廣播:
如今的opencv已經提供了LBF的訓練和測試代碼,推薦閱讀
《使用OpenCV實現人臉關鍵點檢測》
face alignment 流程圖
train階段

測試階段

預處理
裁剪圖片
- tr_data = loadsamples(imgpathlistfile, 2);
說明: 本函數用于將原始圖片取ground-truth points的包圍盒,然后將其向左上角放大一倍。然后截取此部分圖像,同時變換ground-truth points.hou,然后為了節省內存,使用了縮放,將其縮放在150*150的大小內,作為我們后續處理的圖像及ground-truth points。
截取前示意圖:

截取后示意圖:

縮放后示意圖:

注意: loadsamples的第二個參數是2,表明需要進行縮放,但是測試時,并沒有進行縮放,參數為1.
To do list:本函數使用的真實特征點的包圍盒截取的圖像,在實際作用時,肯定不能去真實特征點截取圖像了。我們應該改為人臉檢測框代替這個真實特征點的包圍盒,如果檢測不到,再用真實特征點的包圍盒替代.
function Data = loadsamples(imgpathlistfile, exc_setlabel)
%LOADSAMPLES Summary of this function goes here
% Function: load samples from dbname database
% Detailed explanation goes here
% Input:
% dbname: the name of one database
% exc_setlabel: excluded set label
% Output:
% Data: loaded data from the database
% 基本步驟:
% 1. 載入圖片,取ground_truth shape的包圍盒,然后放大一倍,截取圖像。
% 同時相應地變換shape.
% 2. 為了防止圖片過大,我們把圖像控制在150*150內.
% 3. 用matlab自帶的人臉檢測求解或者直接拿bbox代替bbox_facedet
% 4. 后面還為了防止train文件下夾雜了test的圖片,做了排除處理.
%imgpathlist = textread(imgpathlistfile, '%s', 'delimiter', '\n');Data = cell(length(imgpathlist), 1);setnames = {'train' 'test'};% Create a cascade detector object.
% faceDetector = vision.CascadeObjectDetector();
% bboxes_facedet = zeros(length(imgpathlist), 4);
% bboxes_gt = zeros(length(imgpathlist), 4);
% isdetected = zeros(length(imgpathlist), 1);parfor i = 1:length(imgpathlist)img = im2uint8(imread(imgpathlist{i}));Data{i}.width_orig = size(img, 2);Data{i}.height_orig = size(img, 1);% Data{i}.img = img% shapepath = strrep(imgpathlist{i}, 'png', 'pts');%這一句和下一句是一樣的用途shapepath = strcat(imgpathlist{i}(1:end-3), 'pts');Data{i}.shape_gt = double(loadshape(shapepath)); % Data{i}.shape_gt = Data{i}.shape_gt(params.ind_usedpts, :);% bbox = bounding_boxes_allsamples{i}.bb_detector; %Data{i}.bbox_gt = getbbox(Data{i}.shape_gt); % [bbox(1) bbox(2) bbox(3)-bbox(1) bbox(4)-bbox(2)]; %shape的包圍盒% cut original image to a region which is a bit larger than the face% bounding boxregion = enlargingbbox(Data{i}.bbox_gt, 2.0); %將true_shape的包圍盒放大一倍,形成更大的包圍盒,以此裁剪人臉,也有通過人臉檢測框放大的region(2) = double(max(region(2), 1)); %防止放大后的region超過圖像,這樣一旦超過坐標會變成負數。因此取了和1的最大值.region(1) = double(max(region(1), 1));bottom_y = double(min(region(2) + region(4) - 1, Data{i}.height_orig)); %同理防止過高,過寬right_x = double(min(region(1) + region(3) - 1, Data{i}.width_orig));img_region = img(region(2):bottom_y, region(1):right_x, :);Data{i}.shape_gt = bsxfun(@minus, Data{i}.shape_gt, double([region(1) region(2)])); %68*2的矩陣減去一個向量% to save memory cost during trainingif exc_setlabel == 2ratio = min(1, sqrt(single(150 * 150) / single(size(img_region, 1) * size(img_region, 2)))); %如果圖像小于150*150,則不用縮放,否則縮放到150*150以內img_region = imresize(img_region, ratio);Data{i}.shape_gt = Data{i}.shape_gt .* ratio;end Data{i}.ori_img=img;Data{i}.lefttop=[region(1) region(2)]; %自己補充的Data{i}.bbox_gt = getbbox(Data{i}.shape_gt);Data{i}.bbox_facedet = getbbox(Data{i}.shape_gt); %應該改為人臉檢測框% perform face detection using matlab face detector%{bbox = step(faceDetector, img_region);if isempty(bbox)% if face detection is failed isdetected(i) = 1;Data{i}.bbox_facedet = getbbox(Data{i}.shape_gt);elseint_ratios = zeros(1, size(bbox, 1));for b = 1:size(bbox, 1)area = rectint(Data{i}.bbox_gt, bbox(b, :));int_ratios(b) = (area)/(bbox(b, 3)*bbox(b, 4) + Data{i}.bbox_gt(3)*Data{i}.bbox_gt(4) - area); end[max_ratio, max_ind] = max(int_ratios);if max_ratio < 0.4 % detection failisdetected(i) = 0;elseData{i}.bbox_facedet = bbox(max_ind, 1:4);isdetected(i) = 1;% imgOut = insertObjectAnnotation(img_region,'rectangle',Data{i}.bbox_facedet,'Face');% imshow(imgOut);end end%}% recalculate the location of groundtruth shape and bounding box% Data{i}.shape_gt = bsxfun(@minus, Data{i}.shape_gt, double([region(1) region(2)]));% Data{i}.bbox_gt = getbbox(Data{i}.shape_gt);if size(img_region, 3) == 1Data{i}.img_gray = img_region;else% hsv = rgb2hsv(img_region);Data{i}.img_gray = rgb2gray(img_region);end Data{i}.width = size(img_region, 2);Data{i}.height = size(img_region, 1);
endind_valid = ones(1, length(imgpathlist));
parfor i = 1:length(imgpathlist)if ~isempty(exc_setlabel)ind = strfind(imgpathlist{i}, setnames{exc_setlabel}); %strfind是找imgpathlist{i}中含有setnames{exc_setlabel}='test'的地址if ~isempty(ind) % | ~isdetected(i)ind_valid(i) = 0;endend
end% learn the linear transformation from detected bboxes to groundtruth bboxes
% bboxes = [bboxes_gt bboxes_facedet];
% bboxes = bboxes(ind_valid == 1, :);Data = Data(ind_valid == 1); %找到含有test的地址,并排除出去,保證Data都是train_dataendfunction shape = loadshape(path)
% function: load shape from pts file
file = fopen(path);if ~isempty(strfind(path, 'COFW'))shape = textscan(file, '%d16 %d16 %d8', 'HeaderLines', 3, 'CollectOutput', 3);
elseshape = textscan(file, '%d16 %d16', 'HeaderLines', 3, 'CollectOutput', 2);
end
fclose(file);shape = shape{1};
endfunction region = enlargingbbox(bbox, scale)region(1) = floor(bbox(1) - (scale - 1)/2*bbox(3));
region(2) = floor(bbox(2) - (scale - 1)/2*bbox(4));region(3) = floor(scale*bbox(3));
region(4) = floor(scale*bbox(4));% region.right_x = floor(region.left_x + region.width - 1);
% region.bottom_y = floor(region.top_y + region.height - 1);
end示意圖:

對一幅圖片,實際上我們感興趣的就是人臉區域,至于其他部分是無關緊要的。因此出于節省內存的原因,我們需要裁剪圖片。前面已經講述了裁剪的方法。從坐標系的角度來看,實際上是從原始坐標系轉化到以擴充后的盒子為基礎的坐標系。即如圖藍色的為原始坐標系,就是一張圖片的坐標系。紅色的為后來裁剪后的坐標系,而黑色框為人臉框(可以是人臉檢測獲得的,也可以是ground_truth points的包圍盒)。那么坐標系的變化,簡單而言可以寫作:
shapes_gt?=shapes_gt?[Region(1),Region(2)]shapes_gt~=shapes_gt?[Region(1),Region(2)]
上式就是原來的shape經過裁剪后的坐標。后來還加上了縮放,即:
shapes_gt?=shapes_gt?.?Ratioshapes_gt~=shapes_gt~.?Ratio
左右翻轉圖片
train_model.m 第60行
% Augmentate data for traing: assign multiple initial shapes to each
% image(為每一張圖片增加多個初始shape)
Data = Tr_Data; % (1:10:end);
Param = params;if Param.flipflag % if conduct flippingData_flip = cell(size(Data, 1), 1);for i = 1:length(Data_flip)Data_flip{i}.img_gray = fliplr(Data{i}.img_gray);%左右翻轉Data_flip{i}.width_orig = Data{i}.width_orig;Data_flip{i}.height_orig = Data{i}.height_orig; Data_flip{i}.width = Data{i}.width;Data_flip{i}.height = Data{i}.height; Data_flip{i}.shape_gt = flipshape(Data{i}.shape_gt); Data_flip{i}.shape_gt(:, 1) = Data{i}.width - Data_flip{i}.shape_gt(:, 1);Data_flip{i}.bbox_gt = Data{i}.bbox_gt;Data_flip{i}.bbox_gt(1) = Data_flip{i}.width - Data_flip{i}.bbox_gt(1) - Data_flip{i}.bbox_gt(3); Data_flip{i}.bbox_facedet = Data{i}.bbox_facedet;Data_flip{i}.bbox_facedet(1) = Data_flip{i}.width - Data_flip{i}.bbox_facedet(1) - Data_flip{i}.bbox_facedet(3); endData = [Data; Data_flip];
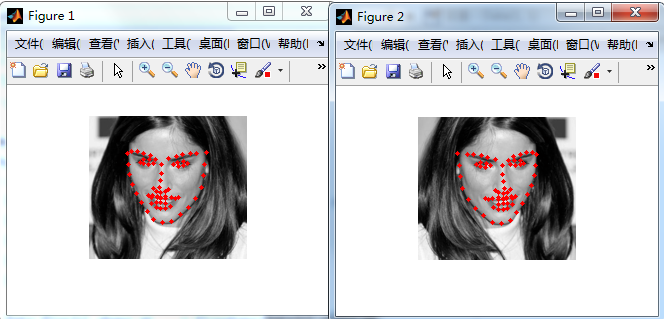
end示意圖:


{alert(‘’‘)}))

)




)
——考新郎( 錯排 ))








