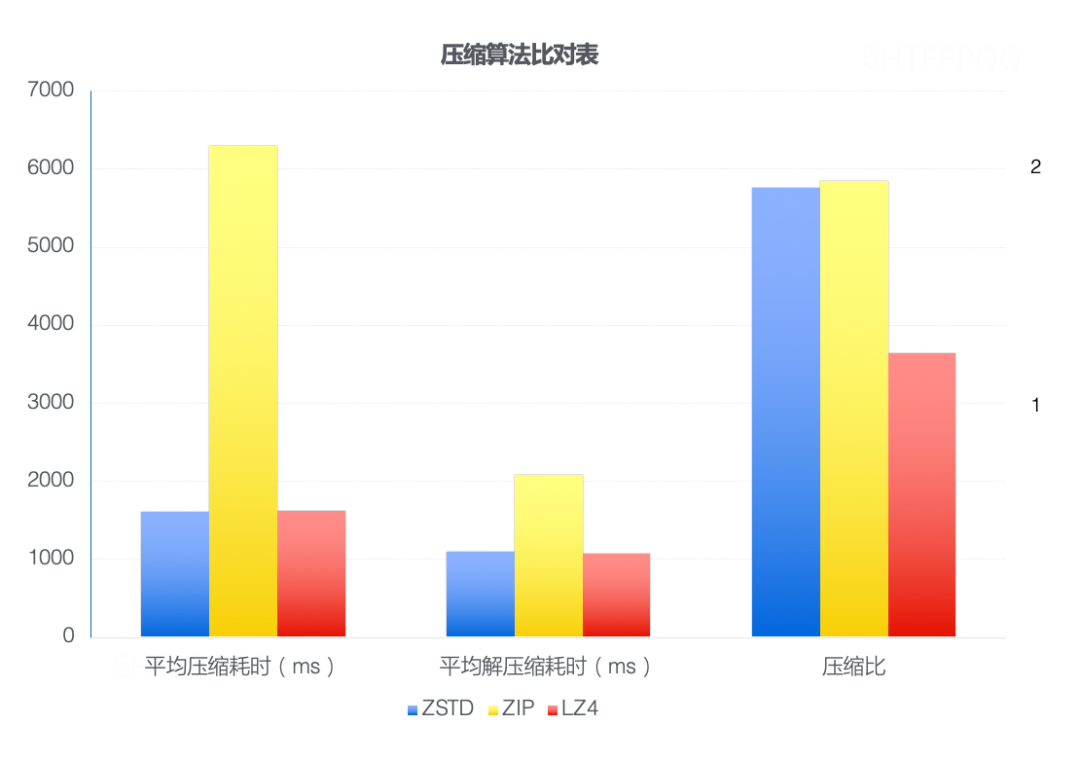
壓縮算法對比
//?ZSTD壓縮算法落地?//
為了實現ZSTD在滴滴ES的落地,我們從以下方面著手:
源碼開發
1、ES?setting和engine擴展
ES通過setting給每個索引配置壓縮格式,需要在ES setting中支持ZSTD壓縮格式。ES會為每個shard初始化一個engine,不同的分片類型或狀態對應不同的engine,例如索引close對應的是noop engine,DCDR從索引對應的following engine,需要在不同類型的engine上抽象并擴展它的ZSTD壓縮能力。
2、Lucene CompressionMode 擴展
Lucene是一個由Java編寫的全文搜索引擎庫,而ZSTD算法是基于C++實現的,因此在Lucene端引入了zstd-jni來擴展ZSTD壓縮能力。通過擴展CompressionMode,自定義ZStandardDecompressor和ZStandardCompressor來實現數據的按塊壓縮、解壓縮。
參數調優
1、Chunk Size調優
行存文件內部是以Chunk形式組織的,Chunk Size通常為數十KB級別。滴滴ES7.6.0版本采用的是Lucene 8.4版本, LZ4壓縮算法設置的Chunk Size為16kb,而ZIP壓縮算法設置的是60kb。將索引設置為ZSTD壓縮格式并導入一批線上數據后,壓縮結果如表所示。
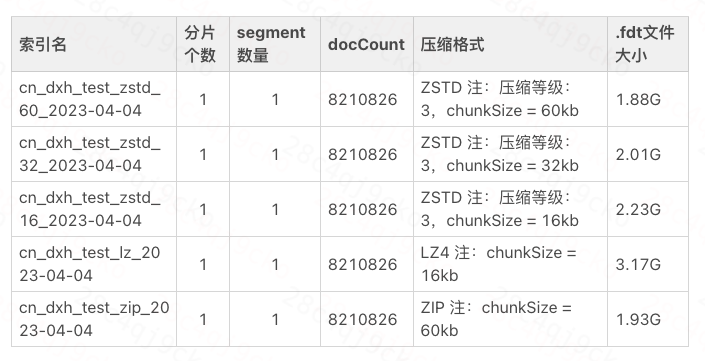
Chunk Size壓縮比對表
增大ChunkSize可以獲得一個更大的數據區間內的共享字典數據,從而獲得更好的壓縮效果。但這也會導致隨機訪問時延變大、CPU消耗進一步增大。為保證后期索引壓縮格式切換為ZSTD時不會出現數據膨脹問題,ChunkSize采用的是60kb。
2、ZSTD壓縮等級調優
ZSTD采用多級壓縮策略,它?提供了從 1 到 22 的壓縮等級,數值越大表示壓縮比越高,但壓縮和解壓縮速度越慢、CPU損耗越高。設置不同的壓縮等級,導入測試數據,壓縮結果如下表所示:
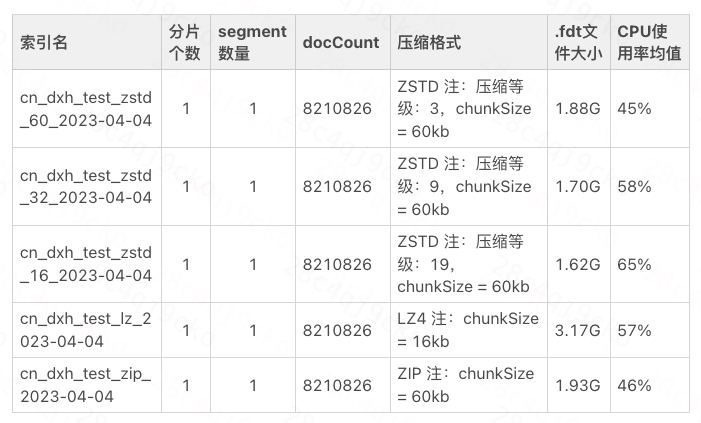
壓縮等級性能比對表
通過增大壓縮等級能夠降低存儲,例如將壓縮等級調整為9,.fdt文件能夠下降10%左右的存儲,索引整體存儲下降5%,此時CPU損耗和ZIP基本持平。
ES線上日志集群寫多讀少,采用的都是物理機(SSD硬盤),集群高峰期CPU使用率超過80%,集群整體磁盤水位在55%左右,CPU使用率是它的瓶頸。因此,采用的壓縮等級為3,該等級在速度和壓縮比之間取得了較好的平衡,并且能夠盡可能地降低集群CPU使用率。
其他
1、解決Lucene打包部分依賴加載失敗問題,比如:Lucene采用ivy進行依賴管理,通過引入repo解決Lucene打包過程中Maven主倉庫中找不到 org.restlet.jee jar的問題,如下圖:
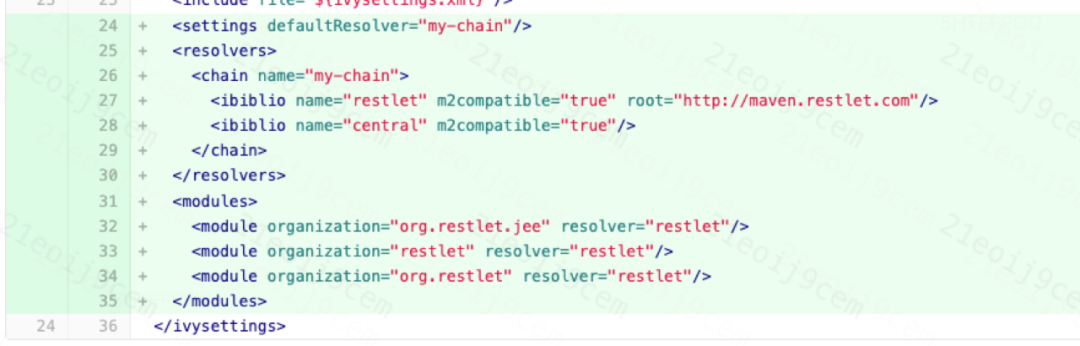
ivy依賴導入圖
2、通過前置初始化zstd模塊,解決ES運行時動態加載zstd-jni-jar失敗問題。
3、通過擴展noop engine的ZSTD壓縮能力,解決索引close場景ZSTD類型解析失敗問題。
//?上線效果?//
經過三個月的實踐與優化,目前已在16個集群上線了ES-ZSTD版本,并將日志集群全量索引(6w+)以及部分公共集群索引的壓縮格式均切換為ZSTD,上線后所有日志集群高峰期CPU使用率平均降幅達到15%,使ES可以提供更高性能、更低成本的檢索服務,主要效果如下:
更高性能
1、某日志集群A上線效果
ES某日志集群A上線ES-ZSTD版本并將全量索引切換壓縮切換為ZSTD格式后,集群高峰期CPU使用率下降18%,寫入reject同比下降50%。
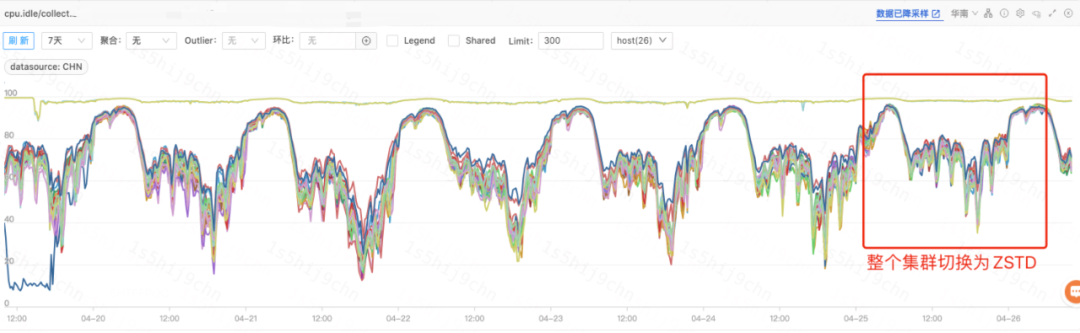
集群CPU Idle圖(集群A)
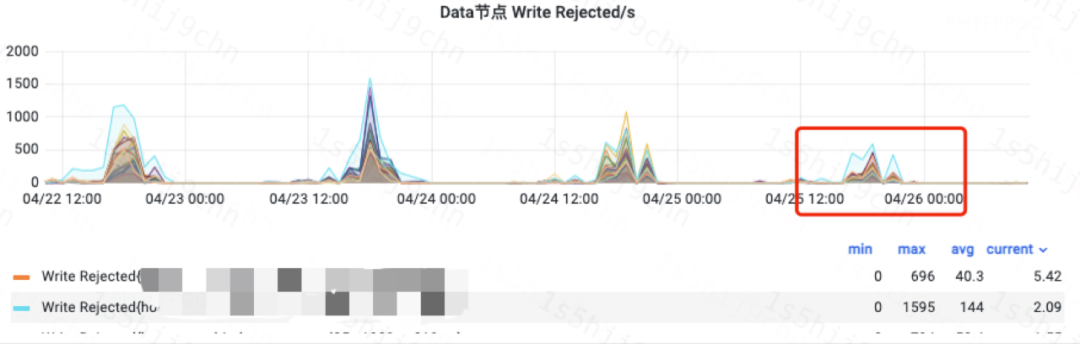
DataNode寫入reject圖(集群A)
2、某超大日志索引M切換效果
ES某超大線上日志索引M壓縮格式由ZIP切換為ZSTD后,寫入條數不變的情況下,集群CPU使用率下降15%,寫入性能提升25%。
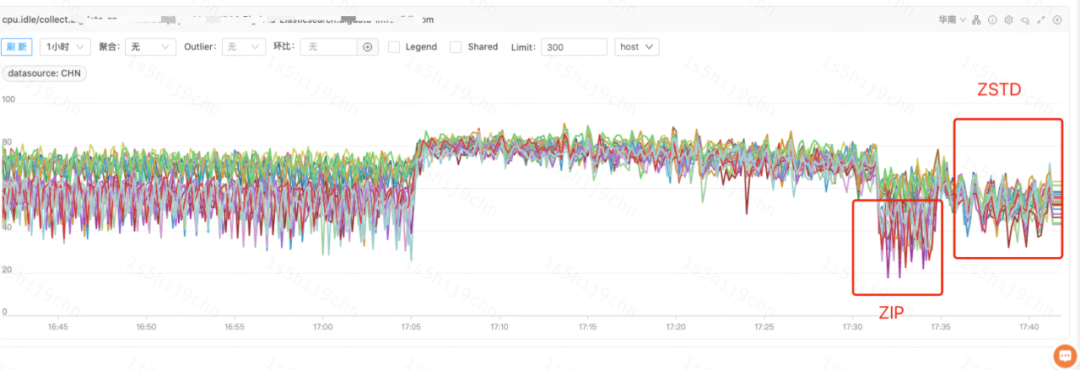
集群CPU Idle圖(集群B)
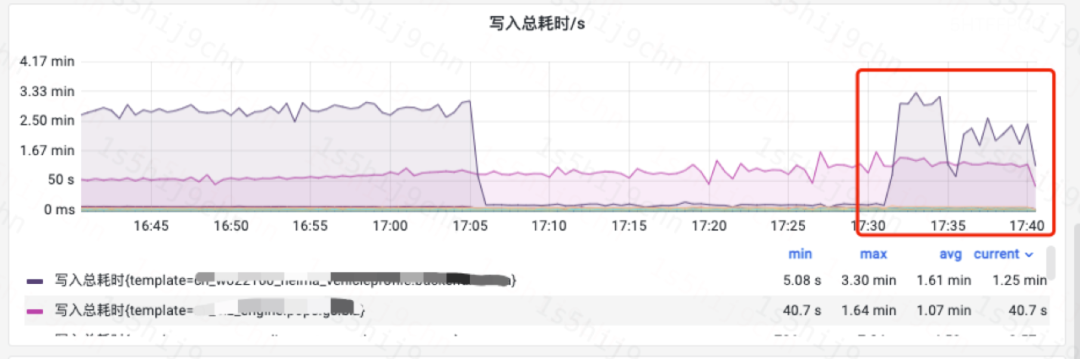
索引寫入總耗時(索引M)
更低成本
1、LZ4壓縮格式索引切換為ZSTD效果
ES日志集群還殘留著部分LZ4壓縮的日志索引,將這些日志索引切換為ZSTD壓縮格式后,平均索引存儲下降達到30%,如下圖:
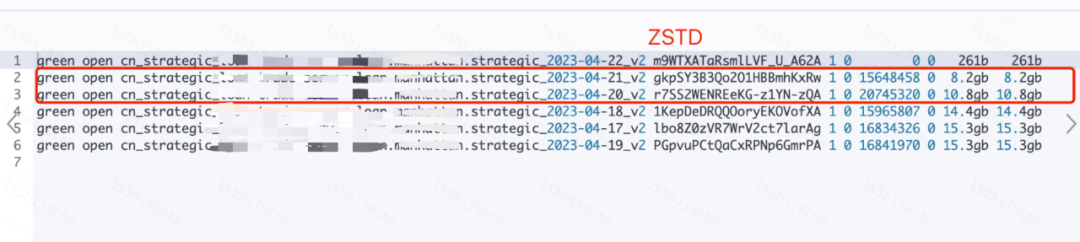
索引存儲圖
2、日志集群縮容
將索引壓縮格式切換為ZSTD后,能夠有效降低集群CPU,因此可以進行集群資源調整。目前已經縮容機器超過20臺,仍在持續下線中。
//?總 結?//
ZSTD助力ES提供更高性能、更低成本的檢索服務。之后也會陸續開啟讀寫分離、ES大版本升級等項目,進一步助力業務發展。

![[excel]vlookup函數對相同的ip進行關聯](http://pic.xiahunao.cn/[excel]vlookup函數對相同的ip進行關聯)


)
)




![用友-NC-Cloud遠程代碼執行漏洞[2023-HW]](http://pic.xiahunao.cn/用友-NC-Cloud遠程代碼執行漏洞[2023-HW])






:張量并行版Embedding層及交叉熵的實現及測試)

