Python語言運行環境:
- windows
- linux
- unix
- Macos等等
博客記錄內容:
Python3的所有語法、面向對象思維、運用模塊進行編程、游戲編程、計算機仿真。
Python是什么類型的語言:
Python是腳本語言,腳本語言(Scripting language)是電腦編程語言,因此也能讓開發者藉以編寫出讓電腦聽命行事的程序。以簡單的方式快速完成某些復雜的事情通常是創造腳本語言的重要原則,基于這項原則,使得腳本語言通常比 C語言、C++語言 或 Java 之類的系統編程語言要簡單容易。一個腳本可以使得本來要用鍵盤進行的相互式操作自動化。一個Shell腳本主要由原本需要在命令行輸入的命令組成,或在一個文本編輯器中,用戶可以使用腳本來把一些常用的操作組合成一組串行。主要用來書寫這種腳本的語言叫做腳本語言。很多腳本語言實際上已經超過簡單的用戶命令串行的指令,還可以編寫更復雜的程序。
腳本語言另有一些屬于腳本語言的特性:
- 語法和結構通常比較簡單
- 學習和使用通常比較簡單
- 通常以容易修改程序的“解釋”作為運行方式,而不需要“編譯”
- 程序的開發產能優于運行性能
Python基本內容:
-
Python2使用的輸出語句是printf
“hello!”,而Python使用的是print(“hello!”),python3對Python不兼容,在Python下使用printf
"hello!"會報錯,不僅如此Python寫完每一條語句不用像C語言一樣加分號 -
print(“hello”+“user”),這里的加號表示字符串的拼接,print(“hello\n”*8)這條語句是輸出8次hello,但是如果把乘號換做加號就會報錯,因為在 Python 中不能把兩個完全不同的東西加在一起,比如說數字和文本。 如果我需要在一個字符串中嵌入一個雙引號,正確的做法是:可以利用反斜杠(\)對雙引號轉義:",或者用單引號引起這個字符串。print(“hel"l"o”)或者print(‘hel"l"o’)
-
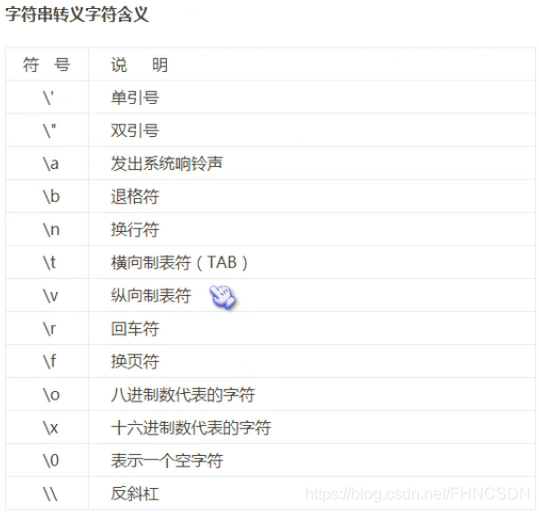
Python的縮進格式可以理解為C語言的花括號,寫程序時要注意代碼的縮進。input()函數是Python的內置函數(BIF)可以獲取用戶的輸入,返回的是字符串類型,可以使用int()這個內置函數,int(input的返回值)將字符串轉化為整型。可以使用 \ \來對\進行轉義,當輸入路徑的時候可以用的到,除此之外還可以使用原始字符串,就是在變量賦值的時候前面加一個r,例如:str=r ’ C : \ file ‘然后打印str就會看到想要輸出的結果:C:\file。因為此時的str就會變成:‘C:\ \now’,他會自動的將 \ 轉義。非要在原始字符串結尾輸入反斜杠,可以如何靈活處理?str = r’C:\Program Files\FishC\Good’ ’ \ \ ’
-
長字符串:當我們需要輸出一個跨越多行的字符串時就用到了這種寫法,使用三重引號字符串。如:str=" " " 要輸出的跨越多行的內容" " ",也可以用三對單引號,必須成對編寫。
-
python里面變量的命名規則和C語言命名規則一樣,變量名可以包括字母、下劃線、數字,但是變量名不能以數開頭。變量使用之前要賦值,還有就是字符串必須使用單引號或者雙引號括起來必須成對出現。
-
and操作符作用是當and(相當于C語言中的&&)左邊和右邊都是true時才會返回布爾類型的True,與之對應的是or(||),當有一邊為真時就返回True。not是將當前的布爾類型數取相反的值,not True=False。除此之外,在python中3<4<5是合法的相當于3<4 and 4<5。 -
random模塊,random模塊里面有一個函數randint(),即隨即返回一個整數。使用之前要將模塊導入import random,使用方法:
number=random.randomint(1,10)。即在1到10之間隨機生成一個整數。 -
Python里面的if語句和while語句用法和C語言里面的用法基本一樣就是將花括號去掉換成冒號并且用縮進表示代碼執行書順序。
-
可以通過
dir(_ _builtins_ _)這個指令查看Python的BIF,如下圖,里面純小寫的是Python的BIF。

-
當我們想要知道這些BIF如何使用時可以,輸入以下指令help(函數名),如下圖所示:

-
內置類型轉換函數,int()作用是將數字字符串或者浮點型(轉化浮點型的時候不是四舍五入而是直接將小數部分去掉)轉化為整型(我感覺就是C語言里面的強制轉換);str()作用是:將數字或者其他類型轉換為字符串;float()作用是:將字符串或者整形數轉換為浮點數。type()這個函數會明確告訴我們括號內數據的數據類型,除此之外還有isinstance()函數來確定數據的數據類型。isinstance這個函數需要兩個參數,第一個參數是待確定類型的數據,第二個參數是指定的類型,然后函數會返回一個bool類型的值,true表示參數類型一致,false表示參數類型不一樣。
-
python里面的加減乘運算和其他語言沒啥區別,就是除法運算 / 兩個整形數相除會得到一個精確的數,而在C語言中只是得到一個整數,小數部分后面的忽略(不進行四舍五入)。python的 / / 這個叫“地板除”,這個運算符和C語言中的還不太一樣,它不管除數和被除數是否是整型,最后得到的是都是整數,只是如果除數和被除數有浮點類型結果也是浮點類型,但是小數部分是0。還有一個運算符 **表示冪運算,例如:3 星星2=9。運算符優先級:先乘除后加減,但是冪運算的運算符順序比左邊的一元運算優先級高比右邊的一元運算級低,例如:-3星星2=-9 而不是 9,3星星-2=0.111111。運算優先級如下圖:
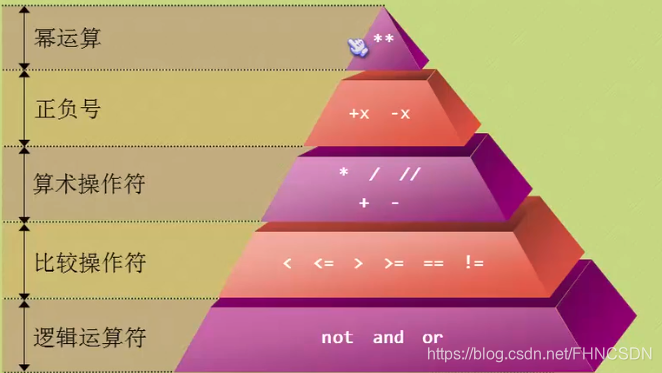
- 三元操作符:語法:x if 條件 else y。若滿足條件返回x若不滿足條件返回y。assert這個關鍵字我們稱之為“斷言”,當這個關鍵字后面的條件為假的時候,程序自動崩潰并拋出
AssertionError的異常。一般來說我們可以在程序中植入檢查點,當需要確保程序中某一個條件為真才能讓程序正常工作的話,assert關鍵字就非常有用了。 - for循環語法:for 目標 in 表達式:后面是循環體
favourite="hello"
for i in favourite:print(i,end=" ")
輸出結果:
h e l l o
這里end=" ",表示輸出一個字符就在其后跟一個空格。member=["早","你好","吃飯了嗎"]
for each in member:print(each,len(each))運行結果:
早 1
你好 2
吃飯了嗎 4
len()這個函數是計算字符串長度的
- range()函數for循環的小伙伴,語法:
range(start, stop[,step]),這個BIF有三個參數,其中中括號括起來的兩個表示這兩個參數是可選的,step=1表示第三個參數(步長)的值默認是1。range這個BIF的作用是生成一個從start參數(默認是0)的值開始到stop參數值(計數到stop結束,但是不包括stop)結束的數字序列。
range(10)
(0,1,2,3,4,5,6,7,8,9)
range(1,11)
(1,2,3,4,5,6,7,8,9,10)
range(0,30,5)
(0,5,10,15,20,25)
range(0,-10,-1)
(0,-1,-2,-3,-4,-5,-6,-7,-8,-9)
range(0)
()
range(1,0)
()range(5)
list(range(5))
[0, 1, 2, 3, 4]
list()函數將range函數的輸出結果轉化為列表。for循環和range配合使用:
for i in range(1,10,2):print(i)
1
3
5
7
9
列表:
列表里面可以存放不同的數據類型。
-
創建一個普通列表:
numbe=[1,2,3,4,5] -
創建一個混合列表:
number=["你好",1,2,3.5,[4,5,6]] -
創建一個空列表:
empty=[] -
如何向列表里面添加元素
numbe.append("你好")這里使用函數:append(),里面的參數是向列表添加的內容,這里這個.表示是numbe這個列表對象里面的方法但是這個函數的參數只能是一個參數,也就是說一次只能添加一個元素到列表,如果想要添加多個參數到列表就要用到extend()函數這個函數用于列表的擴張,參數是一個列表。如:numbe.extend(['hahah','不好']) 得到:[1, 2, 3, 4, 5, '你好', 'hahah', '不好']append()和extend()這兩個函數是添加到列表的尾部,如果想添加到列表的任意位置就要用到inster()函數,這個函數有兩個參數,第一個參數是代表在列表中的位置,第二個參數表示在這個位置要插入的元素。numbe.insert(0,['好不好'])得到:[['好不好'], 1, 2, 3, 4, 5, '你好', 'hahah', '不好'] -
列表元素的交換可以利用中間變量,那么如何將元素從列表中刪除呢?方法一:
remove()函數,參數是要刪除的列表元素名稱。numbe.remove(numbe[0])方法二:利用del方法del方法不是列表中的方法,所以不用.來使用它,直接del numbe[2]這是一條語句,也可以直接del numbe直接將列表刪除。方法三:利用pop()函數,pop()函數其實是用于將列表中的元素取出來,也就是這個函數的返回值,若不給這個函數添加參數則默認取出最后一個元素,添加了參數之后可以取出固定的元素,元素取出后列表里面就沒有了。如:numbe.pop()或者numbe.pop(要取出元素的名稱(可以用下標)) -
列表切片:如果想要一次性獲得多個元素,利用列表切片可以簡單實現這個要求,如:
numbe是列表名稱,那么numbe[1:3]就是將列表切片成從下標一到下標二的一個列表,原列表沒有改變,numbe[:3]表示從列表頭到下標為二處進行切片,numbe[1:]表示從列表下標第一個元素到列表尾部切片,numbe[:]表示將整個列表切片,就是對整個進行了拷貝。
列表的一些常用操作符:
- 比較操作符,就是大于小于符號,列表的比較和字符串的比較一樣從列表中的第一個元素比較(字符串是比較ASIIC值),如果相等繼續比較第二個元素,如果不相等則比較結束。
- 邏輯操作符
- 連接操作符,列表的連接可以用+進行連接得到一個新的列表,必須要保證+兩邊的數據類型相同
- 重復操作符,乘法可以讓列表內容進行重復,如:
list4=[12] 。list*=3.得到:[12, 12, 12] - 成員關系操作符,這個可以用in,如:
list4=[12] , 12 inlist4返回True ,13 in list4返回False ,12 not in list4,返回False注意:in只能描述元素和列表關系,如果列表中還有列表那么,用 in 判斷列表中的元素時子列表中的元素不算入。但是可以利用下標查找子列表中是否有某元素,如:list=[1,[2,3]],2 in list[1]返回Ture。訪問列表中的列表的元素可以用二維數組的方式,list[1][2]第一個下標表示子列表在列表中的位置,第二個下標表示要訪問的元素在子列表中的位置下標。 - dir(list)可以查看列表的內置方法,用的時候要加
.count()函數可用于計算列表某個元素在列表中出現的次數,函數參數為要找的那個元素,返回參數出現次數。如果想得到某個元素的下標還可以用index()函數,函數返回的是要查找元素在列表中第一次出現的元素下標,這個函數有三個參數,第一個是要查找下標的元素,第二個參數是查找的起始位置,第三個參數是要查找的結束位置(如果要查找的元素就在結束位置則不會找到,要將結束位置的值加一才可以找到)。 - reverse()函數,將整個列表結構順序倒轉,該函數沒有參數。列表里面子列表里面的元素順序不變。
- sort()函數:將列表元素進行排隊,若沒有參數則默認從小到大排列,若想得到從大到小在原地翻轉(reverse)一下即可。這個函數有三個參數:sort(func,key,reverse),第一個參數func指定排序的算法,第二個參數key是和算法搭配的關鍵字,第三個參數是reverse默認是False,當把它置為True時則從大到小排列,如:sort(reverse=Ture)。
元組:
元組:帶上枷鎖的列表,元組和列表在實際使用上是非常相似的,元組是不可以隨意刪除和插入元素的元組是不可改變的,就像C語言里面定義的字符串常量一樣不能被修改。定義元組的時候大多數情況下用(),比如:tuple1=(1,2,3),訪問元組元素和訪問列表元素是一樣的都可以用下標訪問。如:tuple1[1],可以使用:來獲得元組的切片或者元組的拷貝,這一點和列表一樣。列表的標志性符號是[ ],那么元組的標志性符號是什么呢?當創建的元組里面只有一個元素時要在這個元素后面加上逗號,為了說明這個變量是元組,如果想要創建一個空元組那么就直接寫tuple1=()就行,總的來說,逗號貌似是元組的標志,就算寫為這樣tuple2=1,2,3那么他的類型也是元組類型。對于元組和列表來說,乘號是重復操作符,將元組里面的元素重復乘以的數值。同樣加號可以用來元組的拼接。
- 那么元組如何來更新呢?可以使用切片加拼接來更新一個元組,
temp=tuple1[:3]+("你好",)+tuple2[:]將得到:(1, 2, 3, '你好', 1, 2, 3)注意你好后面的·逗號不能丟,這個是用來說明它是一個元組的。如果有兩個元素就不用在末尾加逗號了。 - 元組的刪除,可以使用del語句,刪除某個元素可以使用切片和拼接來操作。同樣關系運算符也可以在元組中使用。
字符串:
- python中沒有字符這個類型,同樣對字符串進行操作也可以使用切片進行操作進而得到一個新的字符串。同樣也可以像索引列表、元組元素一樣,用索引來訪問字符串中的某個元素。得到的一個字符也是字符串類型。字符串和元組一樣,一旦被定義就無法添加或者刪除元素,想要添加或者更新字符串可以使用切片和拼接進行操作。同樣關系運算符in也適用于字符串,總的來說:字符串、列表、元組都是屬于序列類型的。
因為字符串在程序中使用是非常常見的,所以字符串有很多方法。
capitalize(),把字符串的第一個字符改為大寫,str1.capitalize()casefold(),把整個字符串改為小寫, str1.casefold()center()將字符串居中,并使用空格填充至長度width的新字符串。tr1.center(20)count(sub[,start[,end]])返回sub子字符串在字符串里面出現的次數,start和end表示范圍,可選。str1.count("o",0,2)或者str1.count("o")encode(encoding='utf-8',errors='strict')以encoding指定的編碼格式對字符串進行編碼。endswith(sub[,start[,end]])檢查字符串是否有以sub子字符串結束,如果是返回True否則返回False,start和end參數表示范圍,可選。str1.endswith('l')hello是以llo結尾或者lo結尾但不是l結尾所以返回False。expandtabs([tabsize=8])把字符串中的tab符號(\t)轉化為空格,默認空格參數是tabsize=8,一個tab范圍是8個字符。find(sub[,start[,end]])檢測sub是否在字符串中,如果有返回索引值否則返回-1,start和end參數標識范圍,可選。index(sub,[start,[,end]])和find方法一樣,不過如果sub不在string中會產生一個異常isalnum()如果字符串至少有一個字符并且所有字符都是字母或者數字返回True,否則返回Falseisalpha()如果字符串至少有一個字符并且所有的字符都是字母則返回True,否則返回Falseisdecimal()如果字符串只包含十進制數字則返回True,否則返回Falseisdigit()如果字符串只包含數字返回True否則返回Falseislower()如果字符串中至少包含一個區分大小寫的字符,并且這些字符都是小寫,則返回True否則返回Falseisnumeric()如果字符串只包含數字字符,則返回True否則返回Falseisspace()如果字符串中只包含空格,則返回True否則返回Falseistitle()如果字符串是標題化(所有單詞都是以大寫開始,其余字母均小寫),則返回True否則返回False。isupper()如果字符串中至少包含一個區分大小寫的字符,并且這些字符都是大寫則返回True否則返回Falsejoin(sub)以字符串作為分隔符,將sub插入到中所有的字符之間str1.join("hh")ljust(width)返回一個左對齊的字符串,并使用空格填充至長度為width的新字符串lower()將字符串中所有大寫字符轉化為小寫lstrip()去掉字符串左邊的所有空格partition(sub)找到字符串sub,把字符串分成一個3元組(pre_sub,sub,fol_sub),如果字符串中不包含sub則返回(‘原字符串’,’ ‘,’ ')replace(old,new[,count])把字符串中的old子字符串換成new子字符串,如果count指定,則替換不超過count次。rfind(sub,[start[,end]])類似于find方法,不過是從右邊開始查找。rindex(sub,[,start[,end]])類似于index方法不過是從右邊開始rjust(width)發送一個右對齊的字符串,并使用空格填充至長度為width的新字符串rpartition(sub)類似于partition方法,不過是從右邊開始查找。rstrip()刪除字符串末尾的空格split(sep=None,maxsplit=-1)不帶參數默認是以空格為分隔符切片的字符串,如果maxsplit有參數設置,則僅分割maxsplit個子字符串,返回切片后的子字符串拼接成的列表。splitlines(([keepends]))按照\n分割,返回一個包含各行作為元素的列表,如果keepends參數指定,則返回前keepsends行startswith(prefix,[,start[,end]])檢查字符串是否有以prefix開頭,是則返回True,否則返回False,start和end參數可以指定范圍檢查,可選。strip([chars])刪除字符串前邊和后邊的所有空格,chars參數可以定制刪除的字符,可選。swapcase()翻轉字符串的大小寫title()返回標題化(所有單詞都是以大寫開始,其余字母均小寫)的字符串。translate(table)根據table的規則(可以由str.maketrans(‘a’,‘b’)定制)轉換字符串中的字符。舉個栗子:str1="aaabbbsss",str1.translate(str.maketrans('a','s'))可以得到sssbbbsss這樣的字符串。upper()轉換字符串中的所有小寫字母為大寫zfill(width)返回長度為width的字符串,原字符串右對齊,前面用0填充。
字符串格式相關方法:
-
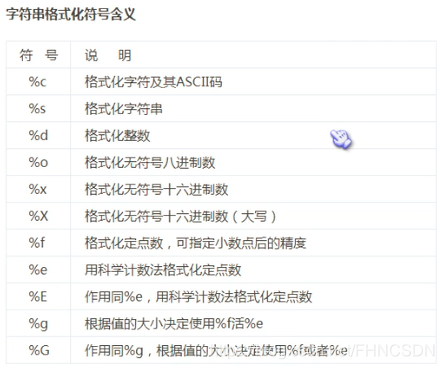
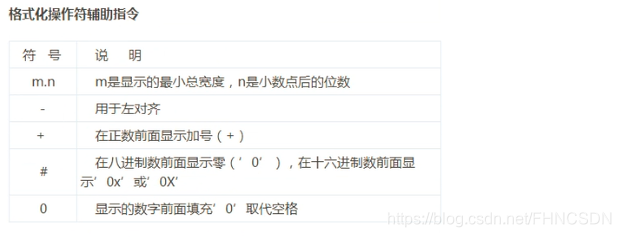
format()函數,這個函數里面有未知參數和已知參數,舉個栗子:"{0} don't {1} you!".format("I","like")這里花括號括起來的叫做未知參數,再來個栗子:"{aa} don't {bb} you!".format(aa="I",bb="like")這里花括號括起來的叫做關鍵字參數,其實我感覺這個和C語言里面的占位符很像,但是他只是用于字符串的輸出。那么怎么輸出花括號呢?用雙重花括號就可以了。那么再來看一下這個:"{0:.1f}{1}".format(32.66,"MB")輸出結果:'32.7MB'這里的冒號表示格式化符號的開始,.1f表示四舍五入保留一位小數,格式化操作符有很多,如下圖:
-
"%c %c %c"%(97,98,99)得到三個數字的ASCII值:'a b c' -
str2="hello" "%s" % str2得到:'hello' -
"%d + %d +%d=%d" % (1,2,3,1+2+3) 得到:'1 + 2 +3=6'
"%5.1f" % 3.14得到:' 3.1'這里的5表示這個字符串的最小有5個位置,小數點后面的1表示保留一位小數。如果有一個負號就不是這樣了,例如:"%-5.1f" % 3.14得到:'3.1 '
序列:
列表、元組和字符串的共同點:
- 都是可以通過索引得到每一個元素
- 默認索引值總是從0開始
- 可以通過分片的方式得到一個范圍內的元素集合
- 有很多共同的操作符(重復操作符、拼接操作符、成員關系操作符)
常見的序列BIF
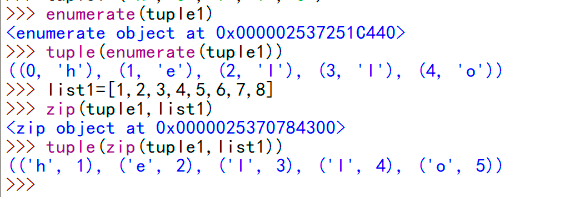
list()把一個可迭代(迭代: 重復反饋過程的活動,其目的通常是為了接近或者達到所需的目標或結果,每一次對過程重復稱為一次迭代,每一次迭代的結果都會被用來下一次迭代的初始值)對象轉換為列表,list()無參數是默認生成一個空的列表。tuple()把一個可迭代的對象轉換為元組。無參數是默認生成一個空的元組。str()把它的參數轉化為字符串len(sub),作用:返回序列的長度max(),作用:返回序列或者參數集合中的最大值,如果是字符的話就會比較其ASCII碼,但是要注意使用max和min要保證所比較的數據類型都是一樣的。min(),作用:返回序列或者參數集合中的最小值,如果是字符的話就會比較其ASCII碼sum(iterable[,start=0])返回序列iterable和可選參數start的總和。同樣保證所加的數據類型都是一樣的,字符串不是數據類型,不能進行sum操作。sorted(),將序列默認從小到大排序reversed(),返回的是迭代器對象,可以通過list將序列逆轉enumerate()這個函數作用是枚舉,作用是生成由每元素的索引加元素本身組成的元組,例如:tuple(enumerate(tuple1))得到:((0, 'h'), (1, 'e'), (2, 'l'), (3, 'l'), (4, 'o'))zip(),返回由各個參數組成的元組,例如:下圖
函數、對象、模塊:
一:函數
- 定義一個函數使用def關鍵字,格式:
def MyFirstFunction():冒號后面根據函數的縮進可以得知函數的執行體。函數調用直接使用函數名加小括號進行調用例如:MyFirstFunction(),如果函數有參數,只需在括號內填寫參數即可,調用時只需加上參數即可。還有就是函數的返回值:和C語言一樣函數的返回使用關鍵字return,將所需要的數值返回。總的來說:python和C函數有點不同,python函數參數在定義時不用填寫參數類型,定義時也不用填寫返回值類型。 - 關鍵字參數就是你在定義函數時填寫的形式參數名稱,調用參數時可以通過關鍵字參數調用,這樣函數就會按照關鍵字參數進行傳參,而不是按照順序。默認參數:是指在函數定義時給參數的默認值,如:
def MySecondFunction(a=3,b=5):這里的3和5就是默認參數在調用函數時如果有參數則使用給出的參數,沒有參數則使用默認參數。搜集參數:就是可變參數定義方式:def MySecondFunction(*part):可以通過len(part)來計算參數的個數,并且可以通過part[元素下表]來訪問參數。其實part就是一個元組作為函數的參數。
函數與過程:
- 嚴格來說,pyhton只有函數沒有過程,python所有函數都會返回一個返回值,有返回值的返回返回值沒有返回值的返回None。python可以返回多個數值通過列表或者元組。
- python參數的作用域問題,在函數里面定義的參數都稱為局部變量,出了這個函數這些參數存儲空間就會被釋放。全局變量作用域是整個程序,在函數里面也可以訪問全局變量,但是不要再函數內部試圖去修改它,因為那樣python會在函數內部新建一個和全局變量名字一樣的局部變量代替。如果真的下想要在函數內部修改全局變量那么可以只用
global關鍵字先聲明一下這個全局變量例如:global num 然后再修改num=...
內嵌函數和閉包:
內嵌函數: 允許在一個函數創建另一個函數,這種函數稱為內嵌函數或內部函數。
栗子:
def func1():print("這里是第一個函數:")def func2():#定義第二個函數print("這里是第二個函數:")func2()#這里是在函數一內部調用函數二。調用結果:
這里是第一個函數:
這里是第二個函數:def func1():print(1)def func2():print(2)def func3():print(3)def func4():print(4)func4()func3()func2()
結果:
1
2
3
4
這里需要注意,在func1這個函數里面可以隨意的調用func2但是出了這個func1函數,外邊就不能調用func2。
閉包: 如果在一個內部函數對外部作用域(但不是在全局作用域的變量進行引用),那么內部函數就會被認為閉包。
栗子:
def Funx(x):def Funy(y):return x*yreturn Funy
在這里說明一下:Funy相對于Funx來說是Funx的內部函數,funx就是funy的外部作用域
在Funy里面引用了Funx的變量x,所以Funy就是閉包函數調用的時候:
如果 i=Funcx(5),那么此時i的類型就會變作function類型,然后可以i(2)再次調用計算得出10
除此之外還可以:Funcx(2)(3)這樣調用
注意: 在外部的代碼段仍然不能調用內部函數,在內部函數中只能對外部作用域的變量進行引用不能對其進行修改,就像全局變量和局部變量的關系,如下面的錯誤示例:
def Fun1():x=5def Fun2():x*=5return xreturn Fun2()此時對Func1調用會出現以下錯誤:
Traceback (most recent call last):File "<pyshell#70>", line 1, in <module>Fun1()File "<pyshell#69>", line 6, in Fun1Fun2()File "<pyshell#69>", line 4, in Fun2x*=5
UnboundLocalError: local variable 'x' referenced before assignment那么有沒有解決方案呢?
方案一:可以使用容器(列表,元組這些都是容器,他們不是存放在棧里面)
def Fun1():x=[5]def Fun2():x[0]*=5return x[0]return Fun2()
方案二:使用關鍵字 nonlocal 就像之前用的global用法一樣。nonlocal用來聲明不是局部變量的
def Fun1():x=5def Fun2():nonlocal xx*=5return xreturn Fun2()
lambda表達式:
- python允許使用lambda關鍵字創建匿名函數,使用lambda關鍵字定義匿名函數:
lambda x: x**x冒號前面的是參數,冒號后面的是函數的返回值,當有多個參數時只需用逗號隔開。使用匿名函數只需要g=lambda x: x**x 將函數任意起一個名字然后調用: g(5) - 使用python寫一些執行腳本的時候,使用lambda就可以省下定義函數的過程,比如說我們只需要寫一個簡單的腳本來管理服務器時間,我們就不需要專門定義一個函數然后再寫調用,使用lambda就可以使得代碼更加精簡。
- 對于一些比較抽象的函數并且整個程序下來只需要調用一兩次的函數,有時候給函數起個名字也是比較頭疼的問題,使用lambda就不需要考慮命名問題了。
- 可以和lambda結合使用的兩個BIF,第一個是:
filter()是過濾器(過濾掉False的內容)。filter有兩個參數,第一個參數是一個函數或者None,第二個參數可迭代的數據。如果第一個參數是函數,則將第二個可迭代數據里的每一個元素作為元素的參數進行計算,把返回True的值篩選出來并成一個列表,如果第一個參數是None,則將第二個參數為True的數據篩選出來,變成一個列表。如下面栗子:
第一個參數為None的情況下:
filter(None,[1,2,0,False,True,"hello"])
<filter object at 0x00000253725D0BE0>返回的是一個對象list(filter(None,[1,2,0,False,True,"hello"]))將返回的對象轉換為列表
[1, 2, True, 'hello']第一個參數是函數的情況下:
def odd(x):return x%2
temp=range(10)
filter(odd,temp)
<filter object at 0x00000253725D0BE0>
list(filter(odd,temp))
[1, 3, 5, 7, 9]lambda和filter()結合使用:
list(filter(lambda x:x%2,range(10)))
- 第二個常用的BIF:
map()map在編程中一般理解為映射的意思,map()這個函數也有兩個參數,一個是函數和一個可迭代的序列,這個函數的功能是將序列的每一個元素作為函數的參數進行運算,直到序列元素全部加工完畢,返回一個加工后的新序列。舉一個簡單的例子:
list(map(lambda x:x**x,range(10)))
[1, 1, 4, 27, 256, 3125, 46656, 823543, 16777216, 387420489]
遞歸:
-
程序調用自身的編程技巧稱為遞歸(
recursion)。遞歸作為一種算法在程序設計語言中廣泛應用。一個方法或函數在其定義或說明中有直接或間接調用自身的一種方法,它通常把一個大型復雜的問題層層轉化為一個與原問題相似的規模較小的問題來求解,遞歸策略只需少量的程序就可描述出解題過程所需要的多次重復計算,大大地減少了程序的代碼量。 -
python默認遞歸的深度是100層但是可以調用
sys.setrecursionlimit(參數自行設計)來得到自己想要的遞歸層數。下面舉一個使用遞歸計算一個數的階乘的例子:
def Func(x):if x==1:return 1else:return x*Func(x-1)
num=int(input("請輸入要計算階乘的數字:"))
print("得到結果:",Func(num))
如果輸入數字5,則下面是遞歸過程:5層遞歸

遞歸舉例:
利用迭代和遞歸計算菲波那切數列第20個數的值:
迭代方法:
def Func(n):n1=1n2=1n3=1if n<1:print("輸入有誤!")return -1while(n-2)>0:n3=n2+n1n1=n2n2=n3n-=1return n3num=int(input("請輸入要得到第幾位數字:"))
ret=Func(num)
if ret!=-1:print("數字是:",ret)
遞歸方法(遞歸方法效率比較低謹慎使用):
def Func(n):if n<1:print("輸入有誤!")return -1if n==1 or n==2:return 1else:return Func(n-1)+Func(n-2)
num=int(input("請輸入要得到第幾位數字:"))
if Func(num)!=-1:print(Func(num))
漢諾塔游戲:
def hanoi(n,x,y,z):if n==1:print(x,'--->',z)else:hanoi(n-1,x,z,y)#將前n減1個盤子從x移動到y上,中間的z參數就是起轉換作用print(x,'--->',z)#將第n個盤子從x移動到z上hanoi(n-1,y,x,z)#將前n減1個盤子從y移動到z上,中間的x參數就是起轉換作用
num=int(input("請輸入漢諾塔的層數:"))
hanoi(num,'x','y','z')
這里:x,y,z表示三個柱子如果輸入參數3則會輸出:
x ---> z
x ---> y
z ---> y
x ---> z
y ---> x
y ---> z
x ---> z
只要按照下面的方式進行移動就好。
字典:(當索引不好用時)
python的字典在很多地方也被稱為哈希值。,字典是一種映射類型而不是序列類型。
- 創建和訪問字典
dict1={"李寧":"一切皆有可能","耐克":"Just do it"}
字典的創建用花括號,冒號之前的叫做鍵值(key)冒號之后的叫做對應的值(value)
print("李寧的口號是:",dict1["李寧"])------->李寧的口號是: 一切皆有可能
值可以通過鍵來訪問創建空字典:dict1{}dict()函數可以用來創建字典,這個函數只有一個參數
例子:dict3=dict((("小明",100),("小王",90),("小張",100)))這種方式是將元組當做dict函數的參數來創建字典,要求必須存在映射關系dict4=dict(張三="80",李四="90")這種方式是使用的關鍵字參數: = 如何給字典元素賦值或者改變鍵的值(當鍵不存在的時候,此時如果給鍵賦值那么將會創建一個新的鍵):
dict3['小明']=90 ----->{'小明': 90, '小王': 90, '小張': 100}
若這個鍵沒有:
dict3["小李"]=88 ------>{'小明': 90, '小王': 90, '小張': 100, '小李': 88}
字典創建函數:
dict()函數:這個函數是一個工廠類型的函數。可以使用**fromkeys()**方法創建并返回一個新的字典,他有兩個參數,第一個參數是字典的鍵,第二個參數是對應字典的值,如果第二個參數不提供的話,默認就是None。使用如下:
dict4={}
dict4.fromkeys((1,2,3))#當第二個參數沒有提供時
{1: None, 2: None, 3: None}dict4.fromkeys((1,2,3),'number')#當第二個參數有參數時,會將所有的鍵的值設為第二個參數的值
{1: 'number', 2: 'number', 3: 'number'}dict4.fromkeys((1,2,3),("one","two","three"))#當第二個參數有多個參數時,他并不會將鍵和值一一對應,而是將第二個參數看做一個整體,作為所有鍵的值。
{1: ('one', 'two', 'three'), 2: ('one', 'two', 'three'), 3: ('one', 'two', 'three')}當用fromkeys()試圖修改一個字典的值時,他并不會將其值修改而是重新創建一個字典
字典的訪問方法:
keys(),values(),items()
dic4={"1":"one","2":"two","3":"three"}
dic4.keys()
dict_keys(['1', '2', '3'])
list(dic4.keys())
['1', '2', '3']list(dic4.values())
['one', 'two', 'three']list(dic4.items())
[('1', 'one'), ('2', 'two'), ('3', 'three')]
如果想要知道某個鍵是否在字典中,那么可以使用get()方法,如果不使用get()方法去訪問字典中一個沒有的鍵時,會報錯,如下:
dic4={"1":"one","2":"two","3":"three"}
dic4[4]
Traceback (most recent call last):File "<pyshell#33>", line 1, in <module>dic4[4]
KeyError: 4如果使用get()方法:
dic4.get(4)他將不會報錯只是返回一個None對象,如果想要他返回別的值同樣
可以設置參數:dic4.get(4,"沒有此鍵"),若找不到鍵時會返回"沒有此鍵"
同樣成員關系操作符也可以應用于字典當中,4 in dic4 則返回False清空一個字典使用clear()方法:
dic4.clear()setdefault()函數和get函數用法相似,只是他在字典中找不到時會新建鍵值對
b
{'1': 'one', '3': 'three'}
b.setdefault("2")
b
{'1': 'one', '3': 'three', '2': None}同樣可以給定鍵的值
b.setdefault("3","4")
'three'
b
{'1': 'one', '3': 'three', '2': None}update()方法:用一個字典去更新另一個字典
c={"4":"four"}
b.update(c)
b
{'1': 'one', '3': 'three', '2': None, '4': 'four'}
pop()(給定鍵彈出對應的值,那么鍵和值在字典里面就不見了)和popitem()(隨機彈出一個鍵值對)區別:
a.popitem()
('3', 'three')
a
{'1': 'one', '2': 'two'}
b
{'1': 'one', '2': 'two', '3': 'three'}
b.pop('2')
'two'
b
{'1': 'one', '3': 'three'}
淺拷貝和賦值:
淺拷貝得到的新的字典和原字典的地址不一樣發生了改變,而賦值則和原來的地址是一樣的,因為賦值就相當于有一個新的標簽指向了字典,改變淺拷貝得到的字典不會影響到原字典而改變通過賦值得到的字典則會改變原字典。
dic4={"1":"one","2":"two","3":"three"}
id(dic4)#查看id
2404516300160
a=dic4.copy()
b=dic4
id(a)
2404516299520
id(b)
2404516300160
集合:
用花括號括起來的一堆東西,但是花括號里面的東西沒有映射關系,那么這個數據類型就是集合。集合有什么特點呢?在我的世界里你就是唯一。這和我們在數學中學到的集合也是一樣的,集合里面沒有重復的元素。集合不支持索引
如何創建一個集合?
- 一種是直接把一堆元素用花括號括起來,集合是無序的
- 一種是使用set()工廠函數,set的參數可以是一個列表,一個元組或者一個字符串。
set1={1,2,3,4,5}
set1
{1, 2, 3, 4, 5}
set2=set([1,2,3,4,5,5])
set2
{1, 2, 3, 4, 5}
- 可以使用for把集合中的數據一個個讀取出來
- 可以通過in和not in判斷一個元素在集合中是否存在
- 可以使用add()方法為集合添加元素,
set2.add(6) - 同樣可以使用remove()方法移除集合中的元素,
set2.remove(3) - 當我們希望集合中的元素不被改變時,可以使用
frozenset()方法定義集合
num=frozenset({1,2,3,4,5}),得到:frozenset({1, 2, 3, 4, 5}),此時集合是不可變的

)

)
...)

)



)








