一、SQL數據存儲的基本介紹
? ? ? ?數據庫中的數據存儲涉及頁(Page)和區(Extent)這兩個概念了。SQL server中數據存儲的基本單位是頁。為數據庫中的數據文件(.mdf或.ndf)分配的磁盤空間可以從邏輯上劃分成頁(從0到n連續編號),磁盤I/O操作在頁級執行。也就是說,SQL Server讀取或寫入數據的最小單位是以8KB為單位的頁。區是8個物理上連續的頁的集合,用來有效地管理頁。如果區內的8個頁屬于同一個表,則這種區稱為統一區;如果區內的8個頁分別屬于至少兩個不同的表,則這種區稱為混合區。頁在SQLScrver中,大小為8KB。這意味著SQL Server數據庫中每MB有128頁。每頁開頭是一個96字節的頁頭,用于存儲有關頁的系統信息。包括頁碼、頁類型、頁的可用空間,以及擁有該頁的對象的分配單元ID。不同類型的數據,存儲在不同類型的頁面里。在數據頁的存儲結構里,每個頁的前面96個字節是頁頭。SQL server通過這96個字節的頁頭和系統表,從邏輯層面上把表的存儲結構管理起來。針對表的存儲結構,SQLserver引入了一些概念:這些概念包括:object(對象)、partition(分區)、Hobt(堆或 B 樹)、allocation_unit(分配單元)。
? ? ? ?表存儲結構的關系如圖所示、每張表會有一個對應的objectID,同時每張表擁有一個或者多個Partition(通常一個Partition對應一個索引)。每個Partition會有一個或者多個Heap or B一Tree(簡稱為Hobt)。Hobt的結構是預留的,通常可以認為,Partition與Hobt是一樣的,PartitionID就是HobtID。每個Hobt會有至多三個分配單元用于存放數據,分別是data(數據)、LOB(大數據字段類型)、Row-Overflow(行溢出)。最頻繁使用的分配單元是Data。如果有LOB數據或者長度超過8000字節的記錄,則可能有另外的LOB分配單元和Row一Overflow分配單元:一個表可以有多個Partition,但是每個Partition以Hobt最多有三個分配單元,每個分配單元可以有許多頁。
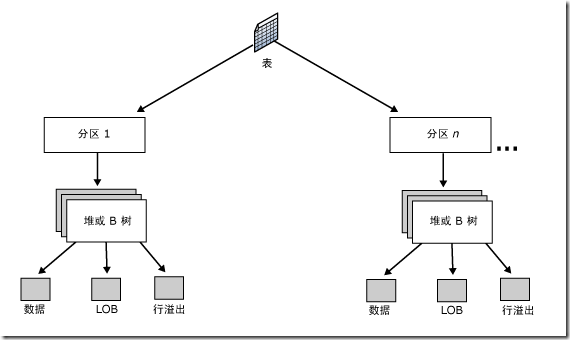
?
二、索引對數據存儲的影響
對于每個分配單元內的數據頁,根據表是否有索引,以及索引是聚焦索引或非聚焦索引,其組織方式常見有以下三種:
1、沒有索引
在這種情況下,數據是按堆的結構存儲,只有一個分區,在系統表里,對于這個分區下面的每個分配單元都有一個連接指向Index Allocation Map頁(IAM,索引指引頁),在IAM頁里,描述了區的信息。數據頁之間沒有任何關系,完全依賴IAM頁組織起來。對于這種表的查詢,數據庫會先查詢IAM頁,任何根據其提供的信息,遍歷所有區,將符合條件的頁返回。其結構入下圖所示:
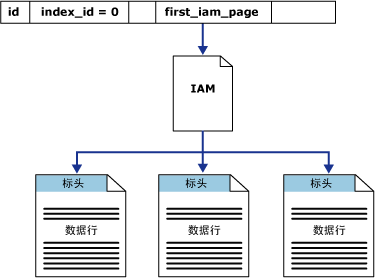
?
PS:表、分區信息等可通過以下系統表查詢
?


1 --查詢表的信息
2 select *from sys.objects where name='test3'
3 --查詢分區信息
4 select *from sys.partitions where object_id='1909581841'
5 --查詢分配單元信息
6 select *from sys.allocation_units where container_id='72057594041335808' ?
?
2.有非聚集索引但沒聚集索引
?這種情況下,數據依然是以堆結構存儲,不過針對每個非聚集索引,都會有一個對應的partition。對于這個partition下面的每個分配單元,都有一個連接指向根頁。數據頁之間通過前后指針互相關聯,在其結構底層,會有一個連接(文件號、頁號、行號)指向真正的數據。其結構如圖所示:
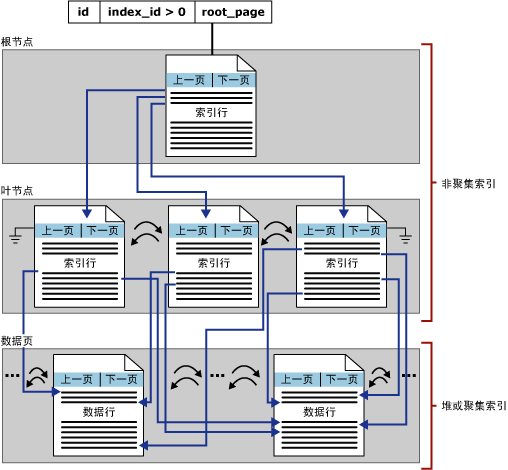
?
?
3、表有聚集索引
當表有索引時,其索引號為1,它有一個對應的partition,同樣這個partition下的分配單元都會連接到一個根頁,不過對于聚集索引來說,它在葉子節點上直接存儲真正的數據,其結構如下:
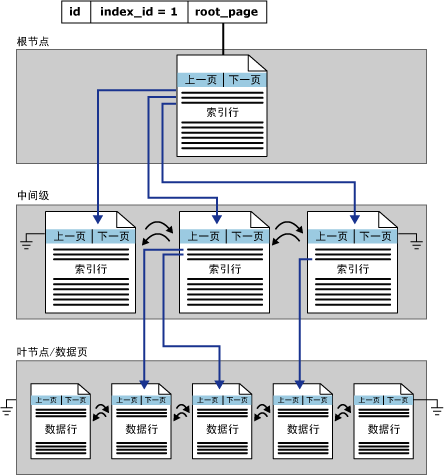
?
?三、樣例分析
創建3個樣例表并插入相同的數據,其中test1無索引,test2只有非聚集索引,test3有聚集索引:
1 use TEST;
2
3 create table test1
4 (
5 id int not null,
6 name char(10) null,
7 test varchar(max) null,
8 )
9
10
11 create table test2
12 (
13 id int not null,
14 name char(10) null,
15 test varchar(max) null,
16 )
17 CREATE NONCLUSTERED INDEX NCL_TEST_ID ON test2 (id)
18
19
20 create table test3
21 (
22 id int not null primary key,
23 name char(10) null,
24 test varchar(max) null,
25 ) 然后執行以下語句,查詢分配單元情況:
1 select e.*from sys.objects as a
2 inner join
3 sys.partitions as b
4 on a.object_id=b.object_id
5 inner join
6 sys.allocation_units as c
7 on b.partition_id=c.container_id
8 inner join
9 sys.system_internals_allocation_units as e
10 on c.allocation_unit_id=e.allocation_unit_id
11 where a.name='test1'
12
13
14 select e.*from sys.objects as a
15 inner join
16 sys.partitions as b
17 on a.object_id=b.object_id
18 inner join
19 sys.allocation_units as c
20 on b.partition_id=c.container_id
21 inner join
22 sys.system_internals_allocation_units as e
23 on c.allocation_unit_id=e.allocation_unit_id
24 where a.name='test2'
25
26 select e.*from sys.objects as a
27 inner join
28 sys.partitions as b
29 on a.object_id=b.object_id
30 inner join
31 sys.allocation_units as c
32 on b.partition_id=c.container_id
33 inner join
34 sys.system_internals_allocation_units as e
35 on c.allocation_unit_id=e.allocation_unit_id
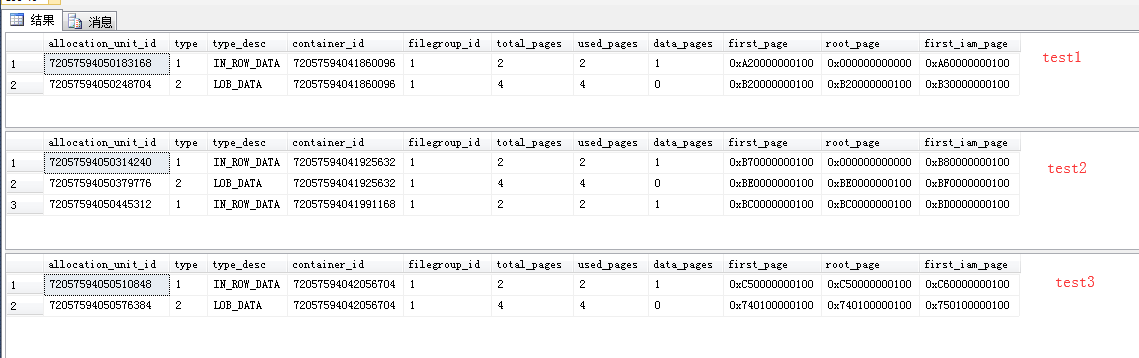
36 where a.name='test3' 得到結果如下圖所示:
?
?
?
?
?
?從圖中可以看到,它們都有data、lob這兩種分配單元,無索引的跟只有聚集索引的都是具有相同數量的partition以及頁,有非聚集索引的多了一個partition以及2頁數據來記錄。
PS:可通過以下語句查詢更詳細的partition信息:
1 dbcc ind('test','test1',1)
2 dbcc ind('test','test2',1)
3 dbcc ind('test','test3',1)
4
5 --dbcc page可查看詳細頁的信息 四、總結
1.無索引情況下數據以堆結構存儲,開iam頁來引導檢索,對于大表來說,建議建立聚集索引使數據有序化,便于處理;
2.非聚集索引是使用額外的存儲來增加檢索效率,對最底層的數據結構沒影響;
3.聚集索引不會增加額外的存儲,但會使底層的數據有序化;
?











和decode(‘utf-8’)的互轉)



獲取name和value并轉為json數組)



