文章目錄
- 8.1變量不是盒子
- 8.2 標識,相等性和別名
- 8.2.1 在==和is之間選擇
- 8.2.2 元組的相對不可變性
- 8.3 默認做淺復制
- (拓展)為任意對象做深復制和淺復制
- 深拷貝和淺拷貝有什么具體的區別呢?
- 8.4 函數的參數作為引用時
- 8.4.1 不要使用可變類型作為參數的默認值
- 總結(閱讀)
- 8.4.2 防御可變參數
- 8.5 del和垃圾回收
- 8.6 弱引用
8.1變量不是盒子
python變量類似于Java中的引用型變量,因此最好把他們理解為附注在對象上的標注.
a = [1,2,3]
b = a
a.append(7)
print(b)
輸出為:
[1, 2, 3, 7]
// 可以發現,a和b引用同一個列表,而不是那個列表的副本
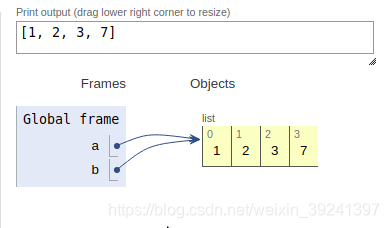
因為變量只不過是標注,所以可以為對象貼上多個標注,貼的多個標注就是別名.
8.2 標識,相等性和別名
每個變量都有標識,類型和值.對象一旦創建,它的標識一定不會變;可以把標識(ID)理解為對象在內存中的地址.
is運算符比較兩個對象的標識;
id()函數返回對象標識的整數表示.
標識最常使用is運算符檢查,而不是直接比較ID.
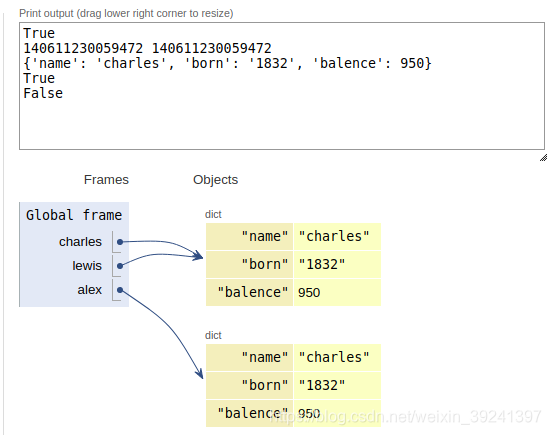
charles = {'name':'charles', 'born':'1832'}
lewis = charles
print(lewis is charles)
print(id(charles), id(lewis))
lewis['balence'] = 950
print(charles)
alex = {'name': 'charles', 'born': '1832', 'balence': 950}
print(alex == charles)
print(alex is charles)
輸出:
True
140640659352168 140640659352168
{'name': 'charles', 'born': '1832', 'balence': 950}
True //比較兩個對象,結果相同,這是因為dic類的__eq__方法就是這樣實現的
False //但是他們是不同的對象,標識不同.
//可以發現,charles和lewis綁定同一個對象,alex綁定另外一個對象
8.2.1 在==和is之間選擇
==運算符比較兩個對象的值(對象中保存的數據),而is比較對象的標識(標識就是在內存中的位置)
在變量和"單例值"之間比較時,應該使用is.可以使用is檢查變量綁定的值是不是None.
x is None
is 運算符比 == 速度快,因為它不能重載,所以 Python 不用尋找并調用特殊方法,而是直接比較兩個整數 ID。而 a == b 是語法糖,等同于 a.eq(b)。繼承自 object 的__eq__ 方法比較兩個對象的 ID,結果與 is 一樣。但是多數內置類型使用更有意義的方式覆蓋了 eq 方法,會考慮對象屬性的值。相等性測試可能涉及大量處理工作。
8.2.2 元組的相對不可變性
元組與多數 Python 集合(列表、字典、集,等等)一樣,保存的是對象的引用。而 str、bytes 和 array.array 等單一類型序列是扁平的,它們保存的不是引用,而是在連續的內存中保存數據本身(字符、字節和數字)。
元組的不可變性其實是指tuple數據結構的物理內容(保存的引用)不可變,與引用的對象無關.
復制對象時,相等性和一致性之間的區別有更深入的影響。副本與源對象相等,但是ID不同。可是,如果對象中包含其他對象,那么應該復制內部對象嗎?可以共享內部對象嗎?這些問題沒有唯一的答案。
8.3 默認做淺復制
l1 = [3, [55, 44], (7, 8, 9)]
l2 = list(l1)
print(l2)
print(l2 == l1)
print(l2 is l1)
print(l2[2] is l1[2])
l3 =l1[:]
print(l3)
print(l3 == l1)
print(l3 is l1)
print(l3[2] is l1[2])
l4 = l1
print(l4 == l1)
print(l4 is l1)
l1[1].append(66)
print(l1)
print(l2)
print(l3)
print(l4)
輸出結果如下:
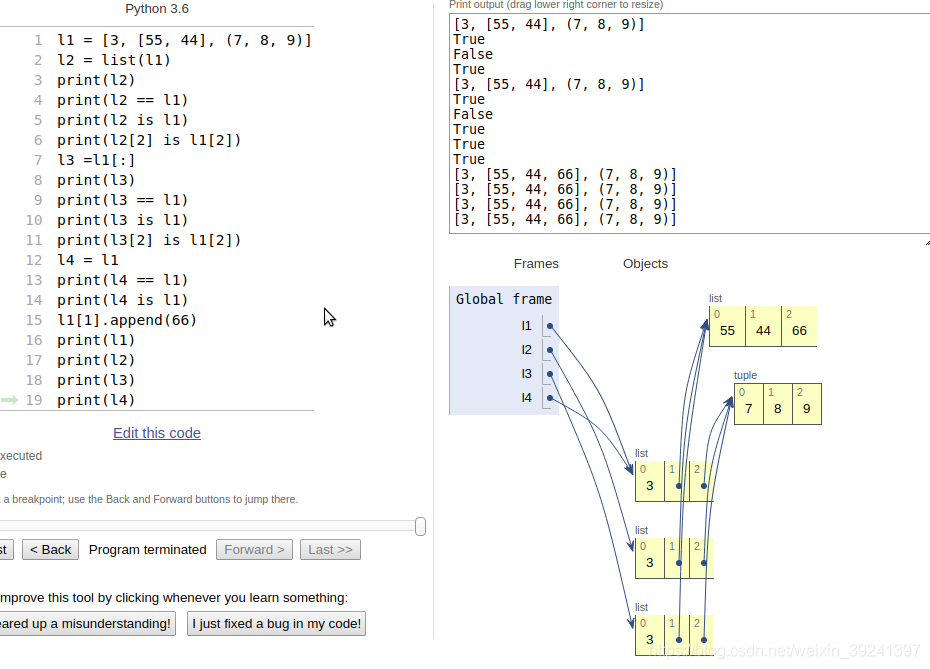
上圖發現:
- l2和l3對應著關于l1的淺拷貝,l4直接將l1起了一個別名,也就是說l4和l1指向了同一個對象。
- 淺拷貝對于內層引用有影響,即內層引用還是指向了同一個對象。
- [3, [55, 44], (7, 8, 9)] //list(l1)創建l1的副本
True //副本和源列表相等
對于列表和其他可變序列來說,還可以使用更簡潔的l3 = l1[:]語句來創建副本
然而,構造方法或者[:] 做的是淺復制(就是復制了最外層容器,副本中的元素是源容器中元素的引用).如果所有的元素都是不可變的,那么這樣沒有問題,如果有可變的元素,會出現問題.
l1 = [3,[66,55,44],(7,8,9)]
l2 = list(l1)
l1.append(100)
l1[1].remove(55)
print('l1:',l1)
print('l2:',l2)
l2[1]+=[33,22]
l2[2]+=(10,11)
print('l1:',l1)
print('l2:',l2)
輸出:
l1: [3, [66, 44], (7, 8, 9), 100]
l2: [3, [66, 44], (7, 8, 9)]
l1: [3, [66, 44, 33, 22], (7, 8, 9), 100]
l2: [3, [66, 44, 33, 22], (7, 8, 9, 10, 11)]
# 對**元組**來說,+=運算符創建一個新元組,然后重新綁定給變量l2[2].現在l1和l2中最后位置上的元組不是同一個對象.
# 總結:對+=和×=所做的增量賦值來說,如果左邊的變量綁定的是不可變對象,會創建新對象;如果是可變對象,會就地修改。
如圖:

(拓展)為任意對象做深復制和淺復制
淺復制沒什么問題,但有時我們需要的是深復制(即副本不共享內部對象的引用)。
import copy
class Bus:def __init__(self, passengers=None):if passengers is None:self.passengers = []else:self.passengers = passengersdef pick(self,name):self.passengers.append(name)def drop(self,name):self.passengers.remove(name)
bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
bus2 = copy.copy(bus1)
bus3 = copy.deepcopy(bus1)
print(id(bus1), id(bus2), id(bus3))
bus1.drop('Bill')
print(bus2.passengers)
print(id(bus1.passengers), id(bus2.passengers),id(bus3.passengers))
print(bus3.passengers)
輸出:
140694379943920 140694379943976 140694379944088
['Alice', 'Claire', 'David']
140694377362824 140694377362824 140694377336776
['Alice', 'Bill', 'Claire', 'David']
結果如圖:
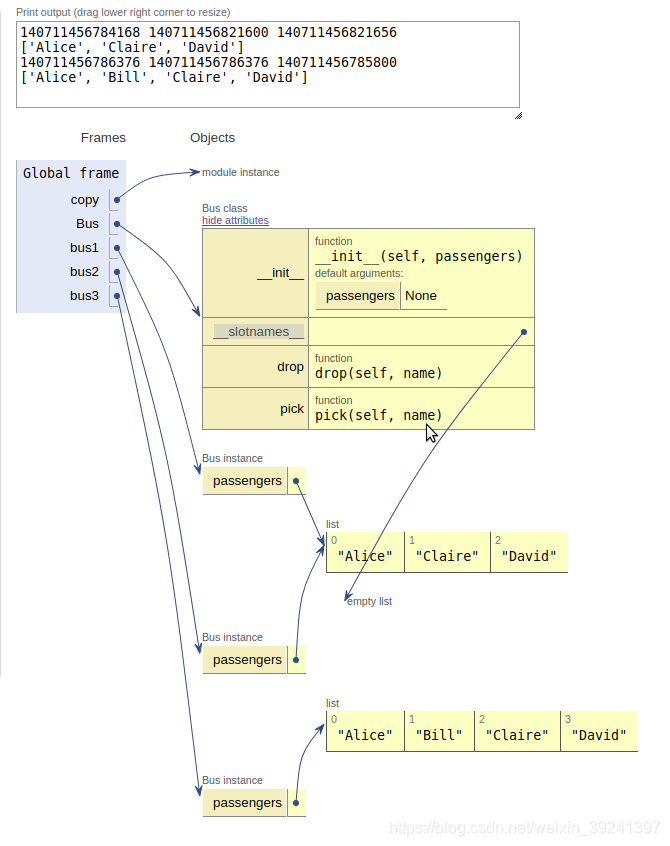
使用 copy 和 deepcopy,創建 3 個不同的 Bus 實例。
審查 passengers 屬性后發現:
- bus1 和 bus2 共享同一個列表對象,因為 bus2 是bus1 的淺復制副本。
- bus3 是 bus1 的深復制副本,因此它的 passengers 屬性指代另一個列表。
從上面可以發現,深拷貝和淺拷貝都會創建不同的對象,深拷貝是完全拷貝一個新的對象,淺拷貝不會拷貝子對象。
深拷貝和淺拷貝有什么具體的區別呢?
import copy
a = [1,2,3,['a','b','c']]
b = copy.copy(a)
c = copy.deepcopy(a)
a[3].append('d')
print(a)
print(b)
print(c)
結果如圖:
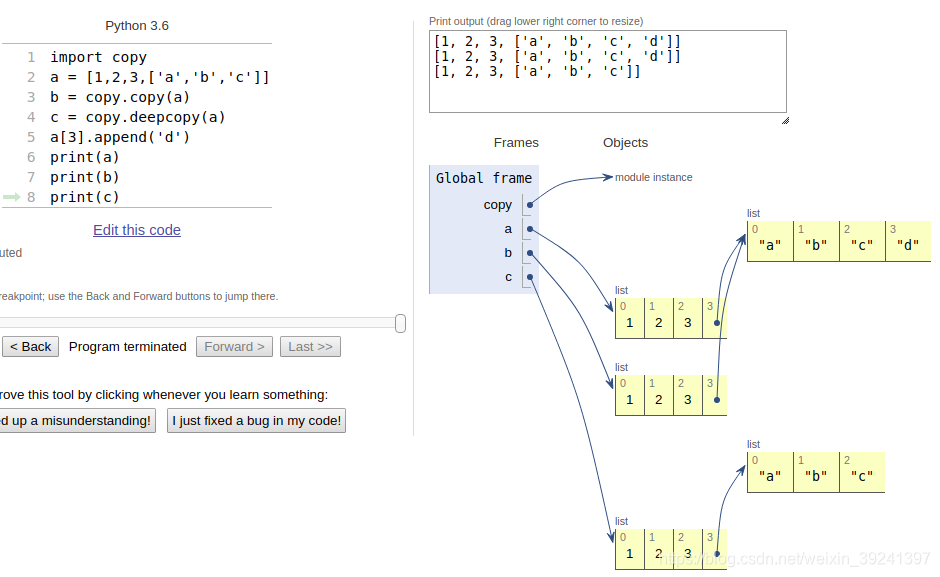
從上圖我們可以發現,
- copy.deepcopy()會完全拷貝一個新的對象出現;
- copy.copy()不會拷貝其子對象,也就是說,如果原來的對象里面又包含別的對象的引用,則這個新的對象還是會指向這個舊的內層引用。
總結:
copy.copy() 淺復制,不會拷貝其子對象,修改子對象,將受影響 .
copy.deepcopy() 深復制,將拷貝其子對象,修改子對象,將不受影響.
8.4 函數的參數作為引用時
python唯一支持的參數傳遞模式是共享傳參(call by sharing).
共享傳參指函數的各個形式參數獲得實參中各個引用的副本,也就是說,函數內部的形參是實參的別名。
這種方案的結果是,函數可能會修改作為參數傳入的可變對象,但是無法修改那些對象的標識(即不能把一個對象替換成另一個對象)。
def f(a,b):a += breturn a
x,y = 1,2
print(f(x, y))
print(x, y)
a = [1, 2]
b = [3, 4]
print(f(a, b))
print(a, b)
t = (10, 20)
u = (30, 40)
print(f(t, u))
print(t, u)
輸出:
3
1 2
[1, 2, 3, 4]
[1, 2, 3, 4] [3, 4]
(10, 20, 30, 40)
(10, 20) (30, 40)
我們發現數字x沒變,列表a變了,元組t沒變
8.4.1 不要使用可變類型作為參數的默認值
可選參數可以有默認值,這是python函數定義的一個很好的特性.但是我們應該避免使用可變的對象作為參數的默認值.
class HauntedBus:"""備受幽靈乘客折磨的校車"""def __init__(self, passengers=[]):self.passengers = passengersdef pick(self,name):self.passengers.append(name)def drop(self,name):self.passengers.remove(name)bus1 = HauntedBus(['Alice','Bill'])
print(bus1.passengers)
bus1.pick('Charlie')
bus1.drop('Alice')
print(bus1.passengers)
bus2 = HauntedBus()
bus2.pick('Carrie')
print(bus2.passengers)
bus3 = HauntedBus()
print(bus3.passengers)
bus3.pick('Dive')
print(bus2.passengers)
print(bus2.passengers is bus3.passengers)
print(bus1.passengers)
輸出:
['Alice', 'Bill']
['Bill', 'Charlie']
['Carrie']
['Carrie']//bus3一開始是空的,但是默認列表卻不為空
['Carrie', 'Dive']
True
['Bill', 'Charlie']
問題在于,沒有指定初始乘客的HauntedBus實例會共享同一個乘客列表。
使用可變類型作為函數參數的默認值有危險,因為如果就地修改了參數,默認值也就變了,這樣會影響以后使用默認值的調用。
修正的方法很簡單:在__init__方法中,傳入passengers參數時,應該把參數值的副本賦值給self.passengers,
def __init__(self,passengers =None):if passengers is None:self.passengers = []else:self.passengers = list(passengers)
總結(閱讀)
- 關于+和extend()方法,+是創建了新對象,extend是就地連接。
- 淺復制分為兩類:
- 第一類:t2 = t1[:]或者 t2 = list(t1) 都是了新的對象t2.但是內層引用還是指向同一個對象。
- 第二類:l2 = copy.copy(l1)
- 深復制: l3 = copy.deepcopy(l1) 完全拷貝了一個新的對象。
- 關于增量運算符+=和×=,以+=為例:a+=b,若+=前面的a為可變序列(例如list),則就地解決,若a為不可變序列(例如tuple),則會創建新的對象。
- 實例中圖片經過:http://www.pythontutor.com/ 生成
8.4.2 防御可變參數
如果定義的函數接收可變參數,應該謹慎考慮調用方是否期望修改傳入的參數。
示例 8-15 一個簡單的類,說明接受可變參數的風險
class TwilightBus:"""讓乘客銷聲匿跡的校車"""def __init__(self, passengers=None):if passengers is None:self.passengers = []else:self.passengers = passengers def pick(self, name):self.passengers.append(name)def drop(self, name):self.passengers.remove(name)
測試一下
>>> basketball_team = ['Sue', 'Tina', 'Maya', 'Diana', 'Pat']
>>> bus = TwilightBus(basketball_team)
>>> bus.drop('Tina')
>>> bus.drop('Pat')
>>> basketball_team
['Sue', 'Maya', 'Diana']
發現:下車的學生從籃球隊中消失了!
TwilightBus 違反了設計接口的最佳實踐,即“最少驚訝原則”。學生從校車中下車后,她的名字就從籃球隊的名單中消失了,這確實讓人驚訝。
這里的問題是,校車為傳給構造方法的列表創建了別名。正確的做法是,校車自己維護乘客列表。修正的方法很簡單:在 init 中,傳入 passengers 參數時,應該把參數值的副本賦值給 self.passengers,像示例 8-8 中那樣做(8.3 節)。
def __init__(self, passengers=None):
if passengers is None:self.passengers = []
else:self.passengers = list(passengers) ?
? 創建 passengers 列表的副本;如果不是列表,就把它轉換成列表。在內部像這樣處理乘客列表,就不會影響初始化校車時傳入的參數了。此外,這種處理方式還更靈活:現在,傳給 passengers 參數的值可以是元組或任何其他可迭代對象,例如set 對象,甚至數據庫查詢結果,因為 list 構造方法接受任何可迭代對象。
8.5 del和垃圾回收
del 語句刪除名稱,而不是對象。del 命令可能會導致對象被當作垃圾回收,但是僅當刪除的變量保存的是對象的最后一個引用,或者無法得到對象時。 重新綁定也可能會導致對象的引用數量歸零,導致對象被銷毀。
在 CPython 中,垃圾回收使用的主要算法是引用計數。實際上,每個對象都會統計有多少引用指向自己。當引用計數歸零時,對象立即就被銷毀:CPython 會在對象上調用__del__ 方法(如果定義了),然后釋放分配給對象的內存。
CPython 2.0 增加了分代垃圾回收算法,用于檢測引用循環中涉及的對象組——如果一組對象之間全是相互引用,即
使再出色的引用方式也會導致組中的對象不可獲取。Python 的其他實現有更復雜的垃圾回收程序,而且不依賴引用計數,這意味著,對象的引用數量為零時可能不會立即調用__del__ 方法。
8.6 弱引用
正是因為有引用,對象才會在內存中存在。當對象的引用數量歸零后,垃圾回收程序會把對象銷毀。但是,有時需要引用對象,而不讓對象存在的時間超過所需時間。這經常用在緩存中。
弱引用不會增加對象的引用數量。引用的目標對象稱為所指對象(referent)。因此我們說,弱引用不會妨礙所指對象被當作垃圾回收。
弱引用在緩存應用中很有用,因為我們不想僅因為被緩存引用著而始終保存緩存對象。

補充-可迭代對象(補充高階函數,以及常用的高階函數))

數據結構)



)







![[Windows Phone] 實作不同的地圖顯示模式](http://pic.xiahunao.cn/[Windows Phone] 實作不同的地圖顯示模式)

![[STemWin教程入門篇]第一期:emWin介紹](http://pic.xiahunao.cn/[STemWin教程入門篇]第一期:emWin介紹)

