譯者注
本文是一篇不可多得的好文,MemoryPack 的作者 neuecc 大佬通過本文解釋了他是如何將序列化程序性能提升到極致的;其中從很多方面(可變長度、字符串、集合等)解釋了一些性能優化的技巧,值得每一個開發人員學習,特別是框架的開發人員的學習,一定能讓大家獲益匪淺。
由于公眾號排版原因,譯者建議大家在桌面端閱讀本文,手機閱讀體驗并不是很好。
簡介
我發布了一個名為MemoryPack[1] 的新序列化程序,這是一種特定于 C# 的新序列化程序,其執行速度比其他序列化程序快得多。
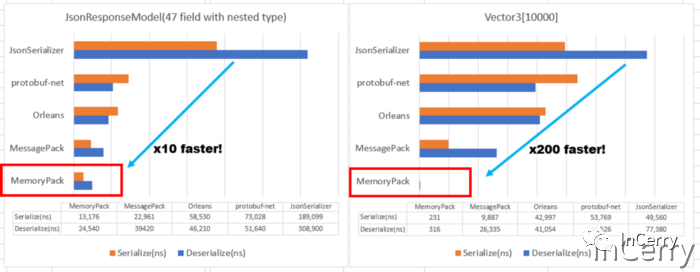
與MessagePack for C#[2] (一個快速的二進制序列化程序)相比標準對象的序列化庫性能快幾倍,當數據最優時,性能甚至快 50~100 倍。最好的支持是.NET 7,但現在支持.NET Standard 2.1(.NET 5,6),Unity 甚至 TypeScript。它還支持多態性(Union),完整版本容錯,循環引用和最新的現代 I/O API(IBufferWriter,ReadOnlySeqeunce,Pipelines)。
序列化程序的性能基于“數據格式規范”和“每種語言的實現”。例如,雖然二進制格式通常比文本格式(如 JSON)具有優勢,但 JSON 序列化程序可能比二進制序列化程序更快(如Utf8Json[3] 所示)。那么最快的序列化程序是什么?當你同時了解規范和實現時,真正最快的序列化程序就誕生了。
多年來,我一直在開發和維護 MessagePack for C#,而 MessagePack for C# 是 .NET 世界中非常成功的序列化程序,擁有超過 4000 顆 GitHub 星。它也已被微軟標準產品采用,如 Visual Studio 2022,SignalR MessagePack Hub[4]協議和 Blazor Server 協議(blazorpack)。
在過去的 5 年里,我還處理了近 1000 個問題。自 5 年前以來,我一直在使用 Roslyn 的代碼生成器進行 AOT 支持,并對其進行了演示,尤其是在 Unity、AOT 環境 (IL2CPP) 以及許多使用它的 Unity 手機游戲中。
除了 MessagePack for C# 之外,我還創建了ZeroFormatter[5](自己的格式)和Utf8Json[6](JSON)等序列化程序,它們獲得了許多 GitHub Star,所以我對不同格式的性能特征有深刻的理解。此外,我還參與了 RPC 框架MagicOnion[7],內存數據庫MasterMemory[8],PubSub 客戶端AlterNats[9]以及幾個游戲的客戶端(Unity)/服務器實現的創建。
MemoryPack 的目標是成為終極的快速,實用和多功能的序列化程序。我想我做到了。
增量源生成器
MemoryPack 完全采用 .NET 6 中增強的增量源生成器[10]。在用法方面,它與 C# 版 MessagePack 沒有太大區別,只是將目標類型更改為部分類型。
using?MemoryPack;//?Source?Generator?makes?serialize/deserialize?code
[MemoryPackable]
public?partial?class?Person
{public?int?Age?{?get;?set;?}public?string?Name?{?get;?set;?}
}//?usage
var?v?=?new?Person?{?Age?=?40,?Name?=?"John"?};var?bin?=?MemoryPackSerializer.Serialize(v);
var?val?=?MemoryPackSerializer.Deserialize<Person>(bin);源生成器的最大優點是它對 AOT 友好,無需反射即可為每種類型自動生成優化的序列化程序代碼,而無需由 IL.Emit 動態生成代碼,這是常規做法。這使得使用 Unity 的 IL2CPP 等可以安全地工作。初始啟動速度也很快。
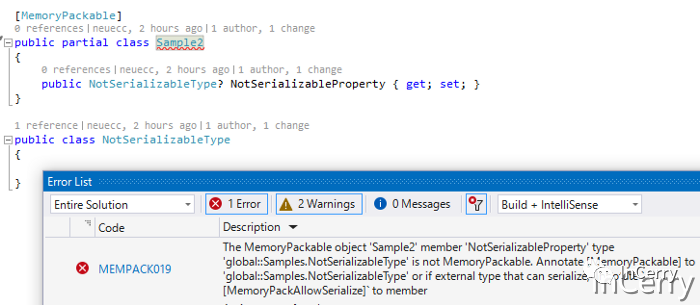
源生成器還用作分析器,因此它可以通過在編輯時發出編譯錯誤來檢測它是否可安全序列化。
請注意,由于語言/編譯器版本原因,Unity 版本使用舊的源生成器[11]而不是增量源生成器。
C# 的二進制規范
MemoryPack 的標語是“零編碼”。這不是一個特例,例如,Rust 的主要二進制序列化器bincode[12] 也有類似的規范。FlatBuffers[13]還可以讀取和寫入類似于內存數據的內容,而無需解析實現。
但是,與 FlatBuffers 和其他產品不同,MemoryPack 是一種通用的序列化程序,不需要特殊類型,并且可以針對 POCO 進行序列化/反序列化。它還具有對架構成員添加和多態性支持 (Union) 的高容忍度的版本控制。
可變編碼與固定編碼
Int32 是 4 個字節,但在 JSON 中,例如,數字被編碼為字符串,可變長度編碼為 1~11 個字節(例如,1 或 -2147483648)。許多二進制格式還具有 1 到 5 字節的可變長度編碼規范以節省大小。例如,Protocol-buffers 數字類型[14]具有可變長度整數編碼,該編碼以 7 位存儲值,并以 1 位 (varint) 存儲是否存在以下的標志。這意味著數字越小,所需的字節就越少。相反,在最壞的情況下,該數字將增長到 5 個字節,大于原來的 4 個字節。MessagePack[15]和CBOR[16]類似地使用可變長度編碼進行處理,小數字最小為 1 字節,大數字最大為 5 字節。
這意味著 varint 運行比固定長度情況額外的處理。讓我們在具體代碼中比較兩者。可變長度是 protobuf 中使用的可變 + 之字折線編碼(負數和正數組合)。
//?Fixed?encoding
static?void?WriteFixedInt32(Span<byte>?buffer,?int?value)
{ref?byte?p?=?ref?MemoryMarshal.GetReference(buffer);Unsafe.WriteUnaligned(ref?p,?value);
}//?Varint?encoding
static?void?WriteVarInt32(Span<byte>?buffer,?int?value)?=>?WriteVarInt64(buffer,?(long)value);static?void?WriteVarInt64(Span<byte>?buffer,?long?value)
{ref?byte?p?=?ref?MemoryMarshal.GetReference(buffer);ulong?n?=?(ulong)((value?<<?1)?^?(value?>>?63));while?((n?&?~0x7FUL)?!=?0){Unsafe.WriteUnaligned(ref?p,?(byte)((n?&?0x7f)?|?0x80));p?=?ref?Unsafe.Add(ref?p,?1);n?>>=?7;}Unsafe.WriteUnaligned(ref?p,?(byte)n);
}換句話說,固定長度是按原樣寫出 C# 內存(零編碼),很明顯,固定長度更快。
當應用于數組時,這一點更加明顯。
//?https://sharplab.io/
Inspect.Heap(new?int[]{?1,?2,?3,?4,?5?});
在 C# 中的結構數組中,數據按順序排列。如果結構沒有引用類型(非托管類型)[17]則數據在內存中完全對齊;讓我們將代碼中的序列化過程與 MessagePack 和 MemoryPack 進行比較。
//?Fixed-length(MemoryPack)
void?Serialize(int[]?value)
{//?Size?can?be?calculated?and?allocate?in?advancevar?size?=?(sizeof(int)?*?value.Length)?+?4;EnsureCapacity(size);//?MemoryCopy?onceMemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);
}// Variable-length(MessagePack)
void?Serialize(int[]?value)
{foreach?(var?item?in?value){//?Unknown?size,?so?check?size?each?timesEnsureCapacity();?//?if?(buffer.Length?<?writeLength)?Resize();//?Variable?length?encoding?per?elementWriteVarInt32(item);}
}在固定長度的情況下,可以消除許多方法調用并且只有一個內存副本。
C# 中的數組不僅是像 int 這樣的基元類型,對于具有多個基元的結構也是如此,例如,具有 (float x, float y, float z) 的 Vector3 數組將具有以下內存布局。

浮點數(4 字節)是 MessagePack 中 5 個字節的固定長度。額外的 1 個字節以標識符為前綴,指示值的類型(整數、浮點數、字符串...)。具體來說,[0xca, x, x, x, x, x, x].MemoryPack 格式沒有標識符,因此 4 個字節按原樣寫入。
以 Vector3[10000] 為例,它比基準測試好 50 倍。
//?these?fields?exists?in?type
//?byte[]?buffer
//?int?offsetvoid?SerializeMemoryPack(Vector3[]?value)
{//?only?do?copy?oncevar?size?=?Unsafe.SizeOf<Vector3>()?*?value.Length;if?((buffer.Length?-?offset)?<?size){Array.Resize(ref?buffer,?buffer.Length?*?2);}MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer.AsSpan(0,?offset))
}void?SerializeMessagePack(Vector3[]?value)
{//?Repeat?for?array?length?x?number?of?fieldsforeach?(var?item?in?value){//?X{//?EnsureCapacity//?(Actually,?create?buffer-linked-list?with?bufferWriter.Advance,?not?Resize)if?((buffer.Length?-?offset)?<?5){Array.Resize(ref?buffer,?buffer.Length?*?2);}var?p?=?MemoryMarshal.GetArrayDataReference(buffer);Unsafe.WriteUnaligned(ref?Unsafe.Add(ref?p,?offset),?(byte)0xca);Unsafe.WriteUnaligned(ref?Unsafe.Add(ref?p,?offset?+?1),?item.X);offset?+=?5;}//?Y{if?((buffer.Length?-?offset)?<?5){Array.Resize(ref?buffer,?buffer.Length?*?2);}var?p?=?MemoryMarshal.GetArrayDataReference(buffer);Unsafe.WriteUnaligned(ref?Unsafe.Add(ref?p,?offset),?(byte)0xca);Unsafe.WriteUnaligned(ref?Unsafe.Add(ref?p,?offset?+?1),?item.Y);offset?+=?5;}//?Z{if?((buffer.Length?-?offset)?<?5){Array.Resize(ref?buffer,?buffer.Length?*?2);}var?p?=?MemoryMarshal.GetArrayDataReference(buffer);Unsafe.WriteUnaligned(ref?Unsafe.Add(ref?p,?offset),?(byte)0xca);Unsafe.WriteUnaligned(ref?Unsafe.Add(ref?p,?offset?+?1),?item.Z);offset?+=?5;}}
}使用 MessagePack,它需要 30000 次方法調用。在該方法中,它會檢查是否有足夠的內存進行寫入,并在每次完成寫入時添加偏移量。
使用 MemoryPack,只有一個內存副本。這實際上會使處理時間改變一個數量級,這也是本文開頭圖中 50 倍~100 倍加速的原因。
當然,反序列化過程也是單個副本。
//?Deserialize?of?MemoryPack,?only?copy
Vector3[]?DeserializeMemoryPack(ReadOnlySpan<byte>?buffer,?int?size)
{var?dest?=?new?Vector3[size];MemoryMarshal.Cast<byte,?Vector3>(buffer).CopyTo(dest);return?dest;
}//?Require?read?float?many?times?in?loop
Vector3[]?DeserializeMessagePack(ReadOnlySpan<byte>?buffer,?int?size)
{var?dest?=?new?Vector3[size];for?(int?i?=?0;?i?<?size;?i++){var?x?=?ReadSingle(buffer);buffer?=?buffer.Slice(5);var?y?=?ReadSingle(buffer);buffer?=?buffer.Slice(5);var?z?=?ReadSingle(buffer);buffer?=?buffer.Slice(5);dest[i]?=?new?Vector3(x,?y,?z);}return?dest;
}這是 MessagePack 格式本身的限制,只要遵循規范,速度的巨大差異就無法以任何方式逆轉。但是,MessagePack 有一個名為“ext 格式系列”的規范,它允許將這些數組作為其自身規范的一部分進行特殊處理。事實上,MessagePack for C# 有一個特殊的 Unity 擴展選項,稱為 UnsafeBlitResolver,它可以執行上述操作。
但是,大多數人可能不會使用它,也沒有人會使用會使 MessagePack 不兼容的專有選項。
因此,對于 MemoryPack,我想要一個默認情況下能提供最佳性能的規范 C#。
字符串優化
MemoryPack 有兩個字符串規范:UTF8 或 UTF16。由于 C# 字符串是 UTF16,因此將其序列化為 UTF16 可以節省編碼/解碼為 UTF8 的成本。
void?EncodeUtf16(string?value)
{var?size?=?value.Length?*?2;EnsureCapacity(size);//?Span<char>?->?Span<byte>?->?CopyMemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);
}string?DecodeUtf16(ReadOnlySpan<byte>?buffer,?int?length)
{ReadOnlySpan<char>?src?=?MemoryMarshal.Cast<byte,?char>(buffer).Slice(0,?length);return?new?string(src);
}但是,MemoryPack 默認為 UTF8。這是因為有效負載大小問題;對于 UTF16,ASCII 字符的大小將是原來的兩倍,因此選擇了 UTF8。
但是,即使使用 UTF8,MemoryPack 也具有其他序列化程序所沒有的一些優化。
//?fast
void?WriteUtf8MemoryPack(string?value)
{var?source?=?value.AsSpan();var?maxByteCount?=?(source.Length?+?1)?*?3;EnsureCapacity(maxByteCount);Utf8.FromUtf16(source,?dest,?out?var?_,?out?var?bytesWritten,?replaceInvalidSequences:?false);
}//?slow
void?WriteUtf8StandardSerializer(string?value)
{var?maxByteCount?=?Encoding.UTF8.GetByteCount(value);EnsureCapacity(maxByteCount);Encoding.UTF8.GetBytes(value,?dest);
}var bytes = Encoding.UTF8.GetBytes(value)是絕對的不允許的,字符串寫入中不允許 byte[] 分配。許多序列化程序使用 Encoding.UTF8.GetByteCount,但也應該避免它,因為 UTF8 是一種可變長度編碼,GetByteCount 完全遍歷字符串以計算確切的編碼后大小。也就是說,GetByteCount -> GetBytes 遍歷字符串兩次。
通常,允許序列化程序保留大量緩沖區。因此,MemoryPack 分配三倍的字符串長度,這是 UTF8 編碼的最壞情況,以避免雙重遍歷。在解碼的情況下,應用了進一步的特殊優化。
//?fast
string?ReadUtf8MemoryPack(int?utf16Length,?int?utf8Length)
{unsafe{fixed?(byte*?p?=?&buffer){return?string.Create(utf16Length,?((IntPtr)p,?utf8Length),?static?(dest,?state)?=>{var?src?=?MemoryMarshal.CreateSpan(ref?Unsafe.AsRef<byte>((byte*)state.Item1),?state.Item2);Utf8.ToUtf16(src,?dest,?out?var?bytesRead,?out?var?charsWritten,?replaceInvalidSequences:?false);});}}
}//?slow
string?ReadStandardSerialzier(int?utf8Length)
{return?Encoding.UTF8.GetString(buffer.AsSpan(0,?utf8Length));
}通常,要從 byte[] 中獲取字符串,我們使用Encoding.UTF8.GetString(buffer)。但同樣,UTF8 是一種可變長度編碼,我們不知道 UTF16 的長度。UTF8 也是如此。GetString我們需要計算長度為 UTF16 以將其轉換為字符串,因此我們在內部掃描字符串兩次。在偽代碼中,它是這樣的:
var?length?=?CalcUtf16Length(utf8data);
var?str?=?String.Create(length);
Encoding.Utf8.DecodeToString(utf8data,?str);典型序列化程序的字符串格式為 UTF8,它不能解碼為 UTF16,因此即使您想要長度為 UTF16 以便作為 C# 字符串進行高效解碼,它也不在數據中。
但是,MemoryPack 在標頭中記錄 UTF16 長度和 UTF8 長度。因此,String.Create<TState>(Int32, TState, SpanAction<Char,TState>) 和 Utf8.ToUtf16的組合為 C# String 提供了最有效的解碼。
關于有效負載大小
與可變長度編碼相比,整數的固定長度編碼的大小可能會膨脹。然而,在現代,使用可變長度編碼只是為了減小整數的小尺寸是一個缺點。
由于數據不僅僅是整數,如果真的想減小大小,應該考慮壓縮(LZ4[18],ZStandard[19],Brotli[20]等),如果壓縮數據,可變長度編碼幾乎沒有意義。如果你想更專業和更小,面向列的壓縮會給你更大的結果(例如,Apache Parquet[21])。為了與 MemoryPack 實現集成的高效壓縮,我目前有 BrotliEncode/Decode 的輔助類作為標準。我還有幾個屬性,可將特殊壓縮應用于某些原始列,例如列壓縮。
[MemoryPackable]
public?partial?class?Sample
{public?int?Id?{?get;?set;?}[BitPackFormatter]public?bool[]?Data?{?get;?set;?}[BrotliFormatter]public?byte[]?Payload?{?get;?set;?}
}BitPackFormatter表示 bool[],bool 通常為 1 個字節,但由于它被視為 1 位,因此在一個字節中存儲八個布爾值。因此,序列化后的大小為 1/8。BrotliFormatter直接應用壓縮算法。這實際上比壓縮整個文件的性能更好。
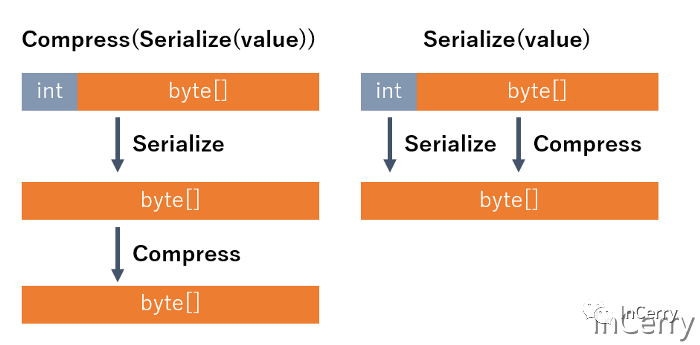
這是因為不需要中間副本,壓縮過程可以直接應用于序列化數據。Uber 工程博客上的使用CLP 將日志記錄成本降低兩個數量級[22]一文中詳細介紹了通過根據數據以自定義方式應用處理而不是簡單的整體壓縮來提取性能和壓縮率的方法。
使用 .NET7 和 C#11 新功能
MemoryPack 在 .NET Standard 2.1 的實現和 .NET 7 的實現中具有略有不同的方法簽名。.NET 7 是一種更積極、面向性能的實現,它利用了最新的語言功能。
首先,序列化程序接口利用靜態抽象成員,如下所示:
public?interface?IMemoryPackable<T>
{//?note:?serialize?parameter?should?be?`ref?readonly`?but?current?lang?spec?can?not.//?see?proposal?https://github.com/dotnet/csharplang/issues/6010static?abstract?void?Serialize<TBufferWriter>(ref?MemoryPackWriter<TBufferWriter>?writer,?scoped?ref?T??value)where?TBufferWriter?:?IBufferWriter<byte>;static?abstract?void?Deserialize(ref?MemoryPackReader?reader,?scoped?ref?T??value);
}MemoryPack 采用源生成器,并要求目標類型為[MemoryPackable]public partial class Foo,因此最終的目標類型為
[MemortyPackable]
partial?class?Foo?:?IMemoryPackable
{static?void?IMemoryPackable<Foo>.Serialize<TBufferWriter>(ref?MemoryPackWriter<TBufferWriter>?writer,?scoped?ref?Foo??value){}static?void?IMemoryPackable<Foo>.Deserialize(ref?MemoryPackReader?reader,?scoped?ref?Foo??value){}
}這避免了通過虛擬方法調用的成本。
public?void?WritePackable<T>(scoped?in?T??value)where?T?:?IMemoryPackable<T>
{//?If?T?is?IMemoryPackable,?call?static?method?directlyT.Serialize(ref?this,?ref?Unsafe.AsRef(value));
}//
public?void?WriteValue<T>(scoped?in?T??value)
{//?call?Serialize?from?interface?virtual?methodIMemoryPackFormatter<T>?formatter?=?MemoryPackFormatterProvider.GetFormatter<T>();formatter.Serialize(ref?this,?ref?Unsafe.AsRef(value));
}MemoryPackWriter/MemoryPackReader使用 ref字段。
public?ref?struct?MemoryPackWriter<TBufferWriter>where?TBufferWriter?:?IBufferWriter<byte>
{ref?TBufferWriter?bufferWriter;ref?byte?bufferReference;int?bufferLength;換句話說,ref byte bufferReference,int bufferLength的組合是Span<byte>的內聯。此外,通過接受 TBufferWriter 作為 ref TBufferWriter,現在可以安全地接受和調用可變結構 TBufferWriter:IBufferWrite<byte>。
//?internally?MemoryPack?uses?some?struct?buffer-writers
struct?BrotliCompressor?:?IBufferWriter<byte>
struct?FixedArrayBufferWriter?:?IBufferWriter<byte>針對所有類型的類型進行優化
例如,對于通用實現,集合可以序列化/反序列化為 IEnumerable<T>,但 MemoryPack 為所有類型的提供單獨的實現。為簡單起見,List<T> 可以處理為:
public?void?Serialize(ref?MemoryPackWriter?writer,?IEnumerable<T>?value)
{foreach(var?item?in?source){writer.WriteValue(item);}
}public?void?Serialize(ref?MemoryPackWriter?writer,?List<T>?value)
{foreach(var?item?in?source){writer.WriteValue(item);}
}這兩個代碼看起來相同,但執行完全不同:foreach to IEnumerable<T> 檢索IEnumerator<T>,而 foreach to List<T>檢索結構List<T>.Enumerator,y 一個優化的專用結構。
但是,MemoryPack 進一步優化了它。
public?sealed?class?ListFormatter<T>?:?MemoryPackFormatter<List<T?>>
{public?override?void?Serialize<TBufferWriter>(ref?MemoryPackWriter<TBufferWriter>?writer,?scoped?ref?List<T?>??value){if?(value?==?null){writer.WriteNullCollectionHeader();return;}writer.WriteSpan(CollectionsMarshal.AsSpan(value));}
}//?MemoryPackWriter.WriteSpan
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public?void?WriteSpan<T>(scoped?Span<T?>?value)
{if?(!RuntimeHelpers.IsReferenceOrContainsReferences<T>()){DangerousWriteUnmanagedSpan(value);return;}var?formatter?=?GetFormatter<T>();WriteCollectionHeader(value.Length);for?(int?i?=?0;?i?<?value.Length;?i++){formatter.Serialize(ref?this,?ref?value[i]);}
}//?MemoryPackWriter.DangerousWriteUnmanagedSpan
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public?void?DangerousWriteUnmanagedSpan<T>(scoped?Span<T>?value)
{if?(value.Length?==?0){WriteCollectionHeader(0);return;}var?srcLength?=?Unsafe.SizeOf<T>()?*?value.Length;var?allocSize?=?srcLength?+?4;ref?var?dest?=?ref?GetSpanReference(allocSize);ref?var?src?=?ref?Unsafe.As<T,?byte>(ref?MemoryMarshal.GetReference(value));Unsafe.WriteUnaligned(ref?dest,?value.Length);Unsafe.CopyBlockUnaligned(ref?Unsafe.Add(ref?dest,?4),?ref?src,?(uint)srcLength);Advance(allocSize);
}來自 .NET 5 的 CollectionsMarshal.AsSpan 是枚舉 List<T> 的最佳方式。此外,如果可以獲得 Span<T>,則只能在 List<int>或 List<Vector3>的情況下通過復制來處理。
在反序列化的情況下,也有一些有趣的優化。首先,MemoryPack 的反序列化接受引用 T?值,如果值為 null,則如果傳遞該值,它將覆蓋內部生成的對象(就像普通序列化程序一樣)。這允許在反序列化期間零分配新對象創建。在List<T> 的情況下,也可以通過調用 Clear() 來重用集合。
然后,通過進行特殊的 Span 調用,它全部作為 Span 處理,避免了List<T>.Add的額外開銷。
public?sealed?class?ListFormatter<T>?:?MemoryPackFormatter<List<T?>>
{public?override?void?Deserialize(ref?MemoryPackReader?reader,?scoped?ref?List<T?>??value){if?(!reader.TryReadCollectionHeader(out?var?length)){value?=?null;return;}if?(value?==?null){value?=?new?List<T?>(length);}else?if?(value.Count?==?length){value.Clear();}var?span =?CollectionsMarshalEx.CreateSpan(value,?length);reader.ReadSpanWithoutReadLengthHeader(length,?ref?span);}
}internal?static?class?CollectionsMarshalEx
{///?<summary>///?similar?as?AsSpan?but?modify?size?to?create?fixed-size?span.///?</summary>public?static?Span<T?>?CreateSpan<T>(List<T?>?list,?int?length){list.EnsureCapacity(length);ref?var?view?=?ref?Unsafe.As<List<T?>,?ListView<T?>>(ref?list);view._size?=?length;return?view._items.AsSpan(0,?length);}//?NOTE:?These?structure?depndent?on?.NET?7,?if?changed,?require?to?keep?same?structure.internal?sealed?class?ListView<T>{public?T[]?_items;public?int?_size;public?int?_version;}
}//?MemoryPackReader.ReadSpanWithoutReadLengthHeader
public?void?ReadSpanWithoutReadLengthHeader<T>(int?length,?scoped?ref?Span<T?>?value)
{if?(length?==?0){value?=?Array.Empty<T>();return;}if?(!RuntimeHelpers.IsReferenceOrContainsReferences<T>()){if?(value.Length?!=?length){value?=?AllocateUninitializedArray<T>(length);}var?byteCount?=?length?*?Unsafe.SizeOf<T>();ref?var?src?=?ref?GetSpanReference(byteCount);ref?var?dest?=?ref?Unsafe.As<T,?byte>(ref?MemoryMarshal.GetReference(value)!);Unsafe.CopyBlockUnaligned(ref?dest,?ref?src,?(uint)byteCount);Advance(byteCount);}else{if?(value.Length?!=?length){value?=?new?T[length];}var?formatter?=?GetFormatter<T>();for?(int?i?=?0;?i?<?length;?i++){formatter.Deserialize(ref?this,?ref?value[i]);}}
}EnsurceCapacity(capacity),可以預先擴展保存 List<T> 的內部數組的大小。這避免了每次都需要內部放大/復制。
但是 CollectionsMarshal.AsSpan,您將獲得長度為 0 的 Span,因為內部大小不會更改。如果我們有 CollectionMarshals.AsMemory,我們可以使用 MemoryMarshal.TryGetArray 組合從那里獲取原始數組,但不幸的是,沒有辦法從 Span 獲取原始數組。因此,我強制類型結構與 Unsafe.As 匹配并更改List<T>._size,我能夠獲得擴展的內部數組。
這樣,我們可以以僅復制的方式優化非托管類型,并避免 List<T>.Add(每次檢查數組大小),并通過Span<T>[index] 打包值,這比傳統序列化、反序列化程序性能要高得多。
雖然對List<T>的優化具有代表性,但要介紹的還有太多其他類型,所有類型都經過仔細審查,并且對每種類型都應用了最佳優化。
Serialize 接受 IBufferWriter<byte> 作為其本機結構,反序列化接受 ReadOnlySpan<byte> 和 ReadOnlySequence<byte>。
這是因為System.IO.Pipelines[23] 需要這些類型。換句話說,由于它是 ASP .NET Core 的服務器 (Kestrel) 的基礎,因此通過直接連接到它,您可以期待更高性能的序列化。
IBufferWriter<byte> 特別重要,因為它可以直接寫入緩沖區,從而在序列化過程中實現零拷貝。對 IBufferWriter<byte> 的支持是現代序列化程序的先決條件,因為它提供比使用 byte[] 或 Stream 更高的性能。開頭圖表中的序列化程序(System.Text.Json,protobuf-net,Microsoft.Orleans.Serialization,MessagePack for C#和 MemoryPack)支持它。
MessagePack 與 MemoryPack
MessagePack for C# 非常易于使用,并且具有出色的性能。特別是,以下幾點比 MemoryPack 更好
出色的跨語言兼容性
JSON 兼容性(尤其是字符串鍵)和人類可讀性
默認完美版本容錯
對象和匿名類型的序列化
動態反序列化
嵌入式 LZ4 壓縮
久經考驗的穩定性
MemoryPack 默認為有限版本容錯,完整版容錯選項的性能略低。此外,因為它是原始格式,所以唯一支持的其他語言是 TypeScript。此外,二進制文件本身不會告訴它是什么數據,因為它需要 C# 架構。
但是,它在以下方面優于 MessagePack。
性能,尤其是對于非托管類型數組
易于使用的 AOT 支持
擴展多態性(聯合)構造方法
支持循環引用
覆蓋反序列化
打字稿代碼生成
靈活的基于屬性的自定義格式化程序
在我個人看來,如果你在只有 C#的環境中,我會選擇 MemoryPack。但是,有限版本容錯有其怪癖,應該事先理解它。MessagePack for C# 仍然是一個不錯的選擇,因為它簡單易用。
MemoryPack 不是一個只關注性能的實驗性序列化程序,而且還旨在成為一個實用的序列化程序。為此,我還以 MessagePack for C# 的經驗為基礎,提供了許多功能。
支持現代 I/O API(
IBufferWriter<byte>,ReadOnlySpan<byte>,ReadOnlySequence<byte>)基于本機 AOT 友好的源生成器的代碼生成,沒有動態代碼生成(IL.Emit)
無反射非泛型 API
反序列化到現有實例
多態性(聯合)序列化
有限的版本容限(快速/默認)和完整的版本容錯支持
循環引用序列化
基于管道寫入器/讀取器的流式序列化
TypeScript 代碼生成和核心格式化程序 ASP.NET
Unity(2021.3) 通過 .NET 源生成器支持 IL2CPP
我們計劃進一步擴展可用功能的范圍,例如對MasterMemory 的 MemoryPack[24]支持和對 MagicOnion[25]的序列化程序更改支持等。我們將自己定位為Cysharp C# 庫[26]生態系統的核心。我們將付出很多努力來種下這一棵樹,所以對于初學者來說,請嘗試一下我們的庫!
版權信息
已獲得原作者獨家授權
原文版權:neuecc
翻譯版權:InCerry
原文鏈接:https://neuecc.medium.com/how-to-make-the-fastest-net-serializer-with-net-7-c-11-case-of-memorypack-ad28c0366516
參考資料
[1]
MemoryPack: https://github.com/Cysharp/MemoryPack
[2]MessagePack for C#: https://github.com/neuecc/MessagePack-CSharp/
[3]Utf8Json: https://github.com/neuecc/Utf8Json
[4]SignalR MessagePack Hub: https://learn.microsoft.com/en-us/aspnet/core/signalr/messagepackhubprotocol
[5]ZeroFormatter: https://github.com/neuecc/ZeroFormatter
[6]Utf8Json: https://github.com/neuecc/Utf8Json
[7]MagicOnion: https://github.com/Cysharp/MagicOnion
[8]MasterMemory: https://github.com/Cysharp/MasterMemory
[9]AlterNats: https://github.com/Cysharp/AlterNats
[10]增量源生成器: https://github.com/dotnet/roslyn/blob/main/docs/features/incremental-generators.md
[11]舊的源生成器: https://learn.microsoft.com/en-us/dotnet/csharp/roslyn-sdk/source-generators-overview
[12]bincode: https://github.com/bincode-org/bincode
[13]FlatBuffers: https://github.com/google/flatbuffers
[14]Protocol-buffers數字類型: https://developers.google.com/protocol-buffers/docs/encoding#varints
[15]MessagePack: https://github.com/msgpack/msgpack/blob/master/spec.md
[16]CBOR: https://cbor.io/
[17]結構沒有引用類型(非托管類型): https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/unmanaged-types
[18]LZ4: https://github.com/lz4/lz4
[19]ZStandard: http://facebook.github.io/zstd/
[20]Brotli: https://github.com/google/brotli
[21]Apache Parquet: https://parquet.apache.org/
[22]CLP 將日志記錄成本降低兩個數量級: https://www.uber.com/en-DE/blog/reducing-logging-cost-by-two-orders-of-magnitude-using-clp/
[23]System.IO.Pipelines: https://learn.microsoft.com/en-us/dotnet/standard/io/pipelines
[24]MasterMemory的MemoryPack: https://github.com/Cysharp/MasterMemory
[25]對MagicOnion: https://github.com/Cysharp/MagicOnion
[26]Cysharp C# 庫: https://github.com/Cysharp/




 MudBlazor組件庫介紹)











![[AHOI2009]飛行棋 BZOJ1800](http://pic.xiahunao.cn/[AHOI2009]飛行棋 BZOJ1800)


