前幾天發現網易云音樂的ncm格式很坑爹,由于網易云的部分音樂采取了這種流媒體平臺模式,這種格式的歌曲下載到設備本地以后只有在網易云音樂的app上面才能播放,而且還要在會員生效期間才能播
今天網易云弄出一個ncm,明天百度音樂來一個cnm,后天酷狗推出nmb,大后天qq音樂又來了個rnm。目前國內的音樂版權可謂是亂到了一個極端,阿叉想聽一個歌手的歌還得在酷狗和網易云之間來回跑,最終用戶就成了受害者
花錢買的歌我們理所當然有權利支配,而不是短期的租借,所以在這里提供一個在盡量不影響音質的情況下將ncm格式轉換成flac格式的方法

↓↓↓↓↓↓↓↓↓
(鏈接掛了的話就盡情騷擾阿叉的微信吧)
使用方法就是把要轉換的ncm音樂文件直接拖到 格式轉換.exe上
然后flac格式的音樂文件就會自己變出來啦
↑↑↑↑↑↑↑↑↑
以這首Sailing為例,經過轉換以后得到了flac文件:
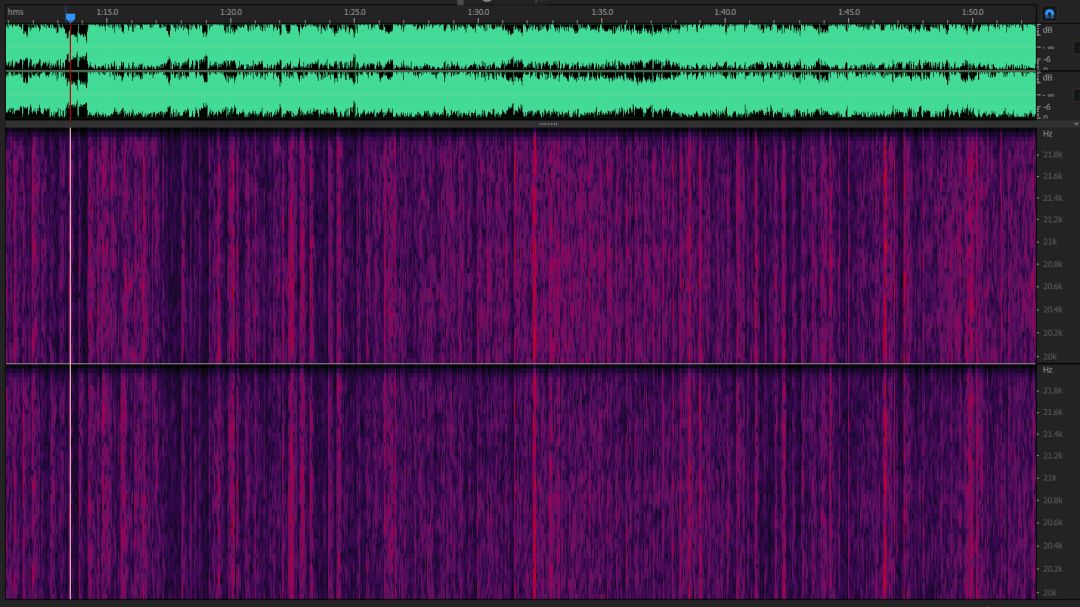
把成品導入AU之后可以發現高頻部分還是很完整的,完全符合無損音質的表現
和來自某狗的原版flac對比:
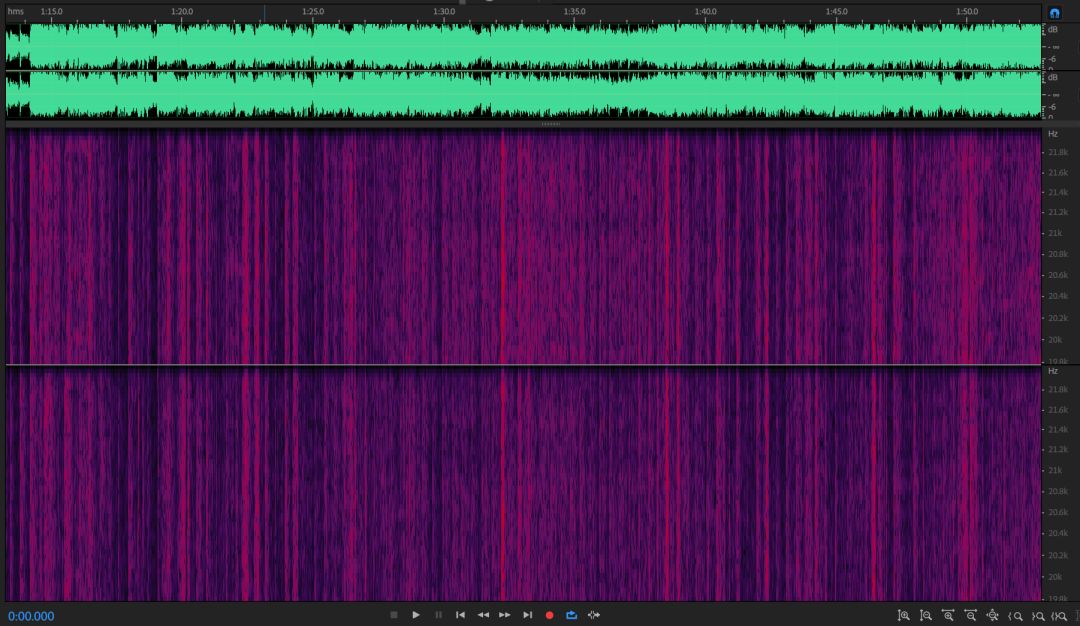
可以明顯看出,轉碼后高頻部分沒有被切掉,比特率都是968kbps,音質幾乎沒有區別,所以我們可以完美地完成無損到無損的轉換
附上源代碼和注釋:
import binascii
import struct
import base64
import json
import os
from Crypto.Cipher import AES
def dump(file_path):
? ? core_key = binascii.a2b_hex("687A4852416D736F356B496E62617857")
? ? meta_key = binascii.a2b_hex("2331346C6A6B5F215C5D2630553C2728")
#core_key和meta_key,把這個字符串按照十六進制反解析為二進制字節序列(bytes類型)
? ? unpad = lambda s : s[0:-(s[-1] if type(s[-1]) == int else ord(s[-1]))]
? ? f = open(file_path,'rb')
? ? header = f.read(8)
? ? assert binascii.b2a_hex(header) == b'4354454e4644414d'
#打開ncm文件并讀取8個字節,確認這8個字節是否是字節序列b'4354454e4644414d',0x43=C,所以這些字節是'CTENFDAM',說明這些就是ncm獨有的文件標記
? ? f.seek(2, 1)
? ? key_length = f.read(4)
? ? key_length = struct.unpack('
? ? key_data = f.read(key_length)
? ? key_data_array = bytearray(key_data)
? ? for i in range (0,len(key_data_array)): key_data_array[i] ^= 0x64
#獲取4字節的key,并且按照小端(
? ? key_data = bytes(key_data_array)
? ? cryptor = AES.new(core_key, AES.MODE_ECB)
? ? key_data = unpad(cryptor.decrypt(key_data))[17:]
#然后用之前的core_key創建了AES_ECB解密器,將整個明文分成若干段相同的小段,然后對每一小段進行加密,如果不足則會進行補足。
cryptor.decrypt(key_data)解析出來的是:
b'neteasecloudmusic10073261712832E7fT49x7dof9OKCgg9cdvhEuezy3iZCL1nFvBFd1T4uSktAJKmwZXsijPbijliionVUXXg9plTbXEclAE9Lb\r\r\r\r\r\r\r\r\r\r\r\r\r'
? ? key_length = len(key_data)
? ? key_data = bytearray(key_data)
? ? key_box = bytearray(range(256))
? ? c = 0
? ? last_byte = 0
? ? key_offset = 0
? ? for i in range(256):
? ? ? ? swap = key_box[i]
? ? ? ? c = (swap + last_byte + key_data[key_offset]) & 0xff
? ? ? ? key_offset += 1
? ? ? ? if key_offset >= key_length: key_offset = 0
? ? ? ? key_box[i] = key_box[c]
? ? ? ? key_box[c] = swap
? ? ? ? last_byte = c
#標準RC4-KSA算法去計算S-box
? ? meta_length = f.read(4)
? ? meta_length = struct.unpack('
? ? meta_data = f.read(meta_length)
? ? meta_data_array = bytearray(meta_data)
? ? for i in range(0,len(meta_data_array)): meta_data_array[i] ^= 0x63
? ? meta_data = bytes(meta_data_array)
? ? meta_data = base64.b64decode(meta_data[22:])
? ? cryptor = AES.new(meta_key, AES.MODE_ECB)
? ? meta_data = unpad(cryptor.decrypt(meta_data)).decode('utf-8')[6:]
? ? meta_data = json.loads(meta_data)
#meta_data的值是這樣的:
b"163key(Don't modify):L64FU3W4YxX3ZFTmbZ+8/fOGFX4ZDFzRxiE6WTSCw8Wbw8yYSVQFmAmCHw9A96ZnO0UOuMsVWYFWvoqD0/YcH3r7VAGU8B3l+FBJm4JL6is23S2yXChnSbfLIksnEUcTC7JtrA1JAoR0GVnz+OT3hGTJRsjGIVQXg2yide/YKBACffE+oYBApqZ5Isq0n7h/MlBnjn6ihuSlIl5V2rXEjSISQr031eSBdEVJ/JcwttzLafIPBh2FQfaVd/U0inWY5jxCXZCw/jxcIdGmGH/0Oft3UlNPt2kDBrsivoVuD03tMWL6A5Flg/jCbofSOblHFC79oU3WF9doUjD24BXuu6K7wyoWkgyG7SJu8tk72hkGw3rLK1nbTHsSEIPjocC6Ba9mzF48SB087MFTSn+9PXPZIboMXFXGI3TpMj4rR6cD+6CEWS7EoZrUC1cipi/A0jT/rFtAirM4hmkbrvslJumMHDJz1q9o6t3XRWydyoIaC3ktXuesyV8sbuoQ+Y/EMWNZRN3KhGR/jnnQPBtseQ=="
前面有22位的“163 key(Don't modify):”,去掉之后用base64解碼,并同樣地通過AES_ECB和meta_key進行解密:
b'music:{"musicId":441491828,"musicName":"\xe6\xb0\xb4\xe6\x98\x9f\xe8\xae\xb0","artist":[["\xe9\x83\xad\xe9\xa1\xb6",2843]],"albumId":35005583,"album":"\xe9\xa3\x9e\xe8\xa1\x8c\xe5\x99\xa8\xe7\x9a\x84\xe6\x89\xa7\xe8\xa1\x8c\xe5\x91\xa8\xe6\x9c\x9f","albumPicDocId":2946691248081599,"albumPic":"https://p4.music.126.net/wSMfGvFzOAYRU_yVIfquAA==/2946691248081599.jpg","bitrate":320000,"mp3DocId":"668809cf9ba99c3b7cc51ae17a66027f","duration":325266,"mvId":5404031,"alias":[],"transNames":[],"format":"mp3"}\r\r\r\r\r\r\r\r\r\r\r\r\r'
去掉前面的 music: ,然后轉為json字典,可以得到一些歌曲原本的信息,比如歌手,歌名之類的
? ? crc32 = f.read(4)
? ? crc32 = struct.unpack('
? ? f.seek(5, 1)
? ? image_size = f.read(4)
? ? image_size = struct.unpack('
? ? image_data = f.read(image_size)
? ? file_name = meta_data['musicName'] + '.' + meta_data['format']
? ? m = open(os.path.join(os.path.split(file_path)[0],file_name),'wb')
? ? chunk = bytearray()
? ? while True:
? ? ? ? chunk = bytearray(f.read(0x8000))
? ? ? ? chunk_length = len(chunk)
? ? ? ? if not chunk:
? ? ? ? ? ? break
? ? ? ? for i in range(1,chunk_length+1):
? ? ? ? ? ? j = i & 0xff;
? ? ? ? ? ? chunk[i-1] ^= key_box[(key_box[j] + key_box[(key_box[j] + j) & 0xff]) & 0xff]
? ? ? ? m.write(chunk)
? ? m.close()
? ? f.close()
#用修改后的RC4-PRGA算法進行還原并輸出新的歌曲文件,得到flac的原本數據
if __name__ == '__main__':
? ? import sys
? ? if len(sys.argv) > 1:
? ? ? ? for file_path in sys.argv[1:]:
? ? ? ? ? ? try:
? ? ? ? ? ? ? ? dump(file_path)
? ? ? ? ? ? except:
? ? ? ? ? ? ? ? pass
? ? else:
? ? ? ? print("Usage: python ncm_transformation.py \"File Name\"")
另:這個是git上一個大神弄的,看得懂的可以看一下,好像比這個要復雜點
https://github.com/nondanee/ncmdump











)



)



